







 首先我们一起来看一下,人工智能系统测试的挑战在哪里?它和传统软件测试的不同之处在什么地方?当今社会,人工智能的发展非常快,特别是以深度学习为代表的人工智能的发展到了一个高速发展的阶段。人工智能的发展已经渗透到了我们生活的方方面面。在人工智能高速发展的今天,也暴露出了人工智能的一些问题。由于人工智能往往存在一些训练过程中的过拟合、欠拟合等等的一些原因,或者遇到了环境中的一些样本的偏差,使得它可能在一些情况下对输入的判断有一些偏差。还有人工智能系统领域比较热门的一个技术——对抗样本技术(后面我们也会提到)也会对人工智能造成非常严重的干扰,特别是对于这种关乎性命攸关的系统,比如自动驾驶系统、医疗辅助诊断系统。我们希望在测试中能够测出这些人工智能系统存在的偏差,这也是为什么针对人工智能系统的测试非常地重要。
首先我们一起来看一下,人工智能系统测试的挑战在哪里?它和传统软件测试的不同之处在什么地方?当今社会,人工智能的发展非常快,特别是以深度学习为代表的人工智能的发展到了一个高速发展的阶段。人工智能的发展已经渗透到了我们生活的方方面面。在人工智能高速发展的今天,也暴露出了人工智能的一些问题。由于人工智能往往存在一些训练过程中的过拟合、欠拟合等等的一些原因,或者遇到了环境中的一些样本的偏差,使得它可能在一些情况下对输入的判断有一些偏差。还有人工智能系统领域比较热门的一个技术——对抗样本技术(后面我们也会提到)也会对人工智能造成非常严重的干扰,特别是对于这种关乎性命攸关的系统,比如自动驾驶系统、医疗辅助诊断系统。我们希望在测试中能够测出这些人工智能系统存在的偏差,这也是为什么针对人工智能系统的测试非常地重要。
一、人工智能系统测试的难点
传统软件的规则是人为写进去的,人工智能系统的规则是从数据中学到的,不断有新的数据进来之后,它里面的规则也会进一步地进行改变。根据学到的规则再从你的输入的数据中得出一个结果。人工智能系统不是通过编写明确的逻辑,而是通过数据来训练数据、训练规则。所以它的测试方法和传统软件的测试方法肯定是有所区别的。

传统软件测试知道了规则之后,根据这个规则去设计测试用例就可以了,但是人工智能系统很难通过设计用例的这种方式去进行测试,这也是人工智能系统测试为什么有挑战性的一个根本性的一个原因。
由于编程模式的改变,使得人工智能的程序会有很多的特性,导致其无法用传统的方法去进行测试。首先它输出的结果具有一定的随机性。因为它是从训练数据中所训练出的一个逻辑规则,使得它输出的结果和你的输入数据是非常相关的。
再一个就是人工智能系统通过的准则很难去确定,怎么判断这个人工智能系统的测试是符合要求的?这个是非常难以判断的。从另外一个角度说,很难判断人工智能系统它的输出还不是正确的。这个在测试领域也有一个专门的名词叫做“test oracle”的问题。也就是说我很难确定测试的结果到底是不是对的。
人工智能系统的规则是通过数据训练出来的,它的性能也就严重依赖于我们输入的训练数据的质量,数据的规模、数据的质量、数据的差别都会影响人工智能系统的性能。
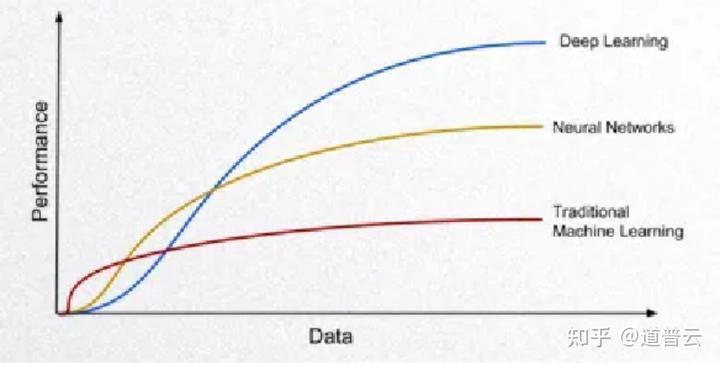
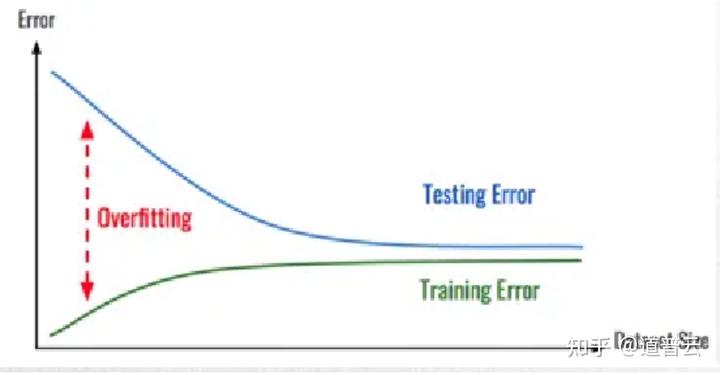
特别是在很多时候,人工智能系统可能会表现出一个过拟合的现象,也就是说在训练阶段表现得很好的一个模型,可能在测试阶段表现并不是特别好,这样就造成我们在测试的时候,对数据的把握就非常的重要。
人工智能系统它的输出结果,除了刚才说的不确定性之外,也是可能会随着时间进行变化的。一般来说,我们大多数企业中的人工智能系统是一个不断更新迭代的过程。先由一定的原始数据训练出一个模型出来,之后根据业务的调整,或者说随着用户数据的一些变化,一段时间之后,原来的模型准确率可能无法满足业务要求,企业往往会对模型进行一个更新的训练。这样这个系统输出的结果会随着你不断更新数据会产生变化。每次更新之后,可能会对这个系统进行一个重新的评估测试。

人工智能系统随着时间的变化,数据的演化,性能、输出结果也会发生变化,因此需要一个可持续的、可循环迭代的测试方法。能够尽快地去训练、测评、部署更新版的模型。这也是人工智能系统测试需要遵循的一个原则。
二、人工智能系统测试流程和方法
接下来我们一起来看一下,人工智能系统究竟应该用什么样的流程和方法去进行测试呢?
