










(转载请注明出处)
使用SDK: Kinect for Windows SDK v2.0 public preview
这次获取Kinect里面流数据中最后一种:音频流。
我们可以从录音设备里面看到Kinect:
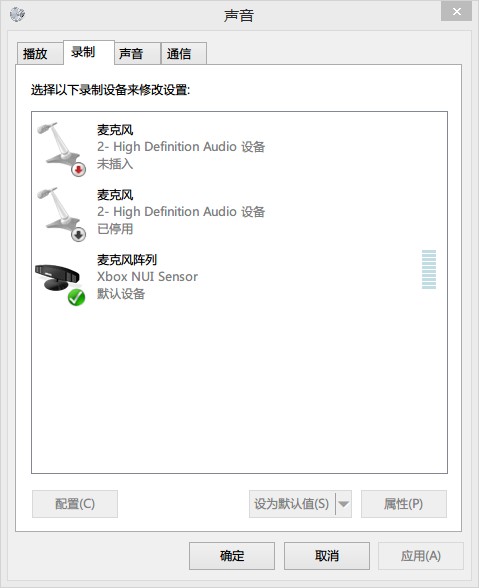
我们可以用一般获取录音一样获取音频流,请注意,从这里获取的音频流是原始数据:麦克风列阵获取的多声道音频,并且
没有利用麦克风列阵进行降噪处理。代码可以查看SDK自带的获取原始数据的例子,因为与通用设备打交道,很麻烦,这里
不做说明。
这里说的是利用自带的方法,获取经处理的音频数据。
经过处理的数据信息如下:
编码: 32位标准浮点(IEEE FLOAT)
声道: 1
采样率: 16000Hz
嗯,16KHz,不是熟悉的44.1KHz。毕竟根据奈奎斯特的采样理论,针对人声已经足够了。
SDK中获取处理后的音频流有两种方法,一种是音频帧,和之前的各种帧差不多:
<span style="font-size:14px;"> // 获取音频源(AudioSource)
if (SUCCEEDED(hr)){
hr = m_pKinect->get_AudioSource(&pAudioSource);
}
// 再获取音频帧读取器
if (SUCCEEDED(hr)){
hr = pAudioSource->OpenReader(&m_pAudioBeamFrameReader);
}
// 注册临帧事件
if (SUCCEEDED(hr)){
m_pAudioBeamFrameReader->SubscribeFrameArrived(&m_hAudioBeamFrameArrived);
}</span>根据事件获取 AudioBeamFrameArrivedEventArgs
再获取 AudioBeamFrameReference 音频帧引用
再获取 AudioBeamFrameList 音频帧链表
目前链表只有一个元素,直接获取 AudioBeamFrame音频帧。
音频帧可能包含复数 AudioBeamSubFrame 音频副帧(比如本人这里包含2个)
这个东西才能获取音频流的真正信息。
还有就是IStream,前面的这不是指C++标准库的输入流,而是COM组件的“流接口”,可读可写。
初始化代码如下:
<span style="font-size:14px;"> if (SUCCEEDED(hr))
{
hr = m_pKinectSensor->get_AudioSource(&pAudioSource);
}
if (SUCCEEDED(hr))
{
hr = pAudioSource->get_AudioBeams(&pAudioBeamList);
}
if (SUCCEEDED(hr))
{
hr = pAudioBeamList->OpenAudioBeam(0, &m_pAudioBeam);
}
if (SUCCEEDED(hr))
{
hr = m_pAudioBeam->OpenInputStream(&m_pAudioStream);
}</span>m_pAudioSteam就是Steam对象,使用时ISteam::Read(void*, ULONG, ULONG*)主动获取音频数据。
相比而言,使用音频帧既可以主动获取,又能使用事件机制,而Stream只能主动获取。所以,如果您仅仅需要获取
音频流,建议使用音频帧。
SDK中音频流除了音频数据信息,还有其他比较重要的数据:发音角度(波束角)与这个角度的信心程度(置信度)。
获取方法有:
IAudioBeam::get_BeamAngle(float*)
IAudioBeam::get_BeamAngleConfidence(float*)
IAudioBeamSubFrame::get_BeamAngle(float*)
IAudioBeamSubFrame::get_BeamAngleConfidence(float*)
这个方法自然是为单机多人应用服务的——能够知道是谁说的话。您的程序仅支持单人的话,还是

这里就仅仅示范音频帧吧,Stream下次的语音识别再使用
这次提供的范例将是无趣的,是一个控制台程序。退出程序请按任意键退出,否则不会将Kinect关闭。
这次就是录取数据,将数据存储到硬盘上。
然后将源数据使用您的音频处理软件导入,如果您目前还没有处理软件的话,这里推荐Audacity.
使用 文件-导入-裸数据 选择刚才生成的文件
然后选择: 32位float-没有尾端-单声道-偏移0-导入100%-采样率16000Hz
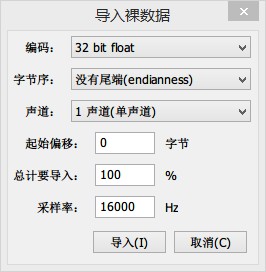
可以看出降噪效果不错
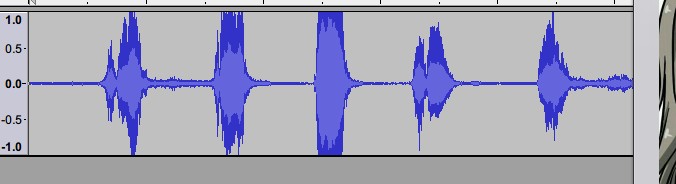
“微软使用了音频降噪,效果拔群!”
下载地址:点击这里















 5474
5474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









