







M. Xiao, D. Wang, M. Wu, P. Wang, Y. Zhou and Y. Fu, "Beyond Discrete Selection: Continuous Embedding Space Optimization for Generative Feature Selection," 2023 IEEE International Conference on Data Mining (ICDM), Shanghai, China, 2023, pp. 688-697, doi: 10.1109/ICDM58522.2023.00078.
keywords: {Training data;Transforms;Feature extraction;Robustness;Decoding;Task analysis;Optimization;Automated Feature Selection;Continuous Space Optimization;Deep Sequential Learning},
论文代码:https://www.dropbox.com/sh/vlwz16cquv5ct9d/AACvhlDRwBe3f4nWwGEE4zeCa?dl=0
摘要
特征选择的目的是为指定的下游任务寻找最优的特征子集。然而,当前的特征选择方法受到两点制约:1)这些方法在不同领域的选择标准不同,难以推广;2)当处理高维特征空间和小样本量时,这些方法的选择性能明显下降。鉴于这些挑战,作者提出了一个问题:所选择的特征子集是否更鲁棒、更准确,并且与输入维度无关?
本文将特征选择问题重新表述为深度可微优化任务,并提出了一个新的研究视角:将离散特征子集概念化为连续嵌入空间优化。本文提出一个新的原则性框架,包括一个顺序编码器、一个精度评估器、一个顺序解码器和一个梯度上升优化器。这个全面的框架包括四个重要步骤:特征精度训练数据的准备、深度特征子集嵌入、梯度优化搜索和特征子集重构。利用强化特征选择学习来生成多样化和高质量的训练数据,并增强泛化能力。通过优化重构和精度损失,使用编码器-评估器-解码器模型结构将特征选择知识嵌入到连续空间中。作者采用梯度上升搜索算法在学习的嵌入空间中寻找更好的嵌入。利用这些嵌入重构特征选择解决方案,并为下游任务选择性能最高的特征子集作为最优子集。最后,通过大量实验验证了所提方法的有效性,在特征选择的鲁棒性和准确性方面均有显著提高。
模型

