







 本文深入探讨GPU的计算能力,包括CUDA计算能力、FLOPS指标及显存大小,对比了不同NVIDIA GPU如Titan X、GTX 980、Tesla K80等在科学计算领域的性能表现,分析了单精度与双精度计算能力的区别,以及它们在深度学习、机器学习中的应用价值。
本文深入探讨GPU的计算能力,包括CUDA计算能力、FLOPS指标及显存大小,对比了不同NVIDIA GPU如Titan X、GTX 980、Tesla K80等在科学计算领域的性能表现,分析了单精度与双精度计算能力的区别,以及它们在深度学习、机器学习中的应用价值。
实验室最近出了一款芯片,想进行指标的对比,现在ai芯片加速器我记得峰值运算能力effiency已经达到了Tops(一般也就几或者十几,effiency一般分为ops/w,ops/mm^2,ops/s等等),于是想看看GPU的运算能力,进行相应参照。
大多数网站都会贴这一张图,其实也没有错,就是不够细致,我们更想知道它的具体ops登记,而不是宽泛的level级别的计算能力数字。nvidia的显卡越来越强,CUDA运算核心越来越多,甚至也开始了他自家的深度学习学院DLI(赚钱),它强大的并行性,使得现在显卡GTX系列,RTX2080,丽台,Tesla系列,P40系列,K4200系列以及TITAN X/V,TITAN XP等等产品一个个成为热点,狂赚一波。
FROM: https://developer.nvidia.com/cuda-gpus
CUDA GPUs
最新信息见:https://developer.nvidia.com/cuda-gpus
NVIDIA GPUs power millions of desktops, notebooks, workstations and supercomputers around the world, accelerating computationally-intensive tasks for consumers, professionals, scientists, and researchers.
Find out all about CUDA and GPU Computing by attending our GPU Computing Webinars and joining our free-to-joinCUDA Registered developer Program.
- Learn about Tesla for technical and scientific computing
- Learn about Quadro for professional visualization
If you have an older NVIDIA GPU you may find it listed on our legacy CUDA GPUs page
Click the sections below to expand
1) CUDA-Enabled Tesla Products
Tesla Workstation Products
| GPU | Compute Capability |
|---|---|
| Tesla K80 | 3.7 |
| Tesla K40 | 3.5 |
| Tesla K20 | 3.5 |
| Tesla C2075 | 2.0 |
| Tesla C2050/C2070 | 2.0 |
//
Tesla Data Center Products
| GPU | Compute Capability |
|---|---|
| Tesla P100 | 6.0 |
| Tesla P40 | 6.1 |
| Tesla P4 | 6.1 |
| Tesla M40 | 5.2 |
| Tesla M40 | 5.2 |
| Tesla K80 | 3.7 |
| Tesla K40 | 3.5 |
| Tesla K20 | 3.5 |
| Tesla K10 | 3.0 |
************************************************************************************************************
2) CUDA-Enabled Quadro Products
Quadro Desktop Products
| GPU | Compute Capability |
|---|---|
| Quadro P6000 | 6.1 |
| Quadro P5000 | 6.1 |
| Quadro M6000 24GB | 5.2 |
| Quadro M6000 | 5.2 |
| Quadro K6000 | 3.5 |
| Quadro M5000 | 5.2 |
| Quadro K5200 | 3.5 |
| Quadro K5000 | 3.0 |
| Quadro M4000 | 5.2 |
| Quadro K4200 | 3.0 |
| Quadro K4000 | 3.0 |
| Quadro M2000 | 5.2 |
| Quadro K2200 | 5.0 |
| Quadro K2000 | 3.0 |
| Quadro K2000D | 3.0 |
| Quadro K1200 | 5.0 |
| Quadro K620 | 5.0 |
| Quadro K600 | 3.0 |
| Quadro K420 | 3.0 |
| Quadro 410 | 3.0 |
| Quadro Plex 7000 | 2.0 |
//
Quadro Mobile Products| GPU | Compute Capability |
|---|---|
| Quadro K6000M | 3.0 |
| Quadro M5500M | 5.0 |
| Quadro K5200M | 3.0 |
| Quadro K5100M | 3.0 |
| Quadro M5000M | 5.0 |
| Quadro K500M | 3.0 |
| Quadro K4200M | 3.0 |
| Quadro K4100M | 3.0 |
| Quadro M4000M | 5.0 |
| Quadro K3100M | 3.0 |
| Quadro M3000M | 5.0 |
| Quadro K2200M | 5.0 |
| Quadro K2100M | 3.0 |
| Quadro M2000M | 5.0 |
| Quadro K1100M | 3.0 |
| Quadro M1000M | 5.0 |
| Quadro K620M | 5.0 |
| Quadro K610M | 3.5 |
| Quadro M600M | 5.0 |
| Quadro K510M | 3.5 |
