









 本文探讨了在存在未观测变量的复杂因果图中,如何利用Frontdoor调整和do-calculus准则识别因果效应。通过前门准则和数学证明,展示了如何通过中介变量M计算T到Y的因果影响,同时介绍了do-calculus的三条规则及其在frontdoor调整中的应用。
本文探讨了在存在未观测变量的复杂因果图中,如何利用Frontdoor调整和do-calculus准则识别因果效应。通过前门准则和数学证明,展示了如何通过中介变量M计算T到Y的因果影响,同时介绍了do-calculus的三条规则及其在frontdoor调整中的应用。
上文我们提到了含有未观测变量的情况,在这种情况下,我们无法block所有后门路径,那么有没有办法可以不满足后门准则也能识别因果效应?(这章篇硬核,建议跟着推一遍)
Frontdoor Adjustment
如图1所示,W是未观测变量,如果我们能只计算T到Y的直接因果边,自然就能识别T到Y的因果关系了,Frontdoor Adjustment就是奔着这个目标去的,它指出只要T和Y直接有一个mediator(中介者)M,即使不满足后门准则,我们也能计算出因果效应,只要因果图满足Frontdoor criterion(前门准则)。在介绍前门准则前,我们先了解下mediator M的定义 :
如果T到Y的所有直接因果路径全部需要通过M,则称一组变量集合M完全 mediate(中介)T到Y的效应,这样的情况称为 complete/full mediator(完全中介)。
Frontdoor criterion,如果:
- M completely mediates T到Y的影响(所有T到Y的的因果路径都通过M
- T到M没有 unblocked backdoor path
- 所有M 到 Y 的后门路径都被T blocked。
则变量集合满足关于T到Y的前门准则。下面我们根据前门准则对图1的因果效应进行识别。
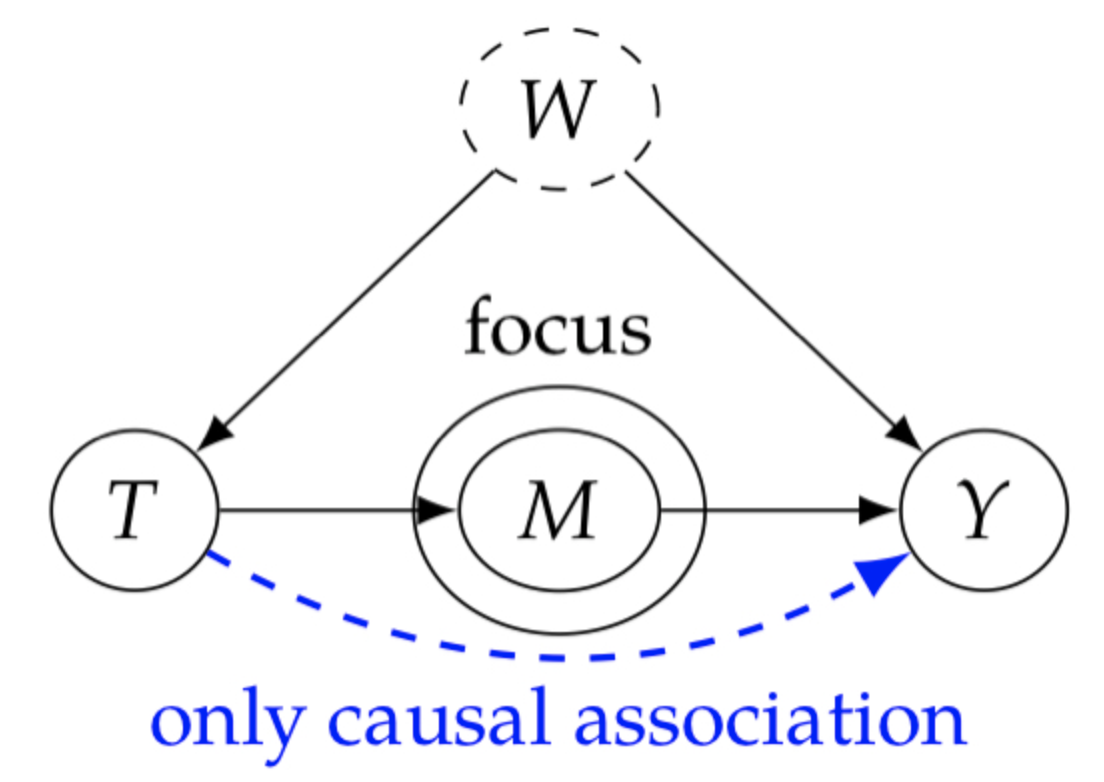
只需要考虑以下三步:
- 识别T到M的因果效应
- 识别M到Y的因果效应
- 合并步骤1和2,识别T到Y的因果效应
首先考虑第一步,识别T到M的因果效应P(m|do(t)),因为Y是T-M的collider,所以Y block T-M的后门路径。因此根据后门调整可得:P(m|do(t))=P(m|t)
第二步,识别M到Y的效应:P(y|do(m))。因为T block M<-T<-W->Y,我们可以通过调整T满足后门标准: P ( y ∣ d o ( m ) ) = ∑ t P ( y ∣ m , t ) P ( t ) P(y|do(m))=\sum_tP(y|m, t)P(t) P(y∣do(m))=∑tP(y∣m,t)P(t)
第三步,由前两步得到T到Y的因果效应:
P ( y ∣ d o ( t ) ) = ∑ m P ( m ∣ d o ( t ) ) P ( y ∣ d o ( m ) ) P(y|do(t))=\sum_mP(m|do(t))P(y|do(m)) P(y∣do(t))=∑mP(m∣do(t))P(y∣do(m))
其实就是求所以m取值下的T到Y的因果效应,全部加起来就是T到Y的真正因果效应了。
因此得到Frontdoor Adjustment,如果(T,M,Y)满足Frontdoor criterion 并且满足positivity 假设,则
P ( y ∣ d o ( t ) ) = ∑ m P ( m ∣ t ) ∑ t ′ P ( y ∣ m , t ′ ) P ( t ′ ) P(y|do(t))=\sum_mP(m|t)\sum_{t'}P(y|m,t')P(t') P(y∣do(t))=∑mP(m∣t)∑t′P(y∣m,t′)P(t′)
