







最近在更新 Transformer 的技术专栏,如果你关注我的公众号的话,会发现有不少文章都打上了“Transformer最后一公里”的标签。
打上标签的文章要么是介绍 Transformer 技术的,要么是介绍学习Transformer 所需要的背景知识的,比如这几篇:什么是token、编码器-解码器架构、RNN、注意力机制等。
有不少朋友可能听说过 Transformer,但是也仅限于听说过,并不太深入了解这个技术。
Transformer 中文可以翻译为变形金刚,可以说该技术顶起了现在大模型的半边天,非常的重要。

接下来,我会用3-5篇文章的篇幅,通俗的解读提出 Transformer 这一技术的划时代论文《Attention is all you need》,论文链接在这里:https://arxiv.org/pdf/1706.03762。
在解读过程中,我不会逐字逐句的进行翻译,而是会挑出重点来进行解读,以帮助你更好的理解提出 Transformer 时的背景以及当时作者的思路。
在解读过程中我会将原文一并放上,方便你阅读原文并理解原意。
本节解读论文的摘要/引言和背景部分。
1.摘要
论文的摘要写的非常简洁明了。主要介绍了当时论文写作的背景,并提出 transformer 这一架构,同时给出了基于 Transformer 架构的模型在一些经典任务中性能数据。
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism.
这一段是说,在写这篇论文时,已经由很多序列模型了,比如之前介绍的Seq2Seq结构,这些模型都是基于复杂的循环神经网络或者卷积神经网络而来的,并且他们都包含一个编码器和解码器。
在一些表现好的模型中,还会在编码器和解码器之间引入注意力机制。
We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 Englishto-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
基于第一段的背景,作者提出了一种全新的神经网络架构,叫做Transformer(变形金刚),该结构不再使用循环结构(RNN)和卷积结构(CNN),而是完全依赖注意力机制运行。
并且作者在一些典型的机器翻译任务上做了实验,实验结果显示基于 Transformer 结构的模型效果非常好(当然好,要不然也不会这么火🔥)。
2.引言
Recurrent neural networks, long short-term memory and gated recurrent neural networks in particular, have been firmly established as state of the art approaches in sequence modeling and transduction problems such as language modeling and machine translation. Numerous efforts have since continued to push the boundaries of recurrent language models and encoder-decoder architectures.
循环神经网络(RNN)、长短时记忆网络(LSTM)以及门控循环神经网络(GRU),这些经典的神经网络在处理序列任务(比如语言建模和机器翻译)中都已经表现出了非常好的效果。
论文中描述效果非常好一般用 state of the art 来描述,它有一个更为常见的缩写是 SOTA。
你可以这样理解 SOTA:
某个模型在某项任务中表现最好,这是和其他的模型在相同的任务中进行横向对比之后得出的结论,一般而言如果你说你的模型在某个任务中 SOTA,那就可以说世界范围内数一数二了。
这些经典的神经网络在很多时序任务中表现好,但是对于学术界而言,只有更好没有最好。
因此,人们一直在不断地探索基于RNN 的 Encoder-Decoder 模型的创新,试图一步步的突破这种模型的使用边界,使其变得更好。
Recurrent models typically factor computation along the symbol positions of the input and output sequences. Aligning the positions to steps in computation time, they generate a sequence of hidden states ht, as a function of the previous hidden state ht−1 and the input for position t. This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples. Recent work has achieved significant improvements in computational efficiency through factorization tricks and conditional computation, while also improving model performance in case of the latter. The fundamental constraint of sequential computation, however, remains.
接下来的这一段其实就表达了一个意思:循环神经网络(RNN) 在执行过程中是顺序执行的,无法进行并行计算,这是它的一个缺点。
怎么理解顺序执行的呢?
以编码器为例,当输入是一个句子时,基于RNN的编码器只有处理完第一个单词,才能继续编码处理第二个单词。
这是因为编码第二个单词时(ht)依赖上一时刻编码的隐藏状态(ht-1),正是这种顺序执行的过程,才使得 RNN 可以学到一个句子的历史信息。
以下面的图为例,模型只有处理完“今天”这个词之后,才能处理“是”这个词,因此模型是顺序执行的。
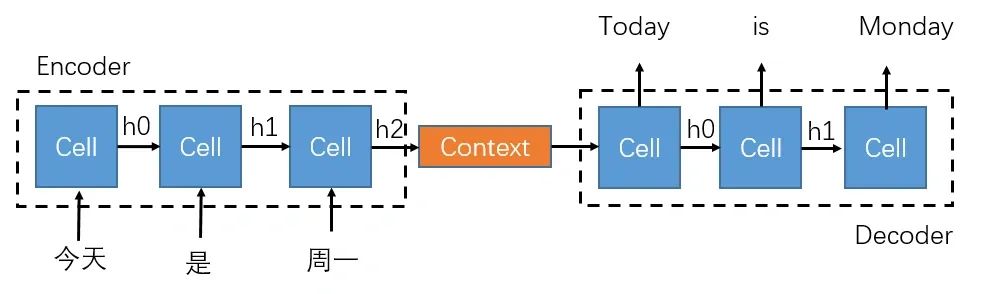
虽然顺序执行很有效,但同样缺点也十分明显:无法并行计算,也就无法发挥出 GPU 这种多核(多线程)架构处理器的并行计算能力,导致模型的计算性能较差。
尽管人们在基于RNN 的编码器-解码器结构上做了很多创新,但是依然改变不了这种顺序执行的本质。
Attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences. In all but a few cases, however, such attention mechanisms are used in conjunction with a recurrent network.
这一段是说在 RNN 中引入了注意力机制的好处,主要就是解决了长文本输入导致的信息丢失的问题。
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output.
The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.
在作者提出的 Transformer 架构中,不再使用 RNN 这种循环结构,转而仅依靠注意力机制来完成数据之间的特征捕捉。
作者在使用了8 个 P100 GPU,并且花费了12个小时的训练后,就在文本翻译任务中取得了 SOTA 的效果。
整体而言,论文的摘要和引言部分写的非常简单,主要就概括了传统RNN和编码器-解码器的缺点。这些缺点主要是有两个:
-
RNN 无法完成并行计算
-
RNN 无法解决长文本输入导致信息丢失的问题
既然RNN有那么多问题不好解决,那我不用不就行了,于是作者直接摒弃了 RNN,提出了新的 Transformer 架构,该架构仅依赖注意力机制,也就不存在上述两个问题了。
可以说,Transformer 架构是对于传统基于RNN的编码器-解码器架构的一次重大创新。
3. 背景
背景部分作者写的也非常简洁,只有3段内容。
The goal of reducing sequential computation also forms the foundation of the Extended Neural GPU , ByteNet and ConvS2S, all of which use convolutional neural networks as basic building block, computing hidden representations in parallel for all input and output positions. In these models, the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet. This makes it more difficult to learn dependencies between distant positions. In the Transformer this is reduced to a constant number of operations, albeit at the cost of reduced effective resolution due to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention as described in section 3.2.
如果你刚开始阅读这一段的话,可能非常难以理解。
在引言部分作者不是提到了传统的 RNN 计算非常难以并行吗?而在常见的AI算法中,好并行计算的一个经典算法是卷积。事实上,人们使用卷积神经网络做了很多的工作,目的就是减少顺序计算的带来的开销,使计算变成并行计算。
但是卷积有个弊端,那就是卷积核一次只能处理局部范围内的数据。
对于一个长输入文本而言,卷积无法学到卷积核之外的数据之间的关系。因此,如果想处理序列数据(如文本)的话,使用卷积是不行的(效果不好)。
但是,卷积之所以可以很好的完成并行计算,是因为每个卷积核是独立在输入特征图上进行运算的,一个卷积核会输出一个通道,一个通道就代表了输入数据的一种特征。
那是否可以仿照卷积的这种特性,设计一种机制来模仿多个卷积核独立计算的这种特性呢?
当然可以,作者提出了一种多头注意力机制(Multi-Head Attention),模仿的就是多个卷积核的作用。
每个"头" 说白了就是一个独立的注意力小网络,每个小网络都会独立的学习到输入数据的某种特征,如此一来,多个"头"之间就可以并行进行计算了。
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence. Self-attention has been used successfully in a variety of tasks including reading comprehension, abstractive summarization, textual entailment and learning task-independent sentence representations . End-to-end memory networks are based on a recurrent attention mechanism instead of sequencealigned recurrence and have been shown to perform well on simple-language question answering and language modeling tasks.
第二段主要就夸了一下作者使用的“自注意力机制“,该机制在很多已有工作中表现非常好。在写这篇论文时,自注意力实际上已经应用在了很多模型和任务中,也并非作者原创,但是作者感觉这个机制非常好用。
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequencealigned RNNs or convolution. In the following sections, we will describe the Transformer, motivate self-attention and discuss its advantages over models.
最后一段,作者继续夸自己的成果:Transformer 是第一个仅仅依赖自注意力机制,而不采用RNN和CNN的Seq2Seq模型。
它的优势非常多,你感兴趣的话就往下阅读吧,记得查看文章左下角的标签,阅读全部文章哦。
后续文章:
《Attention is all you need》通俗解读,彻底理解版:part2-CSDN博客

我的技术专栏已经有几百位朋友加入了。
如果你也希望了解AI技术,学习AI视觉或者大语言模型,戳下面的链接加入吧,这可能是你学习路上非常重要的一次点击呀
最后,送一句话给大家:生活不止眼前,还有诗和远方,共勉~



















 4208
4208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