| Quadro M500M | 5.0 |
************************************************************************************************************
3) CUDA-Enabled NVS Products
Desktop Products
| GPU | Compute Capability |
|---|---|
| NVIDIA NVS 810 | 5.0 |
| NVIDIA NVS 510 | 3.0 |
| NVIDIA NVS 315 | 2.1 |
| NVIDIA NVS 310 | 2.1 |
************************************************************************************************************
4) CUDA-Enabled GeForce Products
GeForce Desktop Products
************************************************************************************************************
5) CUDA-Enabled TEGRA /Jetson Products
GeForce Notebook Products
************************************************************************************************************
6) Tegra Mobile & Jetson Products
Tegra Mobile & Jetson Products
| GPU | Compute Capability |
|---|---|
| Jetson TX1 | 5.3 |
| Jetson TK1 | 3.2 |
| Tegra X1 | 5.3 |
| Tegra K1 | 3.2 |
Notes
(*) OEM-only products
(**) The GeForce GTX860 and GTX870 come in two versions depending on the SKU, please check with your OEM to determine which one is in your system.
- 1152 Kepler Cores with Compute Capability 3.0
- 640 Maxwell Cores with higher clocks and Compute Capability 5.0 or 5.2
Frequently Asked Questions
-
1) How can I find out which GPU is in my computer?
-
Answer:
On Windows computers:
- Right-click on desktop
- If you see "NVIDIA Control Panel" or "NVIDIA Display" in the pop-up window, you have an NVIDIA GPU
- Click on "NVIDIA Control Panel" or "NVIDIA Display" in the pop-up window
- Look at "Graphics Card Information"
- You will see the name of your NVIDIA GPU
On Apple computers:
- Click on "Apple Menu"
- Click on "About this Mac"
- Click on "More Info"
- Select "Graphics/Displays" under Contents list
2) Do I have a CUDA-enabled GPU in my computer?
- Answer: Check the list above to see if your GPU is on it. If it is, it means your computer has a modern GPU that can take advantage of CUDA-accelerated applications. 3) How do I know if I have the latest drivers?
- Answer: Go to www.nvidia.com/drivers 4) How can I obtain a CUDA-enabled GPU or system?
-
Answer:
For Tesla for HPC and supercomputing applications, go to www.nvidia.com/object/tesla_wtb.html
For GeForce for entertainment, go to www.nvidia.com/object/geforce_family.html
For Quadro for professional visualization, go to www.nvidia.com/object/workstation_wheretobuy.html
5) How can I download the CUDA software development kit?
- Answer: Go to CUDA Development Tools.
参考:
https://blog.csdn.net/chigusakawada/article/details/80198970
https://blog.csdn.net/u010159842/article/details/56666158/
但是现在衡量计算速度的标准是TFLOPS(每秒万亿次浮点运算),注意GPU它是浮点运算。。
重点就是关注它的flops是怎么计算的。。
这里先参考一下某博主写的粗浅见解:
https://blog.csdn.net/wesley_2013/article/details/11910117
此博客为博主的自学笔记 ,欢迎大家共同交流,如果有错误的地方欢迎留言指正。
今天开始重新学习CUDA,虽然之前也写过一段程序。可因为种种原因没有继续,加之使用的硬件版本比较低端和英伟达的不断创新进步,发现自己已经处于CUDA的菜鸟乐园中。
闲话不多说---------开干。
今天先将最基本的计算方法重新理解一下,为以后的性能优化打下坚实的基础!!!!
