







一 特征工程介绍(Feature Engineering)
什么是特征工程? 特征工程解决了什么问题? 为什么特征工程对机器学习很重要? 怎么做特征工程? 怎么做好特征工程? 集众多博友智慧,一文全面了解并应用特征工程。
1 定义及意义
(1)定义
- 特征工程(Feature Engineering)特征工程是将原始数据转化成更好的表达问题本质的特征的过程,使得将这些特征运用到预测模型中能提高对不可见数据的模型预测精度。
- 特征工程简单讲就是发现对因变量y有明显影响作用的特征,通常称自变量x为特征,特征工程的目的是发现重要特征。
- 如何能够分解和聚合原始数据,以更好的表达问题的本质?这是做特征工程的目的。 “feature engineering is manually designing what the input x’s should be.” “you have to turn your inputs into things the algorithm can understand.”
- 特征工程是数据挖掘模型开发中最耗时、最重要的一步。
(2)意义
- 特征工程是一个包含内容很多的主题,也被认为是成功应用机器学习的一个很重要的环节。如何充分利用数据进行预测建模就是特征工程要解决的问题! “实际上,所有机器学习算法的成功取决于如何呈现数据。” “特征工程是一个看起来不值得在任何论文或者书籍中被探讨的一个主题。但是他却对机器学习的成功与否起着至关重要的作用。机器学习算法很多都是由于建立一个学习器能够理解的工程化特征而获得成功的。”——ScottLocklin,in “Neglected machine learning ideas”
- 数据中的特征对预测的模型和获得的结果有着直接的影响。可以这样认为,特征选择和准备越好,获得的结果也就越好。这是正确的,但也存在误导。预测的结果其实取决于许多相关的属性:比如说能获得的数据、准备好的特征以及模型的选择。

(3)相关概念
Feature:An attribute useful for your modeling task. Feature Selection:From many features to a few that are useful Feature Extraction:The automatic construction of new features from raw data. Feature Construction:The manual construction of new features from raw data. Feature Importance:An estimate of the usefulness of a feature.
1)特征与属性的区别?
并不是所有的属性都可以看做特征,区分它们的关键在于看这个属性对解决这个问题有没有影响!可以认为特征是对于建模任务有用的属性。 表格式的数据是用行来表示一个实例,列来表示属性和变量。每一个属性可以是一个特征。特征与属性的不同之处在于,特征可以表达更多的跟问题上下文有关的内容。特征是一个对于问题建模有意义的属性。我们使用有意义(有用的)来区别特征和属性,认为如果一个特征没有意义是不会被认为是特征的,如果一个特征对问题没有影响,那就不是这个问题的一部分。在计算机视觉领域,一幅图像是一个对象,但是一个特征可能是图像中的一行;在自然语言处理中每一个文档或者一条微博是一个对象,一个短语或者单词的计数可以作为特征;在语音识别中,一段声音是一个实例,一个特征可能是单个词或者发音。
2)什么是特征重要性?
特征重要性,可以被认为是一个选择特征重要的评价方法。特征可以被分配一个分值,然后按照这个分值排序,那些具有较高得分的特征可以被选出来包含在训练集中,同时剩余的就可以被忽略。特征重要性得分可以帮助我们抽取或者构建新的特征。挑选那些相似但是不同的特征作为有用的特征。 如果一个特征与因变量(被预测的事物)高度相关,那么这个特征可能很重要。相关系数和其他单变量的方法(每一个变量被认为是相互独立的)是比较通用的评估方法。 更复杂的方法是通过预测模型算法来对特征进行评分。这些预测模型内部有这样的特征选择机制,比如MARS,随机森林,梯度提升机。这些模型也可以得出变量的重要性。
2 流程及方法
