









在分享今天的内容之前,先对大家的问的频率比较高的问题做个解答。今天分享的文章内容比较多,建议大家收藏起来慢慢看。
常见误解
误解一:使用本地知识库以后,大模型是不是能够自学习
在之前的文章 DeepSeek+dify 本地知识库:真的太香了 中已经说了。

误解二:使用了知识库以后一定能够检索到
- 首先:向量是不确定性的,它是对问题的模糊描述,
- 比如
广东和广西这两个字在我们的认知里这两个词语是完全不一样的 - 但是在向量的认知里,他们就相近
- ragflow中不管是关键词还是知识图谱都是为了解决这些问题
- 比如
- 其次:向量过程会部分内容丢失
- 我们通过滑动窗口叠加能解决大部分,但是,每个模型的处理不一样,没法保障
误解三: 不管是使用dify还是ragflow都应该达到我们想要的效果
不管是哪个厂商,他们提供的都是应用平台,都具备一定的能力,但是这个能力,你能不能用上?用好是另一回事。
官方给了很多参数的调整,我们需要根据自己的文档不断地调整参数。找到适合自己文档的参数。
最最最重要的是,每家的文档和写作习惯和格式都不一样,也就是数据格式,没有标准,没法直接使用。
ragflow提供了不同场景的数据文档解析,但是你的文档一定是它的标准吗?
误解四:用了知识库,什么都能解决
在误解一中已经提到了,知识库解决的是大模型不能更新的问题的,以及大模型上下文长度限制的问题。
不擅长根据A文档的格式模仿写出文档B,这是大模型干的事,如果行文固定,通过微调可以做到。
也不擅长进行文档总结。这也是大模型干的事。
ragflow中的团队与权限推
在ragflow中,每个用户都是一个团队,用户注册以后,就是一个独立的团队。
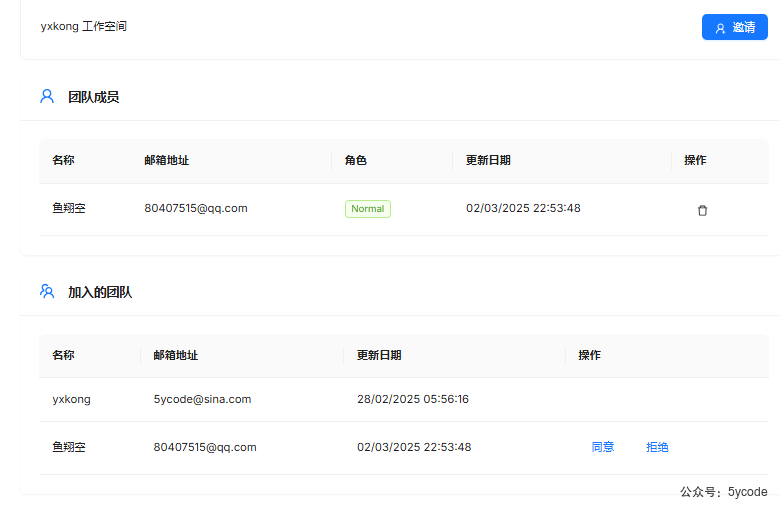
团队成员是你邀请的人,有两个角色Invite 和Nomal
Invite是邀请以后的状态Nomal是被邀请人同意后的状态- 团队负责人可以可以删除团队成员
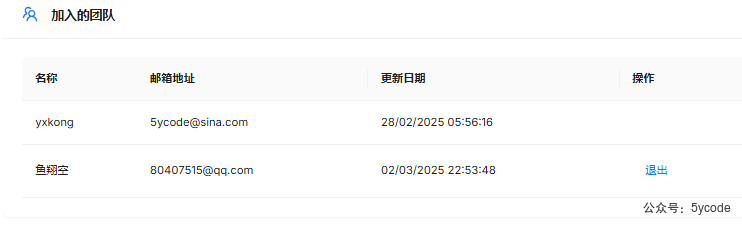
加入的团队
- 没有操作按钮就是自己的团队,这个时候自己的角色就是
owner - 别人邀请你以后,在你的
加入的团队那里就出现同意和拒绝的操作 - 如果你
同意以后,操作那里就变成了退出
作用
强调了那么多,用途是什么?我们举个例子来说明下
| 角色 | 知识库 | 权限范围 |
|---|---|---|
| 公司 | 公司知识库 | 知识专人维护 |
| 部门 | 部门知识库 | 部门人员维护 |
| 小组 | 小组知识库 | 小组人员维护 |
| 个人 | 个人知识库 | 只有个人可操作 |
在dify是没有权限管理的,在dify中我们通过聊聊dify权限验证的三种方案及实现可以个人粒度的权限控制,但是没有角色的概念。
在ragflow 我们可以通过添加不同的维度的用户,来控制知识库的权限。
- 比如公司知识库,专人维护后,发布一个agent,公司的公开的文档,所有人可以通过
agent使用 - 部门的知识库,部门人员维护,并发布部门agent(对所有公布,和官方的人聊了,后续会给agent加权限)
在ragflow中,我们在发布的api外面套一层代理,就解决了所有的权限问题。
但是我们一般不会这么玩,既然使用了ragflow,那么我们会通过api功能化来抽取企业的知识,切片,向量、灌入ragflow。
知识库详解
文档语言
在文档语言中支持四种,分别是
- 中文
- 英文
- vietnamese(越南语)
- Portuguese (Brazil) 巴西葡萄牙语
知识库权限设置

只有我的时候,这个知识库归属于个人团队: 团队的所有人员都能操作该知识库。需要注意的是有了权限可以删除的。
嵌入模型
用于嵌入块的嵌入模型。 一旦知识库有了块,它就无法更改。 如果你想改变它,你需要删除所有的块。
关于哪个向量模型比较好,大家可以参考下
https://github.com/netease-youdao/BCEmbedding/blob/master/Docs/EvaluationSummary/rag_eval_multiple_domains_summary_zh.md
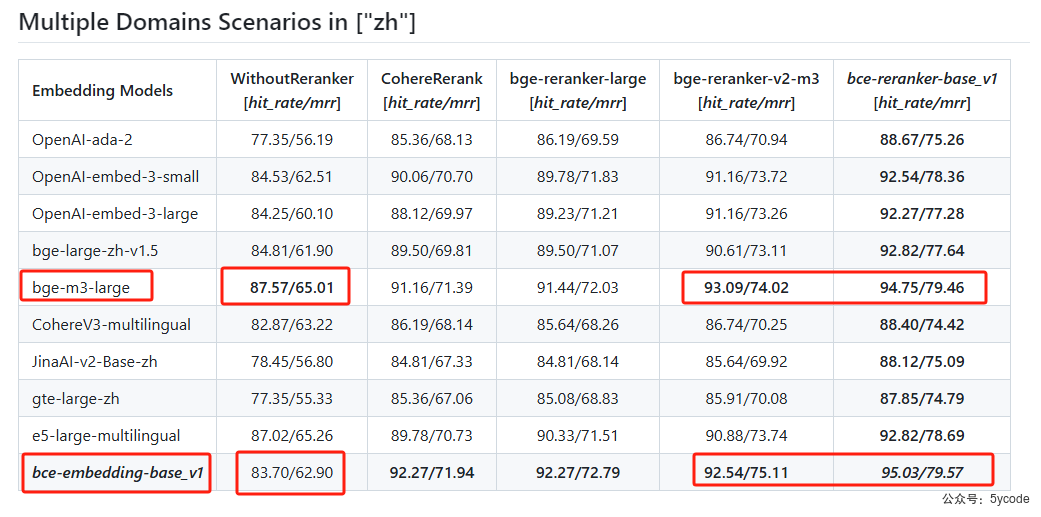
在不使用reranker的情况下,bge-m3-large效果是最好的。bce-embedding-base_v1的效果也不差。
其实效果哪个好,综合一下各大云平台提供的嵌入模型就知道了。这个肯定是最有效的办法。
解析方法(chunk)
每个解析方法选中以后,都可以在右侧查看具体的说明。
General分块
通用分块支持格式为DOCX、EXCEL、PPT、IMAGE、PDF、TXT、MD、JSON、EML、HTML。
此方法将简单的方法应用于块文件:
- 系统将使用视觉检测模型将连续文本分割成多个片段。
- 接下来,这些连续的片段被合并成Token数不超过“Token数”的块。
Q&A 分块
问答分块支持 excel 和 csv/txt 文件格式。
- 如果文件是 excel 格式,则应由两个列组成 没有标题:一个提出问题,另一个用于答案。
- 如果文件是 csv/txt 格式 以
UTF-8编码且用TAB作分开问题和答案的定界符。
未能遵循上述规则的文本行将被忽略,并且 每个问答对将被认为是一个独特的部分。
Resume分块
简历分块,支持的文件格式为DOCX、PDF、TXT。
在选择此分块方法后,ragflow会将上传的简历解析成一个结构化数据。
Manual分块
手册仅支持PDF。需要调大tokens
我们假设手册具有分层部分结构。 我们使用最低的部分标题作为对文档进行切片的枢轴。 因此,同一部分中的图和表不会被分割,并且块大小可能会很大。
Table分块
表格分块,支持EXCEL和CSV/TXT格式文件。
以下是一些提示:
- 对于 csv 或 txt 文件,列之间的分隔符为
TAB。 - 第一行必须是列标题。
- 列标题必须是有意义的术语,以便我们的大语言模型能够理解。 列举一些同义词时最好使用斜杠_‘/’_来分隔,最好使用方括号枚举值,例如 ‘gender/sex(male,female)’.