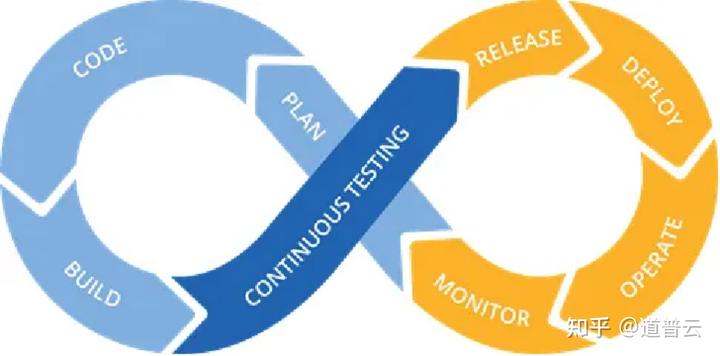
首先我们一起来看一下,一个企业的人工智能产品部署和发布的一个流程,首先企业会从历史数据库中,利用数据去训练出一个初始的模型,这个初始的模型首先会进行一个offline testing,也就是说一个离线的测试。离线的测试就是针对现阶段训练出来的模型进行一些功能、性能方面的测试。
离线测试通过之后,就会把这个模型部署到线上的一个具体业务当中去。部署到线上之后,我们的数据也会进行实时的更新,随着用户访问这个人工智能系统越来越多之后,数据也会随着业务开展变得越来越多。这时候,在线上进行业务的同时,我们会对这个人工智能系统模型进行一个线上的测试,也就是online testing。
线上的测试和线下的测试有什么主要的区别呢?第一个是线上测试会接触到更多的新的一些数据,有些数据可能是一些非法的,有的可能是造成一定影响的,都是有可能发生的,这个对于线下的测试来说一般是很难做到的。
第二点,线上的测试除了线下测试需要考虑的模型的一些参数之外,还可能会考虑到一些性能方面的问题。比如说用户的响应时间等。
在进行线上测试之后,我们会收集到一些新的线上用户的一些数据,这些数据一般来说都会更新到原来的数据库当中去。这样就形成了一个循环迭代的过程。也就是说,不断的用这个数据库去训练这个模型,再从新的数据中去更新这个模型,去不断地进行线下和线上的测试这样一个过程。
从这个过程中我们也可以看到,整个人工智能测试是一个循环迭代更新的一个过程,对于数据的更新也是非常重要的一环。

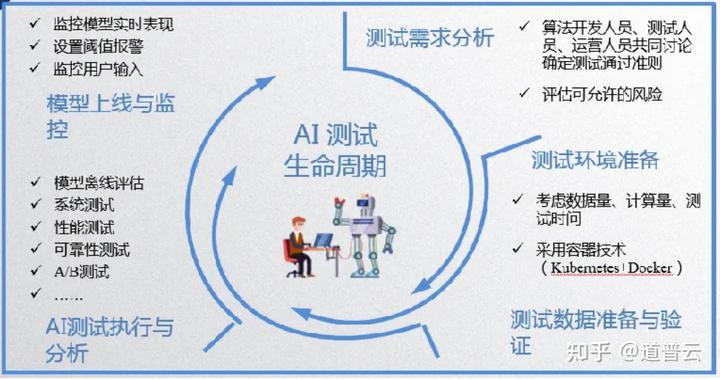
测试的步骤具体来说到底是怎么做的呢?我们经过大量的时间和研究总结出来了人工智能测试的生命周期。基本上它也是一个循环迭代的一个过程,需要经历测试需求的分析、测试环境的准备、数据的准备与验证、测试的执行预分析以及上线后的监控这样一个过程。
1、测试需求分析
首先从测试需求分析阶段,这个可以借鉴我们测试需求分析的一些方法,我们需要明确测试的对象、测试的范围、测试的方法和工具等。对于人工智能系统的测试来说,有两点是需要特别注意的:
1)AI系统测试通过的准则,不再仅仅是测试团队的任务,而需要算法开发人员、测试人员、系统运营人员共同参与讨论测试通过准则。
我们刚才也说过,针对人工智能的测试我们很难去确定它的测试到底怎么样才算是通过,怎么样才算是不通过,也就是所谓的“test oracle”的问题。还涉及到一个问题,测试的充分性的问题。在后面的测试技术板块我们会专门讲这两个问题。
我们如何确定测试通过的准则,需要我们的测试团队结合人工智能系统的一些应用场景,进行一些共同参与、讨论,不同的应用场景,测试通过的准则是不一样的。比如一些关乎性命攸关的系统,它测试的准则往往要求会非常的严格,而对于无关性命的系统,它的测试准则就会相应地放宽一些。
2)AI系统的行为或结果无法完全确定或预测,因此还需要开发、测试和系统运营人员共同定义可允许的风险,风险可根据技术的限制和社会共识来确定。
这个跟我们上面讲到的也是相关联的,比如说一个医疗诊断系统,允许的风险就必须要降到非常低,比如说系统的准确率必须要达到99%以上,即使有1%的差错,也有可能导致医疗事故。
但是对于一个一般的人工智能系统,与生命没有什么关系的人工智能系统,比如说识别一个人的年龄、识别花花草草,这种应用即使出错危险也不会特别大。所以一定要根据具体的业务去分析人工智能测试可能带来的风险可能会有哪些,根据这个风险我们再去设计测试通过的准则有哪些。
