







论文阅读:Enhanced 3D Urban Scene Reconstruction and Point Cloud Densification using Gaussian Splatting and Google Earth Imagery
Abstract
尽管基于大规模遥感图像的3D城市场景重建和建模对于数字孪生和智能城市等许多关键应用至关重要,但由于异构数据集和几何模型的不确定性,这是一个困难的任务。本文提出了一种基于高斯溅射的方法,用于3D城市场景建模和几何检索,贡献如下。首先,我们开发并实现了一种大规模3D城市场景建模的3D高斯溅射(3DGS)方法。其次,我们在提出的3DGS模型中设计了点云密集化方法,以提高城市场景3D几何提取的质量。利用不同传感器的Google Earth图像,我们在加拿大滑铁卢大学地区对该方法进行了测试,证明了与其它多视图立体(MVS)方法相比,所提出方法在重建点云质量上的显著提高。第三,我们设计并进行了广泛的实验,使用跨越十个城市的多源大规模Google Earth遥感图像,比较了3DGS方法与神经辐射场(NeRF)方法,证明了在新视图合成结果上的巨大改进,大大超过了以前的最先进3D视图合成方法。
1. Introduction
3D重建和建模从2D图像中获取最近由于在逼真视图合成方法方面取得的进展而受到了极大的关注。这是一个跨学科的研究领域,涵盖了计算机视觉、计算机图形学和摄影测量学。它在多个领域都有应用,包括辅助3D场景理解的自主导航、遥感和摄影测量用于制作3D地图,这些地图对于导航、城市规划和行政至关重要。此外,它还扩展到地理信息系统,整合了城市数字孪生,以及增强现实和虚拟现实平台,这些平台整合了逼真的场景重建。本文专注于基于3D高斯溅射的遥感大规模视图合成,以及从高斯溅射中提取3D几何。我们仅使用Google Earth Studio的图像,训练了一个3D高斯溅射模型,该模型在性能上超越了以往的NeRF模型。我们在由Google Earth捕获的10个城市的大规模城市数据集上量化和基准测试了视图合成性能,并提取并密集化了我们研究区域的3D几何,与多视图立体密集重建进行了比较。据我们所知,这是首次使用3D高斯溅射进行大规模遥感基础的3D重建和视图合成。
2. Back Ground and Related Work
2.1. Urban 3D Photogrammetry
摄影测量(Photogrammetry)从2D图像中提取3D几何形状和潜在的其他物理信息。基于遥感的城市摄影测量用于3D城市建模,依赖于无人机/航空平台/卫星,这些平台以斜视/非垂直角度捕获感兴趣的建筑物。这通常被称为斜视摄影测量。在大规模场景中,可能还会存在其他土地利用和土地覆盖,这会带来额外的挑战。地面和航空激光雷达扫描仪(LiDAR)也可以用来生成非常精确的3D模型,有时与基于图像的方法结合使用。然而,总体而言,图像在传感器和数据可用性方面更易于获取。
