






全球疾病负担数据库(Global Burden of Disease,简称GBD)是当今流行病学研究中最重要的数据来源之一。它通过系统化的测量和分析,揭示了全球范围内疾病、伤害和风险因素对健康的影响。GBD数据库被广泛应用于SCI论文中,为公共卫生政策、医疗资源分配和健康干预措施提供科学支持。那么,GBD数据库相关的SCI论文一般会涉及哪些内容?本文将带你一探究竟。

总体来说,GBD数据的数据本身就是一系列的时间序列数据,其数据总共只有10个左右的变量,GBD数据库包含的变量有:measure(测量指标)、location(位置)、sex(性别)、age(年龄组)、cause(病因)、metric(指标单位)、year(年份)、val(值)、upper(可信区间上限)和lower(可信区间下限)。
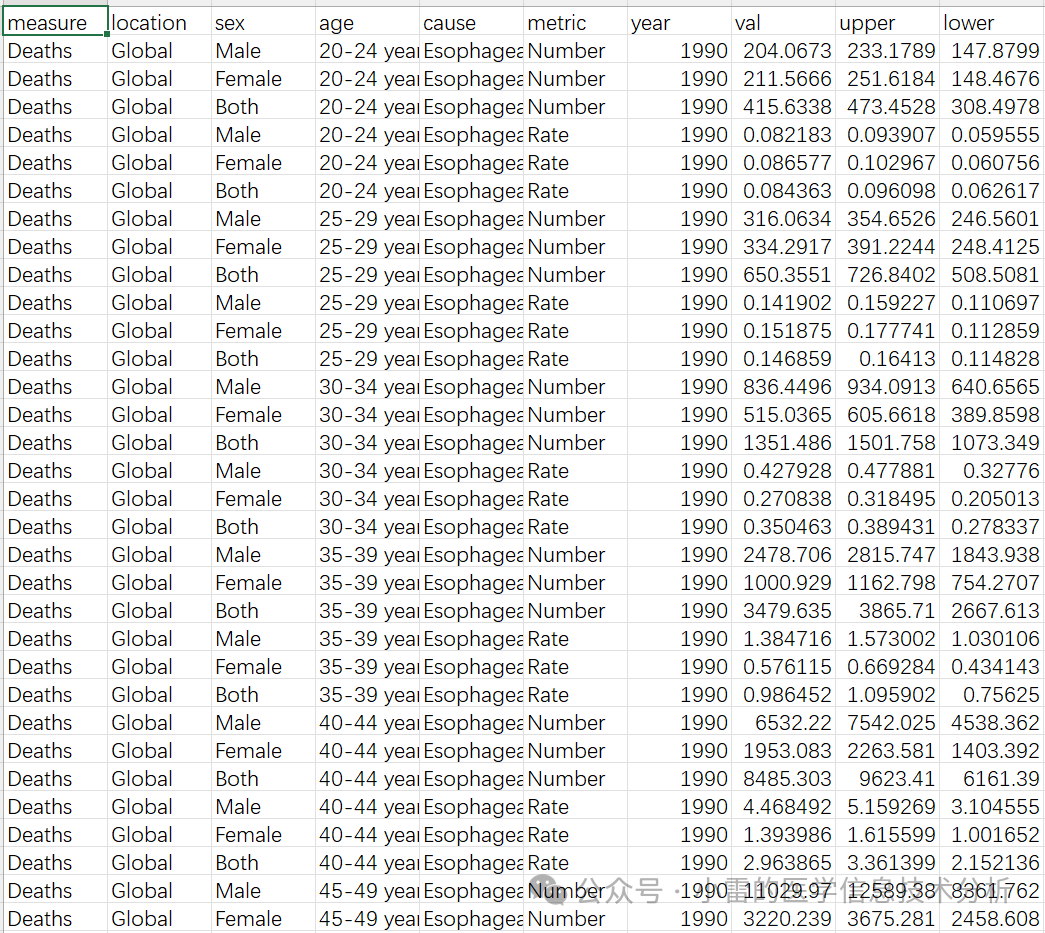
也就是说GBD数据本质就是各种疾病统计出来的时间序列数据。