以上就是需求分析阶段所需要注意的问题,第二个阶段我们需要进行一个测试环境的准备。
2、测试环境准备
这里通常有三大因素,第一个我们需要考虑数据量、计算量、测试时间等因素。对于人工智能的一个系统来说,往往我们需要输入一些特定的测试数据,这个在接下来的一步我们会具体谈到。这个时候我们就需要考虑我们的测试环境能不能顺利地运行这些测试数据的推断和功能。
第二个是需要测试团队具备环境快速部署的能力,因为人工智能系统的部署开发往往是一个循环迭代的一个过程,这时候需要我们在构建测试环境的时候,需要能够快速地更新和部署。
由此,我们结合以前研究的一些经验,我们发觉DevOps的一些相关技术,尤其是容器技术(Docker+Kubernetes)越来越多地应用于人工智能公司当中,被用于人工智能系统测试的快速测试与部署。因为用容器的方式以及Kubernetes的方式能够快速地去部署我们AI测试所需要的环境。
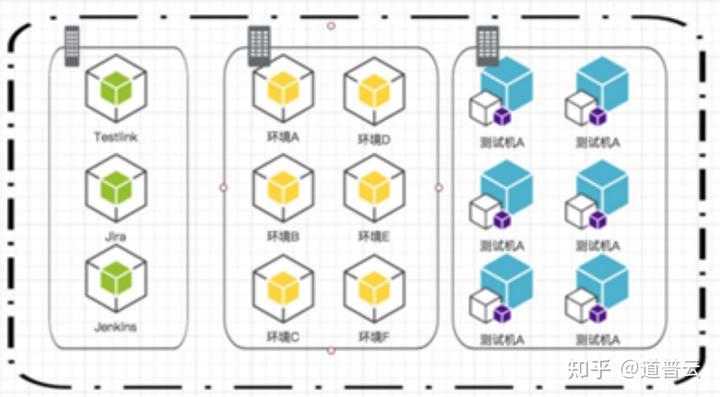
3、数据准备
第三阶段主要数据准备阶段,测试数据准备往往是影响最终测试结果的一个重要的指标,对于测试数据集的选择也是非常有讲究的。
首先,测试人员使用的测试数据集,需要尽可能的覆盖真实环境用户产生的数据情况。比如说真实环境下用户上传图像是用手机拍摄的?还是分辨率比较高的?像这种问题肯定是需要考虑进去的。
测试数据集的验证可遵循以下原则:
1)测试数据与训练数据的比例要合适,这个比例应根据实际算法和应用场景确定;
这个往往发生在离线测试的情况,比如说我们训练好了一个人工智能模型之后,我们需要进行离线测试的时候,我们这个时候的测试数据可以和原来的训练数据成一定的比例关系。这个比例关系可以根据实际的算法和应用场景来确定。
2)测试数据与训练数据需要独立同分布;
关于同分布这一点,要看具体的需求,如果说真实环境集下和训练数据差得非常远的话,也是建议构建测试数据集的时候需要考虑一下真实环境下的比例分布。比如说正负样本的比例需要和真实的环境尽量可以保持一致。
但是我们在离线测试的时候,如果那时候还没有足够真实环境的数据的话,我们可以考虑先构建一个测试数据和训练数据分布尽量保持一致的测试数据。这样可以比较好地进行一个离线的对人工智能系统的判断。
3)对于监督模型,测试数据的标签需要保证正确。
最后是对于监督的模型,所谓监督的模型就是说我训练的时候,我训练的数据是经过人为的标注的,就叫做可监督的学习,对于这种学习出来的模型,我们测试数据的标签也要尽量保证它的正确性。因为不这样的话,我们最后测试出来的一些结论可能也是错误的。
4、测试执行
以上说的测试环境、测试数据都准备好了之后,我们就可以进行具体的人工智能的测试工作了。这里面又可以分为很多种测试的流程,比如说刚才说到的有模型离线的评估、系统的测试、性能的测试、可靠性的测试、A/B测试,最后我们还要针对我们的测试结果进行一定的分析。

1)模型的离线评估
比如说对于模型的离线评估来说,在人工智能测试中主要是用来评测AI模型对未知新数据的预测能力,即泛化能力。通常而言,泛化能力越好,模型的预测能力就越好。衡量模型泛化能力的通用评测指标包括:均方根误差RMSE、平均绝对误差MAE、准确率Precision、召回率Recall及F-measure等。