- 表中的每一行都将被视为一个块。
以下是标题的一些示例:
- 供应商/供货商
TAB颜色(黄色、红色、棕色)TAB性别(男、女)TAB'尺码(M、L、XL、XXL) - 姓名/名字
TAB电话/手机/微信TAB最高学历(高中,职高,硕士,本科,博士,初中,中技,中 专,专科,专升本,MPA,MBA,EMBA
Paper分块
论文分块,仅支持PDF文件。LLM会将论文将按其部分进行切片,例如_摘要、1.1、1.2_等。
这样做的好处是LLM可以更好的概括论文中相关章节的内容, 产生更全面的答案,帮助读者更好地理解论文。 缺点是它增加了 LLM 对话的背景并增加了计算成本, 所以在对话过程中,你可以考虑减少‘topN’的设置。
Book分块
书籍分块,支持的文件格式为DOCX、PDF、TXT。
由于一本书很长,并不是所有部分都有用,如果是 PDF, 请为每本书设置_页面范围_,以消除负面影响并节省分析计算时间。
Laws 分块
法律文件分块,支持的文件格式为DOCX、PDF、TXT。
法律文件有非常严格的书写格式。 我们使用文本特征来检测分割点。
chunk的粒度与’ARTICLE’一致,所有上层文本都会包含在chunk中。
Presentation 分块
演示稿分块,支持的文件格式为PDF、PPTX。
每个页面都将被视为一个块。 并且每个页面的缩略图都会被存储。您上传的所有PPT文件都会使用此方法自动分块,无需为每个PPT文件进行设置。
One分块
单一文档,支持的文件格式为DOCX、EXCEL、PDF、TXT。
对于一个文档,它将被视为一个完整的块,根本不会被分割。
如果你要总结的东西需要一篇文章的全部上下文,并且所选LLM的上下文长度覆盖了文档长度,你可以尝试这种方法。
Tag分块
使用“标签”作为分块方法的知识库应该被其他知识库使用,以将标签添加到其块中,对这些块的查询也将带有标签。
使用“标签”作为分块方法的知识库不应该参与 RAG 过程。
此知识库中的块是标签的示例,它们演示了整个标签集以及块和标签之间的相关性。
此块方法支持EXCEL和CSV/TXT文件格式。
如果文件为Excel格式,则它应该包含两列无标题:一列用于内容,另一列用于标签,内容列位于标签列之前。可以接受多个工作表,只要列结构正确即可。
如果文件为 CSV/TXT 格式,则必须使用 UTF-8 编码并以 TAB 作为分隔符来分隔内容和标签。
在标签列中,标签之间使用英文 逗号。