GPU设备的单精度计算能力的理论峰值计算公式:
单精度计算能力的峰值 = 单核单周期计算次数 × 处理核个数 × 主频
例如: 以GTX680为例, 单核一个时钟周期单精度计算次数为两次,处理核个数 为1536, 主频为1006MHZ,那他的计算能力的峰值P 为
P = 2 × 1536 × 1006MHZ = 3.09TFLOPS
这里1MHZ = 1000000HZ, 1T为1兆,也就是说,GTX680每秒可以进行超过3兆次的单精度运算。
同样,双精度的处理核为64个,不难算出,GTX680的双精度运算能力为0.13TFLOPS。
GPU设备的数据通信时间的计算公式:
通信时间 = 通信量 ÷ 通信速度
例如,单个处理核的输入数据以4个4byte为例,输出为1个4byte,GTX680所有处理核100%利用的情况下,通信量为5× 4 × 1536 byte,GTX680的通信速度为192..2GB/S,所以它的通信时间为
5× 4 × 1536 byte ÷ 192.2GB/S = 1.49e-7 s
如果这4个4byte的数据进行10次运算的话,以GTX680为例,他的主频为1006MHZ,也就是他每1e-9s为一个时钟周期,每个周期可进行两次单精度计算,也就是5个时钟周期即5e-9s可完成计算,为通信时间的几十分之一,故可忽略不计。所以,从内存访问看计算能力:
单精度计算能力 = 单核单精度符点计算次数 × 处理核个数 ÷ ( 通信时间 + 计算时间) 注:此处计算时间忽略不计
即 10 × 1536 ÷ 1.49e-7s = 103GFLOPS
即为普通PC10倍的计算速度。
不得不说现在nvidia家的架构能力真的太强了,出来好多的亚里士多德架构,特斯拉架构,笛卡尔架构,帕斯卡尔架构,费米架构等等,被后面的很多深度学习硬件公司效仿,比如寒武纪,深鉴科技(清华的初创公司,类似的还有汪玉,韩松的魏少军的thinker系列,施路平的天机系列)等等。。
1、SP总数=TPC&GPC数量每个TPC中SM数量每个SM中的SP数量;
TPC和GPC是介于整个GPU和流处理器簇之间的硬件单元,用于执行CUDA计算。特斯拉架构硬件将SM组合成TPC(纹理处理集群),其中,TPC包含有纹理硬件支持(特别包含一个纹理缓存)和2个或3个SM,后面会有详细描述。费米架构硬件组则将SM组合为GPC(图形处理器集群),其中,每个GPU包含有一个光栅单元和4个SM。
2、单精度浮点处理能力=SP总数SP运行频率每条执行流水线每周期能执行的单精度浮点操作数;
该公式实质上是3部分相乘得到的,分别为计算单元数量、计算单元频率和指令吞吐量。
前两者很好理解,指令吞吐量这里是按照FMA(融合乘法和增加)算的,也就是每个SP,每周期可以有一条FMA指令的吞吐量,并且同时FMA因为同时计算了乘加,所以是两条浮点计算指令。
以及需要说明的是,并不是所有的单精度浮点计算都有这个峰值吞吐量,只有全部为FMA的情况,并且没有其他访存等方面的限制的情况下,并且在不考虑调度效率的情况下,才是这个峰值吞吐量。如果是其他吞吐量低的计算指令,自然达不到这个理论峰值。
3、双精度浮点处理能力=双精度计算单元总数SP运行频率每个双精度计算单元每周期能进行的双精度浮点操作数。
目前对于N卡来说,双精度浮点计算的单元是独立于单精度单元之外的,每个SP都有单精度的浮点计算单元,但并不是每个SP都有双精度的浮点单元。对于有双精度单元的SP而言,最大双精度指令吞吐量一样是在实现FMA的时候的每周期2条(指每周期一条双精度的FMA指令的吞吐量,FMA算作两条浮点操作)。
而具备双精度单元的SP数量(或者可用数量)与GPU架构以及产品线定位有关,具体为:
计算能力为1.3的GT200核心,第一次硬件支持双精度浮点计算,双精度峰值为单精度峰值的1/8,该核心目前已经基本退出使用。
GF100/GF110核心,有一半的SP具备双精度浮点单元,但是在geforce产品线中屏蔽了大部分的双精度单元而仅在tesla产品线中全部打开。代表产品有:tesla C2050,2075等,其双精度浮点峰值为单精度浮点峰值的一半;
geforce GTX 480,580,其双精度浮点峰值为单精度浮点峰值的大约1/8左右。
其他计算能力为2.1的Fermi核心,原生设计中双精度单元数量较少,双精度计算峰值为单精度的1/12。
kepler GK110核心,原生的双精度浮点峰值为单精度的1/3。而tesla系列的K20,K20X,K40他们都具备完整的双精度浮点峰值;geforce系列的geforce TITAN,此卡较为特殊,和tesla系列一样具备完整的双精度浮点峰值,geforce GTX780/780Ti,双精度浮点峰值受到屏蔽,具体情况不详,估计为单精度峰值的1/10左右。
其他计算能力为3.0的kepler核心,原生具备较少的双精度计算单元,双精度峰值为单精度峰值的1/24。
