






 本文介绍了一种名为IP-Adapter的轻量级网络,用于在预训练的文生图模型中实现图片提示控制。通过解耦的交叉注意力机制,IP-Adapter在保持模型性能的同时,解决了微调模型的不足,实现了高效、兼容和泛化的图像生成。
本文介绍了一种名为IP-Adapter的轻量级网络,用于在预训练的文生图模型中实现图片提示控制。通过解耦的交叉注意力机制,IP-Adapter在保持模型性能的同时,解决了微调模型的不足,实现了高效、兼容和泛化的图像生成。
项目链接:https://ip-adapter.github.io
摘要
近年来文生图大模型显现了强大的生成能力,然而仅用文本提示进行生成控制又是棘手的,通常需要使用复杂的提示工程。另外一种选择时使用图片提示,俗话说“一图胜千言”,尽管从现有预训练模型直接微调的方法来制作适配图片提示的模型是可行的,但这一过程需要大量的计算资源,并且与其他基础文生图模型的变体、文本提示以及结构控制都会出现不兼容。本文中,作者提出了一种轻量的适配器网络称为IP-Adapter,用于在预训练好的文生图模型上实现图片提示的能力,该工作的关键是解耦的交叉注意力机制,其分离文本特征和图像特征的交叉注意力层。尽管该方法很简单,但是只有22M参数的IP-Adapter可以获得与完全微调的图像提示模型相当甚至更好的性能。当冻结预训练扩散模型时,IP-Adapter不仅可以推广到同一基础模型的变体上,还可以使用现有的可控工具进行可控生成。利用结构的交叉注意力策略,图像提示也可以与文本提示配合,实现多模态图像生成。
引言
现有的文生图模型都需要复杂的提示词工程才能生成一张符合要求的高质量图片,作者希望可以一种简单的方式使得文生图模型也同样可以支持图片提示的输入。在此之前SD Image Variants以及Stable unCLIP的工作已经尝试了对文生图模型在图片嵌入条件上微调来支持图片提示控制,然而这样微调的方法缺点也很明显:1.减弱了原始模型使用文本控制生成的能力;2.微调后的模型通常是不可复用的,因为图片提示能力不能直接转移到相同的文生图基础模型上派生的其他自定义模型上;3.新的模型也不再能与现有结构控制类工具比如ControlNet等适配。
由于微调的诸多缺点,一些工作试图将文本编码器替换为一个图片编码器来避免微调模型,尽管这一方法也简单有效,但是它也有一些缺点:首先调整后模型无法支持用户同时使用文本和图片提示来进行图像生成,另外仅仅微调图像编码器往往不足以保证图像的质量,可能会导致泛化问题。ControlNet、T2I-adapter、Uni-ControlNet的工作都展示了在现有文生图模型中插入额外网络的形式可以有效指导图像的生成工作,这些工作存在生成图片只能部分忠于提示图片,生成结果往往比微调的图片提示模型要差,更不用说和从头训练的模型相比。
作者认为这些前作的缺点在于文生图模型中的交叉注意力模块,通过训练预训练扩散模型中交叉注意层的键和值投影权值来适应文本特征,因此将图像特征和文本特征合并到交叉注意层中只完成了图像特征与文本特征的对齐,但这可能会遗漏一些特定于图像的信息,最终导致仅使用参考图像进行粗粒度的可控生成(例如图像样式)。
最后作者提出了一个更加有效的图片提示适配器IP-Adapter (Image Prompt Adapter) 来避免先前方法的缺点。具体来说IP-Adapter对文本特征和图像特征采用了解耦的交叉注意力机制,在Stable Diffusion模型的每一个交叉注意力层后面,添加一个额外的图像交叉注意力层,在训练阶段只训练新的交叉注意力层的参数,而原始Unet模型保持冻结。作者提出的IP-Adapter是轻量且高效的,生成效果可以与从文生图模型进行全参数微调的版本想媲美,更重要的IP-Adapter展示了出色的泛化能力,并且可以和文本提示兼容,从而轻松完成各类图像生成任务。
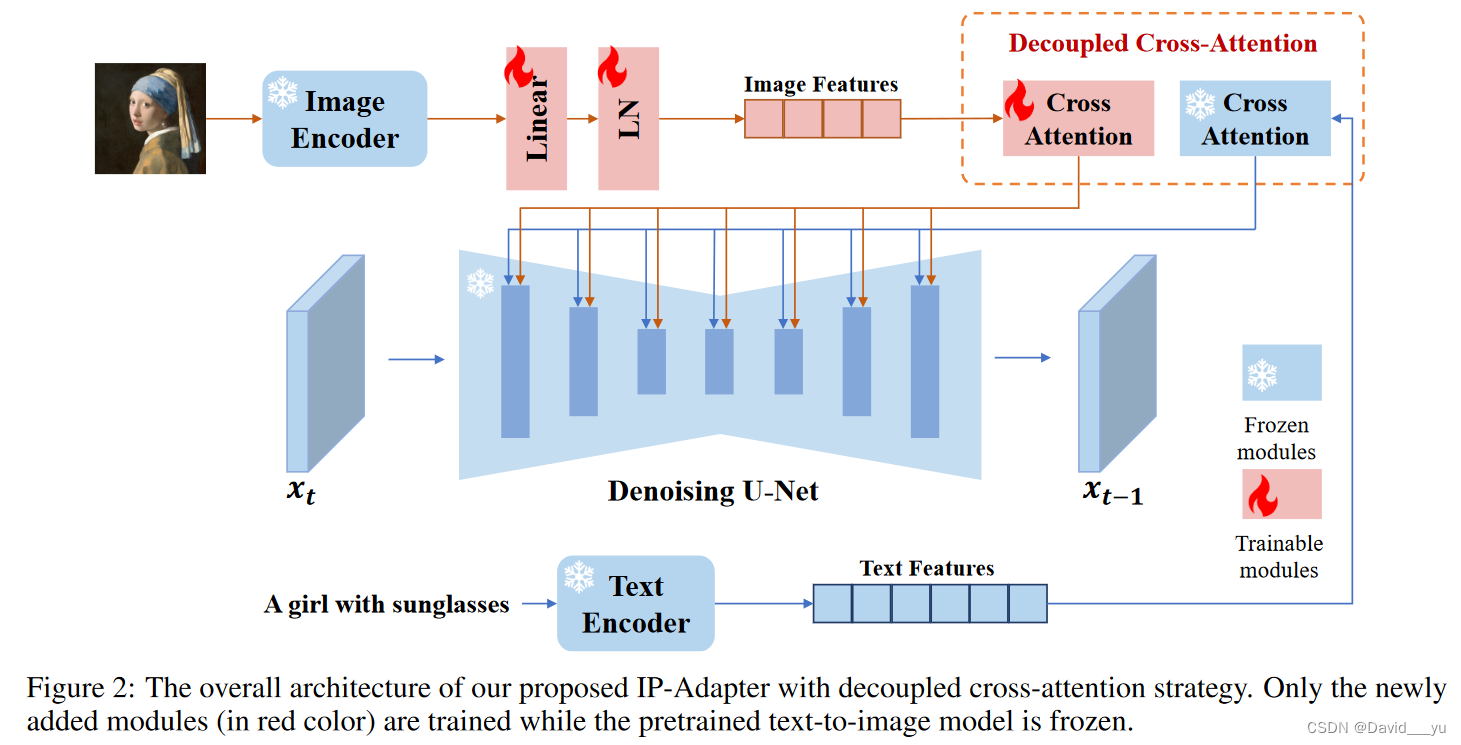
方法
IP-Adapter(Image Promopt Adapter),主要是设计用于预训练的文生图模型可以接受图像图示进行生成。主要包含两个部分:用于从图像提示中获取图像特征的图像编码器和独立的交叉注意力层用于将图像特征注入文生图模型。
图像编码器
和很多方法一样,作者使用了预训练的CLIP图像编码器来作为该工作中的图像编码器,在训练过程中这一部分是不参与训练的,因为CLIP图像编码器本身经过大量数据上的对比学习,具备很好的特征提取能力,其产生的表征能与图片的描述对其并包含丰富的内容和风格。