传统的(非基于深度学习的方法)从图像生成3D点云/几何形状被分为两种类型:从运动结构(SfM)生成稀疏点云,和多视图立体(MVS)生成密集点云(Musialski等人,2013)。最基本的方法可能是从运动结构,它依赖于多视图几何和投影几何来建立3D点与它们在成像平面上的2D投影之间的关系。在每个2D图像中提取关键点,并在具有场景重叠的图像中匹配,然后三角化到三维空间,并且通常使用捆绑平差或其他方法进一步校准/误差校正,从而产生稀疏点云3D重建。然后,可以将稀疏点云网格化和/或转换为数字曲面模型。稀疏SfM摄影测量通常被用作预处理步骤,如各种工作(Yalcin和Selcuk,2015;Langua等人,2017)所示,以帮助利用3D扫描的点云进行进一步的密集重建或数据融合。稀疏SfM点云只能检索场景几何图形,不能再现场景的真实感三维光照,这对于基于AR/VR的应用以及其他严重依赖可视化的应用来说是至关重要的。
在城市环境中,多视图立体(MVS)也需要斜视图像来捕获建筑物及其外立面的几何形状。从根本上说,多视图立体与稀疏SfM摄影测量不同,因为MVS旨在通过利用2D图像中每个像素的3D信息来实现密集重建,与2D图像中特定关键点不同。这可以通过使用各种方法来完成,例如平面扫描或立体视觉和深度图融合,甚至深度学习方法。MVS方法通常分为两类:基于体积的和基于点云的(Musialski等人,2013;Jensen等人,2014)。各种作者(Yalcin和Selcuk,2015;Toschi等人,2017;Lingua等人,2017;Rong等人,2020;Pepe等人,2022;Liao等人,2024)已经使用MVS进行了密集的城市3D重建,这也可以被网格化用于数字表面建模和地球物理模拟等不同目的。然而,与稀疏SfM摄影测量相比,密集MVS摄影测量在计算上更为密集,尤其是在内存方面。此外,密集MVS摄影测量通常需要稀疏SfM摄影测量,或者至少需要从稀疏SfM摄影测量中获得的相机姿态作为预处理步骤。尽管密集重建在视觉上比稀疏重建更具吸引力,但它们仍然不是照片级的,因为它们不能模拟场景中光线的方向依赖性。
2.2. Neural Radiance Fields and Urban 3D Reconstruction/View synthesis
近年来,基于神经辐射场的方法(NERF)(Mildenhall等人,2021)主导了新的视点合成领域。在场景的姿态图像上进行训练,NERF方法使用可区分的渲染过程来学习隐式(Barron等人,2021,2022)或混合场景表示(Müller等人,2022),通常作为密度和方向颜色场,并且通常使用一些多层感知器(MLP)。然后,使用可微分体绘制过程将场景表示绘制成2D图像,从而允许通过使用光度损失的反向传播的逐个像素的监督学习来学习场景表示。某些显式场景表示模型(Yu等人,2021年;Fridovich-Keil等人,2022年;Chen等人,2022年)使用几乎相同的可区分渲染流水线,但显式地存储它们的场景表示,放弃使用解码MLP(尽管这些方法中的一些允许使用浅解码MLP,模糊了显式和混合场景表示之间的界限)。
为了合成图像,NeRF方法采用可微体渲染,使用沿着采样间隔 δ i \delta _i δi的射线的局部密度 σ i \sigma_i σi,通过局部颜色 c i c_i ci的阿尔法混合来生成像素颜色 C C C 。这是由
C = ∑ i c i α i T i C=\sum_ic_i\alpha_iT_i C=i∑ciαiTi