衡量泛化能力的标准有很多,通常对于不同的应用场景来说,它的指标也有可能会不同,比如说对于典型的图像分裂的场景,我们有准确率、召回率、MAE值等。对于别的场景也有可能会有别的指标,待会我们也会讲到,比如说对于目标监测的应用场景来说,也有会有其他的计算指标,像均方根误差、绝对误差等等,这个是根据具体的业务应用来定的。
2)系统测试
模型的离线评估之后,我们也可以进行一个系统的测试,这个时候跟传统的软件测试是有一定的重合的,比如说我们会测试系统整体的业务流程,测试模块之间 数据流动以及测试一些真实用户的使用场景。
在系统测试的过程中我们也可以包括进去一些性能测试、可靠性测试。
3)性能测试
性能测试我们也是可以考虑负载和压力,或者用户并发这样的一些测试。如果说这个人工智能系统用户访问量非常大的话,我们就可以进行一些性能方面的测试,因为人工智能推断的相应时间也是可以影响到我们整体的系统的相应指标。
4)可靠性测试
人工智能系统的可靠性包括了鲁棒性、可用性、容错性、易恢复性等指标;特别是我们需要去测试一些鲁棒性、容错性。
对于无人驾驶、人脸识别等安全攸关的人工智能系统,需尽可能采用异常数据来进行测试,如对抗样本、易出错的样本等去进行一些测试。这个对于对于人工智能系统的安全和鲁棒是非常重要的。具体的测试技术我们之后会进行一个介绍。
5)A/B 测试
除了以上这些测试之外,我们也可以进行一个A/B测试。人工智能系统的模型往往是不断迭代更新的,我们如何确定迭代更新之前和之后这两个模型有没有提升?这时候我们就可以用A/B测试去比较两个模型、或者多个模型的差别。当我们的模型改动之后,我们可以和前面的模型进行一个比较,看看它到底是有优化还是有衰退。来确定我们究竟是用哪一个模型来上线。

5、测试分析
我们通过上面的一系列的测试之后,我们需要对测试的结果进行分析,需要对AI系统各类测试的质量特性进行深入分析;在模型离线评估阶段,需要分析模型泛化能力是否满足应用的需求;在性能测试阶段,需要分析应用响应时间是否满足需求;在可靠性测试阶段,需要分析系统是否可以抵御对抗样本的攻击,及输入异常数据时系统的表现;在A/B测试阶段,则需要通过统计分析,评判新模型是否到达了预期。
以上就是人工智能系统测试整体上的流程和方法论。这里面还有几点需要我们注意:
AI模型上线后,测试人员需要以固定间隔监控模型的实时表现,根据实际业务每隔几天或几星期,对模型各类指标进行评估;
上面我们也讲到过,除了我们要进行不断迭代的测试之外,我们也需要对模型进行一些固定的时间间隔或者实时的监控。为什么呢,之前也有一些新闻讲到,有些模型如果它是根据用户新输入的一些数据去进行一个实时的训练的话,用户新输入的这些数据往往会对模型的性能造成一定的负面影响。
如果模型随着数据的演化而性能下降,说明模型在新数据下性能不佳,就需要利用新数据重新训练模型,更新模型参数;
比如说用户习惯突然有了一些变化,用户输入的特征有所变化的话,以前模型的性能可能就没法满足现在的业务要求,也是要不断的监控去探测。
在一些场景中,我们还需要对用户输入数据进行监控。除了在模型监控之外,对用户输入数据进行监控也是非常重要的。特别是对实时用户新增的数据去进行训练、更新的系统来说尤为重要。
比如说2016年微软在Twitter上发布的一款聊天机器人,他说根据用户不断地聊天数据去训练数据,来进行不断地更新。这样就导致有的人输入一些脏话、或者反动的一些话语,对这个机器人进行不断的调教之后,就导致了这个聊天机器人会表达一些法西斯的思想或者脏话连篇的现象,最后不得不宣布让这个聊天机器人的模型重置。
所以说对这类系统来说,我们也要不断地去监控模型的一些实时的表现,以及用户输入数据的一些实时的表现,防止人们把模型“教坏”的情况。
