







Yu, J., Chen, N., Gao, M., Li, X., & Wong, K.-C. . (2024). Unsupervised Gene-Cell Collective Representation Learning with Optimal Transport. Proceedings of the AAAI Conference on Artificial Intelligence, 38(1), 356-364. https://doi.org/10.1609/aaai.v38i1.27789
这篇论文和论文阅读:ZINB-Based Graph Embedding Autoencoder for Single-Cell RNA-Seq Interpretations-CSDN博客以及论文阅读:Unsupervised Deep Embedded Fusion Representation of Single-Cell Transcriptomics (AAAI-23)-CSDN博客
有共同作者,研究方向一致,可以一起学习一下。
摘要
细胞类型识别在单细胞RNA测序(scRNA-seq)数据分析中起着至关重要的作用。尽管已经提出了许多用于聚类scRNA-seq数据的深度嵌入方法,但它们仍然未能揭示细胞和基因的内在特性。本文提出了一种新颖的端到端深度图聚类模型,scGCOT(a novel end-to-end deep graph clustering model for single-cell transcriptomics data based on unsupervised Gene-Cell collective representation learning and Optimal Transport ),它整合了细胞和基因的相关性。具体而言,scGCOT同时学习细胞和基因的潜在嵌入,并重建细胞图、基因图和基因表达计数矩阵。通过估计重构的计数矩阵中的零膨胀负二项(ZINB)模型,捕捉scRNA-seq数据的基本属性。通过利用基于最优输运的联合表示对齐,scGCOT通过一种相互监督的自我优化策略学习聚类过程和潜在表示。在15个真实的scRNA-seq数据集上,与14种竞争方法的广泛实验表明了scGCOT的竞争优势。
动机及创新点
考虑了基因之间的相关性。将基因相关性和细胞相关性结合在一起。
贡献
- 提出了一种名为scGCOT的深度图嵌入模型,用于在scRNA-seq数据上进行细胞类型识别。
- scGCOT还考虑了基因之间的相关性。据作者所知,scGCOT是第一个将基因相关性和细胞相关性结合在一起的架构。
- ZINB分布以无缝方式估计,以捕捉数据的基本属性。
- 使用最优输运理论进行联合表示对齐,可以持续优化聚类分配。
- 在15个真实的scRNA-seq数据集上,将scGCOT与十几种竞争方法进行了比较。实验结果表明,scGCOT优于所有其他基线方法。
方法
1、预处理
作者采取的方法于论文阅读:ZINB-Based Graph Embedding Autoencoder for Single-Cell RNA-Seq Interpretations-CSDN博客相同。
2、细胞图和基因图