其中 c i c_i ci和 σ i \sigma_i σi是从学习到的辐射场(例如NeRF MLP)中采样的,并且
α i = 1 − exp ( − σ i δ i ) a n d T i = ∏ j = 1 i − 1 ( 1 − α j ) \alpha_i=1-\exp(-\sigma_i\delta_i)\mathrm{~and~}T_i=\prod_{j=1}^{i-1}(1-\alpha_j) αi=1−exp(−σiδi) and Ti=j=1∏i−1(1−αj)
城市场景、不受约束、充满短暂对象(例如行人、汽车)以及不断变化的照明条件对3D场景表示的学习构成了挑战。方法,例如NeRF-W(Martin-Brualla等人,2021年)、Mip-NeRF 360(Barron等人,2022年)、Block-NeRF(Tancik等人,2022年)、Urban Radiance Fields(Rematas等人,2022年)提出了其中一些问题的解决方案,适合地面视图合成和3D城市重建。
还尝试使用Bungee/City-NeRF等方法从遥感图像中进行鸟瞰图3D重建和视图合成(Xiangli等人,2022年)、MegaNeRF(Turki等人,2022年)、Shadow NeRF(Derksen和Izzo,2021年)、Sat-NeRF(Marí等人,2022年)。这些方法试图解决诸如将局部NeRF拼凑成大规模城市场景、多规模城市景观合成以及高层建筑的阴影感知场景重建等问题。BungeeNeRF(Xiangli等人,2022年)很有趣,因为我们使用类似的方法从我们的研究区域提取Google Earth数据集。
2.3. 3D Gaussian Splatting
3D高斯溅射(3DGS)最初是在2023年作为与现有NeRF视图合成方法相竞争的视图合成方法开发的。与标准的NeRF方法相比,标准的高斯溅射方法学习3D场景并合成新视图的速度要快几个数量级,并且在视图合成的视觉质量方面与最佳NeRF模型相当,常常还能超越,这是以更大的内存占用和需要从运动结构(Structure-from-Motion, SfM)初始化/预处理为代价的。工作流程在图1中可视化展示。
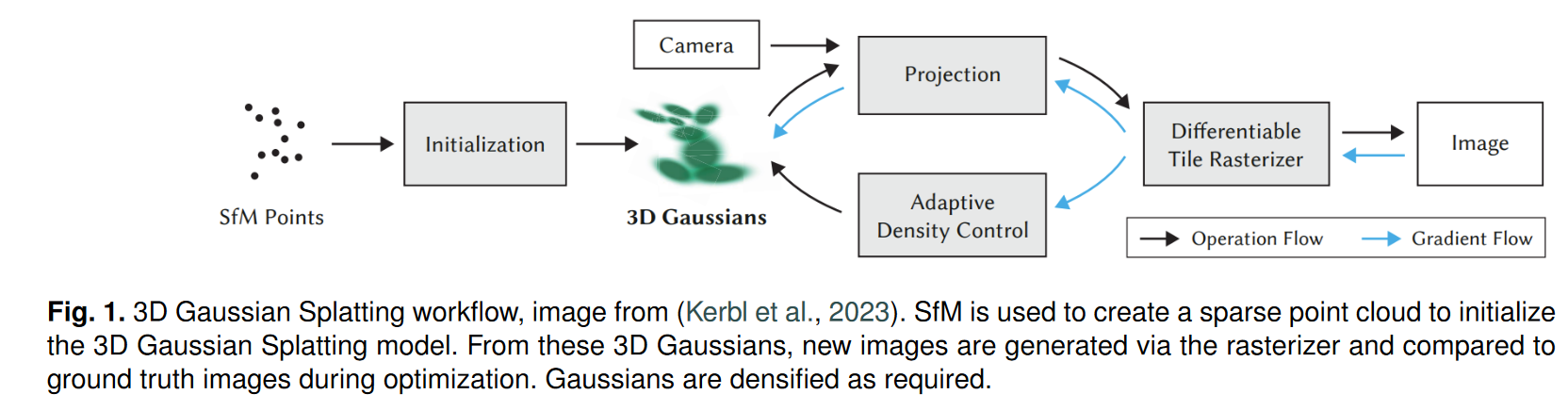
SfM预处理正是标准的稀疏摄影测量过程,它识别2D关键点、匹配重叠图像、将关键点三角测量为3D,并通过束平差或其他方法进行误差纠正。与标准摄影测量有时可以将图像颜色投影为平坦(无光照)的3D点云颜色相比,3DGS能够逼真地再现场景的方向相关照明,这对于许多应用来说至关重要。它还能够使用光测(基于颜色的)目标针对地面真实图像微调场景的几何形状,而不是仅最大限度地减少摄影测量中的重投影误差。与NeRF模型相比,3DGS生成更自然的3D几何形状,所学习的3D高斯函数的3D位置平均值与场景几何形状的3D点云表示之间具有自然的对应关系。
3D高斯飞溅方法将场景表示为3D高斯函数,并将照明表示为附加到这些高斯的球调和(SH)系数,通过基于可微瓦片的高斯网格化器生成2D图像;基于新视图姿势的视锥将高斯投影到二维中,将投影高斯投影到二维中,按字母顺序排列投影高斯以在新视图中产生每像素的颜色。根据地面真值图像来监督新颖的视图,以训练高斯飞溅参数。据我们所知,这是第一个尝试使用3D高斯飞溅的大规模基于遥感的3D重建和视图合成的工作,然而最近的工作(Kerbel等人,2024年;周等人,2024)已将高斯飞溅应用于大规模城市街道级数据集。
