






使用大型语言模型改进文本嵌入,第二部分
Improving Text Embeddings with Large Language Models
3方法
3.1 合成数据生成
利用 GPT-4 等高级 LLM 生成的合成数据提供了一个令人信服的机会,尤其是在增强多种任务和语言的多样性方面。这种多样性对于开发强大的文本嵌入至关重要,这些嵌入可以在不同的任务中表现出色,无论是语义检索、文本相似性还是聚类。
为了生成多样化的合成数据,我们提出了一种简单的分类法,将嵌入任务分类为几组,然后对每个组应用不同的提示模板。
非对称任务 此类别包括查询和文档在语义上相关但不是彼此释义的任务。根据查询和文档的长度,我们进一步将非对称任务分为四个子组:短-长匹配、长-短匹配、短-短匹配和长-长匹配。例如,短长匹配任务涉及一个短查询和一个长文档,这是商业搜索引擎中的典型场景。对于每个子组,我们设计了一个两步提示模板,首先提示 LLM 集思广益,列出任务列表,然后生成一个以任务定义为条件的具体示例。在图 1 中,我们显示了短-长匹配子组的示例提示。GPT-4 的输出大多是连贯且高质量的。在我们的初步实验中,我们还尝试使用单个提示生成任务定义和查询文档对,但数据多样性不如所提出的两步法令人满意。
对称任务 对称任务涉及具有相似语义但表面形式不同的查询和文档。我们研究了两种应用场景:单语语义文本相似性(STS)和双文本检索。我们为每个场景设计了两个不同的提示模板,根据其特定目标量身定制。由于任务定义简单明了,因此我们省略了对称任务的头脑风暴步骤。
为了进一步提高提示的多样性,从而提高合成数据的多样性,我们在每个提示模板中合并了几个占位符,其值在运行时随机采样。例如,在图 1 中,“{query_length}”的值是从集合“{少于 5 个单词,5-10 个单词,至少 10 个单词}”中采样的。
为了生成多语言数据,我们从 XLM-R 的语言列表中抽取了“{language}”的值(Conneau et al., 2020),赋予高资源语言更多的权重。在解析过程中,任何不符合预定义 JSON 格式的生成数据都将被丢弃。我们还会根据精确的字符串匹配来删除重复项。
3.2 训练
给定一个相关的查询文档对(q+,d+),我们首先将以下指令模板应用于原始查询q+,生成一个新的qinst+
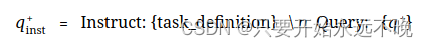
其中“{task_definition}”是嵌入任务的一句话描述的占位符。对于生成的合成数据,我们使用头脑风暴步骤的输出。对于其他数据集,例如 MS-MARCO,我们手动创建任务定义并将其应用于数据集中的所有查询。我们不会使用任何指令前缀修改文档端。这样,文档索引就可以预构建了,我们可以通过只改变查询端来自定义要执行的任务。
给定一个预训练的 LLM,我们在查询和文档的末尾附加一个 [EOS] 令牌,然后将它们输入到 LLM 中,通过获取最后一层 [EOS] 向量来获得查询和文档嵌入(hqinst+,hd+)。为了训练嵌入模型,我们在批次内负例和硬负例上采用标准的 InfoNCE 损失 L:
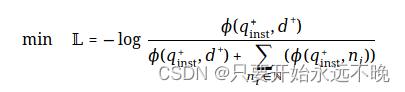
其中 N表示所有负例的集合,φ(q,d) 是一个函数,用于计算查询 q 和文档 d 之间的匹配分数。本文采用温度尺度余弦相似度函数如下:
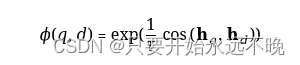
τ 是一个温度超参数,在我们的实验中固定为 0.02。
4 实验
4.1 合成数据统计
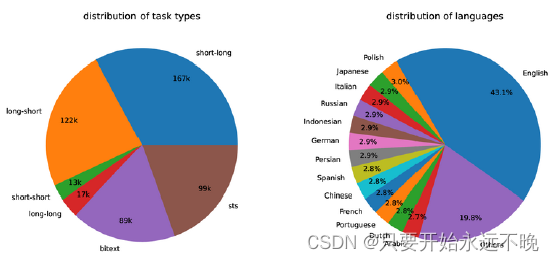
图 2:生成的合成数据的任务类型和语言统计信息(有关任务类型定义,请参见第 3.1 节)。“其他”类别包含 XLM-R 语言列表中的其余语言。
图 2 显示了我们生成的合成数据的统计数据。我们设法使用 Azure OpenAI 服务生成 500k 个示例和 150k 个唯一指令,其中 25% 由 GPT-35-Turbo 生成,其他由 GPT-4 生成。代币总消耗量约为 180M。主要语言是英语,覆盖范围扩大到总共 93 种语言。对于最底层的 75 种低资源语言,每种语言平均大约有 1k 个示例。
在数据质量方面,我们发现部分 GPT-35-Turbo 输出没有严格遵循提示模板中指定的准则。尽管如此,整体质量仍然可以接受,初步实验已经证明了合并该数据子集的好处。
4.2 模型微调和评估
使用公式 2 中的损失对预训练的 Mistral-7b(江 等人,2023 年)检查点进行了 1 个时期的微调。我们遵循 RankLLaMA 的训练配方(马 等人,2023 年)并利用排名 16 的 LoRA(胡 等人,2022 年)。为了进一步降低 GPU 内存需求,应用了梯度检查点、混合精度训练和 DeepSpeed ZeRO-3 等技术。
对于训练数据,我们利用生成的合成数据和 13 个公共数据集的集合,采样后产生大约 1.8M 个示例。更多细节可在附录 A 中找到。为了与以前的一些工作进行公平的比较,我们还报告了唯一标记的监督是MS-MARCO通道排名(Campos等人,2016)数据集的结果。
我们在 MTEB 基准上评估训练过的模型(Muennighoff 等人,2023 年)。请注意,MTEB 中的检索类别对应于 BEIR 基准测试中的 15 个公开可用的数据集(Thakur 等人,2021 年)。由于需要对大量文档进行编码,因此在 8 个 V100 GPU 上评估一个模型大约需要 3 天。虽然我们的模型可以容纳超过 512 的序列长度,但我们只评估前 512 个令牌的效率。每个类别都会报告官方指标。有关评估方案的更多详细信息,请参阅原始论文(Muennighoff 等人,2023 年;Thakur 等人,2021 年)。
4.3 主要结果
表 1:MTEB 基准测试的结果(Muennighoff 等人,2023 年)(英语子集中的 56 个数据集)。这些数字是每个类别的平均值。有关每个数据集的分数,请参阅表 15。
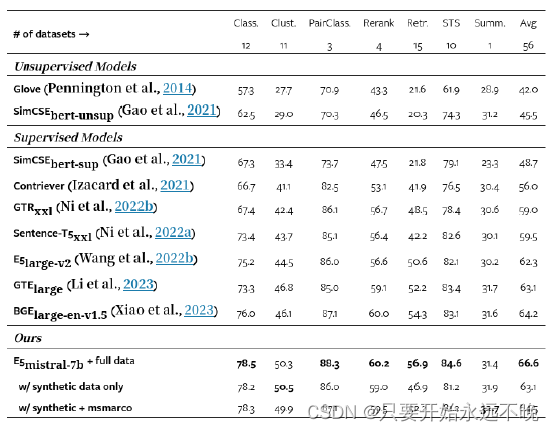