下面我们给出Frontdoor Adjustment的数学证明:
首先针对图1使用贝叶斯网络分解,得到
P ( w , t , m , y ) = P ( w ) P ( t ∣ w ) P ( m ∣ t ) P ( y ∣ w , m ) P(w,t,m,y)=P(w)P(t|w)P(m|t)P(y|w,m) P(w,t,m,y)=P(w)P(t∣w)P(m∣t)P(y∣w,m)
然后使用truncated factorization,得到
P ( w , m , y ∣ d o ( t ) ) = P ( w ) P ( m ∣ t ) P ( y ∣ w , m ) P(w,m,y|do(t)) = P(w)P(m|t)P(y|w,m) P(w,m,y∣do(t))=P(w)P(m∣t)P(y∣w,m)
然后边缘化w和m,得到
∑ m ∑ w P ( w , m , y ∣ d o ( t ) ) = ∑ m ∑ w P ( w ) P ( m ∣ t ) P ( y ∣ w , m ) = ∑ m P ( m ∣ t ) ∑ w P ( y ∣ w , m ) P ( w ) \sum_m\sum_w P(w,m,y|do(t))=\sum_m\sum_wP(w)P(m|t)P(y|w,m)=\sum_mP(m|t)\sum_wP(y|w,m)P(w) ∑m∑wP(w,m,y∣do(t))=∑m∑wP(w)P(m∣t)P(y∣w,m)=∑mP(m∣t)∑wP(y∣w,m)P(w)
P ( y ∣ d o ( t ) ) = ∑ m P ( m ∣ t ) ∑ w P ( y ∣ w , m ) P ( w ) P(y|do(t))=\sum_mP(m|t)\sum_wP(y|w,m)P(w) P(y∣do(t))=∑mP(m∣t)∑wP(y∣w,m)P(w)
我们的目标是把未观测变量w消去,只留下t,m,y。在上式中,我们想如果能将P(w)转化为P(w|m),就能刚好消去w,结合图1可得P(w|t)=P(w|m,t)(y作为collider),于是上式可化为
P ( y ∣ d o ( t ) ) = ∑ m P ( m ∣ t ) ∑ w P ( y ∣ w , m ) ∑ t ′ P ( w ∣ t ′ ) P ( t ′ ) P(y|do(t))=\sum_mP(m|t)\sum_wP(y|w,m)\sum_{t'}P(w|t')P(t') P(y∣do(t))=∑mP(m∣t)∑wP(y∣w,m)∑t′P(w∣t′)P(t′)
= ∑ m P ( m ∣ t ) ∑ w P ( y ∣ w , m ) ∑ t ′ P ( w ∣ t ′ , m ) P ( t ′ ) = ∑ m P ( m ∣ t ) ∑ t ′ P ( t ′ ) ∑ w P ( y ∣ w , m ) P ( w ∣ t ′ , m ) =\sum_mP(m|t)\sum_wP(y|w,m)\sum_{t'}P(w|t',m)P(t')=\sum_mP(m|t)\sum_{t'}P(t')\sum_wP(y|w,m)P(w|t',m) =∑mP(m∣t)∑wP(y∣w,m)∑t′P(w∣t′,m)P(t′)=∑mP(m∣t)∑t′P(t′)∑wP(y∣w,m)P(w∣t′,m)
因为W和M已经d-separation T和Y,所以P(y|w,m)=P(y|w,m,t’)