特征工程的定义形形色色,笔者同样对特征工程的全流程有着自己的理解。下面三幅图是比较常见的特征工程流程,可以参考,便于理解。跟深入了解特征工程,还是需要在广泛学习的基础上对其有充分的自我理解。 - 1.图一是基本的数据挖掘场景
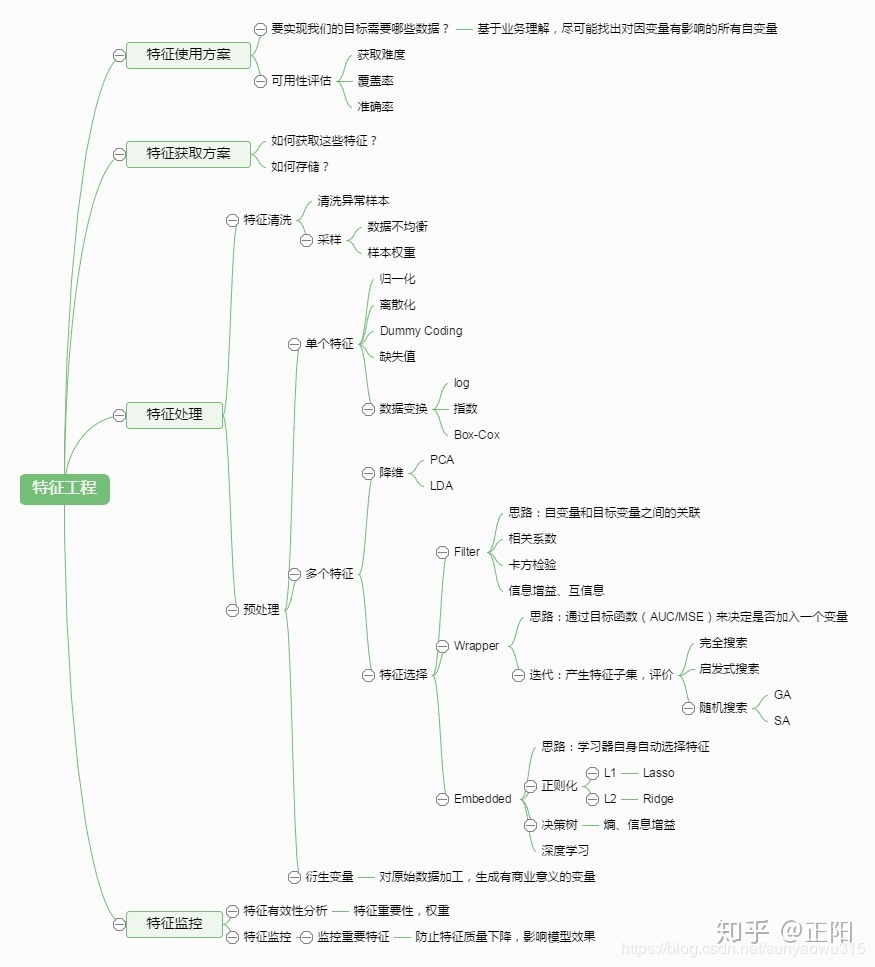
- 2.图二是特征工程的迭代过程

- 3.图三是特征工程的常见方法和步骤

二 数据获取
要实现特征工程目标,要用到什么数据?需要结合特定业务,具体情况具体分析。 重点考虑如下三方面: ①数据获取途径 - 如何获取特征(接口调用or自己清洗or/github资源下载等) - 如何存储?(/data/csv/txt/array/Dataframe//其他常用分布式)
②数据可用性评估 - 获取难度 - 覆盖率 - 准确率
③特征维度
三 数据描述(Feature Describe)
通过数据获取,我们得到未经处理的特征,这时的特征可能有以下问题: - 存在缺失值:缺失值需要补充。 - 不属于同一量纲:即特征的规格不一样,不能够放在一起比较。 - 信息冗余:对于某些定量特征,其包含的有效信息为区间划分,例如学习成绩,假若只关心“及格”或不“及格”,那么需要将定量的考分,转换成“1”和“0”表示及格和未及格。 - 定性特征不能直接使用:某些机器学习算法和模型只能接受定量特征的输入,那么需要将定性特征转换为定量特征。 - 信息利用率低:不同的机器学习算法和模型对数据中信息的利用是不同的。
那么最好先对数据的整体情况做一个描述、统计、分析,并且可以尝试相关的可视化操作。主要可分为以下几方面:
1 数据结构
2 质量检验
标准性、唯一性、有效性、正确性、一致性、缺失值、异常值、重复值
3 分布情况
统计值
包括max, min, mean, std等。python中用pandas库序列化数据后,可以得到数据的统计值。
探索性数据分析(EDA,Exploratory Data Analysis)
集中趋势、离中趋势、分布形状
四 特征处理(Feature Processing)
对数据的整体性有一个宏观的了解之后,即需要进入特征工程第一个重要的环节——特征处理,特征处理会消耗大量时间,并且直接影响特征选择的结果。 特征处理主要包括: ①数据预处理。即数据的清洗工作,主要为缺失值、异常值、错误值、数据格式、采样度等问题的处理。 ②特征转换。即连续变量、离散变量、时间序列等的转换,便于入模。
1 数据预处理
(1)缺失值处理
有些特征可能因为无法采样或者没有观测值而缺失.例如距离特征,用户可能禁止获取地理位置或者获取地理位置失败,此时需要对这些特征做特殊的处理,赋予一个缺失值。我们在进行模型训练时,不可避免的会遇到类似缺失值的情况,下面整理了几种填充空值的方法
1)缺失值删除(dropna)
①删除实例
②删除特征
2)缺失值填充(fillna)
①用固定值填充
对于特征值缺失的一种常见的方法就是可以用固定值来填充,例如0,9999, -9999, 例如下面对灰度分这个特征缺失值全部填充为-99
data['灰度分'] = data['灰度分'].fillna('-99')②用均值填充
对于数值型的特征,其缺失值也可以用未缺失数据的均值填充,下面对灰度分这个特征缺失值进行均值填充
data['灰度分'] = data['灰度分'].fillna(data['灰度分'].mean()))③用众数填充
与均值类似,可以用未缺失数据的众数来填充缺失值
data['灰度分'] = data['灰度分'].fillna(data['灰度分'].mode()))④用上下数据进行填充
- 用前一个数据进行填充
data['灰度分'] = data['灰度分'].fillna(method='pad')- 用后一个数据进行填充
data['灰度分'] = data['灰度分'].fillna(method='bfill')⑤用插值法填充
data['灰度分'] = data['灰度分'].interpolate()⑥用KNN进行填充
from fancyimpute import BiScaler, KNN, NuclearNormMinimization, SoftImpute
dataset = KNN(k=3).complete(dataset)⑦random forest进行填充