不符合上述规则的文本行将被忽略,并且每对文本将被视为一个不同的块。
标签库
大部分的解析方法都可以选择标签库。
实战演练
我们通过下面的演示稿,来演示下。

对应资料的网盘链接
https://pan.quark.cn/s/918266bd423a
https://pan.baidu.com/s/1IjddCW5gsKLAVRtcXEkVIQ?pwd=ech7
知识库设置说明

- 在数据集里,上传以后,默认解析方法和知识库的设置一样
1。 - 点击
2出现下拉操作,我们选择3
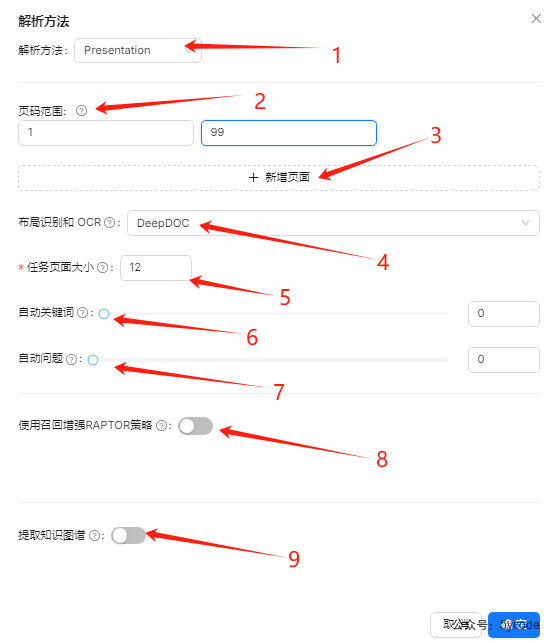
- 我们在
1选择解析方法为Presentation - 我们可以在
2可以设置解析的页码,可以通过3添加新的页面,过滤掉一些不想要的信息 - 在
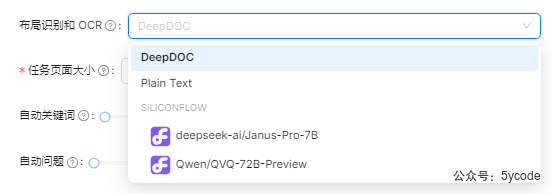
4使用deepDoc做布局识别和OCR,当然也可以用在线服务,如果ragflow是一张张的识别处理,都会同步给在线服务。 5这里相当于分组了,根据你的文档,进行分组,将上下文有关联的尽可能分到一个组里- 自动关键词
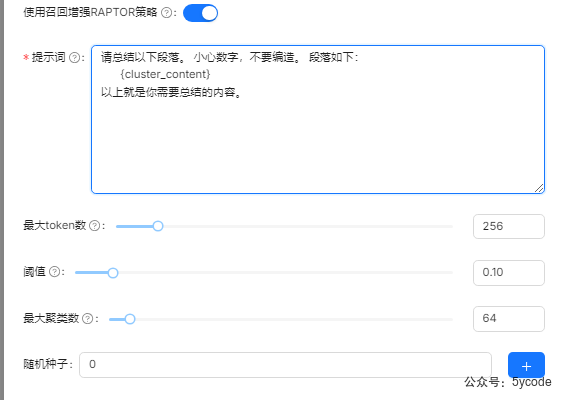
6,我们可以利用大模型从每个块里提取指定的关键词,多路检索。所以会消耗一定的tokens。 - 自动问题
7,这个看自己的需求吧 - RAPTOR策略
8 - 提取知识图谱
9
布局识别和OCR补充图
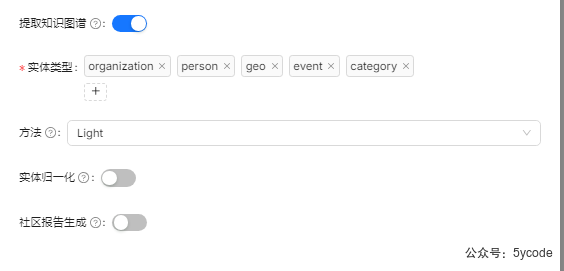
Light:实体和关系提取提示来自 GitHub - HKUDS/LightRAG:“LightRAG:简单快速的检索增强生成”
General:实体和关系提取提示来自 GitHub - microsoft/graphrag:基于图形的模块化检索增强生成 (RAG) 系统
建立3个知识库
使用同一份资料在不同的解析方法下看下最终的检索效果。
知识库1
解析方法配置如下。
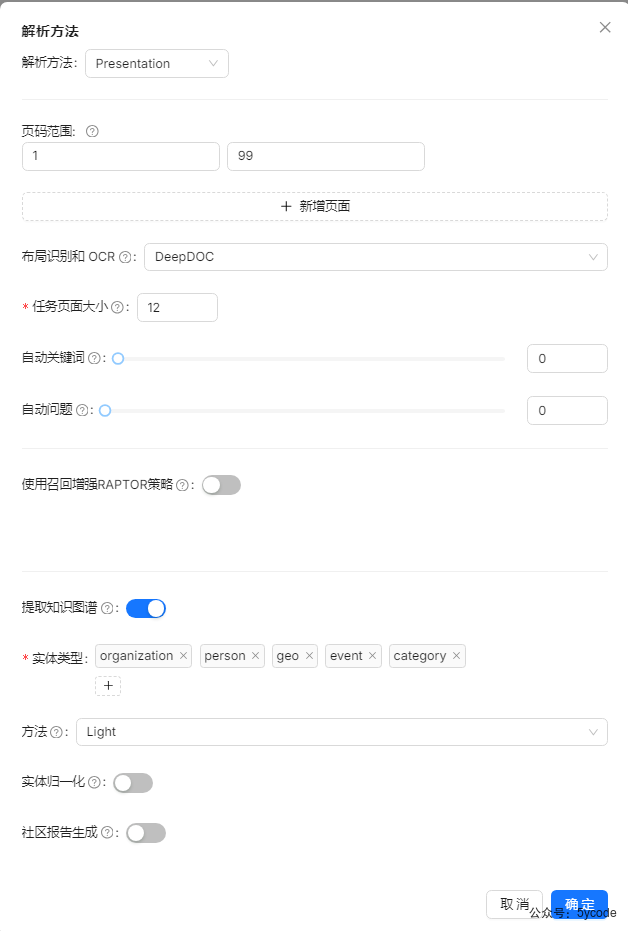
- 使用演示稿的解析方法
- 提取知识图谱
知识库2
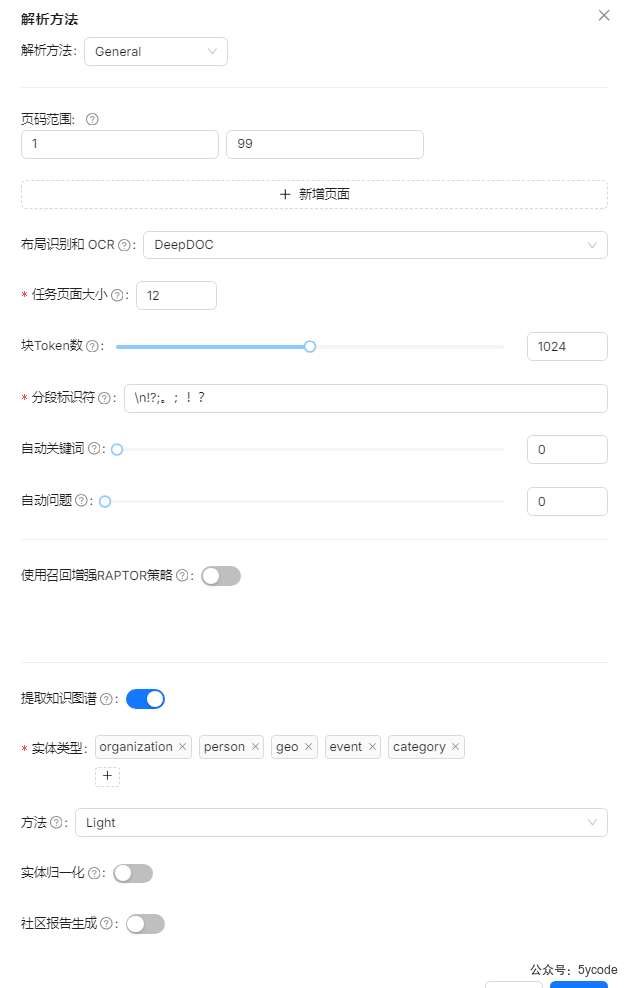
使用通用解析方法,解析
实在是搞不动了,本来这个知识库测试做了知识图谱的,但是执行了一天都没有把这个知识图谱跑完。

开启图谱查询的时候,前端返回