3. Method
3.1. Region of Study
研究的地区是加拿大安大略省的基奇纳-滑铁卢(Kitchener-Waterloo)地区,以滑铁卢大学为中心。根据2021年的人口普查,滑铁卢大约有121000人口,占地64.06平方公里(加拿大统计局,2023年)。滑铁卢大学位于北纬43.472°,西经80.550°,主校区占地4.5平方公里。在城市尺度上,研究区由各种土地利用和土地覆盖特征组成,如城市道路、建筑、农业和其他土地利用、低植被、水域、温带混交林和其他土地覆盖。研究区域以环境一号(EV-1)大楼为中心(位于北纬43.468°,西经80.542°),面积约165km2。我们在城市尺度上进行大尺度的视点合成,在邻域尺度上进行三维点云比较。为该场景检索的谷歌地球图像主要来自陆地卫星/哥白尼号、空中客车公司、Data Scripps海洋学研究所(SIO)和美国国家海洋和大气管理局(NOAA)。
3.2. Google Earth Studio Datasets
对于研究区域,我们使用了七个不同高度、半径和倾角的同心圆作为相机路径,以加拿大安大略省滑铁卢大学的EV-1大楼为中心。第一个圆圈半径为500米,海拔为475米。最后一个圆圈半径为7,250米,海拔为3,690米。所有图像都指向位于北纬43.468°,西经80.542°的滑铁卢大学EV-1大楼上方(海拔390米)。最后一个圆圈的图像相对于水平线倾斜约65°,但有一些偏差(在∼0.3°范围内)。我们使用Google Earth Studio沿着使用这些圆圈定义的相机路径收集了401张图像。研究区域和摄像机姿势以及稀疏的SfM结果如图2所示。在预处理过程中,我们观察到距离场景中心6公里以上的SfM点云重建效果较差,6公里内的SfM重建合理,1公里内可以识别出单个建筑物的SfM重建结果良好。SfM前处理得到了包含337382个点的稀疏点云,用于初始化3DGS的三维高斯函数。这个多比例尺Google Earth Studio(Alphabet Inc.,2015-2024年)数据集的灵感来自BungeeNeRF数据集(向力等人,2022年),我们也将其用于多城市大规模视图合成基准。

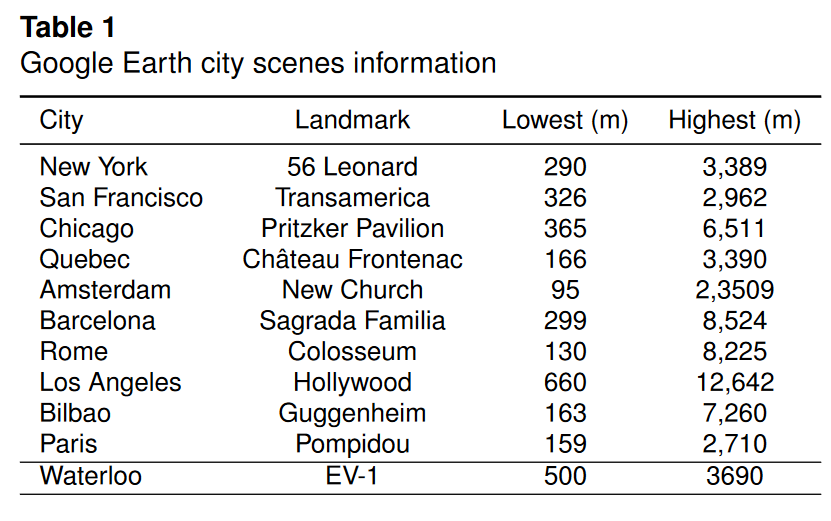
对于BungeeNeRF场景,我们使用BungeeNeRF(向力等人,2022)指定的Google Earth Studio相机路径。BungeeNeRF数据集包括10个城市的10个场景。每个场景都围绕着一个特定的地标,摄像机路径由不同轨道半径和高度的同心圆定义,场景覆盖范围在最高海拔处达到全市范围。关于10个BungeeNeRF场景和滑铁卢场景的详细信息可以在表1中找到。以伦纳德56号为中心的纽约场景和以泛美航空为中心的旧金山场景作为BungeeNeRF的视图重建基准的主要场景(向力等,2022),分别拥有459和455幅图像。这两个场景是在1:30分钟的视频中以每秒30帧的速度渲染的。所有其他场景包含221个图像,通过在给定固定相机路径的情况下将帧限制固定为220+1进行渲染,并用于其他可视化。我们注意到,最初的BungeeNeRF论文包含两个额外的场景(西德尼和西雅图),但没有为这两个场景提供Google Earth Studio的相机路径。