三、人工智能系统测试技术
刚才我们对于人工智能系统测试的总的流程进行了阐述,接下来我们一起了解一下,人工智能系统测试具体有哪些技术呢?就我们以前的研究成果跟大家进行一个分享和讨论。
刚才我们说到了,人工智能系统测试分为很多步骤,其中比较典型的步骤包括模型离线的评估以及可靠性的测试。对于一些人工智能系统测试特有的问题,比如说测试结果准确与不准确难以确定、测试充分性难以确定的问题,我们之前的学术界也好,工业界也好,也研究出了一些方法去应对这些难点。比如说用蜕变测试或变异测试这些方法去测试AI系统,接下来我们会一个个进行详细的介绍。
1、模型离线评估
首先对于模型离线评估来说,这个往往是通过一些具体的可以计算的一些指标来进行评估。有很多这样的指标,比如说敏感度、特异度等。特定的系统可能会某些指标有一些特定的要求,比如说大于某一个值等。这个具体的值是和具体的风险分析相对应的,比如说你这个系统是不是会对人的生命财产造成严重的损失?这个风险就决定了我们最后指定离线评估通过的准则的时候,需要考虑的具体的阈值是多少。
设置模型离线评估通过准则,如:Sensitivity = true positive/positive ≥ 90%Specificity = true negative/negative ≥85%
这个指标有非常多种,在这里我们仅以分类这样一个应用来说。举一两个例子,比如对于分类来说,我们可以去计算它的一个准确率、查准率、 查全率等等,这些指标都是有一定的公式的。这些指标都是去衡量对于所有的测试输入来说,到底能准确判断的输出到底有多少。
a)准确率(accuracy):对于给定的数据集,预测正确的样本数占总样本数的比率准确率=预测正确的样本数/总样本数*100%
b) 查准率(也叫精确率,Precision):对于给定的数据集,预测为正例的样本中真正例样本的比率查准率=预测正确的正例样本数/预测为正例的总样本数*100%
c) 查全率:(也叫召回率、敏感度、Recall):对于给定的数据集,预测正确的正例样本占所有实际为正例样本的比率查全率=预测正确的正例样本数/实际为正例的总样本数*100%
d) F1 值:查准率和查全率的调和平均数F1=2∗(查准率∗查全率)/(查准率+查全率)*100%
除了这些指标之外,对于分类应用来说还有很多其他的指标,下面这张表格中比较全面地列出了对于一个典型的分类应用来说,可以测量的一些指标。我们前面提到的只是一部分,比如说准确率、召回率等。每一行、每一列除以一行总的量和一列总的量都会形成一个相应的指标。对于医学领域来说,甚至还有一些对于医学领域特定的一些指标。
具体指标的选择需要根据具体的应用来确定选取哪些指标来作为衡量的一个标准。

除了分类之外,我们再举一个例子,比如对于目标检测这样一个应用场景来说,(目标检测业务场景是什么呢,比如说在一张图像当中,我能够用人工智能的程序去框出我所关心的目标它所在的位置在哪里,比如说在这一张图片当中去框出人脸的位置),它的评价指标又和前面讲的的分类指标有所不同。
这个时候就需要去计算我框出的框和具体正确的框的位置之间到底差多少,比如说我们可以去计算两个框之间的相似度是多少,这个是可以用两个框重合的面积去比上两个框的相并面积。也就是用交并比这样一个指标来衡量。
同时也可以用mAP,也就是平均准确率来衡量,可以通过一条曲线来计算,比如说我们设定不同的判断阈值,会得到不同的查准率和查全率,然后绘制成一条曲线,这条曲线下的面积代表目标检测这个类的平均准确率,对于不同的类别我们再算一个平均值,就得到了mAP的指标。
