






 论文介绍了华中科技大学等机构研发的VisionMamba,一种基于Mamba架构的视觉模型,通过双向状态空间模型提高处理长序列和高分辨率图像的效率,对比Transformer模型在性能和内存消耗上有显著优势。
论文介绍了华中科技大学等机构研发的VisionMamba,一种基于Mamba架构的视觉模型,通过双向状态空间模型提高处理长序列和高分辨率图像的效率,对比Transformer模型在性能和内存消耗上有显著优势。
Mamba是LLM的一种新架构,与Transformers等传统模型相比,它能够更有效地处理长序列。就像VIT一样现在已经有人将他应用到了计算机视觉领域,让我们来看看最近的这篇论文“Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Models,”

对于VIT来说,Transformers虽然功能强大,但通常需要大量的计算资源,特别是对于高分辨率图像。Vision Mamba旨在通过提供更有效的替代方案来解决这个问题。
Vision Mamba vs Transformers
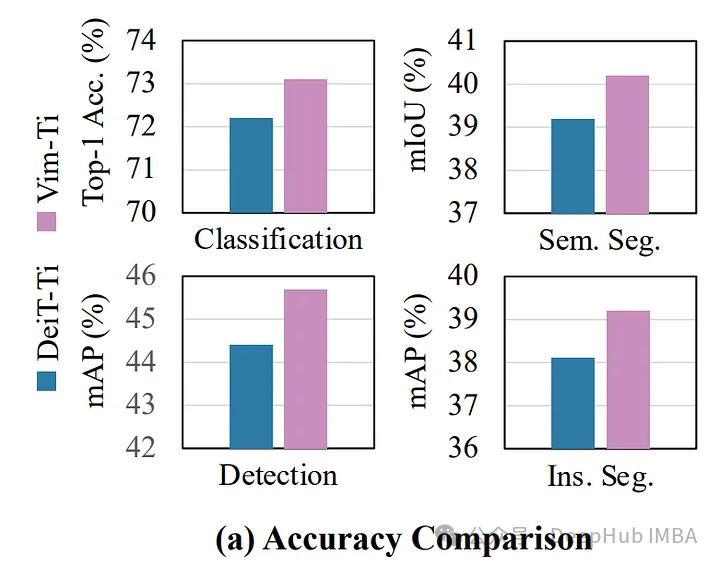
这篇论文主要由华中科技大学、地平线机器人、北京人工智能研究院的研究人员贡献,深入研究了Mamba 是如何处理视觉任务的。Mamba的效率来自于它的双向状态空间模型,与传统的Transformer模型相比,理论上可以更快地处理图像数据。
处理图像本质上比处理文本要复杂得多。因为图像不仅仅是像素的序列;它们还包含复杂的模式,变化的空间关系,以及理解整体环境的需要。这种复杂性使得视觉数据的有效处理成为一项具有挑战性的任务,特别是在规模和高分辨率下。
Vision Mamba (Vim)
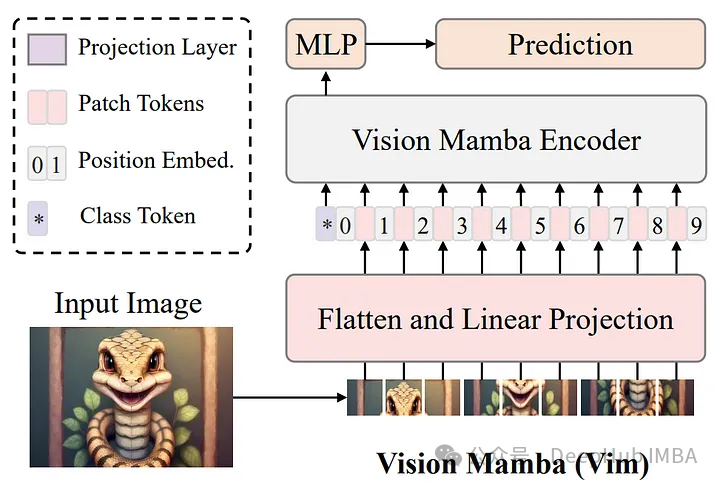
Mamba块是Vim的一个关键特性,通过使用位置嵌入标记图像序列,并使用双向状态空间模型压缩视觉表示,Vision Mamba可以有效地捕获图像的全局上下文。这种方法解决了可视数据固有的位置敏感性,这是传统Transformer模型经常遇到的一个关键问题,特别是在更高分辨率下。
Vision Mamba Encoder
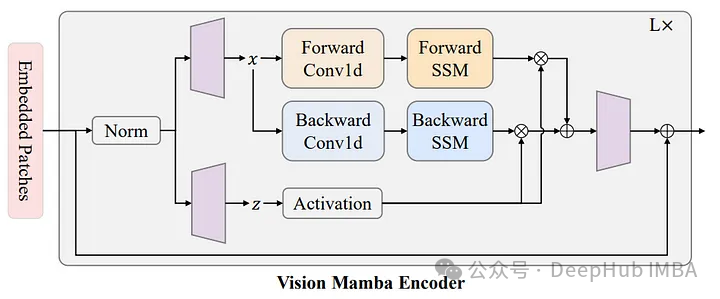
Vim模型首先将输入图像划分为小块,然后将小块投影到令牌中。这些令牌随后被输入到Vim编码器中。对于像ImageNet分类这样的任务,在令牌标记序列中添加了一个额外的可学习分类标记(这个标记是重BERT开始一致这样使用的)。与用于文本序列建模的Mamba模型不同,Vim编码器在正向和反向两个方向上处理标记序列。