Google Earth Studio提供了一个平台,只需指定相机姿态和场景位置即可生成多视图航空/卫星图像。Google Earth Studio制作了来自各种政府和商业来源的合成图像,以及使用这些来源的遥感图像构建的3D模型的渲染图像。其中包括Landsat/Copernicus、空客、NOAA、美国海军、USGS、Maxar图像和不同时间拍摄的数据集。在图5右下角的两张图像中可以观察到合成图像的一个明显示例,不同的Water颜色指示不同的数据源和/或采集时间。
3.3. Structure from Motion Preprocessing and Sparse Point Cloud Extraction
3D高斯飞溅的标准实现依赖于COLMAP(Schonberger和Frahm,2016)进行预处理。该SfM预处理收集了一组相机姿态未知的无序图像,并输出每个图像的相机姿态以及稀疏点云。与所有SfM方法一样,COLMAP SfM由以下步骤组成。
特征提取(Feature Extraction):在这一步骤中,对于每个图像 I i I_i Ii,识别关键点 x j ∈ R 2 x_j\in R^2 xj∈R2,并分配稳健视图不变局部特征 f j ∈ R n f_j\in R^n fj∈Rn。缩放不变特征变换(SFT)特征(Lowe,1999)在COLMAP中用作默认设置,并提供稳健的特征,允许在多个图像中将相同的3D点识别为相应的投影2D关键点。匹配(Matching):通过搜索图像及其各自的特征,识别具有匹配关键点特征的潜在重叠图像对。
几何验证(Geometric Verification):通过验证潜在重叠图像对来构建具有连接重叠图像的节点和边缘图像的场景图。该验证是通过使用稳健的估计技术(例如Fischler和Bolles(1981)的随机样本共识(RASAC)的变体)来估计潜在连接的图像对中的有效单应性来完成的。
**图像配准(Image Registration):**从关键点被三角测量成3D的起始图像对,通过解决Pespective-n-Point问题(Fischler和Bolles,1981),将给定场景图具有重叠的新图像添加到场景中,该问题在给定多个3D点及其2D投影的情况下估计相机姿态。该步骤稳健地估计新注册图像的姿态。
三角测量(Triangulation):给定从两张已知姿势的图像中观察到的关键点,关键点被三角测量(Hartley和Zisserman,2003)为3D。新配准的图像通过允许将更多关键点三角测量到3D重建中来扩展场景。
误差纠正(Error-Correction):为了纠正配准和三角测量中的误差,束平差(Triggs等人,2000年)是通过在最小化由3D点在图像平面上的重新投影的平方误差给出的重新投影损失 E E E期间联合优化相机位姿 P c ∈ S E 3 P_c\in SE3 P
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