那么GBD的SCI论文中常见的分析有那些内,下图做了简单的总结:

具体来说有以下内容:
-
描述统计:对疾病发病率、患病率、死亡率及DALYs进行现阶段的描述统计,常用指标包括ASIR(年龄标准化发病率)、ASDR(年龄标准化死亡率)和ASPR(年龄标准化患病率)。
-
变化趋势分析:分析疾病发病率、患病率、死亡率及DALYs的变化趋势,计算变化率指标(如EAPC、APC、AAPC),采用方法包括joinpoint分析等。
-
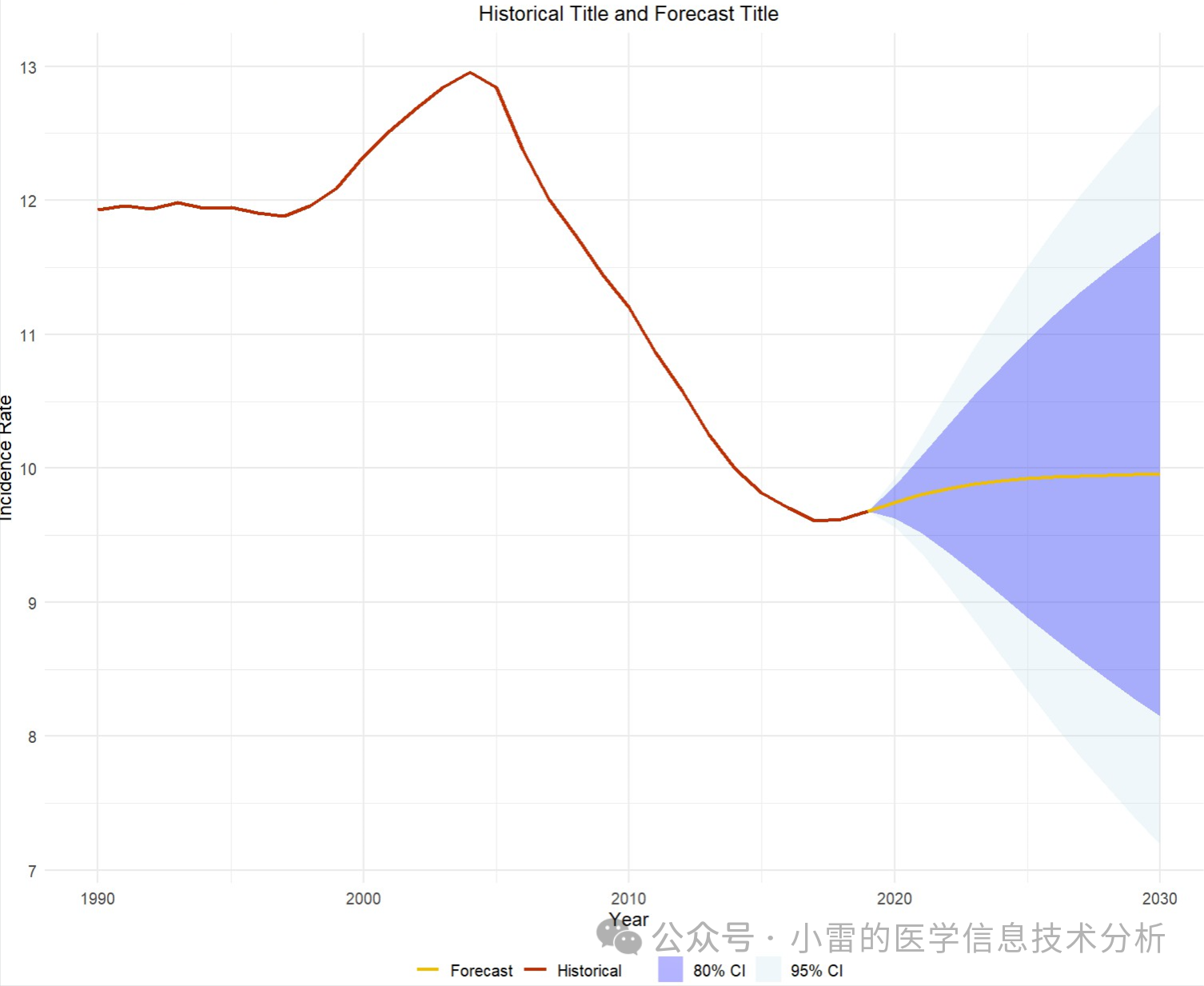
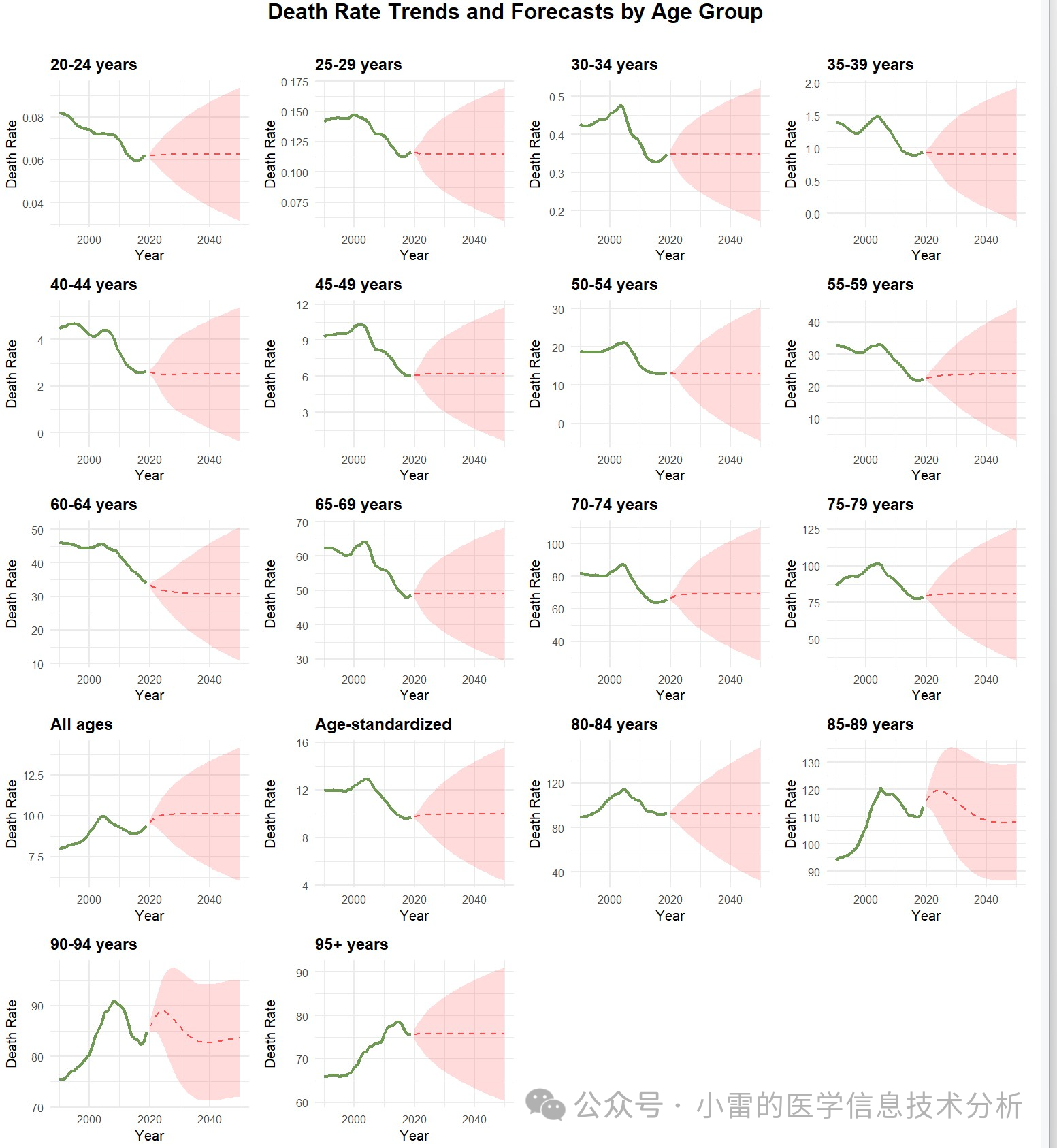
未来趋势预测:对疾病发病率、患病率、死亡率等未来趋势进行预测,采用时间序列分析方法,如BAPC(贝叶斯年龄周期队列分析)和ARIMA模型。
-
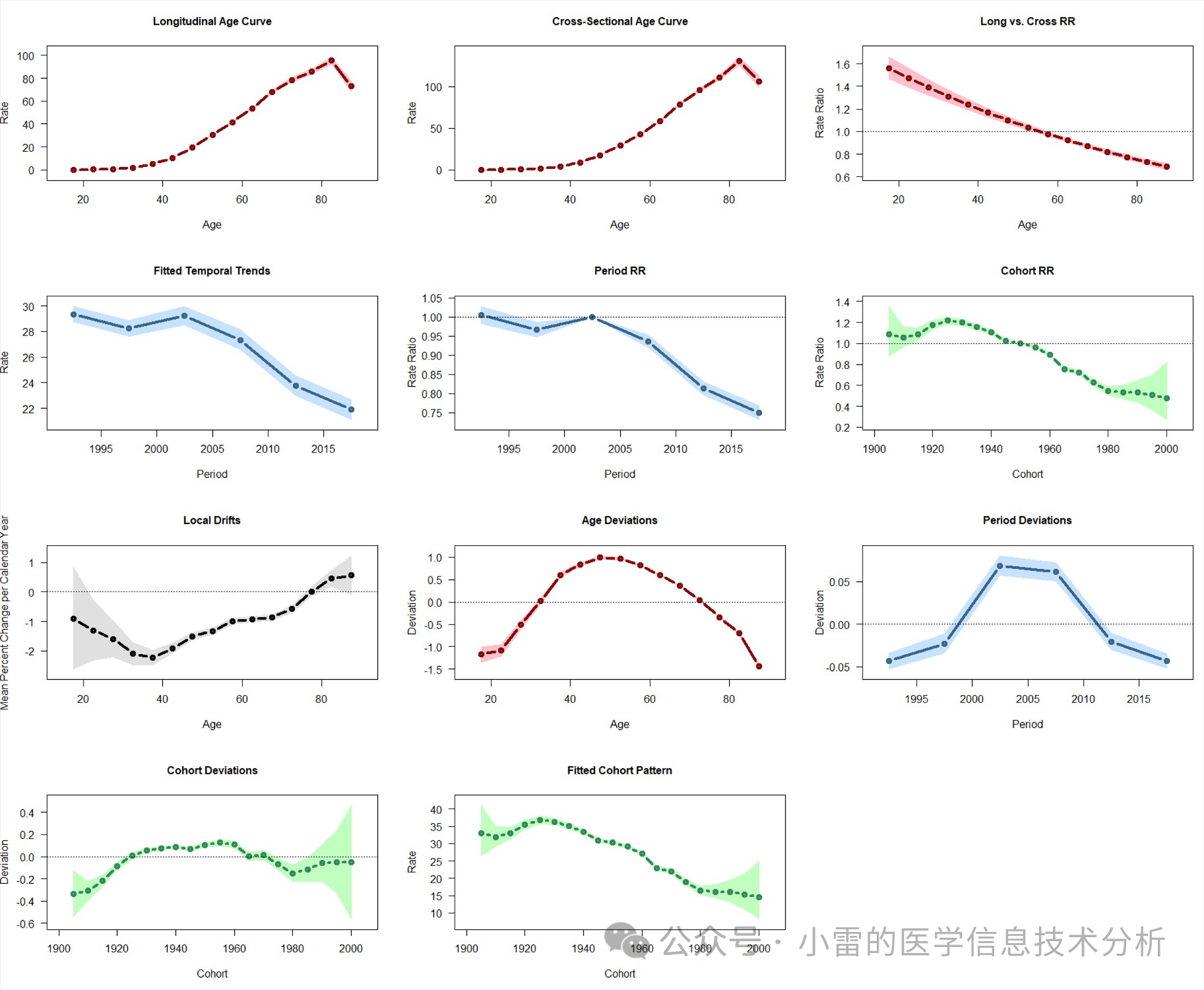
年龄-时期-队列(APC)分析:通过APC流行病学模型分析时间序列数据的变化原因,解释年龄效应、时间效应和队列效应。