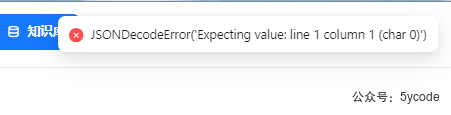
从后端日志上看,已经查到了。但是转换的时候出错了。

知识库3
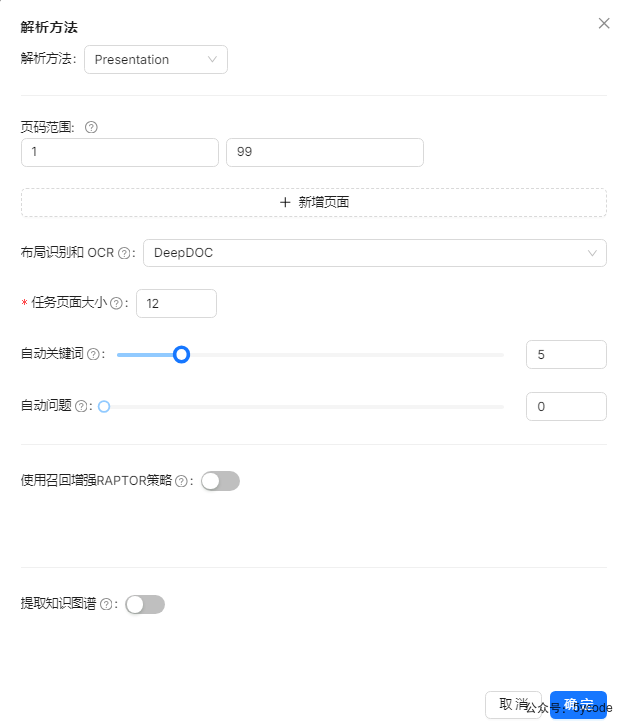
使用演示稿+自动关键词创建知识库
报错
rate limiting 限速
刚开始使用的硅基流动,报rate limiting,然后换本地,换其他
同样deepseek-r1:32b在各个平台上的速率。
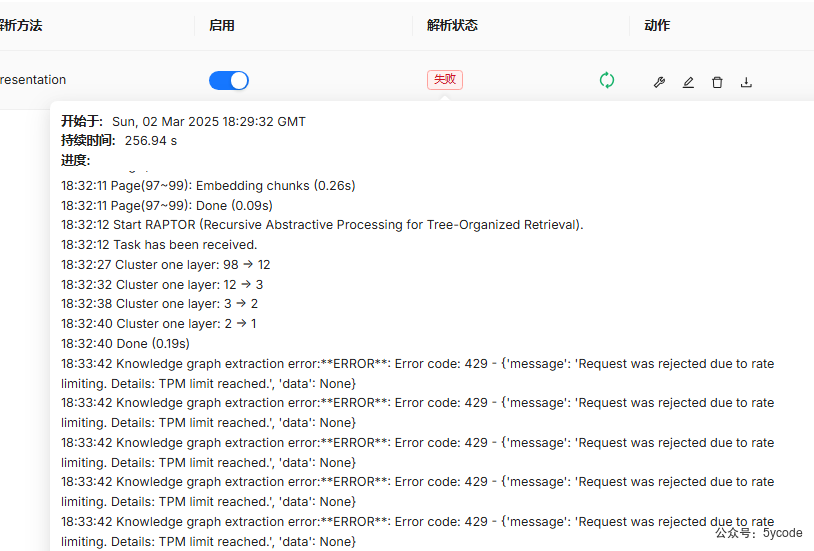
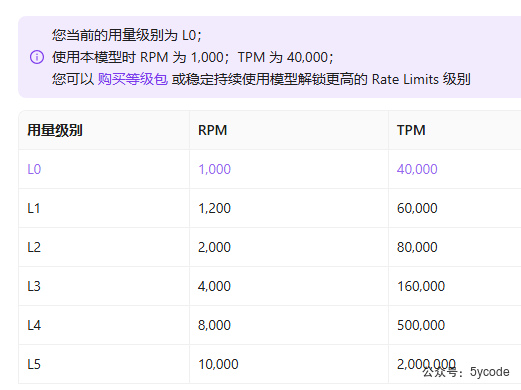
硅基流动是限制的最狠的,根据每个月的消费金额不同限速。
- RPM 为一分钟最多发起的请求数,请求数个人够用了
- TPM 为一分钟最多允许的token数,token数远远不够

阿里百炼:
- QPM 每分钟调用次数是15000
- TPM 每分钟 120万 ,并发不高的话够用了
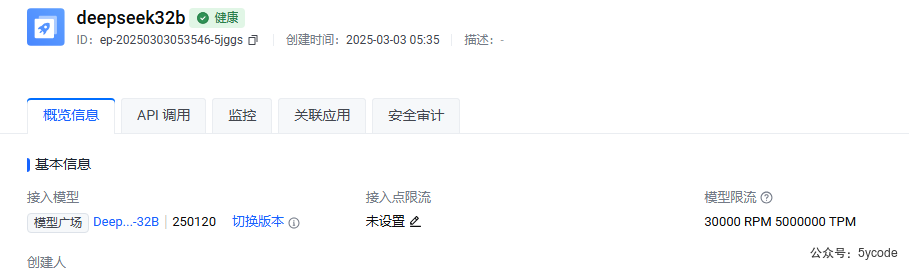
火山引擎:
- RPM每分钟调用次数是30000
- TPM每分钟 500万
怎么选,看大家的使用场景
开启PAPTOR报 Fail to bind LLM used by PAPTOR

这个问题我以为是我中途切换了模型了,实际上用单一模型也是这样,看官方的issue也没有解决,先搁置。
耗时长
一方面是开启的选项太多,特别吃内存和gpu。另一方面是平台的限流。
- 使用本地32b模型 关键词生成要200多秒,使用本地14b模型,关键词生成也得1分多钟
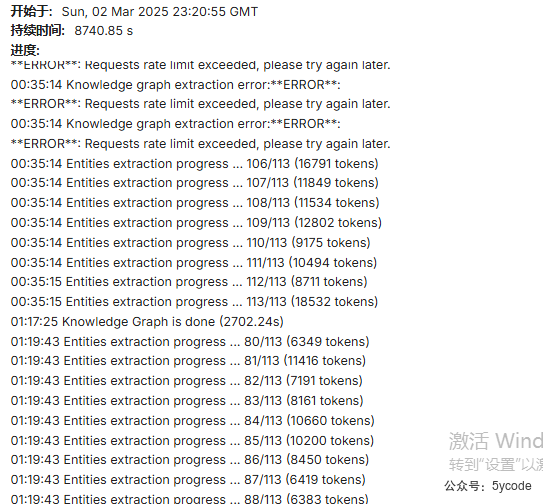
- 就一个99页的演示稿的知识图谱的提炼,Knowledge Graph is done (4816.26s),后续找下如何优化


耗费token多
看后台日志就能知道,真的很费token,同时执行时间超长,一个知识库干完了100万的token。
无法访问百炼
报下面的错误
[ERROR]Fail to bind LLM used by Knowledge Graph: **ERROR**: **ERROR**: HTTPSConnectionPool(host='dashscope.aliyuncs.com', port=443): Max retries exceeded with url: /api/v1/services/aigc/text-generation/generation (Caused by NameResolutionError("<urllib3.connection.HTTPSConnection object at 0x7f3c4c633ac0>: Failed to resolve 'dashscope.aliyuncs.com' ([Errno -3] Temporary failure in name resolution)"))
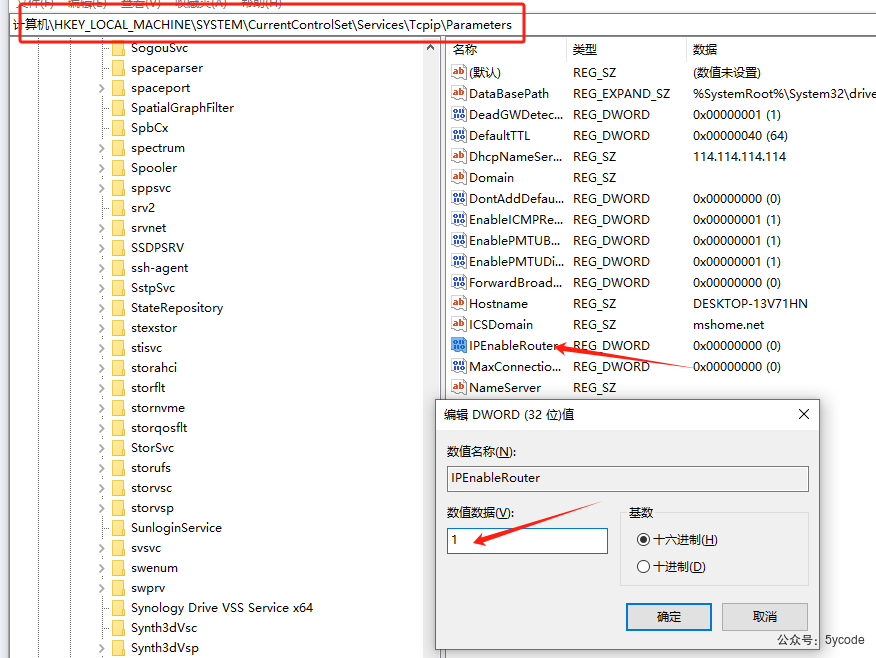
修改以后,还会出这个问题。
测试助手
测试1
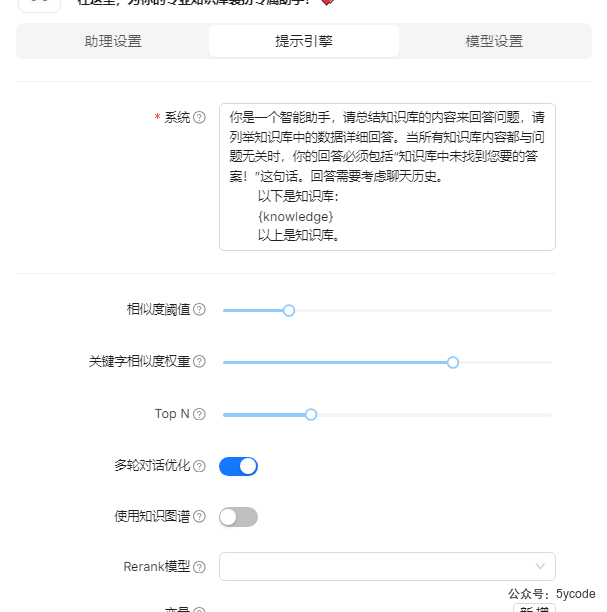
助手配置如下
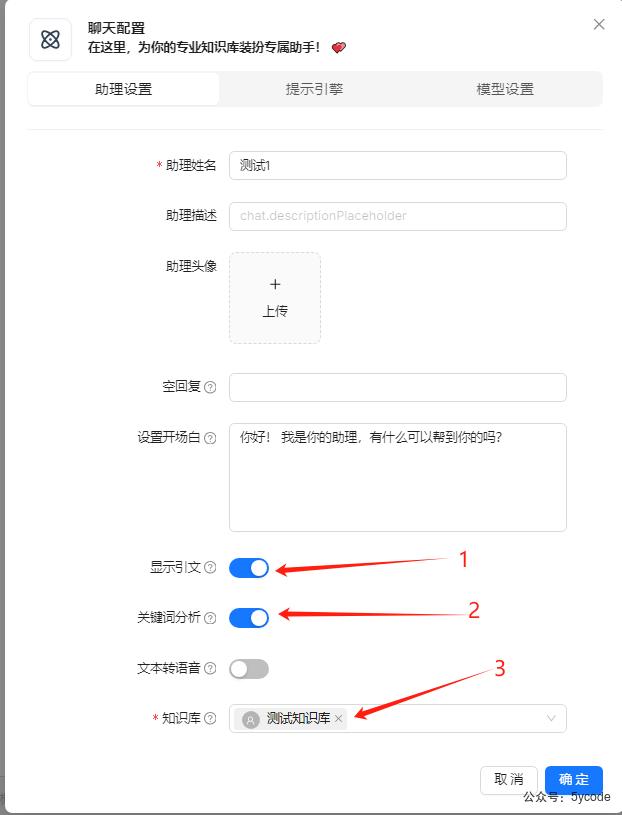
- 设置显式引文
1 - 关键词分析就不用管了
- 指定知识库
3
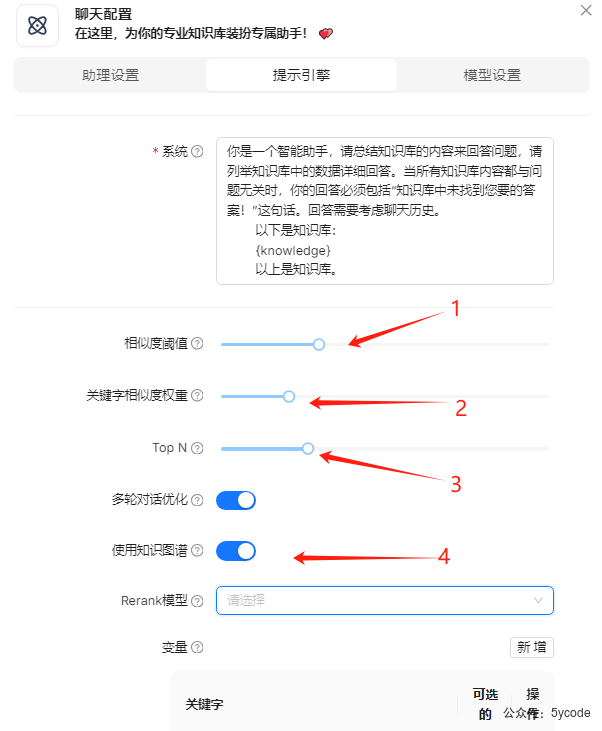
- 相似度阈值设置为
0.3 - 关键字相似度权重
0.2,如果你的文档关键词很确定,可以提高关键字词匹配的权重。要不然一个关键词在多个片段里出现的时候,会让你怀疑检索。 - 开启使用知识图谱
4
数据集解析完以后,我们可以通过检索测试,不断地调整检索的参数,来找到适合自己的
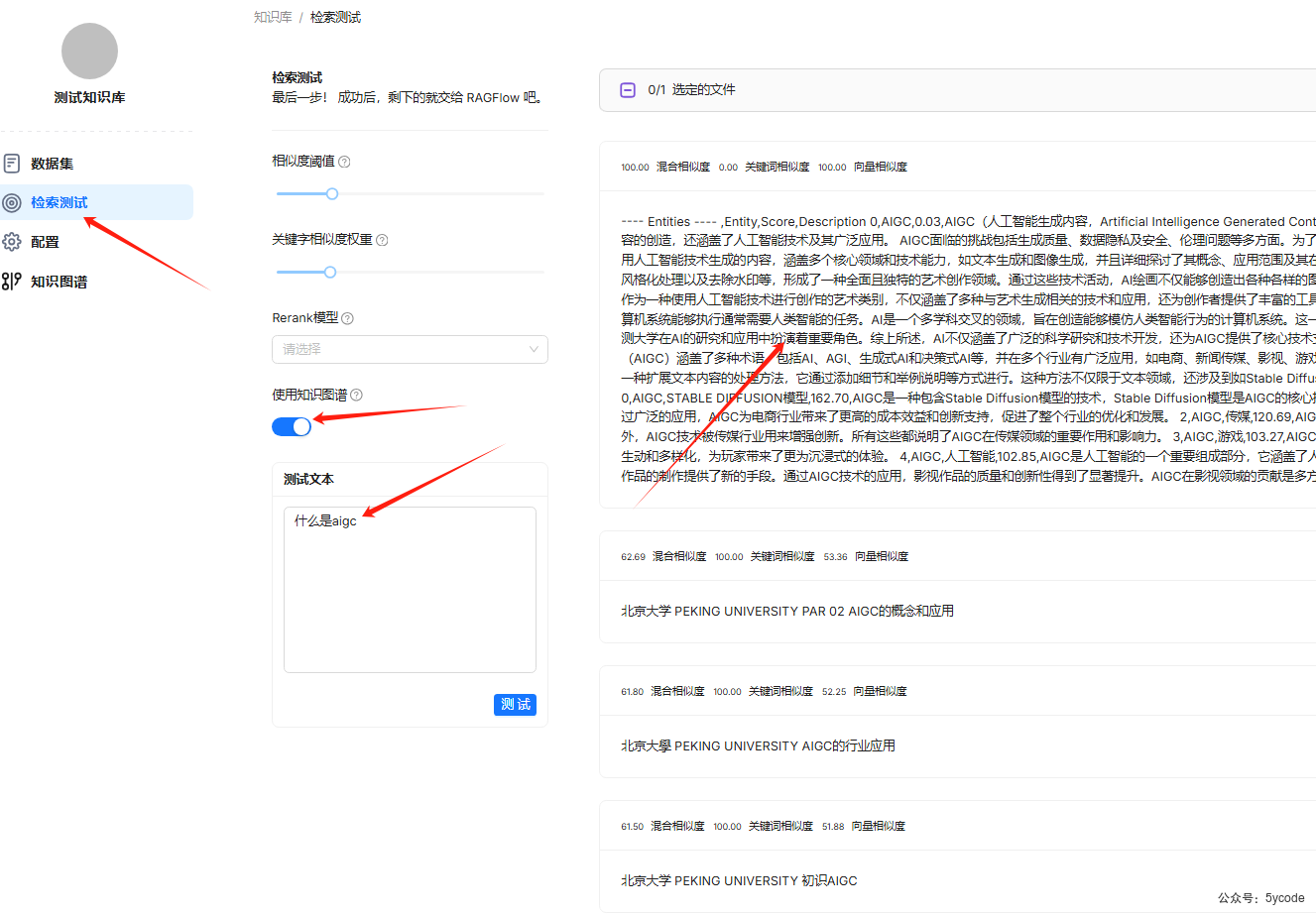
最上面匹配到的是知识图谱相关的内容。
聊天设置
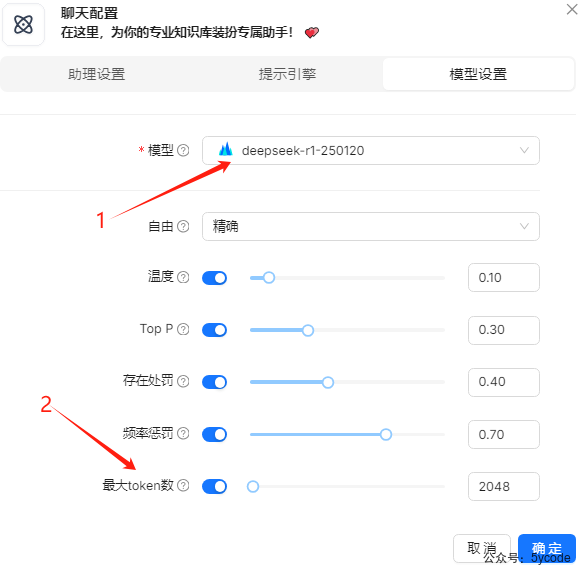
这块都统一用deepsek-r1 250120 (火山引擎的)
提问效果
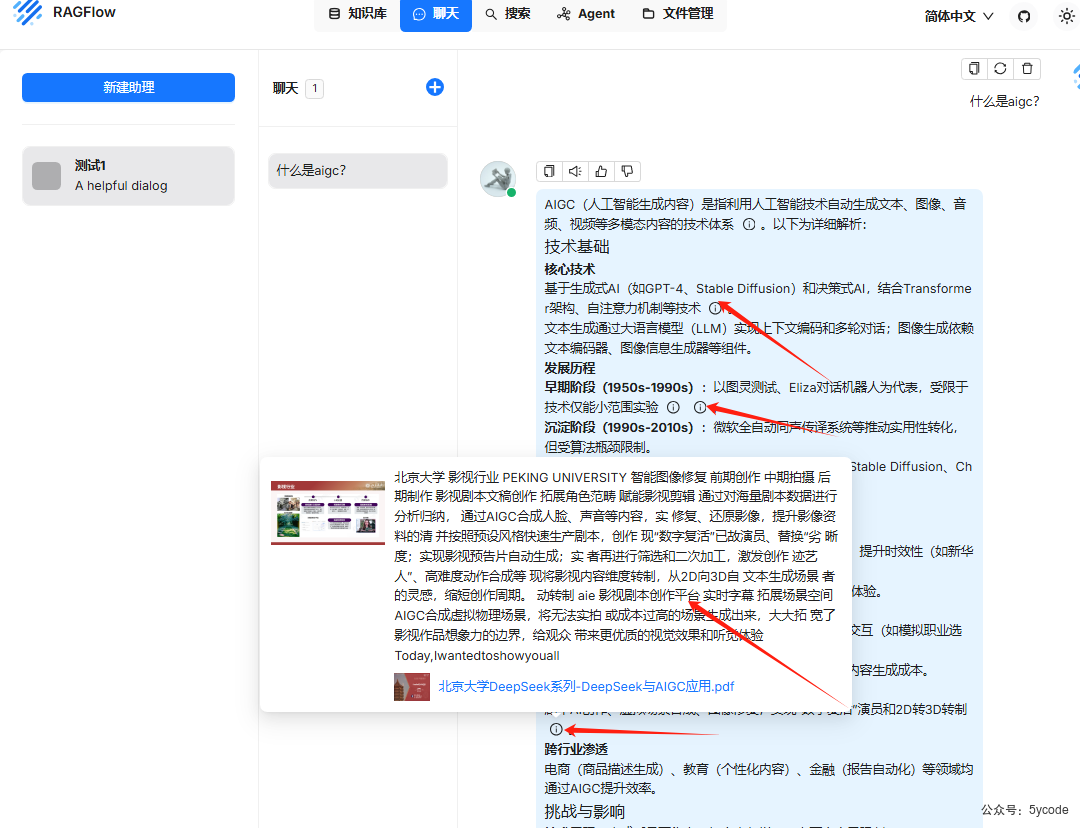
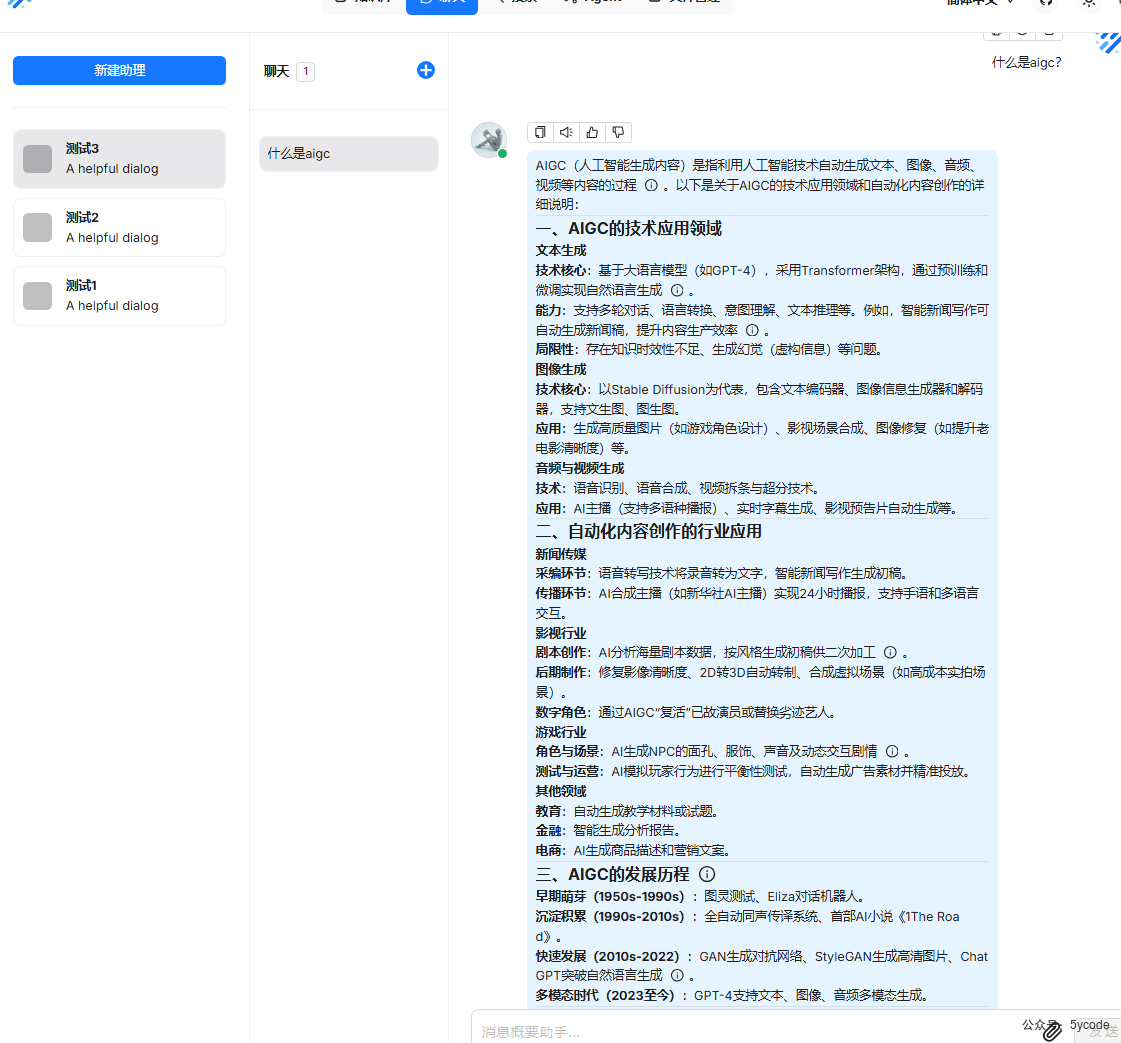
测试2
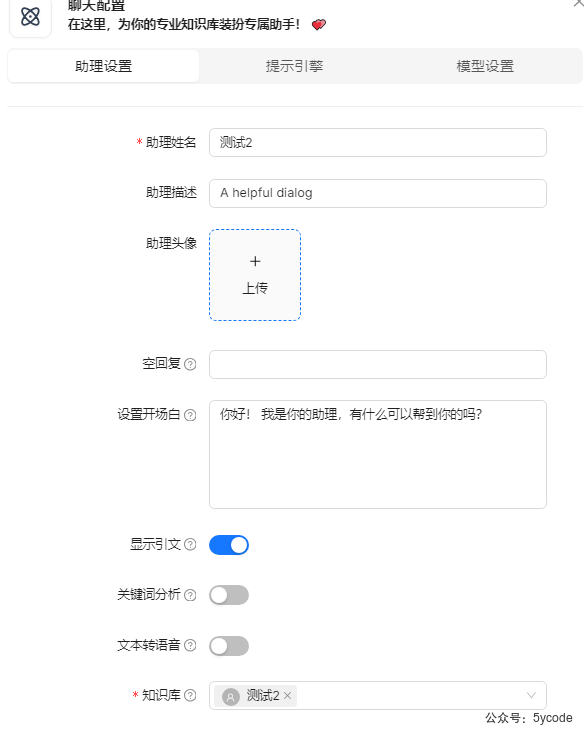
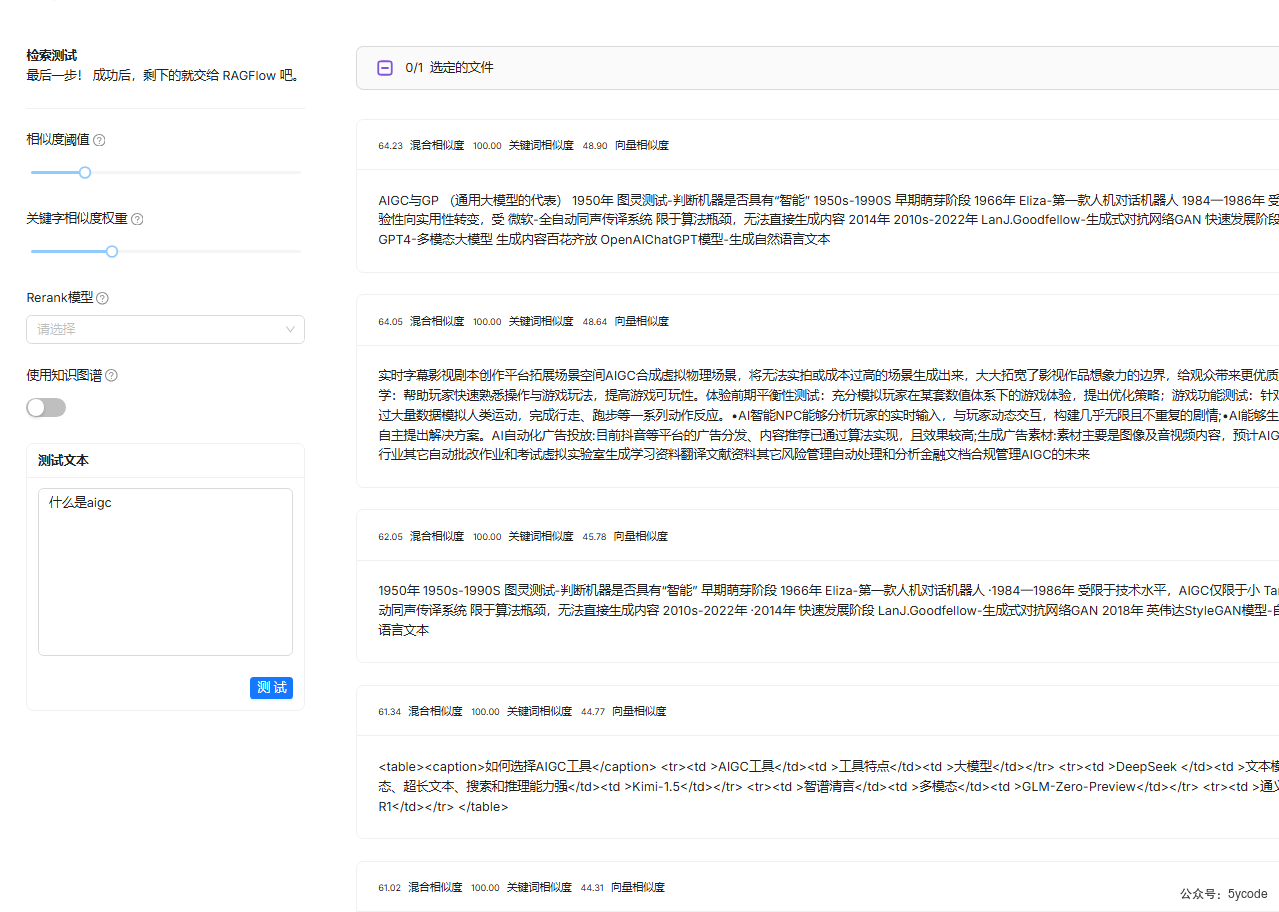
知识库检索结果
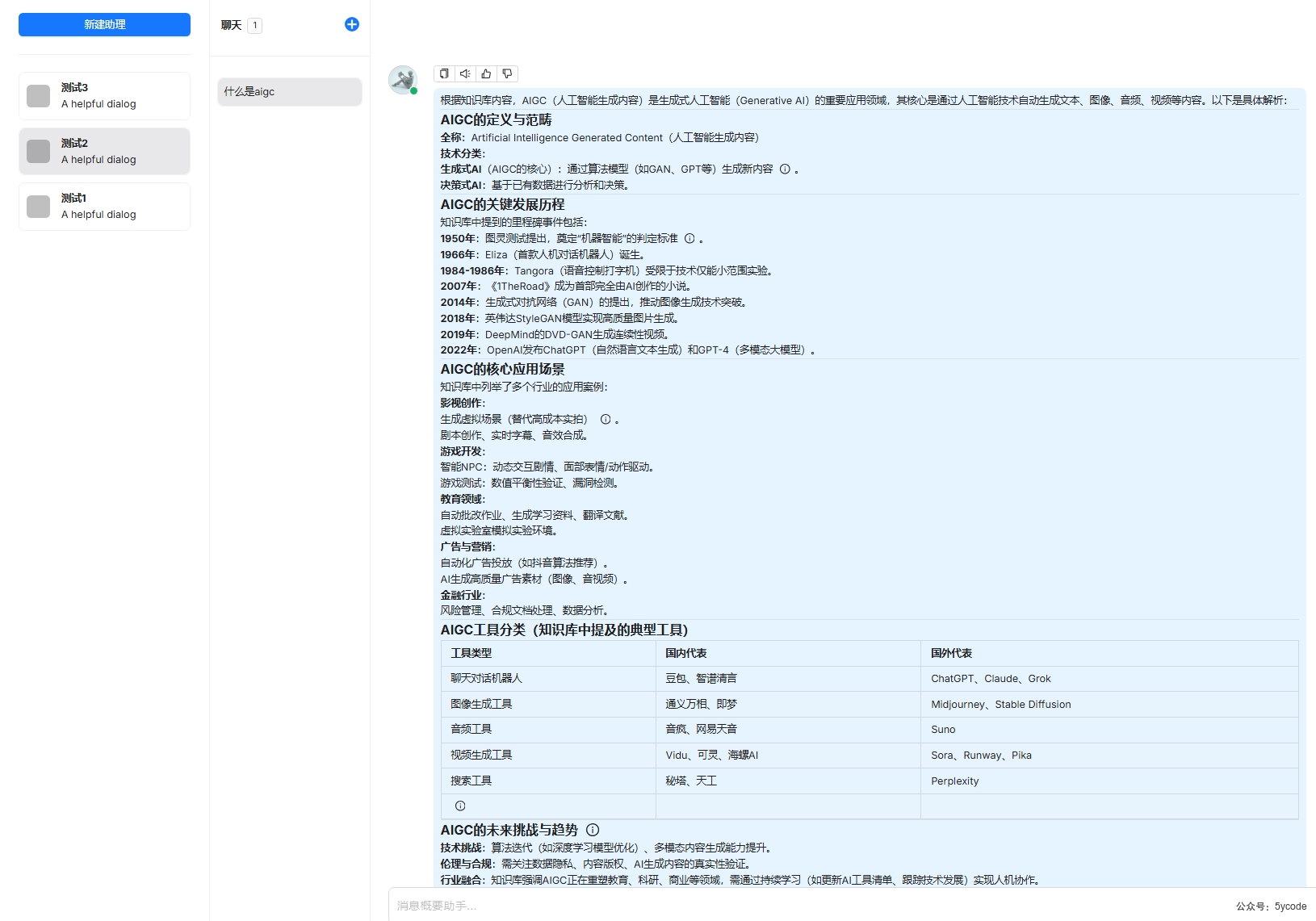
聊天框效果。
测试3
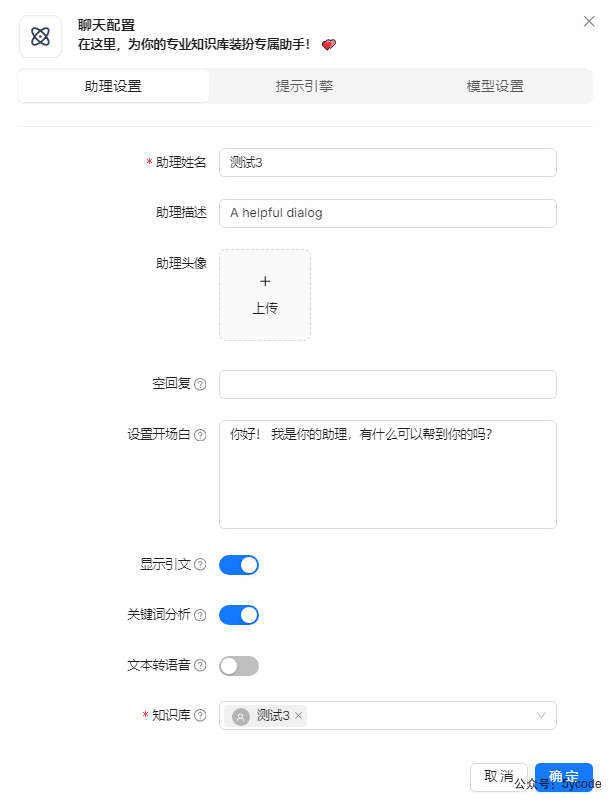
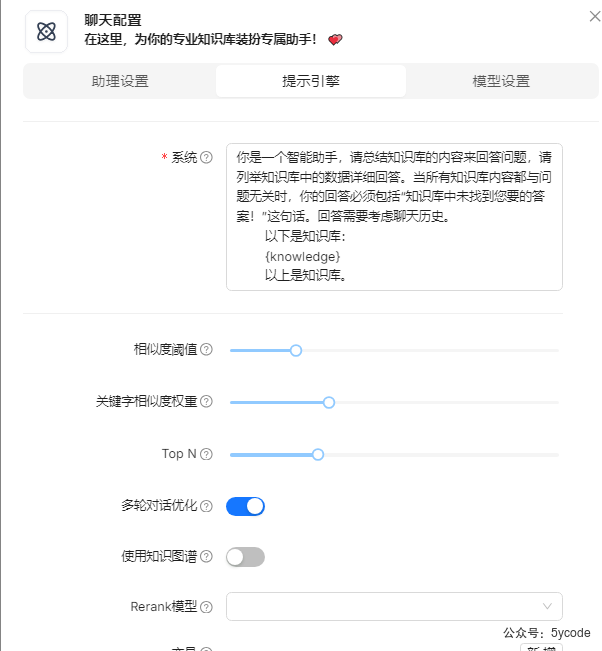