给定经过预处理的scRNA-seq基因表达数据$ X \in \mathbb{R}^{M \times n} $,其中$ X_{ij} $表示第$i$个细胞中第$j$个高变异基因的表达计数,首先构建细胞相关图。类似于以前的工作,如论文阅读:ZINB-Based Graph Embedding Autoencoder for Single-Cell RNA-Seq Interpretations-CSDN博客,使用KNN算法构建细胞图$ G_c $,图中的每个节点代表一个细胞。具体来说,如果a是b在前K个最短距离内的邻居,则节点a和节点b之间存在一条边。随后,作者使用相同的方法基于$ X^T $构建基因相关图$ G_g $,其中$ (X^T)_{ij} $表示第$j$个细胞中第$i$个基因的表达计数。构建基因相关图在$ X^T $上是基于生物学直觉的:一些基因可能在多种类型的细胞中表达,而另一些则不表达,因此$ X^T $可以被视为每个基因的细胞表达谱。
3、基于注意力机制的图自编码器
由于单细胞RNA测序数据本质上存在噪音(Grün、Kester和Van Oudenaarden 2014),因此可以推断出,相关图中许多边可能连接不正确。因此,需要注意力机制来确保获得图结构的准确信息。为了捕捉细胞图和基因图中精确的内在结构和节点特征,我们基于Graph Transformer(Shi等人2020)开发了两个基于注意力机制的图自编码器,用于细胞和基因表示学习。基因表达矩阵$ X $和细胞表达概况$ X^T $以及它们对应的邻接矩阵$ A_c $和$ A_g $被用作输入。
对于细胞图自编码器的学习,考虑到图编码器具有 L 层,作者假设每个节点的隐藏维度为 dl,这意味着第 l 层的输入数据为 \( x_i^{(l)} \in \mathbb{R}^{d_l} \)。然后,细胞图编码的过程定义如下:
\[ y_i^{(l)} = W_1 x_i^{(l)} + \sum_{j \in N(i)} \alpha_{i,j} W_2 x_j^{(l)}, \]
这里 \( y_i^{(l)} \) 表示细胞图编码器的第 l 个输出特征图;\( W_1 \) 和 \( W_2 \) 是编码器层的可学习权重;注意力系数 \( \alpha_{i,j} \) 通过点积注意力计算得到:
\[ \alpha_{i,j} = \text{softmax} \left( \frac{{(W_3 x_i^{(l)})^T (W_4 x_j^{(l)})}}{{\sqrt{d_l}}} \right), \]
这里 \( W_3 \) 和 \( W_4 \) 是注意力计算的可学习权重。在每次图注意力计算之后,将非线性激活函数应用于输出 \( y_i^{(l)} \):
\[ x_i^{(l+1)} = \sigma(y_i^{(l)}), \]
其中 \( \sigma(\cdot) = \max(0, x) \) 表示 ReLU 函数。为了简化方程,作者将细胞图编码器的计算缩写为:
\[ Z_c = f_1^E(X). \]
理想情况下,细胞之间的内在相关性应该在潜在嵌入空间中得到保留,因此,作者通过简单地组合一个全连接层和一个自身内积来定义解码器部分,如下所示:
\[ \hat{Z}_c = W_c Z_c + b_c, \]
\[ \hat{A}_c = \phi(\hat{Z}_c^T \hat{Z}_c), \]
这里,\( \hat{A}_c \) 是细胞相关图的重构邻接矩阵;\( \phi(\cdot) \) 是Sigmoid激活函数。为了约束学习过程,计算重构邻接矩阵 \( \hat{A}_c \) 与细胞图原始邻接矩阵 \( A_c \) 之间的均方误差损失作为重构损失:
\[ L_c = ||A_c - \hat{A}_c||_2^2. \]
类似地,作者使用与细胞图自编码器相同结构的基因图自编码器进行基因表示学习,记为 \( f_2^E \)。然后,自编码器给出的基因潜在空间被表述为:
\[ Z_g = f_2^E(X^T). \]
基因相关图的重构邻接矩阵以与细胞解码器相同的方式获得:
\[ \hat{Z}_g = W_g Z_g + b_g, \]
\[ \hat{A}_g = \phi(\hat{Z}_g^T \hat{Z}_g). \]
然后,计算基因自编码器的重构损失来约束学习过程:
\[ L_g = ||A_g - \hat{A}_g||_2^2. \]
4、基于ZINB的基因-细胞集体表示学习解码器
为了捕获基因-细胞表达计数矩阵 X 的全局结构,作者在 scGCOT 中集成了一个解码器,利用潜在特征嵌入 Z_g 和 Z_c 来更好地获取 scRNA-seq 数据的结构。首先,让潜在表示 Z_g 和 Z_c 通过它们的内积共同重构原始基因表达矩阵 X,并计算重构损失:
\[ \hat{X} = Z_c^T Z_g, \]
\[ L_r = ||X - \hat{X}||_2^2. \]
单细胞RNA测序基因表达计数矩阵基本上具备三个特征:1)离散;2)方差大于均值;3)许多条目为零值。这些特征可以被建模为零膨胀负二项(ZINB)分布。形式上,ZINB以均值 µ 和负二项分布的离散参数 θ 作为基础,并附加了一个表示scRNA-seq数据辍学事件概率的额外系数 π:
\[ \text{ZINB}(X|\pi, \mu, \theta) = \pi\delta_0(X) + (1 - \pi) \times \frac{{\Gamma(X + \theta)}}{{X!\Gamma(\theta)}} \times \left( \frac{\theta}{{\theta + \mu}} \right)^\theta \times \left( \frac{\mu}{{\theta + \mu}} \right)^X \]
其中,µ 和 θ 分别代表负二项分布的均值和离散参数;π 表示零组分的权重。为了捕获scRNA-seq数据的特征,作者假设重构后的 ˆX 也遵循 ZINB 分布。ZINB 分布的三个参数 µ、θ 和 π 通过构建三个并行输出的全连接层进行估计:
\[ \hat{\pi} = \text{sigmoid}(W_\pi \hat{X}), \]
\[ \hat{\theta} = \exp(W_\theta \hat{X}), \]
\[ \hat{\mu} = \exp(W_\mu \hat{X}), \]
其中,Wπ、Wθ 和 Wµ 是三个参数估计器的相应权重;激活函数的选择取决于三个参数的范围和定义:由于 π 表示零点质量的权重,在 [0, 1] 范围内,sigmoid 函数被选择用于估计 \(\hat{\pi}\);鉴于参数 µ 和 θ 的非负特性,作者使用指数函数。随后,ZINB 参数估计的损失函数定义为 ZINB 分布的负对数似然函数:
\[ L_z = -\log(\text{ZINB}(X|\hat{\pi}, \hat{\theta}, \hat{\mu})). \]
5、基于最优传输(OT)的联合表示对齐
