







 本文介绍了如何构建一个Mask R-CNN模型,专门用于检测汽车损伤。从数据收集、注释、训练到模型预测,详细阐述了每个步骤,包括使用VIA工具进行图像注释,通过Matterport Github存储库进行模型训练,并展示了模型在实际图像上的应用。
本文介绍了如何构建一个Mask R-CNN模型,专门用于检测汽车损伤。从数据收集、注释、训练到模型预测,详细阐述了每个步骤,包括使用VIA工具进行图像注释,通过Matterport Github存储库进行模型训练,并展示了模型在实际图像上的应用。
介绍
计算机视觉领域的应用继续令人惊叹着。从检测视频中的目标到计算人群中的人数,计算机视觉似乎没有无法克服的挑战。

这篇文章的目的是建立一个自定义Mask R-CNN模型,可以检测汽车上的损坏区域(参见上面的图像示例)。这种模型的基本应用场景为,如果用户可以上传照片并且可以评估来自他们的损害,保险公司可以使用它来更快地处理索赔。如果贷方承销汽车贷款,特别是二手车,也可以使用这种模式。
目录
-
什么是Mask R-CNN?
-
Mask R-CNN的工作原理
-
如何构建用于汽车损坏检测的Mask R-CNN
-
收集数据
-
注释数据
-
训练模型
-
验证模型
-
运行图像模型并进行预测
-
什么是MaskR-CNN?
Mask R-CNN是一个实例分割模型,它允许我们识别目标类别的像素位置。“实例分割”意味着对场景内的各个目标进行分段,无论它们是否属于同一类型- 即识别单个车辆,人员等。查看以下在COCO 数据集上训练的Mask-RCNN模型的GIF 。如你所见,它可以识别汽车,人员,水果等的像素位置。
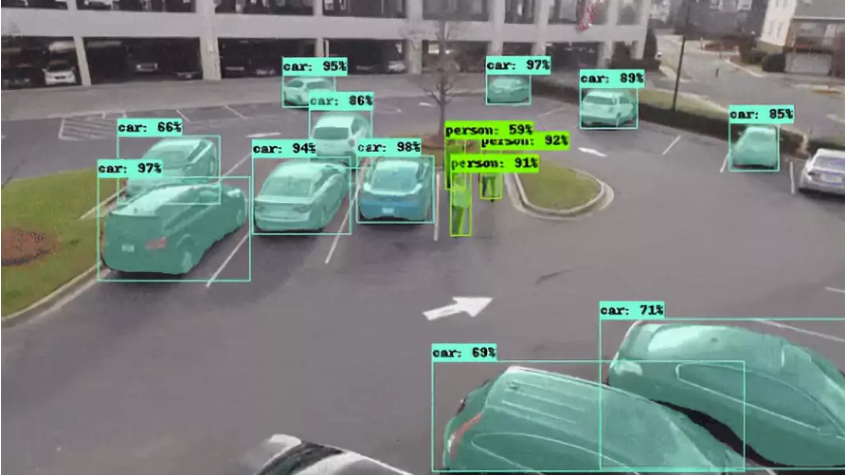
Mask R-CNN不同于经典目标检测模型–Faster R-CNN等,除了识别类别及其边界框位置之外,还可以对边界框中与该类别对应的像素区域进行着色。那么哪些任务需要这些额外的细节呢?我能想到的一些例子是:
- 自动驾驶汽车需要知道道路的确切像素位置; 其他汽车也可以据此避免碰撞
- 机器人可能需要他们想要拾取的物体的像素位置(这里可以联想到亚马逊的无人机)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6431
6431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