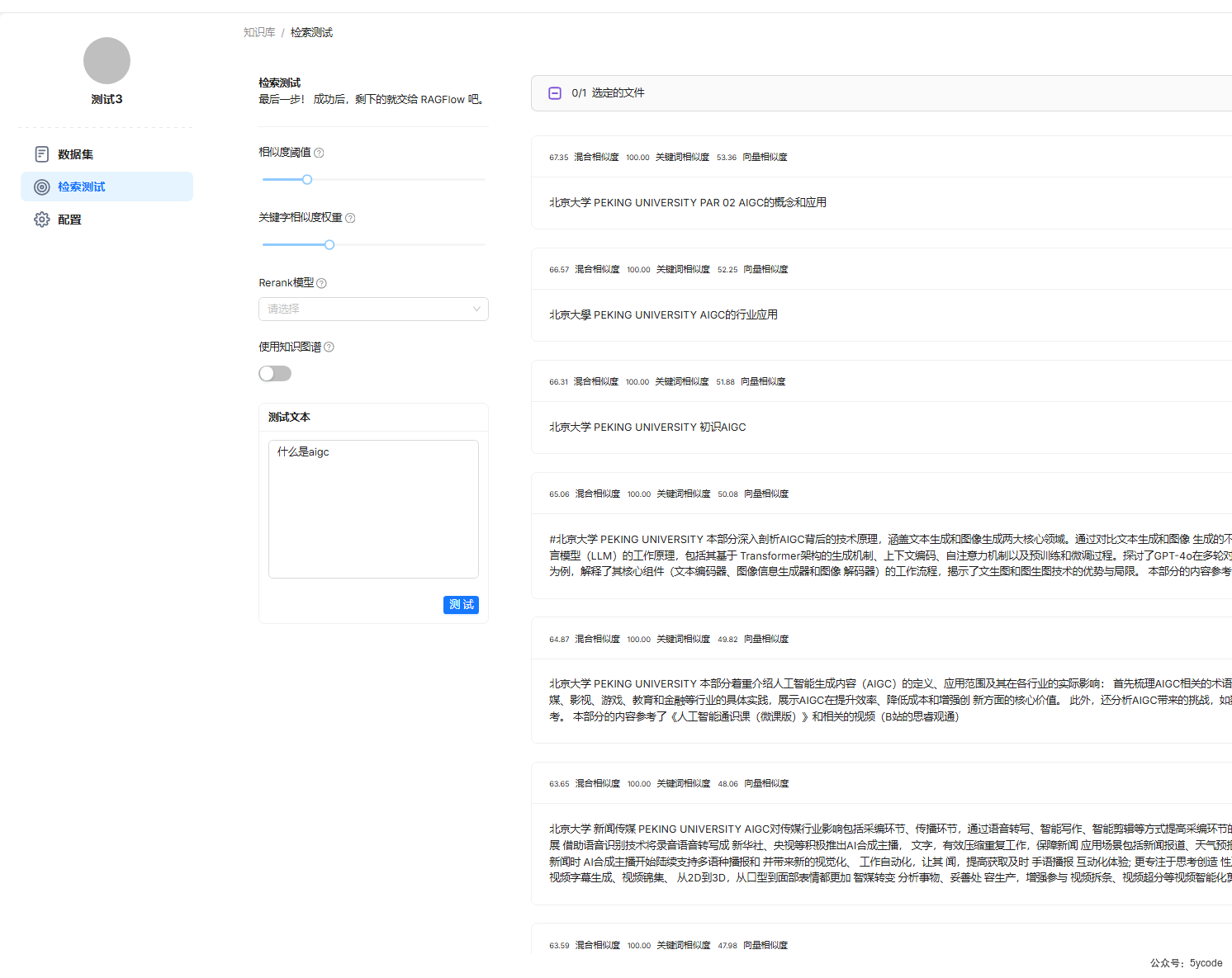
知识库检索效果。
总结
- 从知识检索测试来说,开启知识图谱的检索效果最好。
- 从聊天效果来说,反而通用的更符合我的口味。
- 我的需求不明确,只是随意拿着一份文档测试,测试没有目标性,只是体验下检索的效果以及差异性,这个需要专业的测试。
注意事项
失败以后不要清空chunk
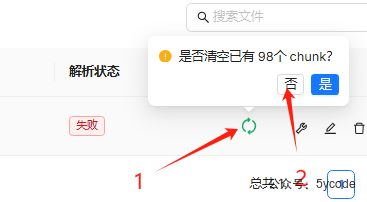
- 如果你用同一个模型,中途失败了,点击
1不要清空已有chunk,任务可以继续,否则会极其耗时 - 如果你切换模型,会自动清空chunk
docker崩溃
docker崩溃以后把本机的软件都关闭下,同时开启ollama和 docker,特别吃资源,本地ollama响应速度又慢,这就很容易导致崩溃。
- 当你把报错丢给ai后,不要随意相信ai的回复去执行
wls --update,会让你先执行wsl --unregister docker-desktop和wsl --unregister docker-desktop-data然后docker镜像全部丢失,还得重新下一遍
注意ragflow的数据映射
在docker-compose-base.yml 中 volumes配置,ragflow都是用的逻辑卷,一旦执行了上一步操作,整个数据就没了,得重新注册,创建知识库等。
建议将数据映射到docker目录下的volumes目录,比如./volumes/mysql/:/var/lib/mysql
自动关键词
- 对关键词检索需求不是特别高的,最好不要开启,特别费资源。(因为开了这个跑崩了docker)
- 拆解出来的关键词和语义没有什么关联,效果可能不太好,如何使用需要根据自己的场景调整。
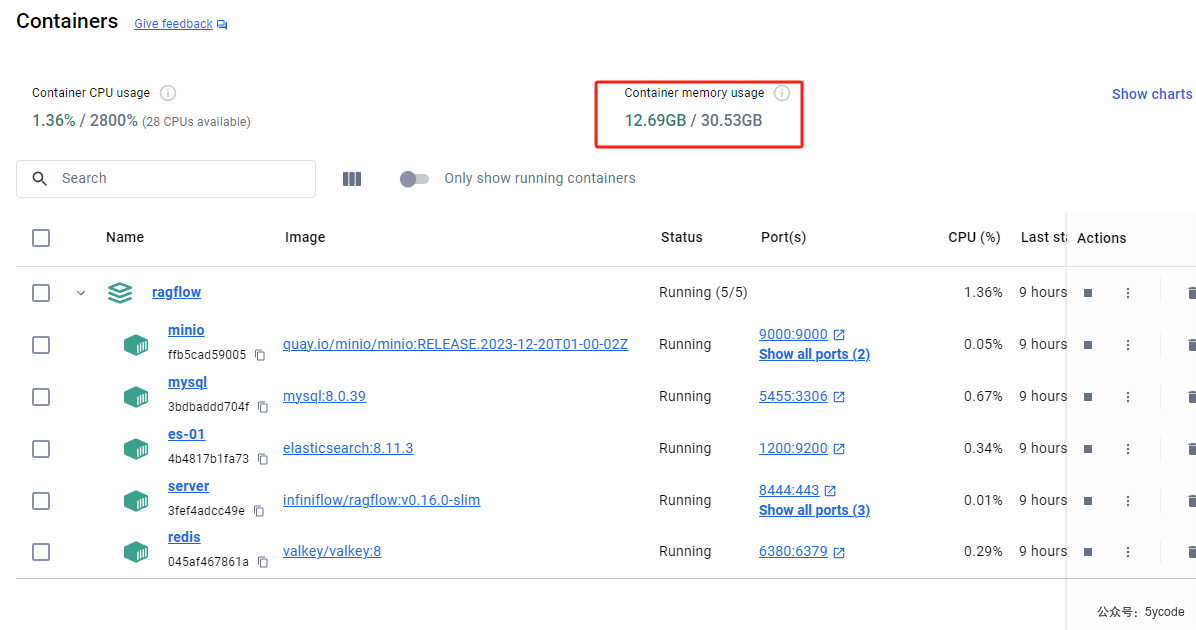
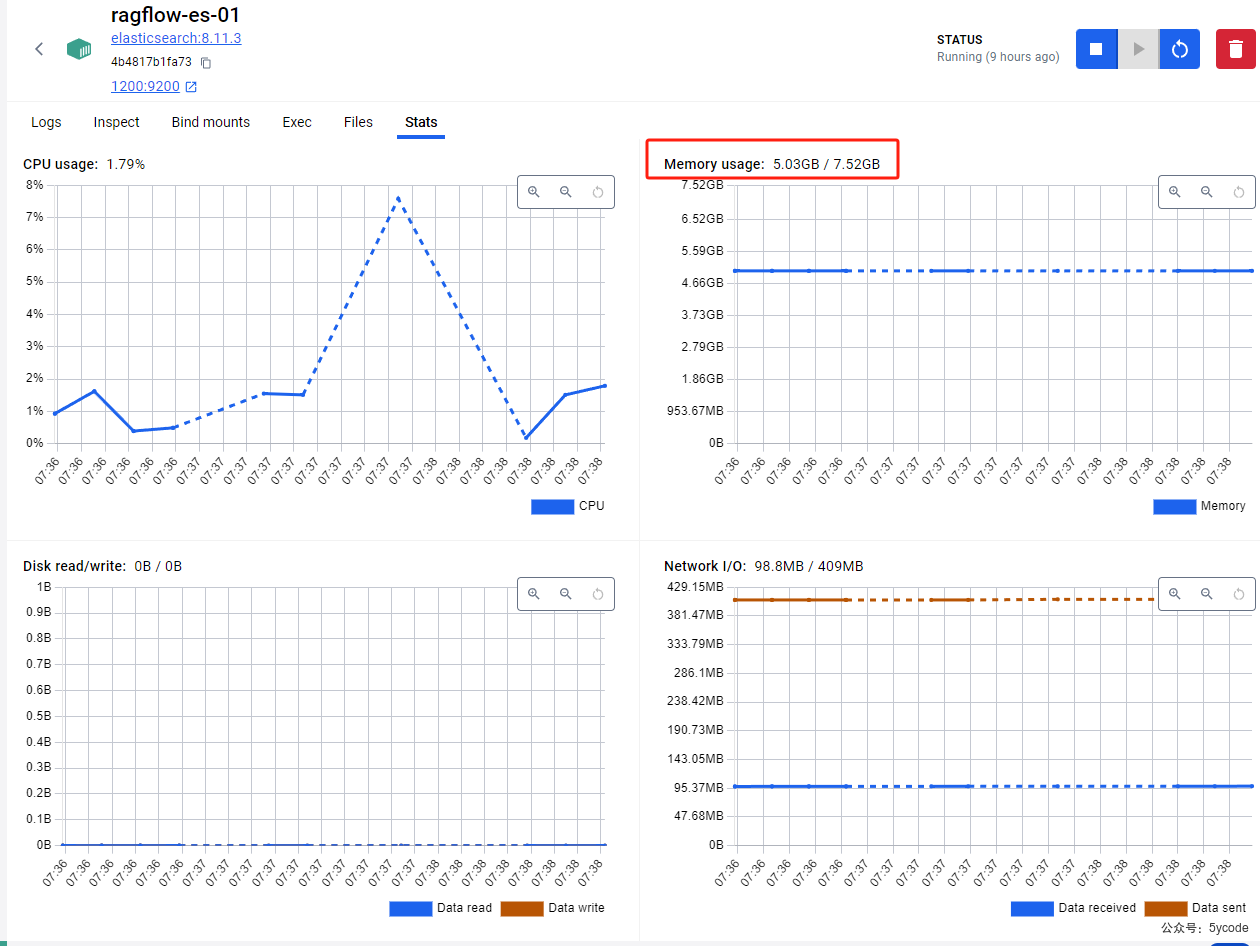
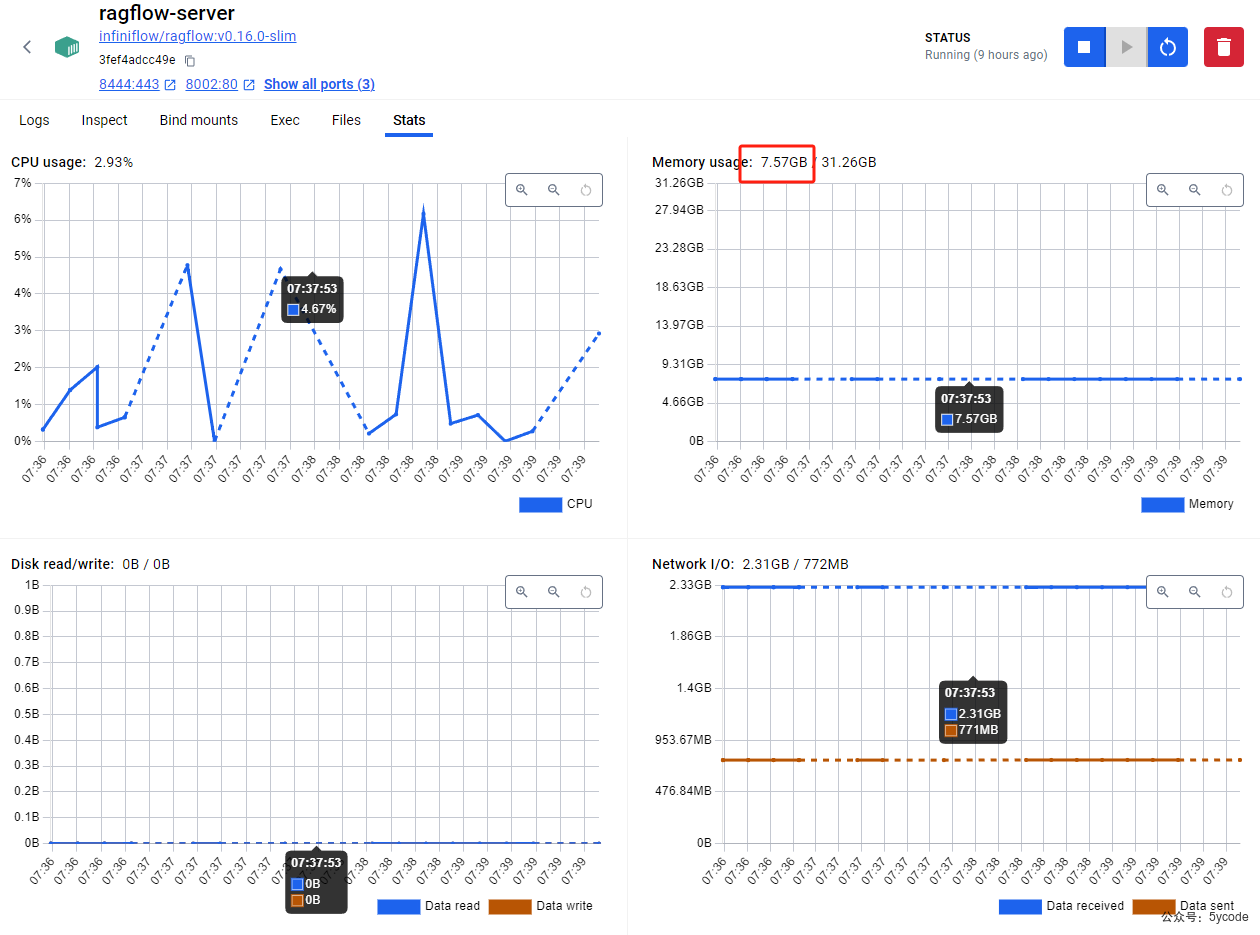
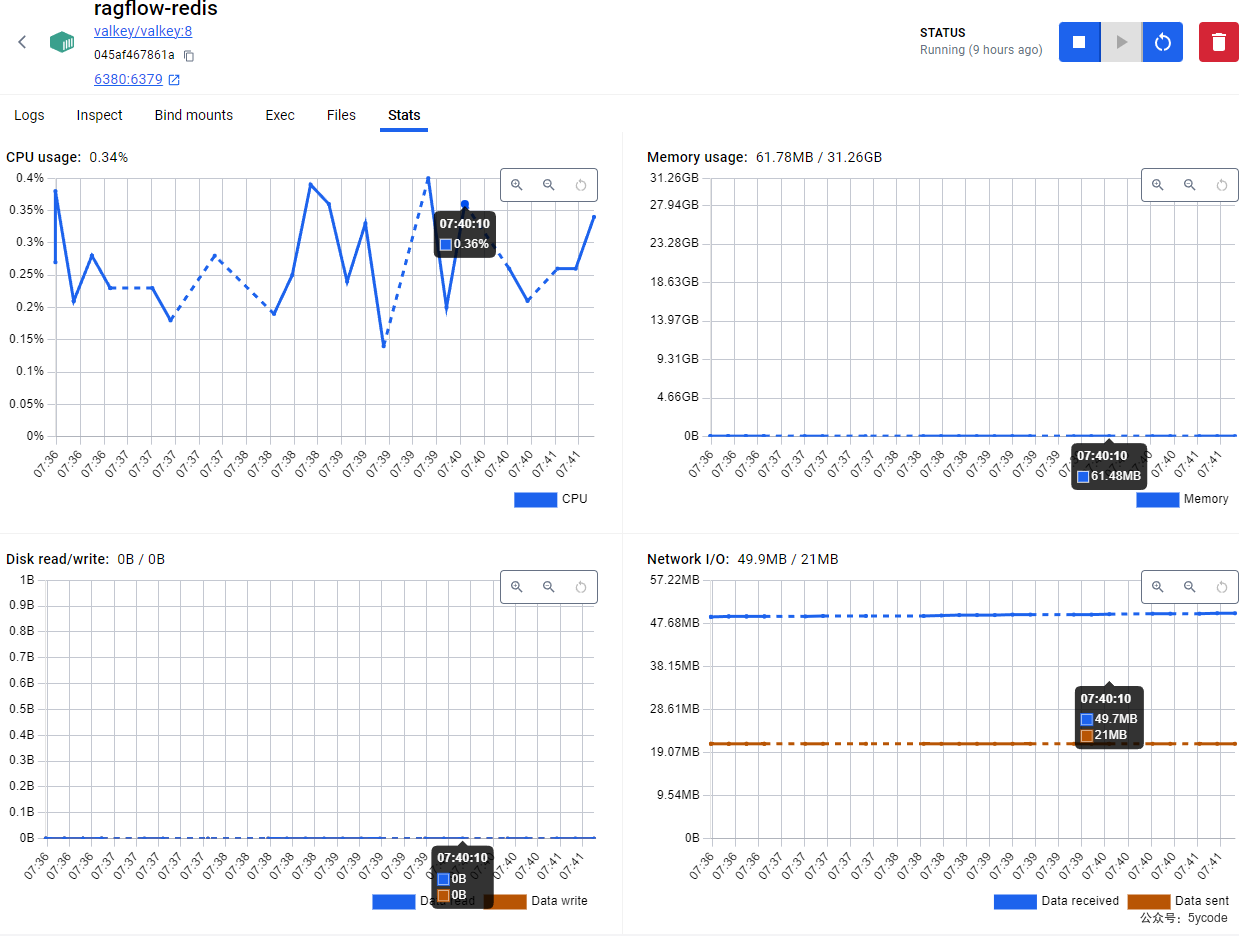
服务资源监控
最吃资源的是ragserver,其次就是es。
知识图谱
放一个知识库图谱的效果,
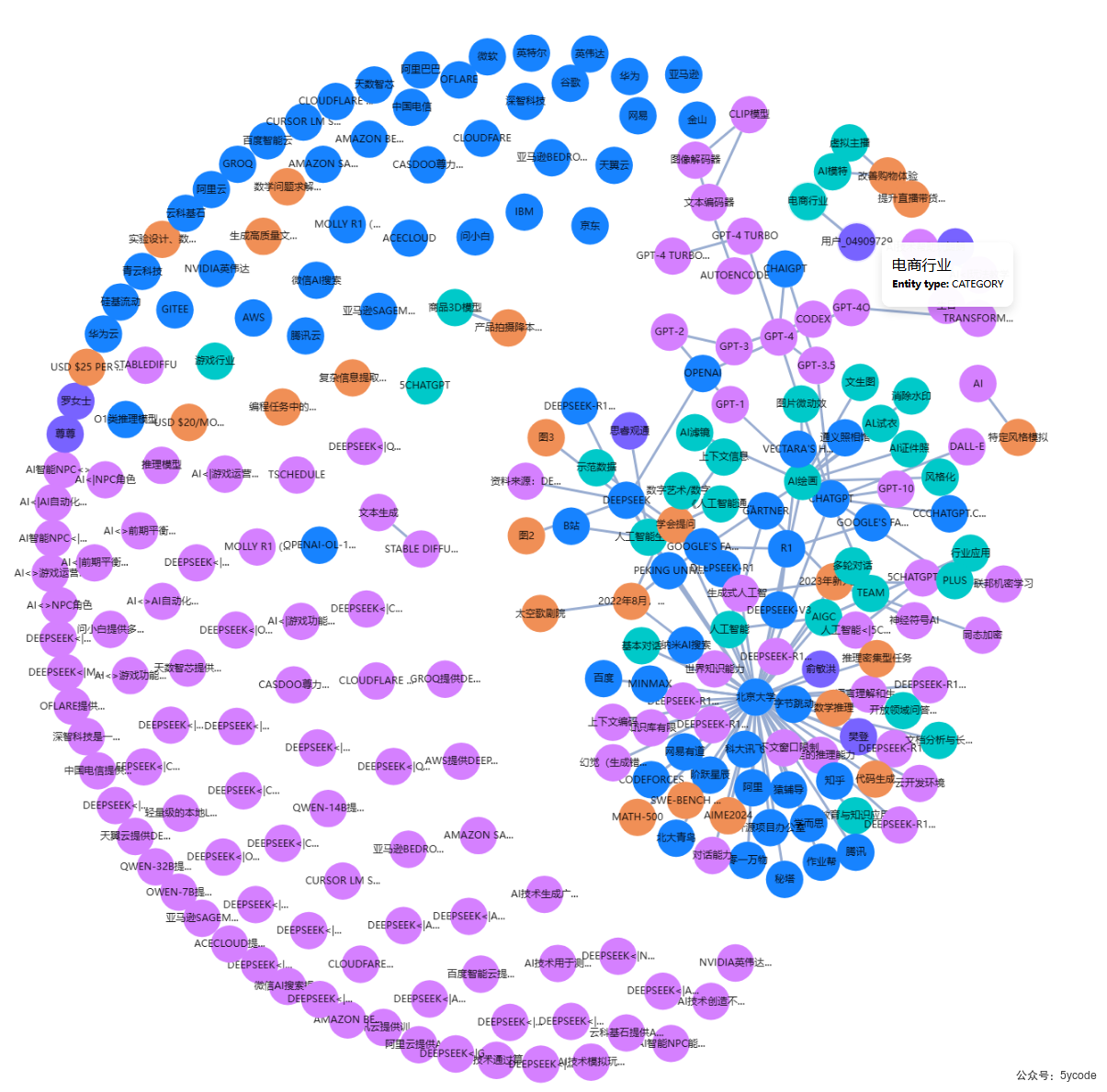