为了增强聚类分配的表示,作者引入了一种新的方法,称为相互监督的自优化策略,利用了 OT 的优势。这种策略持续地对齐聚类分布和辅助分布,从而优化聚类过程。作者将聚类分布称为 Q,将辅助分布称为 P,与 (Xie, Girshick, and Farhadi 2016) 中一样。为了量化潜在嵌入 Zc 的聚类分布,作者将 Q 中的一个元素 qiu 定义为:
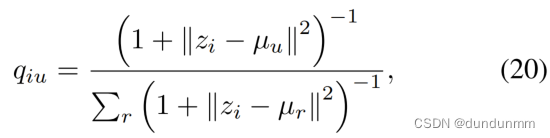
在作者的方法中,每个细胞 i 都由其潜在表示 zi 表示,而 μu 则表示通过谱聚类生成的伪标签得到的簇中心表示,给定簇数 r。为了确保高置信度数据点的突出性,引入了基于 qiu 的辅助分布 P,其定义如下:
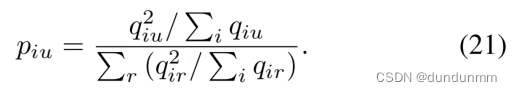
此外,作者将分布 Q 和 P 之间的差异表示为熵正则化 OT 问题,其形式化如下:
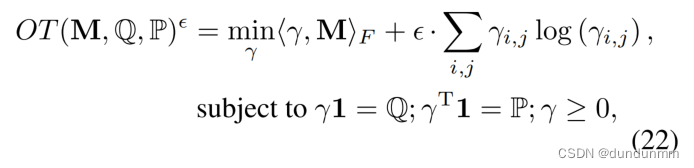
在这里,M 表示从分布 Q 到 P 的运输成本矩阵,简单定义为欧氏距离,而从 Q 到 P 的运输量是 γ;ϵ 是控制熵正则化项的正则化参数。OT 的目标是在边缘约束的情况下最小化期望的运输成本。最后,作者利用 Sinkhorn 散度 (Genevay, Peyré, and Cuturi 2018) 来对齐两个有限离散分布。Sinkhorn 散度,记为 Ls,定义如下:
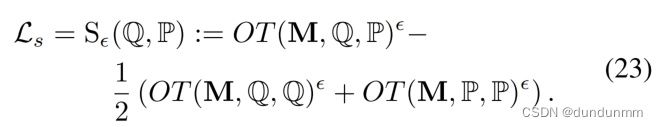
这里,辅助分布 P 基于 Q,并且期望 Q 与 P 对齐以优先处理高置信度数据点。作者持续优化此对齐直到达到最大迭代次数。
6、整体训练过程
scGCOT 的整体训练过程包含两个阶段,即嵌入学习阶段和表示对齐与聚类分配阶段。在嵌入学习阶段,用于训练的损失函数定义为:
\[ L1 = \lambda_1 Lc + \lambda_2 (Lg + Lr) + \lambda_3 Lz, \]
其中 λ1、λ2、λ3 是每个损失的权重系数。在 scGCOT 学习了一定数量的周期的潜在嵌入后,它转向表示对齐和聚类分配阶段,其中损失函数根据 (Kendall, Gal, and Cipolla 2018) 进行组合:
\[ L2 = \lambda'_1 Lc + \frac{1}{2\sigma_1^2} Lz + \frac{1}{2\sigma_2^2} Ls + \log(\sigma_1 \sigma_2), \]
其中 σ1 和 σ2 是用于平衡损失 Lz 和 Ls 的两个参数。
实验
1、实验数据
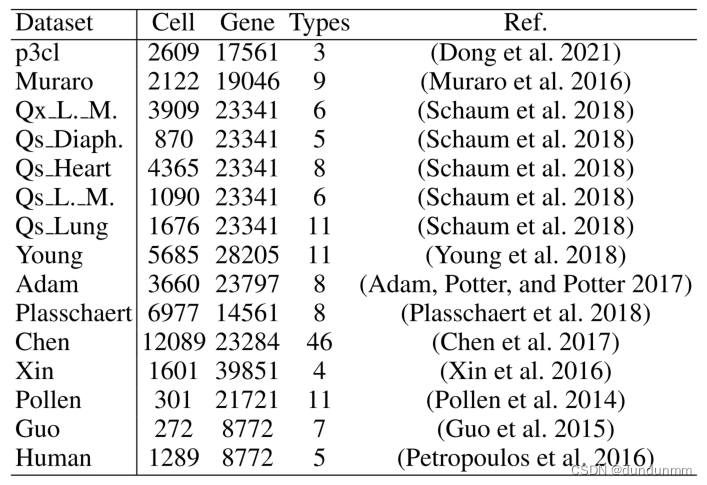
2、实验设置
所有实验均在配备128GB内存和两块RTX 4090 GPU的Ubuntu 20.04服务器上进行。所提出的scGCOT是基于PyTorch 2.0.0、PyG 2.3.0和Python 3.10.11构建的。在所提出的scGCOT方法中,使用最近邻参数K = 15和高度可变基因数量n = 500构建细胞图和基因图的KNN算法。在图自编码器中,f1E和f2E均设置为具有128和15的隐藏维度的两层图转换器网络。用于获取ˆZc和ˆZg的全连接网络的输出维度均设置为32。还有一些超参和学习率的设置,具体见论文。其他基准方法的参数保持默认设置。
3、实验结果
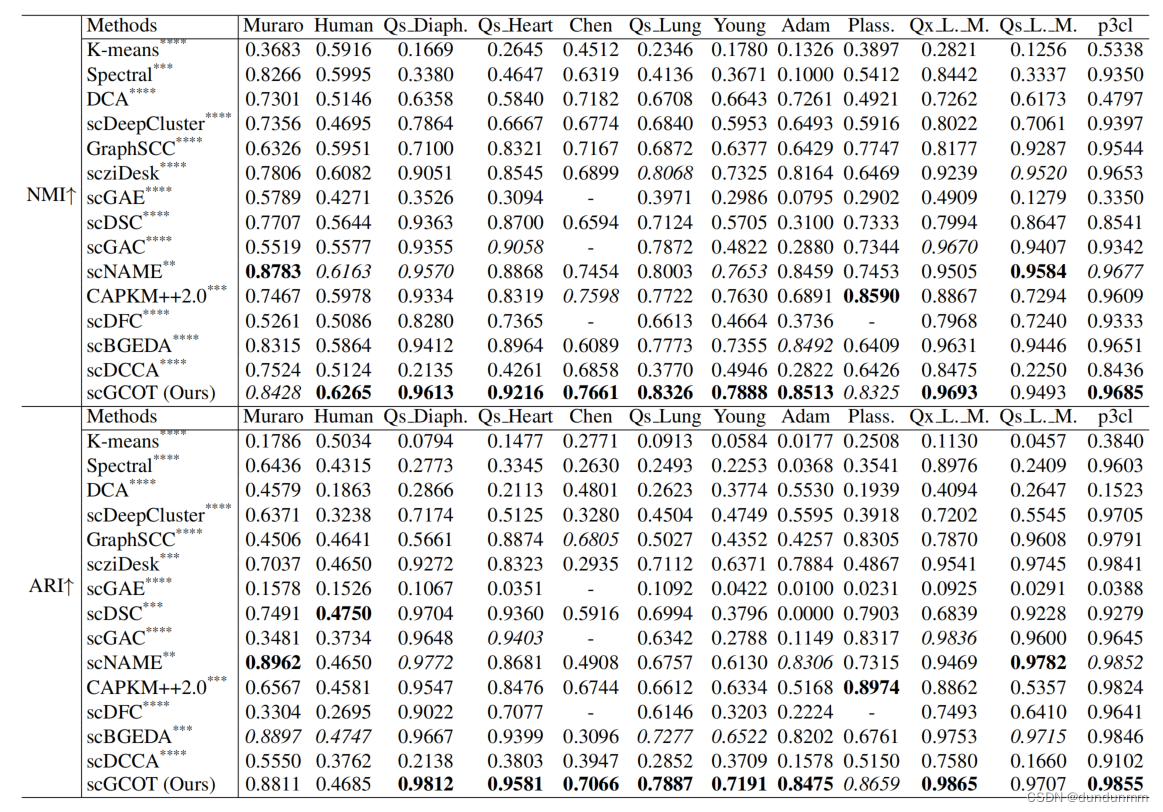
基因-细胞
学习了,创新点的选择太重要了。。。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