计算能力3.5的GK208核心,该卡的双精度效能不明,但是考虑到该核心定位于入门级别,大规模双精度计算无需考虑使用。
所以不同核心的N卡的双精度计算能力有显著区别,不过目前基本上除了geforce TITAN以外,其他所有geforce卡都不具备良好的双精度浮点的吞吐量,而本代的tesla K20/K20X/K40以及上一代的fermi核心的tesla卡是较好的选择。
参考于:
https://cudazone.nvidia.cn/forum/forum.php?mod=viewthread&tid=7722&extra=page%253D1
https://blog.csdn.net/ZIV555/article/details/51753985
讲的比较详细的是下面这一篇,里面有一些我也不知道怎么就输出的信息,可能是某种软件吧:
https://blog.csdn.net/enjoyyl/article/details/81529779#1080TI_33
计算能力换算
理论峰值 = GPU芯片数量*GPU Boost主频*核心数量*单个时钟周期内能处理的浮点计算次数
只不过在GPU里单精度和双精度的浮点计算能力需要分开计算,以最新的Tesla P100为例:
双精度理论峰值 = FP64 Cores * GPU Boost Clock * 2 = 1792 *1.48GHz*2 = 5.3 TFlops
单精度理论峰值 = FP32 cores * GPU Boost Clock * 2 = 3584 * 1.58GHz * 2 = 10.6 TFlop
信息
# 1080TI
Total amount of global memory: 11172 MBytes (11715084288 bytes)
(28) Multiprocessors, (128) CUDA Cores/MP: 3584 CUDA Cores
GPU Max Clock rate: 1582 MHz (1.58 GHz)
Memory Clock rate: 5505 Mhz
Memory Bus Width: 352-bit
L2 Cache Size: 2883584 bytes
# 1080
Total amount of global memory: 8111 MBytes (8504868864 bytes)
(20) Multiprocessors, (128) CUDA Cores/MP: 2560 CUDA Cores
GPU Max Clock rate: 1734 MHz (1.73 GHz)
Memory Clock rate: 5005 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 2097152 bytes
1080TI
~/NVIDIA_CUDA-8.0_Samples/7_CUDALibraries/batchCUBLAS$ export CUDA_VISIBLE_DEVICES=0 ~/NVIDIA_CUDA-8.0_Samples/7_CUDALibraries/batchCUBLAS$ ./batchCUBLAS -m1024 -n1024 -k1024 batchCUBLAS Starting... GPU Device 0: "GeForce GTX 1080 Ti" with compute capability 6.1 ==== Running single kernels ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x40000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00037980 sec GFLOPS=5654.24 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x0000000000000000, 0) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00894690 sec GFLOPS=240.026 @@@@ dgemm test OK ==== Running N=10 without streams ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x00000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00294209 sec GFLOPS=7299.19 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.07993412 sec GFLOPS=268.657 @@@@ dgemm test OK ==== Running N=10 with streams ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x40000000, 2) beta= (0x40000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00224590 sec GFLOPS=9561.78 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.05540895 sec GFLOPS=387.57 @@@@ dgemm test OK ==== Running N=10 batched ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x3f800000, 1) beta= (0xbf800000, -1) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00197387 sec GFLOPS=10879.6 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x4000000000000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.05372214 sec GFLOPS=399.739 @@@@ dgemm test OK Test Summary 0 error(s)
1080
liu@iridescent:~/NVIDIA_CUDA-8.0_Samples/7_CUDALibraries/batchCUBLAS$ export CUDA_VISIBLE_DEVICES=1 liu@iridescent:~/NVIDIA_CUDA-8.0_Samples/7_CUDALibraries/batchCUBLAS$ ./batchCUBLAS -m1024 -n1024 -k1024 batchCUBLAS Starting... GPU Device 0: "GeForce GTX 1080" with compute capability 6.1 ==== Running single kernels ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x40000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00060892 sec GFLOPS=3526.7 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x0000000000000000, 0) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00993085 sec GFLOPS=216.244 @@@@ dgemm test OK ==== Running N=10 without streams ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x00000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00369406 sec GFLOPS=5813.35 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.09741306 sec GFLOPS=220.451 @@@@ dgemm test OK ==== Running N=10 with streams ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x40000000, 2) beta= (0x40000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00317717 sec GFLOPS=6759.12 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.07991505 sec GFLOPS=268.721 @@@@ dgemm test OK ==== Running N=10 batched ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x3f800000, 1) beta= (0xbf800000, -1) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00302100 sec GFLOPS=7108.51 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x4000000000000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.07566714 sec GFLOPS=283.807 @@@@ dgemm test OK Test Summary 0 error(s)
