






论文阅读:A Faster and More Effective Cross-View Matching Method of UAV and Satellite Images for UAV Geolocalization
1. Introduction
无人飞行器(UAV)近年来迅速发展,由于其操作便捷和强大的数据收集能力,逐渐成为遥感图像获取的主要平台。Alexander等人[1]使用无人机数据在热带雨林中定位树木。Amour等人[2]提出了一种基于深度学习的无人机图像中汽车检测方法。Deng等人[3]将基于无人机的多光谱遥感应用于精准农业。无人机应用涉及众多领域,如摄影测量、农业和地图制作[4-7]。然而,目前无人机的定位和导航主要依赖于GPS和GNSS等定位系统。如何在没有定位系统辅助的情况下实现无人机的自主定位和导航,是一个具有挑战性的任务。
**跨视角图像匹配技术将带有地理位置标签的卫星图像与没有地理位置标签的无人机图像进行匹配,以实现无人机图像的定位和导航。**由于地理定位的巨大应用价值,跨视角地理定位已成为近年来的研究焦点。许多先前的方法侧重于从图像中提取手工设计的特征[8-11]。随着卷积神经网络性能的快速发展,许多研究使用CNN在图像中自动提取鲁棒特征。为了弥合不同视图图像之间的差距,提出了连体网络[12],这对模型学习视点不变特征很有帮助。Liu等人[13]设计了一个网络,通过方向对图像中的像素进行编码。Hu等人[14]提出了一种类似连体的架构,通过使用NetVLAD[15]获得了更强大的特征描述。
遥感领域中的另一系列工作集中在度量学习上,研究了各种损失函数以学习具有区分性的特征。为了缩小学习到的分布和真实分布之间的差距,Liu等人[16]提出了一种随机吸引和排斥嵌入损失。Vo等人[17]展示了通过方向回归损失,显式的方向监督可以提高位置预测的准确性。其他一些工作集中在领域对齐上。Shi等人[18]应用极坐标变换来扭曲航空图像,并实现了航空视图和地面视图之间的对齐。进一步地,他们通过采用动态相似性匹配网络[19]设计了一种DSM方法,以估计在定位过程中的跨视角方向对齐。上述大部分工作是在两个数据集上进行的,CVUSA[20]和CVACT[13],它们用于匹配地面视图和卫星视图图像。Zheng等人提出了基于无人机的数据集University-1652[21],并从分类的角度检验了图像检索任务。通过实例损失[22,23]优化的模型可以学习到比排名损失更有区分性的嵌入。在最近的一项工作中,受到分区策略[24-27]的启发,Wang等人[28]提出了一个专注于基于University-1652的无人机和卫星视图图像匹配的局部模式网络(LPN)。LPN在跨视角地理定位中整合了上下文信息,并应用了旋转不变的方格环特征分区策略,使网络能够专注于地理目标周围的辅助信息,如房屋、道路和树木,这在跨视角地理定位领域是一次突破。