图1显示了本文的框架概述,包括四个步骤:1)特征精度训练数据准备;2)深度特征子集嵌入;3)梯度优化最佳嵌入搜索;4)最优特征子集重构。步骤1收集选定的特征子集和相应的预测性能作为深度特征子集嵌入的训练数据。特别是,为了利用现有的同行知识,使用经典的特征选择方法(例如,K-Best,mRMR)收集特征子集-准确率记录;为了探索众包未知知识,利用强化学习(reinforcement learning, RL)特征选择器收集不同的特征子集-准确率记录。步骤2是开发一个深度编码器-评估器-解码器模型,以学习特征子集的最佳嵌入空间。具体来说,给定一个特征子集,编码器将特征子集ID token映射为连续的嵌入向量;评估器通过预测相应的模型性能,沿着梯度方向优化嵌入向量;解码器使用特征子集嵌入向量重构特征ID标记。通过联合优化编码器、评估器和解码器的重建和评估损失来学习最优嵌入空间。step3旨在加快最优特征子集嵌入向量在嵌入空间中的梯度优化搜索。首先选择top-K个历史特征子集-准确率对作为搜索种子(起点),并使用训练有素的编码器获得相应的嵌入。然后,从这些嵌入开始,以分钟为速率,沿着性能改进的梯度方向进行搜索,以确定最优的嵌入。步骤4是利用训练有素的解码器将最优特征ID token重建为这些已识别的嵌入的候选特征子集。用一个下游ML模型评估这些候选特征子集,以提出性能最高的最佳特征子集。
特征精度训练数据准备
作者收集一组特征精度对作为训练数据,以构建一个描述原始特征集属性的有效连续空间。
强化学习可以用来自动探索和选择各种特征子集,以评估相应特征子集的性能。换句话说,强化特征选择可以被视为自动化训练数据准备的工具。作者开发了一个多智能体强化特征选择系统,每个智能体选择或取消选择一个特征,以逐步探索特征子集,并找到高精度低冗余的特征子集。强化特征选择系统利用随机性和自优化来自动生成高质量、多样化、全面的特征子集准确率记录,以克服数据稀疏性。
为了学习特征子集嵌入空间,将特征子集视为标记序列,并利用seq2vec模型将特征子集作为向量嵌入。由于特征子集与顺序无关,因此令牌序列与顺序无关。利用顺序不可知的特性,通过在特征标记序列中洗牌和重新排列所选特征的顺序来增强特征子集精度训练数据。
深度特征子集嵌入
大多数传统的特征选择算法都是离散选择公式。由于难以在高维数据集中枚举所有可能的特征组合,因此这种公式导致性能不佳。为了高效地搜索到最优的特征子集,将特征选择从离散空间的搜索转变为连续空间的搜索是至关重要的,在连续空间中,基于梯度的优化可以更快、更有效地进行选择。
但是,如何将来自特征选择的知识纳入到嵌入空间中呢?有两种潜在的方法:1)顺序建模,不分顺序地学习相同特征子集的不同嵌入;2)集合建模,为相同的特征子集生成一致的嵌入,即使顺序改变。在顺序建模中,具有不同顺序的相同子集产生不同的嵌入。这些形成了一个全局连续的嵌入空间,其中较亮的区域表示模型性能较差,而较暗的区域对应于优越的性能。通过梯度将候选嵌入转移到最优区域,可以很容易地搜索最优解决方案。相反,集合建模,对相同特征子集的变化学习一致的嵌入,会导致局部最优嵌入空间。该模型不能感知对性能没有影响的特征子集的顺序。因此,即使在嵌入更新后,由于缺乏明确的方向,定位最佳点仍然具有挑战性。基于这些观察,选择了序列建模(即LSTM),将特征选择知识集成到连续嵌入空间中。
本文的目标是构建一个有效的连续嵌入空间,以便在性能更高的梯度方向上使用基于梯度的搜索来搜索更好的特征子集。本文开发了一个新的学习框架,包括编码器、评估器和解码器。
联合优化:
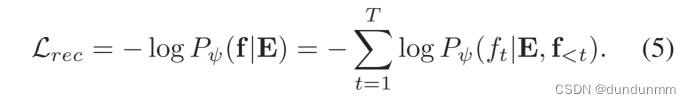
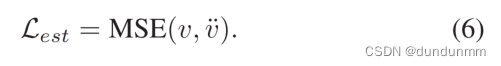
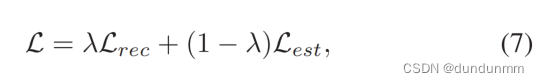
梯度优化最佳嵌入搜索
当编码器-评估器-解码器模型收敛时,在良好构建的连续空间中执行基于梯度的搜索,以获得更好的特征选择结果。与深度神经网络初始化的重要性类似,良好的初始点可以加速搜索过程,增强其性能。这些点被称为“搜索种子”。因此,首先根据相应的模型性能对选择记录进行排序。然后,选择top-K个选择记录作为搜索种子,以搜索更好的嵌入。
假设top-K选择的记录之一是(f, v)。将f输入编码器以获得嵌入E = [h1, h2,···,hT]。然后,沿着鉴别器ω:

其中η是步长,E+是增强的嵌入。应该将η设置在一个合理的范围内(例如足够小),使增强的嵌入E+的模型性能优于E,记为ω(E+)≥ω(E)。对每条记录进行搜索过程,并收集这些增强的嵌入,由[E+ 1, E+ 2,···,E+ K]表示。由于将离散的选择记录嵌入到d维嵌入空间中,搜索过程的时间复杂度与原始特征集的大小无关。
最优特征子集重构
增强的嵌入表明可能有更好的特征选择结果。为了找到最优的方法,应该使用它们重建特征ID token。具体来说,将[E+ 1, E+ 2,···,E+ K]输入到训练好的解码器中,得到重建的特征ID token [f1 +,f2 +,···,f + K]。在整个解码过程中,不需要设置特征ID token的数量;相反,识别每个标记,直到停止标记,类似于自然语言生成的工作方式。然后,使用它们从原始特征集中选择不同的特征子集。最后,采用下游的机器学习模型来评估这些子集,并输出最优的特征ID token f,该token可以用来选择具有最高模型性能的最佳特征子集。
实验
数据集