在表 1 中,我们的模型“E5mistral-7bmistral-7b + full data”在 MTEB 基准测试中获得了最高的平均分数,比之前最先进的模型高出 2.4 分。在“仅使用合成数据”设置中,没有标记数据用于训练,但性能仍然相当有竞争力。我们认为生成语言建模和文本嵌入是同一枚硬币的两面,这两项任务都需要模型对自然语言有深刻的理解。给定嵌入任务定义,一个真正健壮的 LLM 应该能够自行生成训练数据,然后通过轻量级微调转换为嵌入模型。我们的实验揭示了这个方向的潜力,需要更多的研究来充分探索它。
表2:与商用车型和MTEB排行榜榜首车型的比较(截至2023-12-22)。对于此处列出的商业模型,有关其模型架构和训练数据的详细信息很少。
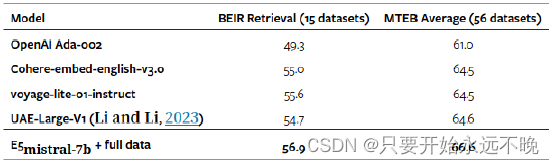
在表 2 中,我们还与几种商业文本嵌入模型进行了比较。然而,由于缺乏关于这些模型的透明度和文档,进行公平的比较是不可行的。我们特别关注BEIR基准测试的检索性能,因为RAG是一种新兴技术,可以利用外部知识和专有数据来增强LLM。如表 2 所示,我们的模型明显优于当前的商业模型。
4.4 多语言检索
表 3:高资源和低资源语言的 MIRACL 数据集开发集nDCG@10。我们根据候选文件的数量选择4种高资源语言和4种低资源语言。BM25 和 mDPR 的数据来自 Zhang et al. (2023b)。有关所有 18 种语言的完整结果,请参见表 5。
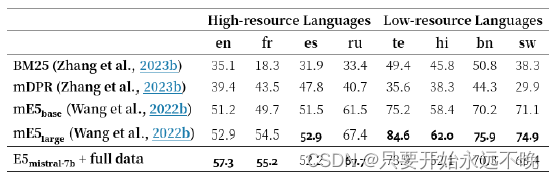
为了评估我们模型的多语言能力,我们对 MIRACL 数据集(Zhang et al., 2023b)进行了评估,该数据集包括 18 种语言的人工注释查询和相关性判断。如表 3 所示,我们的模型在高资源语言上超过了 mE5largel,尤其是在英语上。然而,对于资源匮乏的语言,与mE5base相比,我们的模型仍然不理想。我们将其归因于Mistral-7B主要是在英语数据上进行预训练,我们预计未来的多语言LLM将利用我们的方法来弥合这一差距。
5 分析
5.1 对比预训练是否必要?
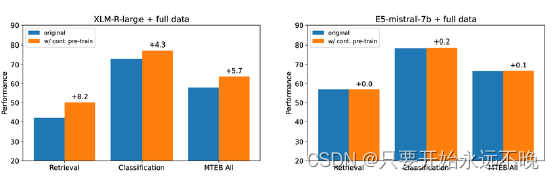
图 3:对比预训练的效果。详细数字见附录表6。
弱监督对比预训练是现有文本嵌入模型成功的关键因素之一。例如,Contriever (Izacard et al., 2021) 将随机裁剪的跨度视为预训练的正对,而 E5 (Wang et al., 2022b) 和 BGE (Xiao et al., 2023) 收集和过滤来自各种来源的文本对。
本节重新评估了对 LLM 进行对比预训练的必要性,尤其是那些已经在数万亿 Token 上进行了预训练的 LLM。图 3 显示,对比预训练对 XLM-Rlarge 有益,在对相同数据进行微调时,其检索性能提高了 8.2 个百分点,这与之前的研究结果一致。然而,对于基于Mistral-7B的模型,对比预训练对模型质量的影响可以忽略不计。这意味着广泛的自回归预训练使 LLM 能够获得良好的文本表示,并且只需要最少的微调即可将它们转换为有效的嵌入模型。
5.2 扩展到长文本嵌入

请参阅标题