为了有效分解全局图像嵌入,作者训练了一个小的投影网络来将图像特征转换为一个长度为N的序列特征(工作是采用了N=4)。在预训练扩散模型中,图片特征的维度与文本特征的维度相同。这个投影网络在作者的工作中是由一个线性层和一个层归一化(Layer Normalization)组成的。
解耦交叉注意力
图像特征通过调制模块中的解耦交叉注意力层加入到预训练文生图模型的UNet中,在原始的SD模型中文本特征是经由CLIP文本编码器,再通过交叉注意力层加入到UNet中的:给定一个查询向量Z![]() 和文本特征ct
和文本特征ct![]() ,交叉注意力的输出Z'
,交叉注意力的输出Z'![]() 由下述公式计算得到
由下述公式计算得到![]() ,其中的
,其中的![]() ,
, ![]() ,
, ![]() ,分别表征注意力操作中的query,key,value,Wq
,分别表征注意力操作中的query,key,value,Wq![]() 、Wk
、Wk![]() 和Wv
和Wv![]() 分别是可训练线性投影层的权重矩阵。
分别是可训练线性投影层的权重矩阵。
一个直接的做法是将图像特征和文本特征进行拼接,然后将它们输入给交叉注意力层。然而作者发现这样的方法不够有效,相反他们提出了一个解耦的交叉注意力,使得文本特征和图像特征具有独立的交叉注意力层。
具体的,作者就是在原始Unet的每个交叉注意力层后面都新增加一个交叉注意力层来进行图像特征的注入。给定图像特征 ci![]() ,新的交叉注意力层Z''
,新的交叉注意力层Z''![]() 通过下式计算:
通过下式计算:![]() ,其中其中的
,其中其中的![]() ,
, ![]() ,
, ![]() 是图像特征的query,key和value,W'k
是图像特征的query,key和value,W'k![]() 和W'v
和W'v![]() 是对应的权重矩阵,需要注意的是这里图像特征和文本特征使用了同一个query,所以只需要给每个交叉注意力层添加两个额外的参数W'k
是对应的权重矩阵,需要注意的是这里图像特征和文本特征使用了同一个query,所以只需要给每个交叉注意力层添加两个额外的参数W'k![]() 和W'v
和W'v![]() ,为了加快收敛,W'k
,为了加快收敛,W'k![]() 和W'v
和W'v![]() 初始化使用Wk
初始化使用Wk![]() 和Wv
和Wv![]() 的权重,然后简单的将图像交叉注意力的输出添加到文字交叉注意力的结尾。因此最终的解耦交叉注意力就表达为以下的形式:
的权重,然后简单的将图像交叉注意力的输出添加到文字交叉注意力的结尾。因此最终的解耦交叉注意力就表达为以下的形式:![]() ,训练过程中Unet模型是固定的,只训练W'k
,训练过程中Unet模型是固定的,只训练W'k![]() 和W'v
和W'v![]() 。
。
训练和推理
在训练中作者只优化IP-Adapter的参数,同样适用图像文本对数据进行训练,在训练中随机丢弃图像编码来使得前向时可以执行classifier-free guidance,丢弃图像编码的操作是通过将CLIP图片编码置零来实现的。当文本交叉注意力和图像交叉注意力分离后,在推理阶段可以调整图像编码的权重:Znew=AttentionQ,K,V+λ•Attention(Q,K',V')![]() ,当λ变成0时则退化为原始的文生图模型。
,当λ变成0时则退化为原始的文生图模型。
实验
为了训练IP-Adapter,作者构建了一个多模态数据集,包含从两个开源数据集(LAION-2B、COYO-700M)中选取的一千万个图文数据对。
作者实验中使用了SD1.5,使用OpenCLIP ViT-H/14作为图像编码器。在Stable Diffusion中有16个交叉注意力层,作者在这些交叉注意力层后添加了新的图像交叉注意力层。IP-Adapter中的全部可训练参数包含映射网络和调制模块,总参数量为22M。作者在实验中使用了diffusers库并使用了DeepSpeed ZeRO-2用于快速训练。IP-Adapter在单台8卡V100 GPU上进行训练,每张卡上的batch size为8,一共训练了100万步,作者使用了AdamW优化器,并使用固定的学习率0.0001以及0.01的权重衰减。在训练的时候,作者将图片的最短边缩放到512,然后对图像进行中心裁剪得到512x512的图像。开启了CFG,设置0.05的概率丢弃文本和图像中的一个,以及0.05的概率同时丢弃文本和图像。在推理过程中作者采用DDIM采样50步,设置CFG系数为7.5,当只使用图像提示时,设置文本提示为空并将λ设置为1.0。
本文提出的IP-Adapter与其他方法在COCO验证集上的定量比较