-
分解分析(Decomposition Analysis):解释率的变化来源,包括老龄化、人口因素和生物学因素等。
-
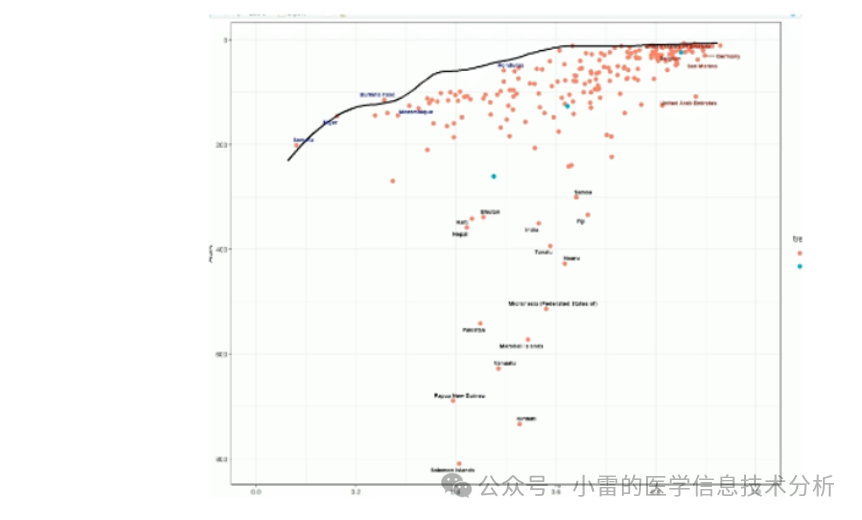
前沿分析(Frontier Analysis):衡量各国家社会发展指数(SDI)与疾病控制情况的关系。
-
数据可视化:通过各种描述性图形展示数据,便于解读与传播。
常见的结果和绘图如下内容:
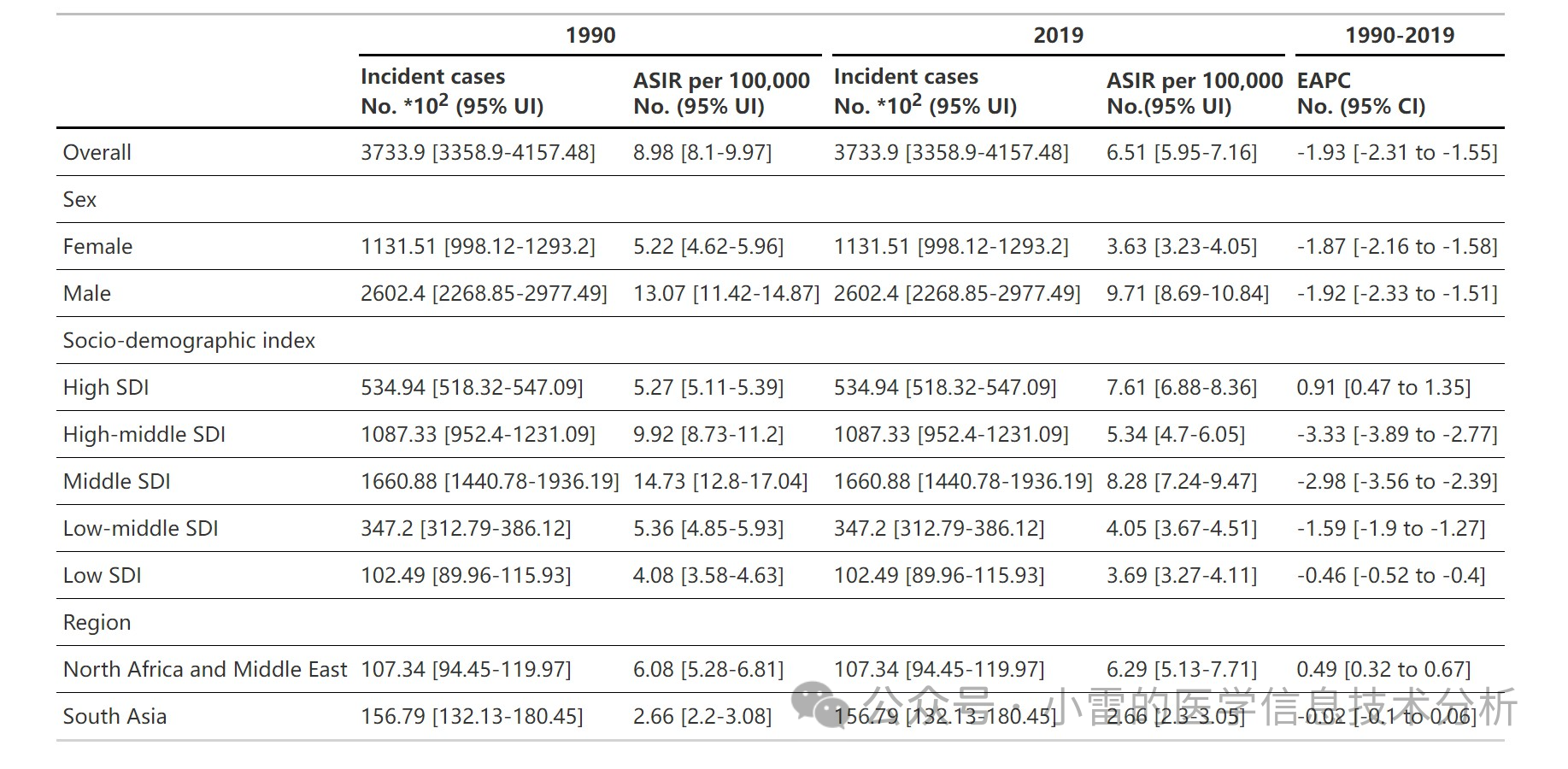
统计的两年对比EAPC表格:
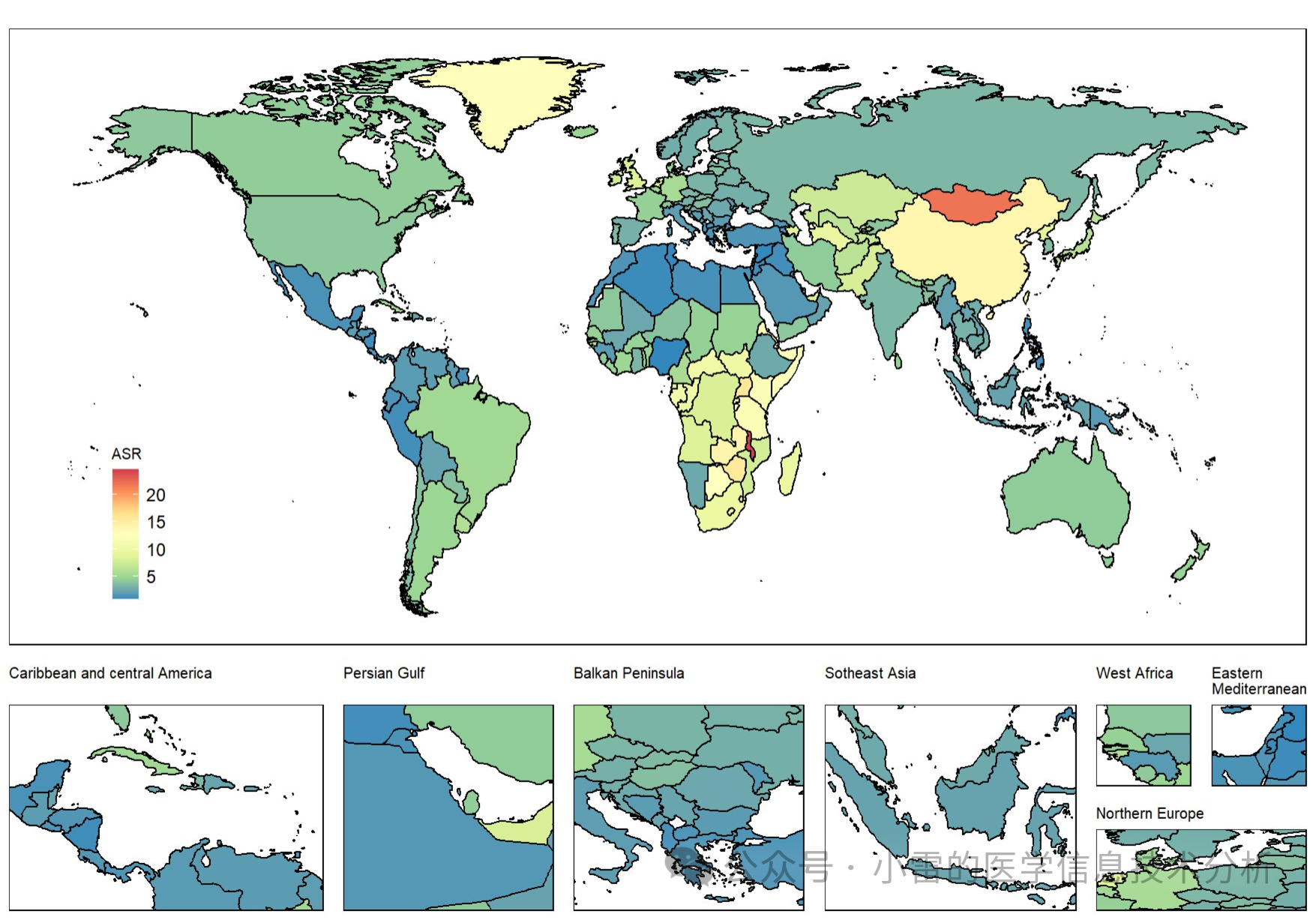
发病率、患病率、死亡率的世界地图:
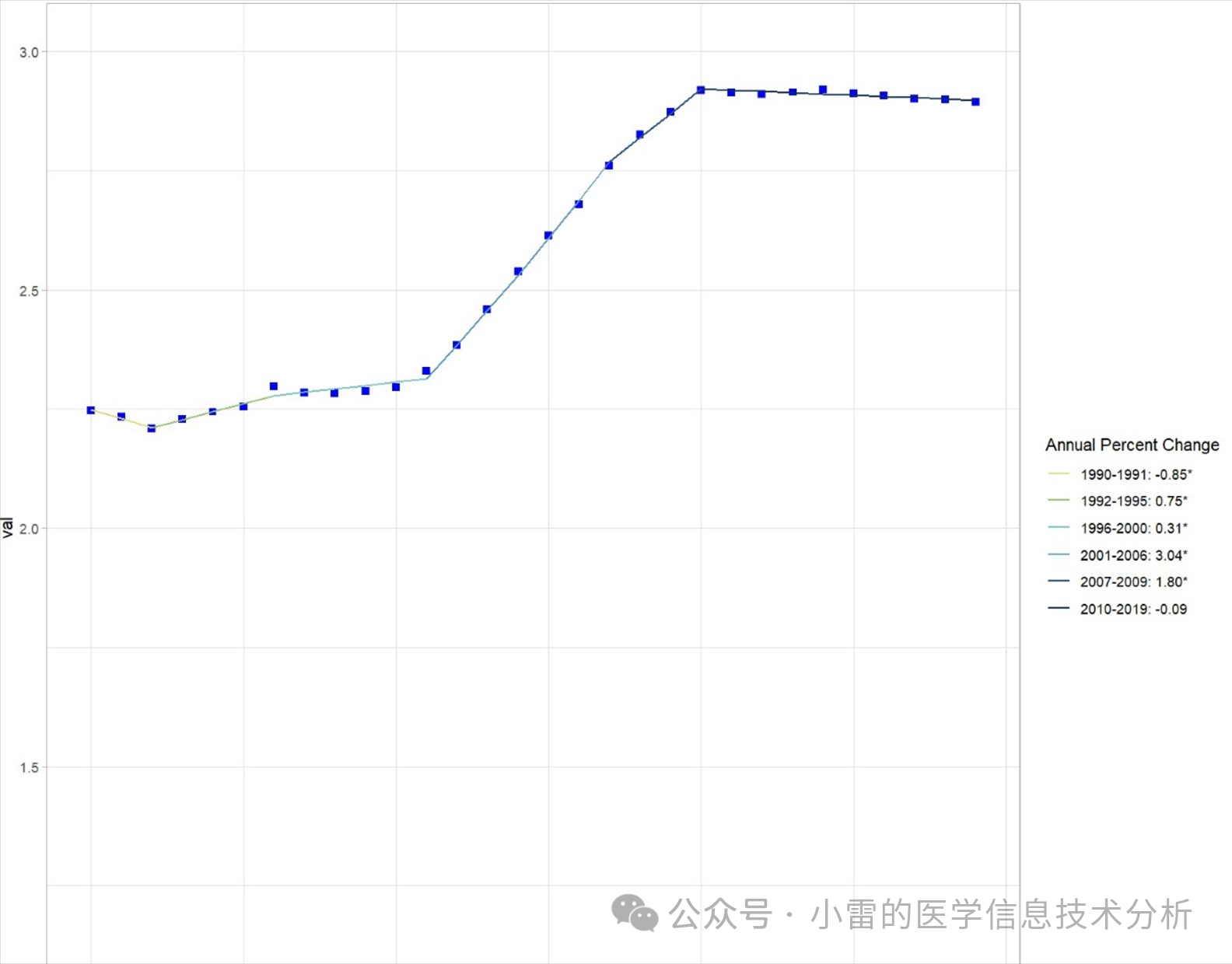
jointpoint回归计算APC、AAPC
未来趋势预测一般是ARIMA模型和BAPC模型,当然也有其他的时间序列预测模型:
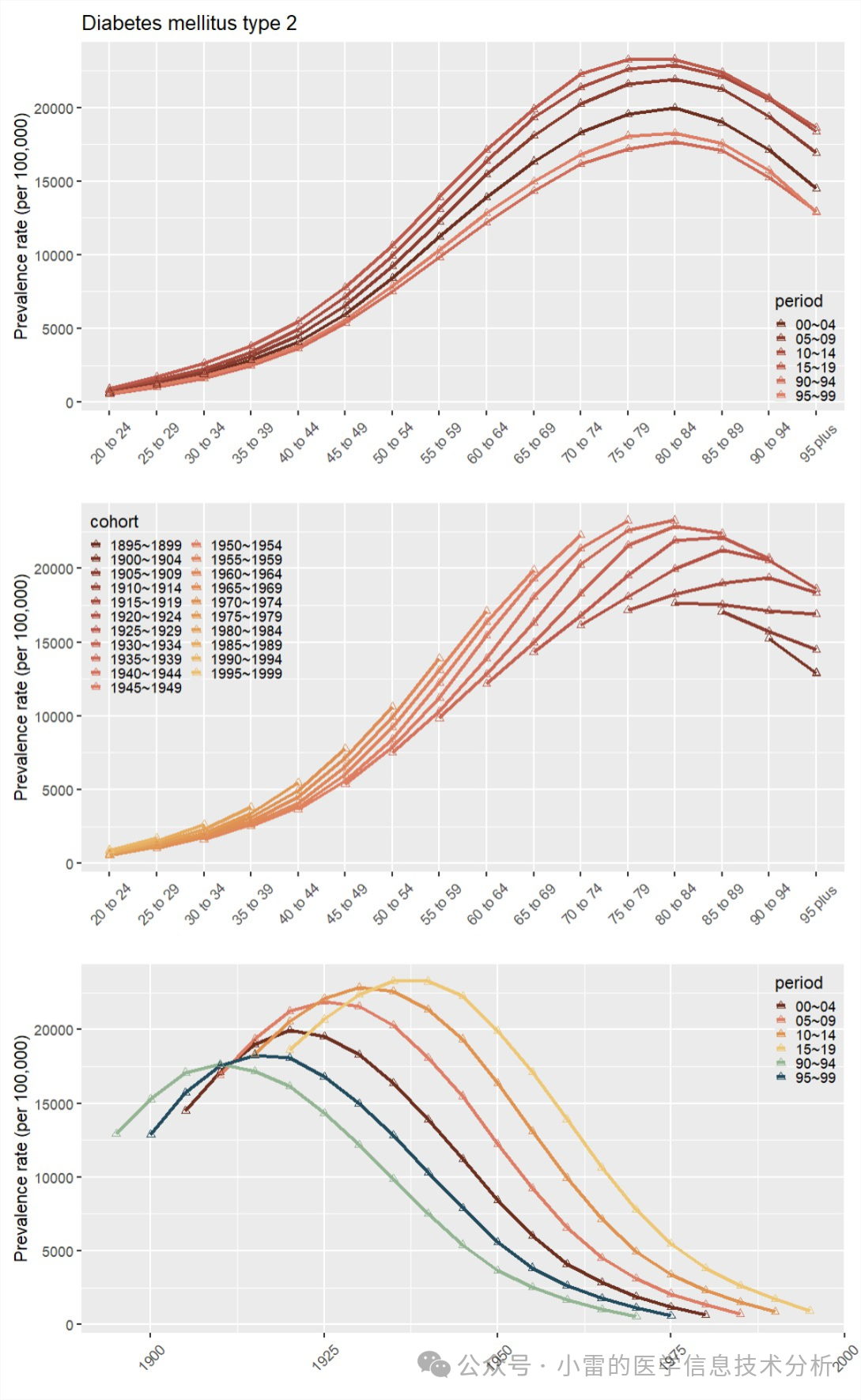
年龄-时期-队列(APC)分析。这个分析其实和分解分析一样,都是一种解释性分析,用来将率的变化分解成各种因素:
分解分析(Decomposition Analysis):解释率的变化来源,包括老龄化、人口因素和生物学因素等:
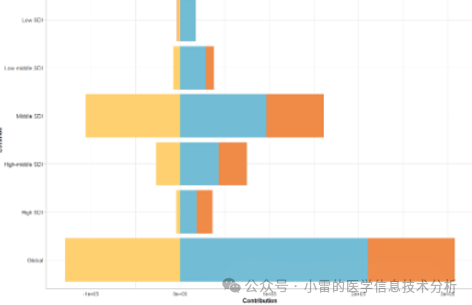
前沿分析(Frontier Analysis):衡量各国家社会发展指数(SDI)与疾病控制情况的关系。
除了之外还有各类高级的数据可视化图形,这个就不在一一介绍。那么该怎么开始学习,首先这里必须要知道的就是GBD各种数据库的概念和指标,这个我们就放在下篇文件进行介绍。
如果您对GBD数据分析感兴趣,可以联系,获取最新的分析流程的分析方法,可添加下方联系方式:

















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