P ( y ∣ d o ( t ) ) = ∑ m P ( m ∣ t ) ∑ t ′ P ( t ′ ) ∑ w P ( y ∣ w , m ) P ( w ∣ t ′ , m ) = ∑ m P ( m ∣ t ) ∑ t ′ P ( t ′ ) ∑ w P ( y ∣ w , m , t ′ ) P ( w ∣ t ′ , m ) P(y|do(t))=\sum_mP(m|t)\sum_{t'}P(t')\sum_wP(y|w,m)P(w|t',m)=\sum_mP(m|t)\sum_{t'}P(t')\sum_wP(y|w,m,t')P(w|t',m) P(y∣do(t))=∑mP(m∣t)∑t′P(t′)∑wP(y∣w,m)P(w∣t′,m)=∑mP(m∣t)∑t′P(t′)∑wP(y∣w,m,t′)P(w∣t′,m)
= ∑ m P ( m ∣ t ) ∑ t ′ P ( t ′ ) ∑ w P ( y , w ∣ t ′ , m ) = ∑ m P ( m ∣ t ) ∑ t ′ P ( t ′ ) ∑ w P ( y , w ∣ t ′ , m ) =\sum_mP(m|t)\sum_{t'}P(t')\sum_wP(y,w|t',m)=\sum_mP(m|t)\sum_{t'}P(t')\sum_wP(y,w|t',m) =∑mP(m∣t)∑t′P(t′)∑wP(y,w∣t′,m)=∑mP(m∣t)∑t′P(t′)∑wP(y,w∣t′,m)
= ∑ m P ( m ∣ t ) ∑ t ′ P ( t ′ ) P ( y ∣ t ′ , m ) = ∑ m P ( m ∣ d o ( t ) ) P ( y ∣ d o ( m ) ) =\sum_mP(m|t)\sum_{t'}P(t')P(y|t',m)=\sum_mP(m|do(t))P(y|do(m)) =∑mP(m∣t)∑t′P(t′)P(y∣t′,m)=∑mP(m∣do(t))P(y∣do(m))
证毕。
do-calculus
如果T到Y之间既不满足后门准则,也不满足前门准则该怎么办?do-calculus能够识别任何可识别的因果量。为了学习do-calculus的规则,我们需要先定义一些术语。
G X ‾ G_{\overline{X}} GX:移除G中所有指向X的边,即X没有parent
G X ‾ G_{\underline{X}} GX:移除G中所有被X指向的边,即X没有descendent
G Z ( W ) ‾ G_{\overline{Z(W)}} GZ(W):移除Z指向W的所有边,即Z中没有W的parent
知道这三个术语后,我们学习do-calculus的三条规则,给定因果图G,分布P,不相交的三个变量集Y,T,Z和W,有下列规则:
Rule 1: P ( y ∣ d o ( t ) , z , w ) = P ( y ∣ d o ( t ) , w ) , i f Y ⊥ ⊥ G T ‾ Z ∣ T , W P(y|do(t),z,w)=P(y|do(t),w), if Y {\perp \!\!\! \perp}_{G_{\overline{T}}}Z|T,W P(y∣do(t),z,w)=P(y∣do(t),w),ifY⊥⊥GTZ∣T,W
Rule 2: P ( y ∣ d o ( t ) , d o ( z ) , w ) = P ( y ∣ d o ( t ) , z , w ) , i f Y ⊥ ⊥ G T ‾ , Z ‾ Z ∣ T , W P(y|do(t),do(z),w)=P(y|do(t),z,w), if Y {\perp \!\!\! \perp}_{G_{\overline{T},\underline{Z}}}Z|T,W P(y∣do(t),do(z),w)=P(y∣do(t),z,w),ifY⊥⊥GT,ZZ∣T,W
Rule 3: P ( y ∣ d o ( t ) , d o ( z ) , w ) = P ( y ∣ d o ( t ) , w ) , i f Y ⊥ ⊥ G T ‾ , Z ( W ) ‾ Z ∣ T , W P(y|do(t),do(z),w)=P(y|do(t),w), if Y {\perp \!\!\! \perp}_{G_{\overline{T},\overline{Z(W)}}}Z|T,W P(y∣do(t),do(z),w)=P(y∣do(t),w),ifY⊥⊥GT,Z(W)Z∣T,W