a)IoU:目标检测算法中用来评价2个矩形框之间相似度的指标(两个矩形框相交的面积/两个矩形框相并的面积)IoU=(area(B_p∩B_gt))/(area(B_p∪B_gt))
b)mAP:用来度量模型预测框类别和位置是否准确的指标。根据不同的threshold,得到不同点的查准率(precision)和查全率(recall),然后绘制成一个曲线,这条曲线下的面积代表该类的AP,而mAP则是对不同类别的AP取均值
其实还有很多的对于不同的应用场景来说比如说自然语言处理等指标,这些指标都可以运用一些公式或者工具去计算,计算出来的就是比较客观的对于模型连线评估判断的评估指标。
这里我们再举几个例子,比如说对于最终的模型准确率我们可以划出一个曲线来,对不同的模型曲线来进行一个比较,谁的准确率比较高一些。
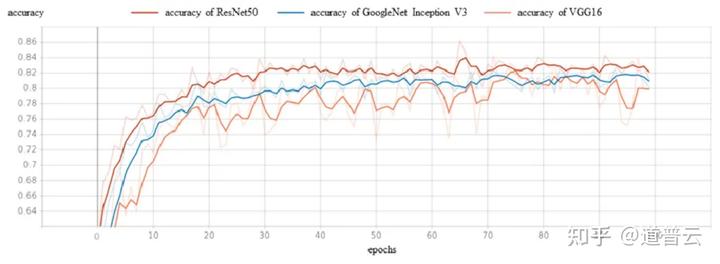
Overall accuracy
对于一些分类的应用来说,特别是多分类的应用,我们可以计算出每一个类它的准确率和召回率,以及它的宏观准确率、召回率,甚至于F1值有多少。
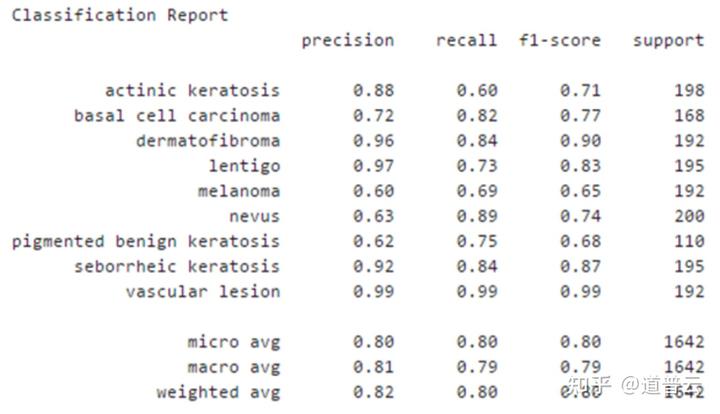
Sensitivity(Recall)/Precision/F-Measure
再比如说,我们可以通过混淆计算的方式来比较直观地去判断一个模型的好坏。对于多分类系统来说,我们可以画出这样的一个矩阵,这个矩阵的每一行是每一类的真实的类型,每一列是推断的类型。这个矩阵,如果对角线上的数字越大,就说明每一类正确识别的次数就越多。对角线上的数字越大,非对角线上的数字越小,就说明这个模型越好,反之,这个模型性能就不怎么好。
如果说在非对角线上有某个数字特别大,我们就要需要去具体的观察,比如说这一类我可能判断的失误比较多一些,就可以进一步去判断,这一类到底什么原因它判断的错误比较多,有可能是训练样本的原因?还是测试数据值的原因?等等,这个矩阵会给大家一个非常好的参考。

Confusion matrix
还有比如说我们可以通过这些可视化的方式来用肉眼去判断一下我们这个分类系统到底是不是好。比如说我们可以把测试的数据分类后的结果,用t-SNE这样的技术算法去进行一个绘图。
从这一张绘图中,我们可以看到如果说同一颜色的数据点都靠得比较近、都靠成一团的话,就说明我们这个模型它对于数据的分类来说是分的比较清楚的。
反之,如果这个模型把不同颜色的点都混在一起的话,就说明这个模型对于某些类型的数据它可能分类地不是特别的好,或者说很难以区分。这里面可能又有很多因素造成,可能我这个训练数据当中,有几类数据长得确实比较像,对于这个模型来说确实是很难区分。或者还有一种可能,就是刚才说的过拟合的原因,也就是说我模型训练的时候,训练到的一些知识过于关注数据中的一些细节,而没有真正学到数据中差别的特征值也会造成这种现象。
总之我们可以根据这些可视化的结果,去进行一个直观的判断。
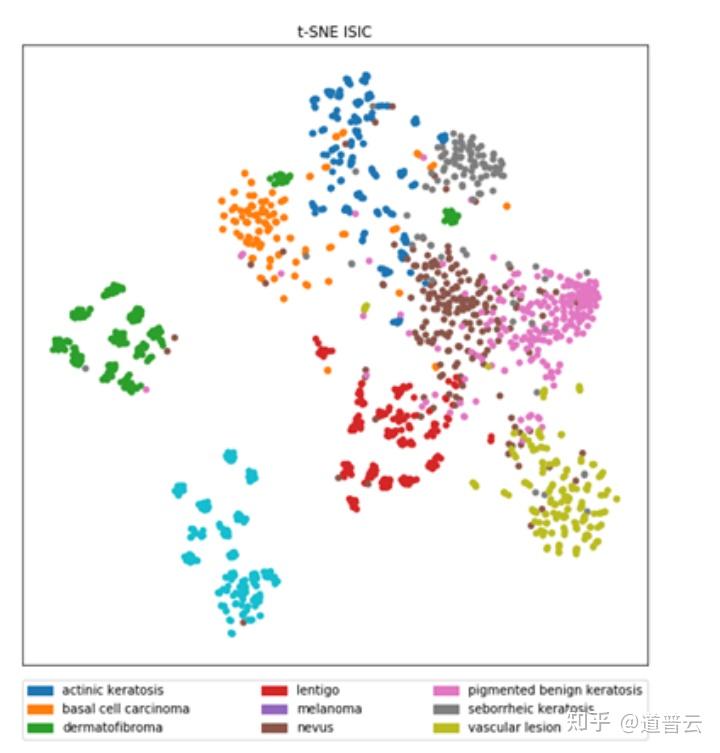
t-SNE
2、可靠性测试
接下来我们着重介绍一下可靠性测试,上面讲的是模型离线的测试,这里面测试基本上对于一些典型的应用来说基本上是比较成熟的,也就是说各个领域的测试指标基本上都是比较固定的,或者说是比较有共识的。对于可靠性来说我们主要是要关注模型的安全性,或者对于异常输入的影响。