注意力的目标是专注于显著特征并抑制不相关特征[29]。在Re-id(行人重识别)领域有相当多的研究[30-34],但在跨视角地理定位中却很少见。一些工作在线性特征图上使用了具有小感受野的卷积操作。受到SE-Net[35]的启发,Wang等人[36]提出了一个全注意力块(FAB),以防止空间信息的丢失。为了最大化补充信息,Li等人[37]制定了HA-CNN,联合学习软像素注意力和硬区域注意力。Chen等人[38]考虑了以前的工作,专注于粗略注意力,并明确增强了注意力知识的辨别力和丰富性。另一些工作扩大了感受野以引入更多的上下文信息。Wang等人[39]堆叠了注意力模块以生成注意力感知特征,并应用注意力残差学习来训练深度网络。Yang等人[40]设计了一个内部注意力网络搜索图像中的信息丰富和区分性区域。Zhang等人[41]在编解码器风格的注意力模块之前插入了一个非局部块[42],以基于全局精炼特征启用注意力学习。在最近的一项工作中,Zhang等人[29]挖掘了特征节点之间的关系表示,以学习语义并推断注意力。
自从Hinton等人在2015年提出知识蒸馏以来,联合学习在深度学习领域迅速发展。借鉴这个想法,Romero等人[44]使用大型、强大且易于训练的网络指导小型但更难训练的网络。JIM等人[45]将层间通过特征图内积计算的流视为蒸馏知识。在最近的一项工作中,Wang等人[46]将特征编码为金字塔结构,并鼓励较短的代码通过自蒸馏模仿较长的代码。与上述基于蒸馏的方法不同,Zhang等人[47]提出了一种深度互学习(DML)策略,一群学生在整个训练过程中协作学习并相互教学。
然而,大多数上述跨视角方法侧重于全局信息,很少有关注上下文信息的。现有的硬部分表示学习策略忽略了位置的偏移和平移,很少有专门为跨视角地理定位设计的注意力机制。为了克服上述缺点,我们实现了以下改进:
- 改进了现有的分区策略,使所提出的模型对偏移和平移变化更加鲁棒。与现有工作不同,模型被分为全局和局部分支,它们一起训练以结合整体和部分(见第2.2-2.4节)。
- 提出了跨视角地理定位的注意机制和分区策略。具体来说,注意力模块查找区域之间的关系,让每个区域关注不同的特征(参见2.5节)。
- 我们最大限度地减少KL分歧损失,以缩小域之间的差异(参见第2.6节)。
- 结果,该模型取得了出色的表现。对基准数据集的测试结果表明,该模型在无人机和卫星图像匹配任务中的准确性大大超过了现有最佳模型。此外,与SOTA方法相比,该模型的推理时间减少了30%,并达到了同等水平的准确性。当推理时间几乎相同时,模型的准确性远远领先于SOTA方法(参见第3节)。
2. Materials and Methods
2.1. Datasets and Evaluation Indicators