首先理解一下Rule 1,让我们考虑一种特殊的情况,do(t)为空集,则得到
Rule 1 with do(t) removed: P ( y ∣ z , w ) = P ( y ∣ w ) , i f Y ⊥ ⊥ G Z ∣ W P(y|z,w)=P(y|w), if Y {\perp \!\!\! \perp}_{G} Z|W P(y∣z,w)=P(y∣w),ifY⊥⊥GZ∣W,即d-separation定义,因此可得,Rule 1是 d-separation 到干预分布的泛化。
对于Rule 2,继续考虑特殊情况do(t)为空集,则得到
Rule 2 with do(t) removed: P ( y ∣ d o ( z ) , w ) = P ( y ∣ z , w ) , i f Y ⊥ ⊥ G Z ‾ Z ∣ W P(y|do(z),w)=P(y|z,w), if Y {\perp \!\!\! \perp}_{G_{\underline{Z}}}Z|W P(y∣do(z),w)=P(y∣z,w),ifY⊥⊥GZZ∣W,即后门调整,因此可得,Rule 2是 后门调整到干预分布的泛化。
对于Rule 3,继续考虑特殊情况do(t)为空集,则得到
Rule 3 with do(t) removed: P ( y ∣ d o ( z ) , w ) = P ( y ∣ w ) , i f Y ⊥ ⊥ G Z ( W ) ‾ Z ∣ W P(y|do(z),w)=P(y|w), if Y {\perp \!\!\! \perp}_{G_{\overline{Z(W)}}}Z|W P(y∣do(z),w)=P(y∣w),ifY⊥⊥GZ(W)Z∣W,首先看后面的if条件,当Z没有指向W的边时,给定W,Y和Z是d-separation的,那么这种情况下是否do(z)对y没有影响(Modularity)。
Application:frontdoor Adjustment
为了更好地理解do-calculus rules,我们再看一个例子,用do-calculus证明frontdoor Adjustment。还是针对图1的因果图,首先,我们对目标P(y|do(t))进行边缘化,得到
P ( y ∣ d o ( t ) ) = ∑ m P ( y ∣ d o ( t ) , m ) P ( m ∣ d o ( t ) ) P(y|do(t))=\sum_mP(y|do(t),m)P(m|do(t)) P(y∣do(t))=∑mP(y∣do(t),m)P(m∣do(t))
= ∑ m P ( y ∣ d o ( t ) , m ) P ( m ∣ t ) =\sum_mP(y|do(t),m)P(m|t) =∑mP(y∣do(t),m)P(m∣t)(Rule 2,T到M的后门路径被Y blocked)
= ∑ m P ( y ∣ d o ( t ) , d o ( m ) ) P ( m ∣ t ) =\sum_mP(y|do(t),do(m))P(m|t) =∑mP(y∣do(t),do(m))P(m∣t)(Rule 2,M到Y的后门路径被do(t) blocked)