IP-Adapter只需一次训练即可用在同一文生图模型的派生模型上

作者实验了IP-Adapter与其他结构控制类工作如ControlNet等进行配合,共同控制图像,由IP-Adapter进行图像提示的添加,结构类控制网络进行生成结果的控制。

作者比较了和其他的一些支持图片提示方法的对比:

作者也展示了IP-Adapter用在图生图模型以及Inpainting模型上的表现:

以下是展示了多模态(文本+图片)控制生成的表现:

也做了和其他一些支持多模态控制方法的比较:

同时作者还比较了使用解耦交叉注意力和简单叠加形式(图片embedding连接在文本embedding后一起进行交叉注意力)交叉注意力的效果差别:

由于使用了CLIP图片编码器的全局图像embedding,这可能会失去参考图的一些信息,作者还比较了使用CLIP和使用CLIP加上一个小图像编码网络补充细节后的结果:

作者发现过多的图像embedding加入后会让最终结果和图片提示更接近,但可能会引入额外的结构控制。
点评
IP-Adapter的工作是非常有意义的,它引入了一个轻量的Adapter网络,仅仅需要额外训练多一倍的交叉注意力层,就可以实现很好的图像提示,而且这一添加还可以在前向时关闭,同时具备泛化能力,对于后续InstantID等工作都有很好的指导作用,也让我们思考可以使用添加额外交叉注意力层的形式来进行更多模态的加入,非常有意义。

















 1754
1754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