实验结果
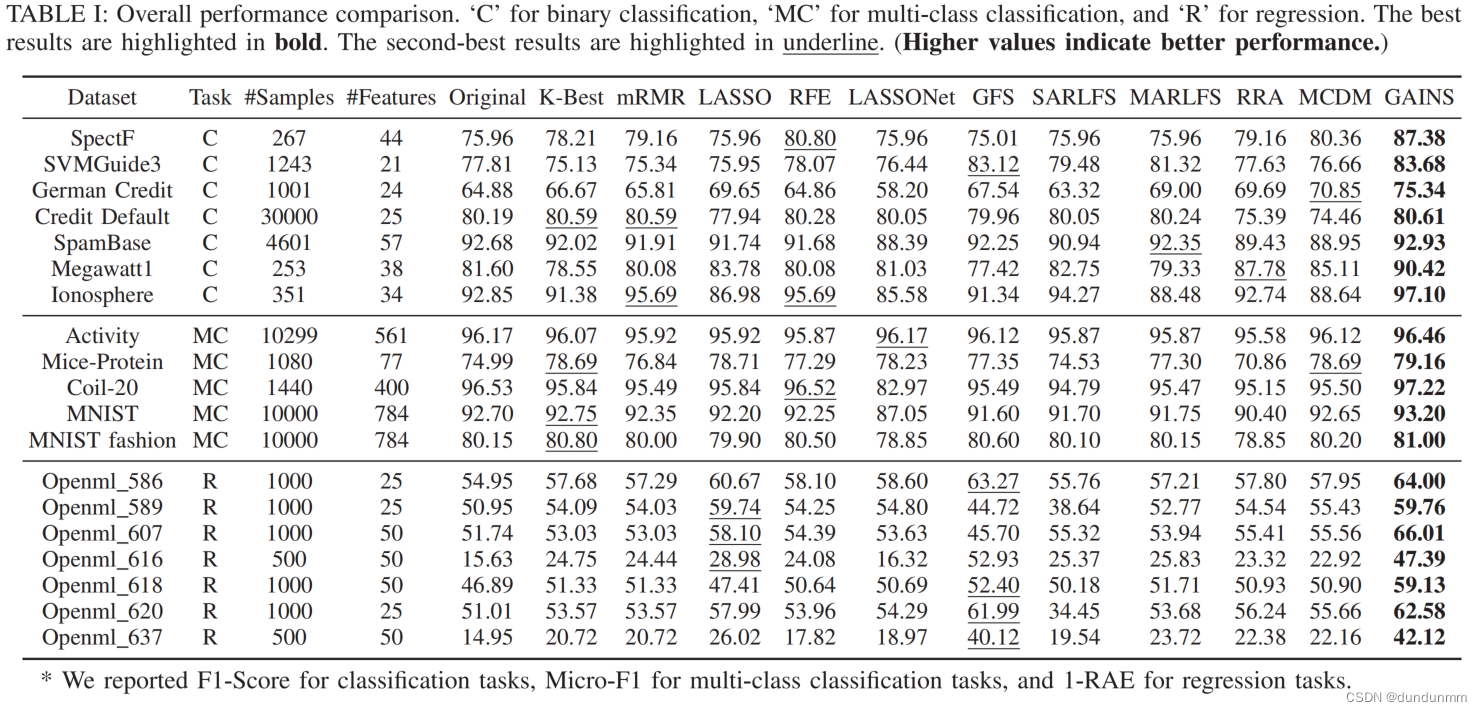
自动优化特征选择,可以借鉴。👍















 8178
8178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