= ∑ m P ( y ∣ d o ( m ) ) P ( m ∣ t ) =\sum_mP(y|do(m))P(m|t) =∑mP(y∣do(m))P(m∣t)(Rule 3,考虑W为空集的情况,得到 P ( y ∣ d o ( t ) , d o ( m ) ) = P ( y ∣ d o ( m ) ) , i f Y ⊥ ⊥ G M ‾ , T ‾ Z ∣ T P(y|do(t),do(m))=P(y|do(m)),if Y {\perp \!\!\! \perp}_{G_{\overline{M},\underline{T}}}Z|T P(y∣do(t),do(m))=P(y∣do(m)),ifY⊥⊥GM,TZ∣T, M ‾ , T ‾ = d o ( m ) \overline{M},\underline{T}=do(m) M,T=do(m))
= ∑ m P ( m ∣ t ) ∑ t ′ P ( y ∣ d o ( m ) , t ′ ) P ( t ′ ∣ d o ( m ) ) =\sum_mP(m|t)\sum_{t'}P(y|do(m),t')P(t'|do(m)) =∑mP(m∣t)∑t′P(y∣do(m),t′)P(t′∣do(m))(边缘化)
= ∑ m P ( m ∣ t ) ∑ t ′ P ( y ∣ m , t ′ ) P ( t ′ ∣ d o ( m ) ) =\sum_mP(m|t)\sum_{t'}P(y|m,t')P(t'|do(m)) =∑mP(m∣t)∑t′P(y∣m,t′)P(t′∣do(m))(Rule 2,M到Y的后门路径被t’ blocked)
= ∑ m P ( m ∣ t ) ∑ t ′ P ( y ∣ m , t ′ ) P ( t ′ ) =\sum_mP(m|t)\sum_{t'}P(y|m,t')P(t') =∑mP(m∣t)∑t′P(y∣m,t′)P(t′)(Rule 3,m到t’没有因果效应,因为m到t’没有直接因果路径)
证毕。
do-calculus被证实具有completeness,即只要因果图具有可识别性,就可以用do-calculus识别出因果效应。
Determining Identifiability from the Graph
如果因果图是可识别的我们就可以通过do-calculus识别因果效应,那么如何确定因果图是可识别的呢?我们已经学过了后门准则和前门准则,接下来我们学习更为广泛的准则。
single variable intervention
单变量干预。当只有一个干预变量时,有
unconfounded children criterion:如果存在一个变量集合可以block T到所有既是T的孩子节点又是Y的祖先节点的顶点(包括Y本身)的后门路径,则其满足unconfounded children criterion。
可以看出unconfounded children criterion是后门准则和前门准则的泛化。据此可得到一个可识别性的充分不必要条件,unconfounded children identifiability:
若结果变量集合Y和单变量T满足unconfounded children criterion和positivity,则P(Y=y|do(T=t))是可识别的。
single variable intervention和前门准则的直觉是一致的,都是隔离所有T到Y的直接因果边以外的边,只不过single variable intervention考虑了后门准则的情况。
学习了一个充分条件,还可以据此得到一个必要不充分条件:如果每一个M既是T的孩子也是Y的祖先,且每个M都是都可以被block。
这一章的内容比较硬核,我们学习的知识是最简单的单个预变量情况,多个预变量的情况我也还没学,如果大家感兴趣可以一起交流。本章进一步扩展了可识别性和识别方法,下一章开始,我们学习如何评估因果效应。

















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