这里面有典型的两种,一种叫对抗样本,对抗样本(Adversarial Examples)是攻击者故意设计,诱导机器学习模型出错的输入样本。
当时提出对抗样本的这篇论文也是引起了很大的轰动,以至于后来我们学术界也好、工业界也好很多人都对对抗样本的生成以及防御方法进行了非常多的研究。
对抗样本具体是怎么回事?我们可以看下面这张样例。比如说我们输入是一张熊猫的图片,如果说原始状态下,我训练好了这个模型,能够正确地判断出我输入的这张图片是一个熊猫,但是攻击者对这张熊猫图片加入一些很微小的噪声,但是这个噪声人的眼睛是看不出来的,但是对于机器学习系统来说,它输入的时候具体计算出来的时候,就会有所差别。这个噪声是经过我特别训练之后所生成的,它的目的在于,这个噪声添加进去之后,能够恰好使得目标系统的输出和原来正常的输出不同。

比如说熊猫加入一个噪声之后,我就能够让这个系统识别成一个长臂猿,或者识别成一个其他的动物,这个在人工智能系统的安全性能来说也是非常重要的一个问题。不仅是在图像领域,在语音识别领域和自然语言处理领域都会有这样的一个问题。
比如说语音识别,在自动驾驶的时候,我要攻击这个自动驾驶系统的语音操作的系统,有时候我们可以去用特定的方法生成一段音乐。这段音乐人类听起来就是一段正常的音乐,但是这段音乐输入到人工智能系统之后,进行解析的时候,有目的地让这一段音乐被解析成自动驾驶的一个指令,比如说刹车,这样对人工智能自动驾驶系统来说就非常危险。
还有对于人脸识别系统的攻击方式,比如说我可以生成这样一副特殊的眼镜,这副眼镜戴上去之后,能够使得系统将原来这位女士识别成一位演员。

还有对自动驾驶系统的攻击,比如说我原来有一个STOP的交通方式,加入一些噪声或者加入一些贴图之后,尽管人的肉眼看上去仍然是一个STOP,但是对于自动驾驶系统,特别是以图像为基准的自动驾驶系统,我们攻击它的时候,就有可能让它识别成一个绿灯。这对于这种性命攸关的系统来说这是非常危险的。

所以我们在做可靠性测试的时候,对于这种性命攸关的系统,我们是非常有必要加入一些对抗样本去测试。我们可以用技术手段去特别地生成一些对抗样本,对人工智能系统去进行一个更有针对性的测试。
测试完成之后,如果人工智能系统不能很好地去防御这种对抗攻击的话,我们也可以运用相关的手段去加强人工智能系统对于恶意输入的抵御能力。比如说我们可以引入一个对抗性的一个训练,也就是说我们可以把这些对抗样本也同时加入到我们的训练数据当中去,让人工智能系统对这些对抗样本的特征有一定的学习,这样可以加强人工智能系统的可靠性。
利用差分测试生成易出错的测试样本
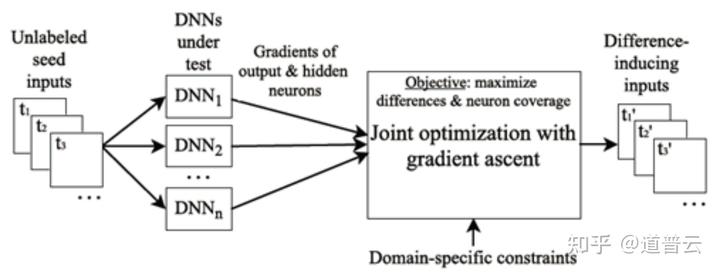
除了对抗样本之外,我们可以生成一些也是容易让人工智能系统出错的一些样本。比如说我们可以应用相似的人工智能系统的输出,来构造一些容易使人工智能系统出错的样本,比如说参考项我们可以引入A、B、C、D等多个系统,这些系统功能是相似的,我们在构建这个样本的时候,通过一定算法去构建出能够使这个被测系统和A、B、C、D这些系统输出不一样的样本。
这些往往都是一些非常异常的、或者corner case的一些样本,这些样本也对于人工智能的可靠性测试也是非常有帮助的。
差分测试(Differential Testing)——引入其他功能相同的DNN,作模型交叉验证。
功能相同(或相似)的DNN系统在现实中可能存在多个实现(比如不同的公司就有不同的自动驾驶系统)。
当测试某个系统A的时候,使用功能相似的系统B,C,D等作为参考系统。