图 4:改编自 Mohtashami 和 Jaggi (2023) 的个性化密钥检索任务图示。“<前缀填充物>”和“<后缀填充物>”是“草是绿色的。天空是蓝色的。太阳是黄色的。来吧。那里,又回来了。此外,每个文档都有一个唯一的人名和一个随机插入的随机密钥。任务是从 100 名候选人中检索包含给定人员密钥的文档。
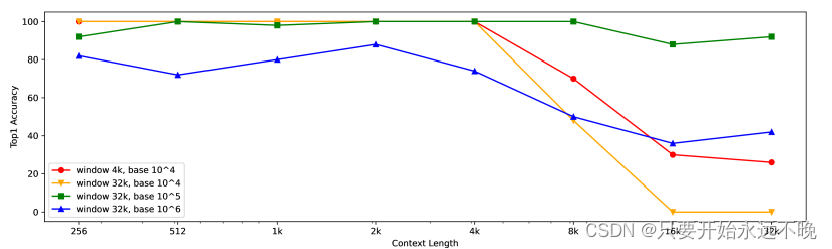
图 5:个性化密钥检索的准确性与输入上下文长度的函数关系。对于每个上下文长度,我们随机生成 50 个查询并计算前 1 个准确率。
文本嵌入模型的现有评估数据集通常很短,为了评估模型的长上下文能力,我们引入了一种称为个性化密钥检索的新型合成任务,如图 4 所示。此任务需要将长上下文中的密钥信息编码到嵌入中。我们通过改变滑动窗口尺寸和RoPE旋转底座来比较不同变体的性能(Su等人,2024)在图5中。结果表明,4k滑动窗口的默认配置在4k令牌内达到100%的准确率,但随着上下文长度的增加,精度会迅速下降。天真地将滑动窗口大小扩展到 32k 会导致性能更差。通过将 RoPE 轮换基数更改为 10^{5},该模型可以在 32k 代币内实现超过 90% 的准确率。但是,对于较短的上下文,这需要在性能上进行较小的权衡。未来研究的一个潜在途径是通过轻量级后期训练有效地使模型适应更长的上下文(Zhu 等人,2023 年)。
5.3 训练超参数分析
表 4:具有各种超参数的 MTEB 基准测试结果。第一行对应于默认设置,该设置采用最后令牌池、LoRA 等级 16 和自然语言指令。除非另有说明,否则所有模型均在合成和 MS-MARCO 通道排名数据上进行训练。
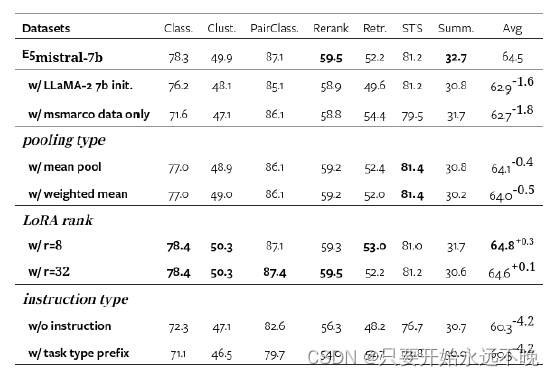
表4给出了不同配置下的结果。我们注意到Mistral-7B初始化比LLaMA-2 7B具有优势,这与Mistral-7B技术报告(江等人,2023)的发现一致。池化类型和 LoRA 等级的选择不会对整体性能产生实质性影响,因此尽管 LoRA 等级 8 略有优势,但我们坚持默认设置。另一方面,添加指令的方式对性能有相当大的影响。我们推测,自然语言指令可以更好地告知模型手头的嵌入任务,从而使模型能够生成更具判别性的嵌入。我们的框架还提供了一种通过指令自定义文本嵌入行为的方法,而无需微调模型或重新构建文档索引。
6 结论
本文表明,通过利用 LLM 可以大大提高文本嵌入的质量。我们提示专有的 LLM(例如 GPT-4)使用多种语言的指令生成各种合成数据。结合Mistral模型强大的语言理解能力,我们在竞争激烈的MTEB基准测试中为几乎所有任务类别建立了新的最先进的结果。与现有的多阶段方法相比,培训过程更加精简和高效,从而避免了对中间预培训的需要。
对于未来的工作,我们的目标是进一步提高我们模型的多语言性能,并探索使用开源LLMs生成合成数据的可能性。我们还打算研究如何提高基于 LLM 的文本嵌入的推理效率并降低存储成本。















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