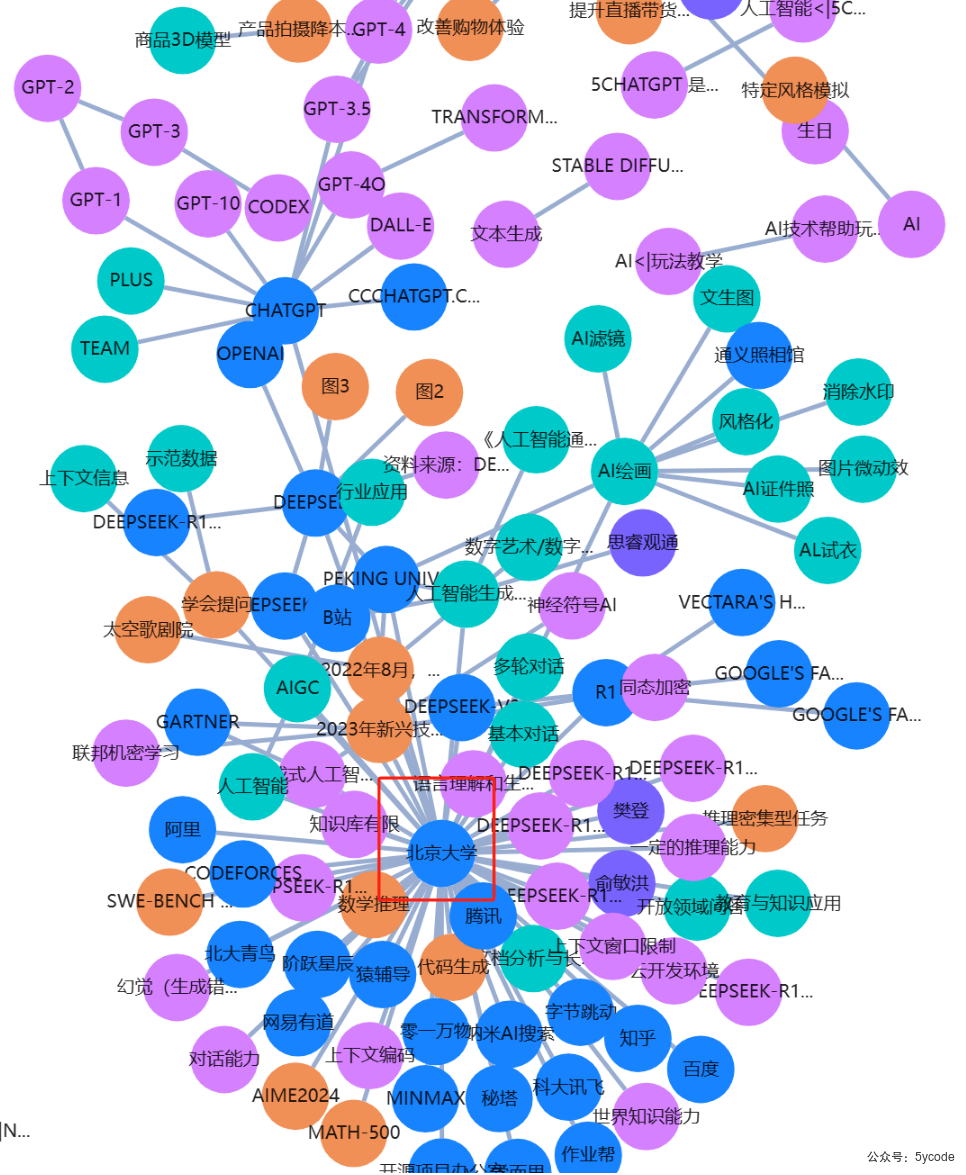
因为演示文稿的每页都有北京大学的原因,导致,整个知识图谱都围绕北京大学生成了。
相关资料
清华DeepSeek相关资料
https://pan.quark.cn/s/5c1e8f268e02
https://pan.baidu.com/s/13zOEcm1lRk-ZZXukrDgvDw?pwd=22ce
北京大学DeepSeek相关资料
https://pan.quark.cn/s/918266bd423a
https://pan.baidu.com/s/1IjddCW5gsKLAVRtcXEkVIQ?pwd=ech7
零基础使用DeepSeek
https://pan.quark.cn/s/17e07b1d7fd0
https://pan.baidu.com/s/1KitxQy9VdAGfwYI28TrX8A?pwd=vg6g
ollama的docker镜像
https://pan.quark.cn/s/6a72a906e37f 提取码:TRbV
https://pan.baidu.com/s/13JhJAwaZlvssCXgPaV_n_A?pwd=gpfq
deepseek的模型(ollama上pull下来的)
https://pan.quark.cn/s/dd3d2d5aefb2
https://pan.baidu.com/s/1FacMQSh9p1wIcKUDBEfjlw?pwd=ks7c
dify相关镜像
https://pan.quark.cn/s/e1e9c6ee7fd8 提取码:1rbC
https://pan.baidu.com/s/1oa27LL-1B9d1qMnBl8_edg?pwd=1ish
ragflow相关资料和模型
- https://pan.quark.cn/s/6da146679cd6?pwd=6dfY 提取码:6dfY
- https://pan.baidu.com/s/1bA9ZyQG75ZnBkCCenSEzcA?pwd=u5ei
公众号案例
- https://pan.quark.cn/s/18fdf0b1ef2e
- https://pan.baidu.com/s/1aCSwXYpUhVdV2mfgZfdOvA?pwd=6xc2
总入口(有时候会被屏蔽):
https://pan.quark.cn/s/d147f8e0ad30 提取码:jr33