还记得双向LSTM么,Vim的一个突出特点是它的双向处理能力。与许多以单向方式处理数据的模型不同,Vim的编码器以向前和向后的方向处理标记。双向模型允许对图像上下文进行更丰富的理解,这是准确图像分类和分割的关键因素。
基准测试结果及表现
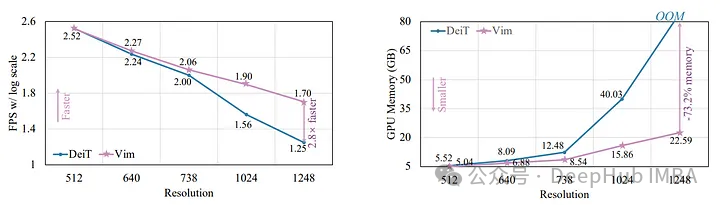
在ImageNet分类、COCO对象检测和ADE20K语义分割方面,Vim不仅表现出更高的性能,而且还表现出更高的效率。例如,在处理高分辨率图像(1248 × 1248)时,Vim比DEIT快2.8倍,同时节省了86%的GPU内存。考虑到在高分辨率图像处理中经常遇到的内存限制,这是一个非常大的进步。
与VIT的比较分析
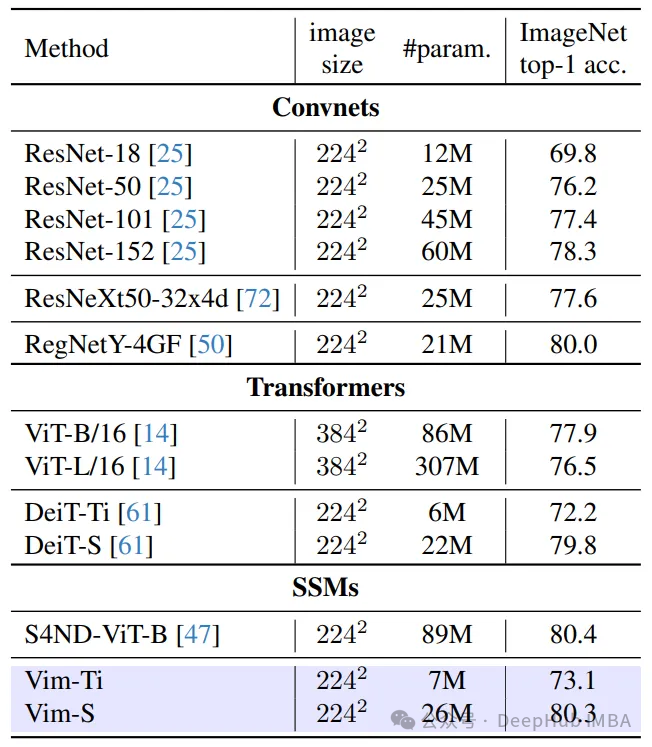
这篇论文并没有仅仅停留在比较VIM和DEIT。它还包括与VIT的比较。虽然VIT确实是一个强大的模型,但VIM在效率和性能上仍然超过它,特别是随着分辨率的增加。这种比较为评估VIM的能力提供了更广泛的背景。
高分辨率图像处理
论文还强调了高分辨率图像处理在各个领域的重要性。例如在卫星图像中,高分辨率对于详细分析和准确结论至关重要。同样在PCB制造等工业环境中,在高分辨率图像中检测微小故障的能力对于质量控制至关重要。VIM在处理此类任务方面的也非常有可比性。
总结
论文介绍了一种将Mamba用于视觉任务的方法,该方法利用双向状态空间模型(ssm)进行全局视觉上下文建模和位置嵌入。这种方法标志着传统的注意力机制可能会退出历史的舞台,因为VIM展示了一种有效的方法来掌握视觉数据的位置上下文,而不需要基于transformer的注意机制。
VIM以其次二次的时间计算和线性内存复杂性与Transformer模型中典型的二次增长形成鲜明对比。这一点使得VIM特别适合处理高分辨率图像。
通过对ImageNet分类等基准的全面测试,验证了VIM的性能和效率,证明可以将其应用在计算机视觉领域强大模型的地位。
论文地址:
https://avoid.overfit.cn/post/7171ae82866d4b07853266073485e8cb
作者:azhar

















 2397
2397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