Jteson
$ ./batchCUBLAS -m1024 -n1024 -k1024 batchCUBLAS Starting... GPU Device 0: "NVIDIA Tegra X2" with compute capability 6.2 ==== Running single kernels ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x40000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.00372291 sec GFLOPS=576.83 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x0000000000000000, 0) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.10940003 sec GFLOPS=19.6296 @@@@ dgemm test OK ==== Running N=10 without streams ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x00000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.03462315 sec GFLOPS=620.245 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 1.09212208 sec GFLOPS=19.6634 @@@@ dgemm test OK ==== Running N=10 with streams ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x40000000, 2) beta= (0x40000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.03504515 sec GFLOPS=612.776 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 1.09177494 sec GFLOPS=19.6697 @@@@ dgemm test OK ==== Running N=10 batched ==== Testing sgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x3f800000, 1) beta= (0xbf800000, -1) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 0.03766394 sec GFLOPS=570.17 @@@@ sgemm test OK Testing dgemm #### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x4000000000000000, 2) #### args: lda=1024 ldb=1024 ldc=1024 ^^^^ elapsed = 1.09389901 sec GFLOPS=19.6315 @@@@ dgemm test OK Test Summary 0 error(s)
对比
1080ti 1080 Jetson Tx2 GFLOPS=5654.24 GFLOPS=3526.7 GFLOPS=576.83 GFLOPS=7299.19 GFLOPS=5813.35 GFLOPS=620.245
科学计算显卡的两个主要性能指标:
1、CUDA compute capability,这是英伟达公司对显卡计算能力的一个衡量指标;
2、FLOPS 每秒浮点运算次数,TFLOPS表示每秒万亿(10^12)次浮点计算;
3、另外,显存大小也决定了实验中能够使用的样本数量和模型复杂度。
1、CUDA compute capability对比
GTX Titan x :5.2
GTX 980 :5.2
Tesla K80 :3.7
Tesla K40 :3.5
K4200 : 3.0
2、TFLOPS 比较