https://pan.baidu.com/s/1GK0_euyn2LtGVmcGfwQuFg?pwd=nkq7
系列文档:
DeepSeek本地部署相关
ollama+deepseek本地部署
局域网或断网环境下安装DeepSeek
DeepSeek相关资料
清华出品!《DeepSeek从入门到精通》免费下载,AI时代进阶必看!
清华出品!《DeepSeek赋能职场应用》轻松搞定PPT、海报、文案
DeepSeek个人应用
不要浪费deepseek的算力了,DeepSeek提示词库指南
服务器繁忙,电脑配置太低,别急deepseek满血版来了’
DeepSeek+本地知识库:真的太香了(修订版)
DeepSeek+本地知识库:真是太香了(企业方案)
deepseek一键生成小红书爆款内容,排版下载全自动!睡后收入不是梦
最轻量级的deepseek应用,支持联网和知识库
dify相关
Deepseek+Dify本地知识库相关问题汇总
dify的sandbox机制,安全隔离限制
DeepSeek+dify 本地知识库:高级应用Agent+工作流
DeepSeek+dify知识库,查询数据库的两种方式(api+直连)
DeepSeek+dify 工作流应用,自然语言查询数据库信息并展示
聊聊dify权限验证的三种方案及实现
dify1.0.0版本升级及新功能预览
ragflow相关
DeepSeek+ragflow构建企业知识库:突然觉的dify不香了(1)
# DeepSeek+ragflow构建企业知识库之工作流,突然觉的dify又香了
关于我
资深全栈技术专家 | 互联网领域十年架构沉淀
技术纵深:高并发架构 | 应用调优 | 分布式系统
技术版图:Java/Vue/Go/Python
管理沉淀:8年技术团队管理 | 百万级DAU经验
专注输出:
✓ 架构思维 × 技术管理 × 全栈实战
✓ 新技术应用 × 行业趋势前瞻
📢【三连好运 福利拉满】📢
🌟 若本日推送有收获:
👍 点赞 → 小手一抖,bug没有
📌 在看 → 一点扩散,知识璀璨
📥 收藏 → 代码永驻,防止迷路
📤 分享 → 传递战友,功德+999
🔔 关注 → 关注5ycode,追更不迷路,干货永同步
💬 若有槽点想输出:
👉 评论区已铺好红毯,等你来战!


















 1279
1279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