from sklearn.ensemble import RandomForestRegressor
zero_columns_2 = ['机构查询数量', '直接联系人数量', '直接联系人在黑名单数量', '间接联系人在黑名单数量',
'引起黑名单的直接联系人数量', '引起黑名单的直接联系人占比']
#将出现空值的除了预测的列全部取出来,不用于训练
dataset_list2 = [x for x in dataset if x not in zero_columns_2]
dataset_2 = dataset[dataset_list2]
# 取出灰度分不为空的全部样本进行训练
know = dataset_2[dataset_2['灰度分'].notnull()]
print(know.shape) #26417, 54
# 取出灰度分为空的样本用于填充空值
unknow = dataset_2[dataset_2['灰度分'].isnull()]
print(unknow.shape) #2078, 54
y = ['灰度分']
x = [1]
know_x2 = know.copy()
know_y2 = know.copy()
print(know_y2.shape)
#
know_x2.drop(know_x2.columns[x], axis=1, inplace=True)
print(know_y2.shape)
print(know_x2.shape)
#
know_y2 = know[y]
# RandomForestRegressor
rfr = RandomForestRegressor(random_state=666, n_estimators=2000, n_jobs=-1)
rfr.fit(know_x2, know_y2)
# 填充为空的样本
unknow_x2 = unknow.copy()
unknow_x2.drop(unknow_x2.columns[x], axis=1, inplace=True)
print(unknow_x2.shape) #(2078, 53)
unknow_y2 = rfr.predict(unknow_x2)
unknow_y2 = pd.DataFrame(unknow_y2, columns=['灰度分'])⑧使用fancyimpute包中的其他方法
# matrix completion using convex optimization to find low-rank solution
# that still matches observed values. Slow!
X_filled_nnm = NuclearNormMinimization().complete(X_incomplete)
# Instead of solving the nuclear norm objective directly, instead
# induce sparsity using singular value thresholding
X_filled_softimpute = SoftImpute().complete(X_incomplete_normalized)
# print mean squared error for the three imputation methods above
nnm_mse = ((X_filled_nnm[missing_mask] - X[missing_mask]) ** 2).mean()
# print mean squared error for the three imputation methods above
nnm_mse = ((X_filled_nnm[missing_mask] - X[missing_mask]) ** 2).mean()
print("Nuclear norm minimization MSE: %f" % nnm_mse)
softImpute_mse = ((X_fi 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4462
4462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