研究是在Zheng[21]发布的University-1652上进行的。University1652包含来自世界各地72所大学的大约1652个地点或所谓的地理目标。每个地理目标包含三个视图:卫星视图、无人机视图和街景视图。每个目标有1张卫星视图图像,50多张不同拍摄角度和高度的无人机视图图像,以及一些街景视图图像。本研究选择了卫星视图和无人机视图,并在匹配这两种视图时测试了方法的性能。方法的性能主要反映在两个任务上,即无人机到卫星和卫星到无人机。前者的目的给出一张无人机图像并找到同一地点的无人机图像;后者的目的是给出一张卫星图像并找到相应地点的K张卫星图像。数据集中查询集和图库集的图像数量详情见表1。在无人机到卫星任务的测试数据集中,每个无人机视图图像只有一个真正匹配的卫星视图图像。
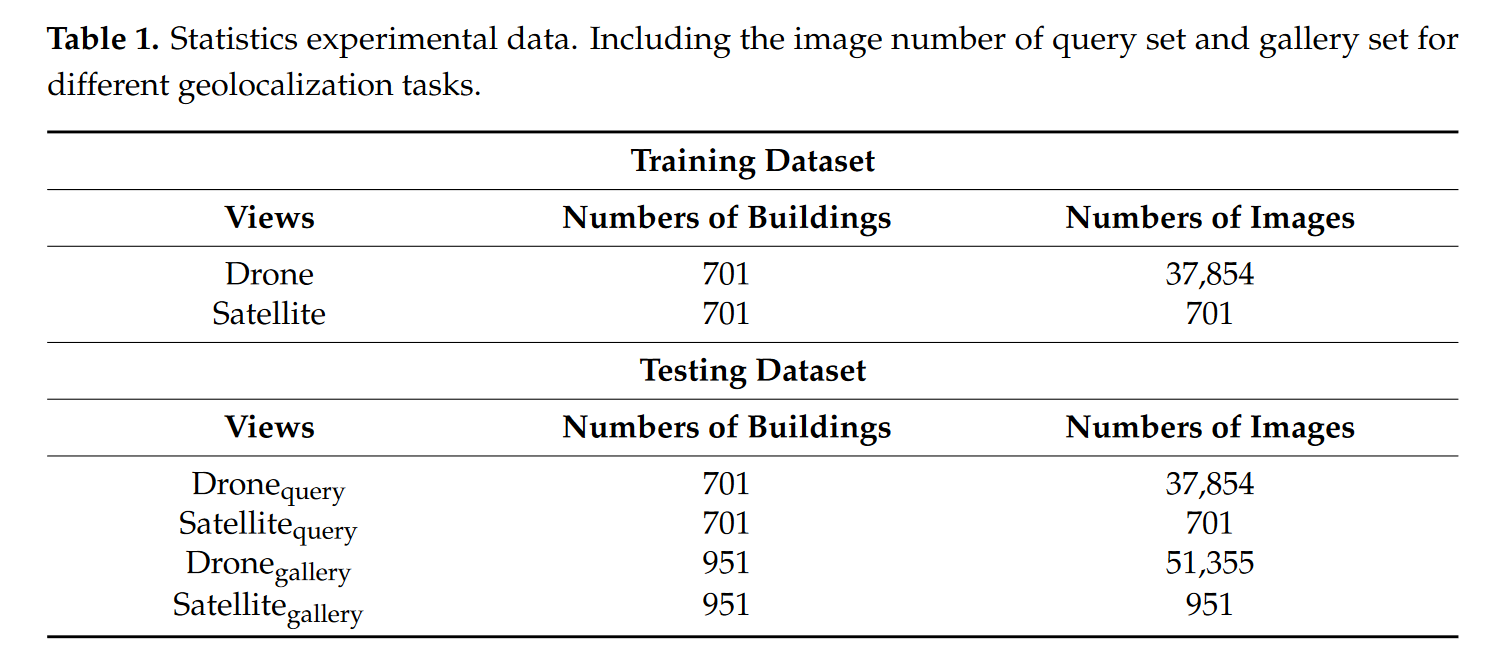
卫星图像的地理标签来自Google地图。Google地图图像与无人机视图图像的比例相似,具有高空间分辨率(从级别18到20,空间分辨率范围从1.07到0.27米)。
由于空域控制和高成本,收集大量真实的无人机视图图像非常困难,因此无人机视图图像是通过Google Earth提供的3D模型模拟的。3D模型中的视图螺旋下降,视图高度从256米到121.5米,同时定期记录图像,以获得接近现实世界的大量无人机图像。
在跨视角匹配和图像检索领域,Recall@K(R@K)和平均精度(AP)是重要的评估指标。R@K指的是顶级K排名列表中匹配图像的数量比率,衡量检索系统的召回率。AP衡量检索系统的精度。这两个指标用于评估方法的性能。
2.2. Backbone Structure
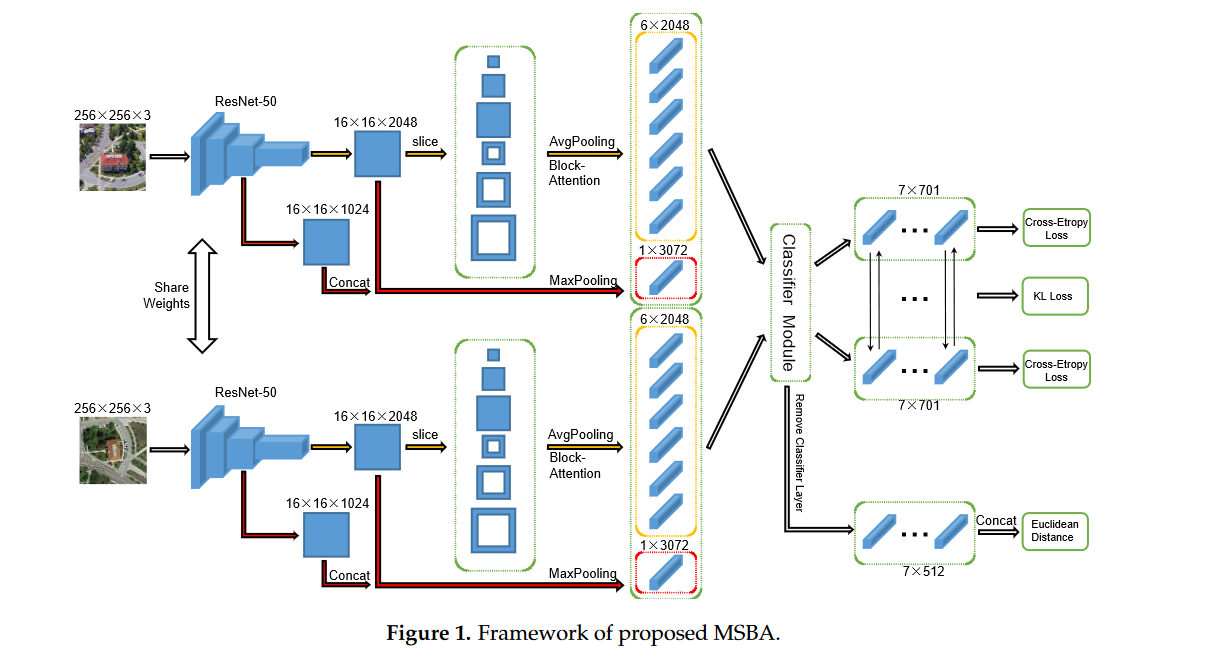
多尺度块注意力网络(MSBA)由两大分支组成,即卫星视图和无人机视图,与其它主流方法[21,28,48]不同,去除了街景视图分支。本研究注重性能和效率,使用Resnet50[49]作为主干网络来提取图像特征。其他具有经典性能的网络,如VGG[50],或具有卓越性能的新网络也是可选的,以实现更好的结果。Resnet50中第四层后的全平均池化层和分类层都被移除了。为了与其他方法进行比较,以256×256大小的图像为例,展示了网络的整个结构和前向传播过程,如图1所示。整个结构被分为两个分支,即无人机视图分支和卫星视图分支,它们共享主干网络的权重。每个分支包含全局(用红色箭头标记的分支)和局部(用黄色箭头标记的分支)。在全局分支中,第三层和第四层后的特图特征被连接起来,然后发送到最大池化层。在局部分支中,第四层后的特图被划分为六个块(详见2.3节),然后对每个块执行平均池化和注意力操作(详见2.5节)。所有汇聚的特征都被发送到分类器模块,包括全连接层、批量归一化层、dropout层和分类层。在训练阶段,模型通过最小化交叉熵损失和KL散度损失(详见2.6节)进行优化。在测试阶段,从分类器模块中移除分类层,并将所有特征连接起来以计算特征空间中图像的欧几里得距离。















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