单精度single 双精度double
GTX Titan x : 7 0.2
GTX 980 : 4.6 0.15
Tesla K80 : 8.74 2.91
Tesla K40 : 4.29 1.43
K4200 : 2.0
单精度能够保证小数点后6到7位计算准确(2^23),双精度则是14到15位(2^52)
3、显存大小
GTX Titan x :12Gb
GTX 980 :4Gb
Tesla K80 :24Gb
Tesla K40 :12Gb
K4200 :4Gb
4、价格比较(网上商城京东淘宝报价)
GTX Titan x :8000+-
GTX 980 :6000+-
Tesla K80 :30000++
Tesla K40 :25000+-
K4200 :6000+-
1、GTX 系列显卡优缺点:
优点:单精度计算能力强大,显存最大12Gb,性价比高
缺点:双精度计算能力弱,没有计算纠错ECC 内存,对于超高精度计算不利
2、Tesla 或 quadro显卡优缺点:
优点:双精度计算能力最强,拥有ECC内存增强计算准确率,
缺点:单精度计算能力差,价格较高
总结:单从性能上选择,Tesla K80是最强大的,但也最贵;综合性价比来考虑 GTX Titan X 最好。
CUDA这个东西不管是软件,编程,还是硬件都是很值得去开发的,对理解现有计算机以及并行架构是非常有益处的,大家也可以自己去网上找到自己想要的CUDA教程。
这里再贴一下一个比较硬核的:
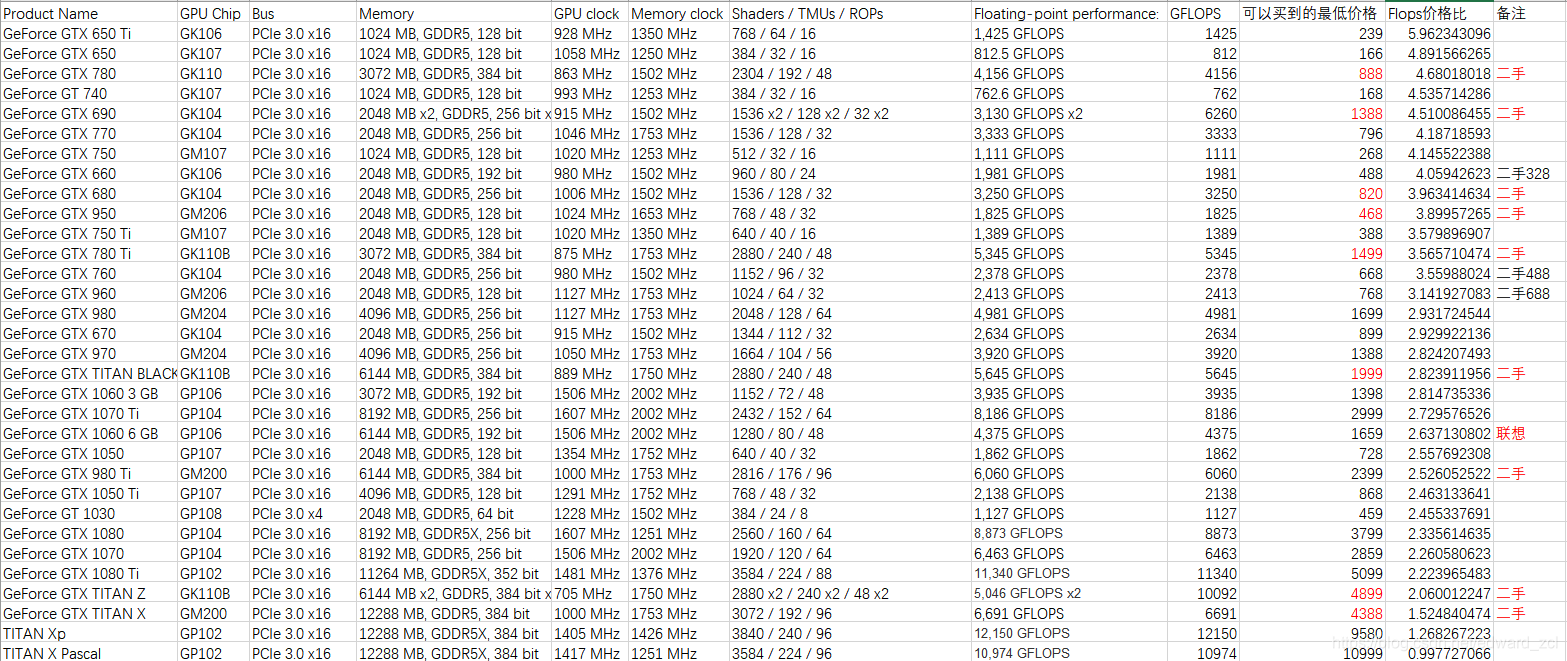
数据来源于某宝和techpowerup
Flops是浮点运算性能,与游戏体验有很大关系但是并不绝对,可能还和显存等等其他有关。但是在做机器学习、深度学习、数学计算的时候通常这个数字非常具有参考价值。
由此可以分析,二手性价比最高的是GTX780、GTX660和GTX760。GTX650 GTX650ti虽然性价比相当高还是新卡但是性能太差。新显卡最值得买的是GTX770。GTX660对比GTX1050发现,实际上GTX1050性价比超级低。9系列性价比最高的是GTX960。旗舰性价比最高是GTX980.而且居然排名相当靠前。GTX690作为二手卡性价比也是很高,但是那个350W的功耗,玩一玩把钱玩回来了。私以为做机器学习深度学习的可以参考这个表组SLI。双路时候tensorflow的效率还是相当高的。玩游戏的钉钉们可以找到自己常玩游戏的配置要求。挑一个性价比最高的买。
顺带科普一下手机的性能啊,来源于维基百科英文版:
mate10 的麒麟970 NPU有 1900 Gflops
iphone 8 配的 A11 中的 NPU 有 600 Gflops
米6 配的高通 835 性能是 567 Gflops
米5 高通 820 是 407 Gflops
iphone 7 配的 A10 中的 PowerVR GT7600 是 380 Gflops
小米 Max 配的高通骁龙 650 性能是 180 Glops
其中HUAWEI 的NPU和A11的NPU的flops是有水分的。因为flops就是浮点运算次数每秒。然而…一般都是以32位浮点数…一般NPU(专门算神经网络的)为了优化性能会采用8位浮点数。由于GPU通常用8位浮点数去计算16位、32位、64位。因此…这些计算难度的关系几乎就是成倍数的。也就是说HUAWEI NPU的性能和A11的NPU的性能换算成其他的要除以4(毕竟NPU只是一部分,人家还有GPU呢)一个CPU封装塞这么多已经很厉害了吧。
当然了,网上也有很多贴吧或者论坛,视频,各种评测或者天梯图,讨论各种显卡的优劣,例如:RTX2080ti,RTX2070以及GTX1080ti的分析等,大家可以自行斟酌。
更多参考:
https://blog.csdn.net/p312011150/article/details/83989674
https://www.expreview.com/52443-3.html
https://www.expreview.com/67453.html
http://tieba.baidu.com/p/5388310468
http://k.sina.com.cn/article_2934331057_aee656b1001004rc9.html?cre=oldpagepc&mod=g&loc=15&r=0&doct=0&rfunc=72&tj=none
https://bbs.csdn.net/topics/392311745
https://baijiahao.baidu.com/s?id=1597974095090413567&wfr=spider&for=pc

















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









