








文章目录
概述
GwcNet源于文章《Group-Wise Correlation Stereo Network》,是CVPR2019的文章。
文章链接。无论是什么时候的理论发展,总是站在前人的基础上一步一步的去推进,GwcNet也是在PSMNet上进行的扩展。在前人基础上,做出一些一些的改进,才有了精度更好的效果,而GwcNet相比起PSMNet则做出了这样的改动:
- 使用group-wise相关的代价空间。
- 使用了改进的3D stacked 沙漏网络(hourglass network)。
暂时看来,其group-wise相关的代价空间对后来的网络有一定的借鉴意义。
网络架构
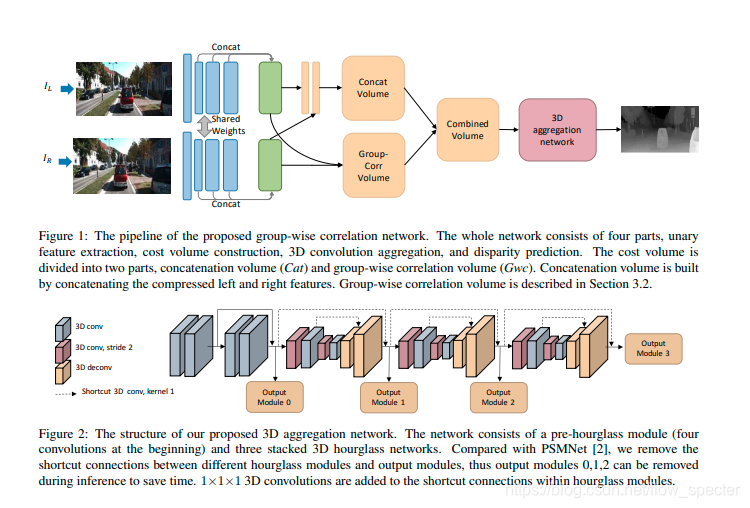
图一是整体的gwc-net的架构,分为四个部分,一维的特征提取,代价空间的构建,3D的代价聚合以及视差预测,和传统的立体匹配方法基本上对应上了。至于代价空间被分成了两个部分,一个是直接级联的Cat(通过级联左右特征得到的),另一个是通过group-wise相关得到的Gwc。
图二则是3D 代价聚合模块的架构。这个网络先是在开头整了四个卷积,然后紧跟着,整了3个3D hourglass network。然后移除掉了hourglass network之间的shortcut connections。
3.2. Group-wise correlation volume
要说group-wise的cost volume的话,那么先去看看与之相对的,之前的cost volume是如何构造的。以psm-net的描述为例。在psm-net中有着这样的描述—“We concatenate the left and right feature maps into a cost volume”,而这个cost volume是4D(高 × \times × 宽 × \times ×视差 × \times ×特征的size)的,由左右特征级联而成的。在实际代码中,有:
def build_concat_volume(refimg_fea, targetimg_fea, maxdisp):
B, C, H, W = refimg_fea.shape
volume = refimg_fea.new_zeros([B, 2 * C, maxdisp, H, W])
for i in range(maxdisp):
if i > 0:
volume[:, :C, i, :, i:] = refimg_fea[:, :, :, i:]
volume[:, C:, i, :, i:] = targetimg_fea[:, :, :, :-i]
else:
volume[:, :C, i, :, :] = refimg_fea
volume[:, C:, i, :, :] = targetimg_fea
volume = volume.contiguous()
return volume
具体解释见另一篇博客,在此不赘述。
而对于基于其进行改进的group-wise correlation volume,代码为:
def groupwise_correlation(fea1, fea2, num_groups):
B, C, H, W = fea1.shape
assert C % num_groups == 0
channels_per_group = C // num_groups
cost = (fea1 * fea2).view([B, num_groups, channels_per_group, H, W]).mean(dim=2)
assert cost.shape == (B, num_groups, H, W)
return cost
def build_gwc_volume(refimg_fea, targetimg_fea, maxdisp, num_groups):
B, C, H, W = refimg_fea.shape
volume = refimg_fea.new_zeros([B, num_groups, maxdisp, H, W])
for i in range(maxdisp):
if i > 0:
volume[:, :, i, :, i:] = groupwise_correlation(refimg_fea[:, :, :, i:], targetimg_fea[:, :, :, :-i],
num_groups)
else:
volume[:, :, i, :, :] = groupwise_correlation(refimg_fea, targetimg_fea, num_groups)
volume = volume.contiguous()
return volume
可以看到,所谓的group-wise相关的代价体其实是将unary features分成许多个组,然后一个组一个组的计算他们的点积,也就是得到代价,这更贴近于我们传统匹配方法中代价的概念,而且通过组的概念减少了参数。在网络中,这个group-wise相关的cost volume后面还跟着级联的cost volume,只不过后面跟着的级联的cost volume的通道要少一些。文章中说,实验结果证明这种相关的cost volume与级联的cost volume是complementary的。