给定相同的输入,如果系统A的输出不同于其他参考系统,那么有很大概率A的输出是错误的。
在一些常见的AI应用领域,多个功能相同的DNN是容易找到的(如图像分类领域就有VGG、ResNet、DenseNet等)。
最大化被测DNN与其他参考DNN之间的输出差异。
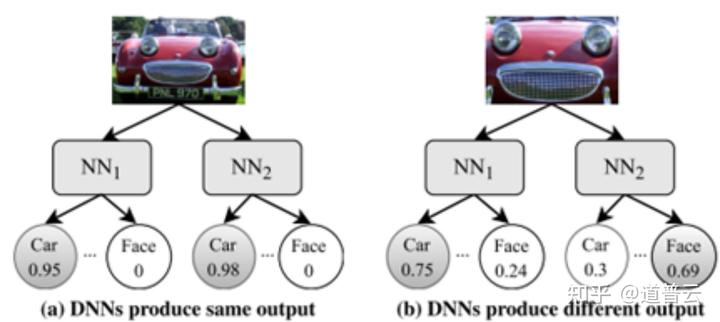
具体来说,比如我们可以去调节图像的明暗度,使得我们A、B、C、D不同的人工智能系统它的输出不一样。比如说在图像比较明亮的时候,我们的A系统判断是向左转,我们把这个图像变暗之后,使得B系统输出的变成了向右转。

我们还可以把这个图像放大,至于这个放大程度,我们可以通过精确的训练去计算出来。使得两套系统对于这同一张图片判断不一样,一张识别为一辆汽车,另一张识别为一个笑脸。像这样的图片就能很好地测试出我们的人工智能系统的可靠性。
3、蜕变测试
对于测试结果准确性的问题,我们可以引入“蜕变测试”这么一个思路,进行测试。蜕变测试在整个软件测试领域也已经提出很多年了,这个测试的思维也是特别适合人工智能系统刚才说的如何判断测试结果准不准确的问题。
比如说我们要测试sinx,如果说我们不知道我们输入的x它的结果是不是对的,我们可以构造一个蜕变关系,sinx=sin(π-x),然后我们输入x和π-x,去看看它的输出结果是不是符合我们蜕变的关系,由此来判断我们的测试结果是不是准确。
对于人工智能系统也是一样的,我们可以把我们测试的输入数据也是进行一些变换,比如说可以变换测试数据的规模、输入的顺序等,也可以针对单个输入的样本去进行一个变换。比如说变换测试数据的一个标签值,或者某些像素值等等。
之前我们需要假设,比如说我们构建的一些像素值或者改变规模等等,应该是不改变它的一个输出结果,有这样一个蜕变关系之后,我们再把两种输入输入到系统当中去,看看它们是不是符合这样一个结果。
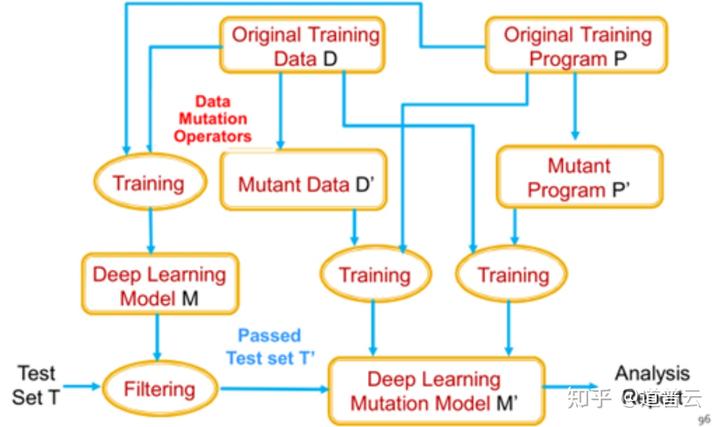
4、变异测试
第二种就是变异测试的一个思路,这个解决我们测试充分性的问题,也就是说我们所进行的测试到底是不是充分的,是不是足够了。到底测试进行到什么程度才是足够呢?我们可以通过引入变异测试的思路来实现。
它的思路是将被测系统在数据源级别或模型级别进行变异,由此会生成一些变异的版本,然后把我们的测试数据输入到这些编译的版本当中去,去测试这些测试的结果,能不能使这些变异的版本的输出出现一些变化,如果说能够使变异的版本出现一些输出结果的变化的话,我们就可以判断输入的测试用例是比较有效的。反之的话,就说明我们这个测试用例无法很好地测试出系统的一些变化。
由此来判断我们的测试集是不是充分,是不是所有的编译的版本能够使它发生一个变化。
人工智能测试技术在不断的演进过程当中,我们也需要不断地利用新的技术方法去适应并且解决人工智能测试的挑战。本文整理自上海计算机软件技术开发中心人工智能应用技术研究及测试领域高级研究员陈文捷技术交流内容,如需视频回放可私信我获取。
我们在医疗、汽车领域拥有丰富的人工智能测试经验。具备大量的数据模型和经过训练的测试数据集,如果您有人工智能测试课题共建、人工智能测试技术交流、人工智能测试工具选型、人工智能模型训练、人工智能行业数据集等需求,欢迎私信我,一起技术交流、探讨。
(谢绝转载,更多内容可查看我的专栏)

















 8386
8386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