3.3 Improved 3D aggregation module
在psm-net中,代价聚集模块使用的网络架构是stacked hourglass。
gwc-net在其基础上又加了一个辅助输出的模块。此外,去除了不同output模块之间的连接。通过
1
×
1
×
1
1 \times 1\times1
1×1×1的3D卷积在每个hourglass模块间形成了连接。再放一次代价聚集的模块图,可以和附录中的psm-ne代价聚集部分的网络进行比对。
3.4 Output module and loss function
注意到在代价聚集模块中,有0,1,2,3共四个output module, 对于每一个output module而言,都有两个3D卷积,使其输出为一个4D的cost volume, 随即这个volume被上采样并通过在视差维度上使用softmax
函数将其转换为一个概率volume。此时,就可以使用以下公式得到每一个像素的估计视差:
d
~
=
∑
k
=
0
D
m
a
x
−
1
k
⋅
p
k
\widetilde d = \sum_{k=0}^{D_{max}-1}k \cdot p_k
d
=k=0∑Dmax−1k⋅pk
其中,
k
k
k和
p
k
p_k
pk分别表示候选视差的下标以及对应的概率。
从四个output module输出的视差分别记为
d
~
0
\widetilde d_0
d
0,
d
~
1
\widetilde d_1
d
1,
d
~
2
\widetilde d_2
d
2,
d
~
3
\widetilde d_3
d
3。
对于整个网络来说,整体的损失函数为:
L
=
∑
i
=
0
i
=
3
λ
i
⋅
S
m
o
o
t
h
L
i
(
d
~
i
−
d
∗
)
L = \sum_{i=0}^{i=3} \lambda _i \cdot Smooth_{L_i}(\widetilde d_i - d^{*})
L=i=0∑i=3λi⋅SmoothLi(d
i−d∗)
其中,
λ
i
\lambda_i
λi表示第
i
i
i个视差结果的系数,
d
∗
d^{*}
d∗表示真值,
S
m
o
o
t
h
L
1
Smooth_{L_1}
SmoothL1就是Smooth L1,相对于
L
1
L1
L1损失来说处理了0附近的梯度爆炸问题,具体为:
S m o o t h L 1 ( x ) = { 0.5 x 2 , if ∣ x ∣ < 1 ∣ x ∣ − 0.5 , otherwise Smooth_{L_{1}}(x)=\left\{ \begin{array}{ll}0.5 x^{2}, & \text { if }|x|<1 \\ |x|-0.5, & \text { otherwise }\end{array} \right. SmoothL1(x)={0.5x2,∣x∣−0.5, if ∣x∣<1 otherwise
附录
hourglass network
文中的hourglass network可以追踪到PsmNet,在psm-net中首次出现的关于hourglass的原文是:
“Moreover, we design a stacked hourglass
3D CNN in conjunction with intermediate supervision to
regularize the cost volume. The stacked hourglass 3D CNN
repeatedly processes the cost volume in a top-down/bottomup manner to further improve the utilization of global context information.”
即,设计的stacked hourglass 3D CNN模块中间加了自监督,这个模块反反复复的对代价空间进行处理,目的就是尽可能多的利用全局语义信息。
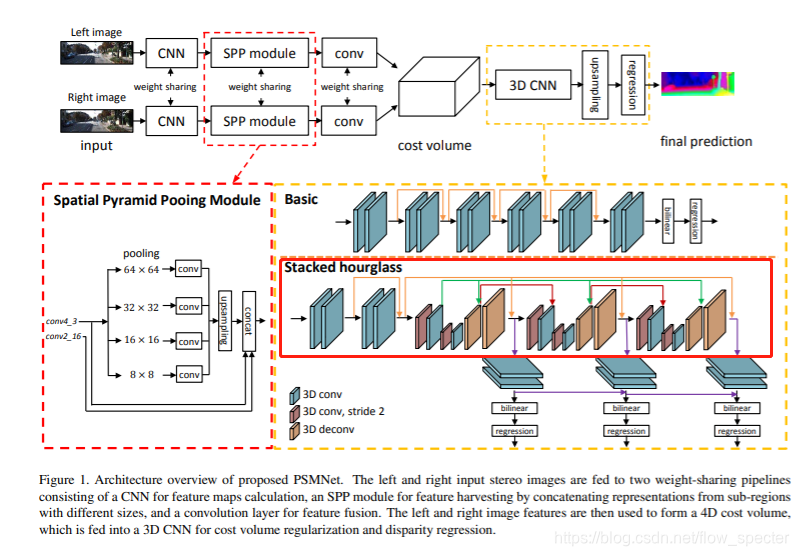
下图为PSM的整体网络结构,我用红框标出来的部分就是stacked hourglass了:
其实stacked hourglass network的出处是《Stacked Hourglass Networks for Human Pose Estimation》,作者设计这个网络的初衷是想要捕捉整合图像所有尺度的信息,至于为什么叫做stacked hourglass network呢,其实就是这个网络结构,长得很像堆起来的沙漏。
参考链接1:源于知乎



















 318
318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











