









 本文深入剖析SSD目标检测模型,介绍其创新点、网络结构、训练过程及损失函数等核心内容。SSD结合了YOLO的速度与Faster R-CNN的准确性,通过多尺度特征图、卷积检测及先验框策略,实现了实时高精度的目标检测。
本文深入剖析SSD目标检测模型,介绍其创新点、网络结构、训练过程及损失函数等核心内容。SSD结合了YOLO的速度与Faster R-CNN的准确性,通过多尺度特征图、卷积检测及先验框策略,实现了实时高精度的目标检测。
简介
这篇文章提出了一个新的目标检测模型SSD,这是一种 single stage 的检测模型,相比于R-CNN系列模型上要简单许多。其精度可以与Faster R-CNN相匹敌,而速度达到了惊人的59FPS,速度上完爆 Fster R-CNN。
基于”Proposal + Classification”的Object Detection的方法,RCNN系列(R-CNN、SPPnet、Fast R-CNN以及Faster R-CNN)取得了非常好的效果,因为这一类方法先预先回归一次边框,然后再进行骨干网络训练,所以精度要高,这类方法被称为two stage的方法。但也正是由于此,这类方法在速度方面还有待改进。由此,YOLO应运而生,YOLO系列只做了一次边框回归和打分,所以相比于RCNN系列被称为one stage的方法,这类方法的最大特点就是速度快。但是YOLO虽然能达到实时的效果,但是由于只做了一次边框回归并打分,这类方法导致了小目标训练不充分及定位不太准确的问题。简而言之,YOLO系列对于目标的尺度比较敏感,而且对于尺度变化较大的物体泛化能力比较差(YOLOv2和YOLOv3也用了多尺度训练,有改善)。
针对YOLO和Faster R-CNN的各自不足与优势,WeiLiu等人提出了Single Shot MultiBox Detector,简称为SSD。SSD整个网络采取了one stage的思想,以此提高检测速度。并且网络中融入了Faster R-CNN中的anchors思想,并且做了特征分层提取并依次计算边框回归和分类操作,由此可以适应多种尺度目标的训练和检测任务。SSD的出现使得大家看到了实时高精度目标检测的可行性。
SSD算法速度快的根本原因在于移除了 region proposals 步骤以及后续的像素采样或者特征采样步骤。(The fundamental improvement in speed comes from eliminating bounding box proposals and the subsequent pixel or feature resampling stage.)
当然作者还是使用了比较多的trick的,总的来说,SSD相比于YOLO(这里指YOLOv1)的改进主要有三点:
- 采用了全卷积的网络,去掉了YOLO网络结构最后的全连接层;
- SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体;
- SSD采用了不同尺度和长宽比的先验框(Prior boxes, Default boxes,在Faster R-CNN中叫做锚,Anchors)。
Yolo算法缺点是难以检测小目标,而且定位不准,但是这几点重要改进使得SSD在一定程度上克服这些缺点。
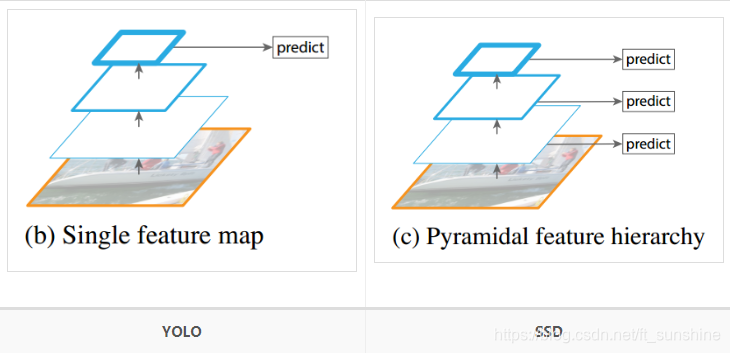
创新点
首先我们来明确几个概念:
- 先验框:即预先设置好的大小、长宽比不同的anchor。模型预测输出的检测框是在先验框的基础上调整而来的;
- 边界框/检测框:模型预测输出的物体位置(框),模型预测输出的检测框是在先验框的基础上调整而来的;
- gt框:真实的物体位置(边界框的真实位置);
采用多尺度特征图用于检测
所谓多尺度采用大小不同的特征图,CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图大小,得到一些比较大的特征图和一些比较小的特征图,它们都用来做检测。这样做的好处是比较大的特征图来用来检测相对较小的目标。效果如下:
采用卷积进行检测
与Yolo最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为 m × n × p m \times n \times p m×n×p的特征图,只需要采用 3 × 3 × p 3 \times 3 \times p 3×3×p这样比较小的卷积核得到检测值。
设置先验框
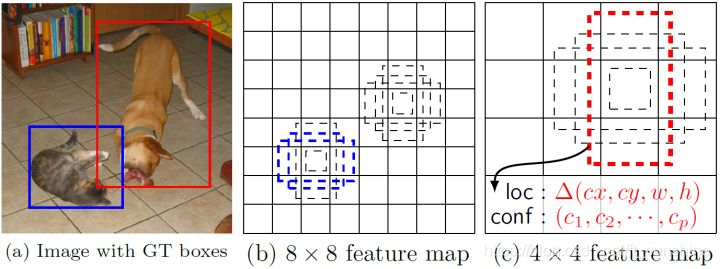
在Yolo中,每个单元预测多个边界框,但是其都是相对这个单元本身(正方块),但是真实目标的形状是多变的,Yolo需要在训练过程中自适应目标的形状。而SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框,预测的边界框(bounding boxes)是以这些先验框为基准的,在一定程度上减少训练难度。一般情况下,每个单元会设置多个先验框,其尺度和长宽比存在差异,如下图所示,可以看到每个单元使用了4个不同的先验框,图片中猫和狗分别采用最适合它们形状的先验框来进行训练,后面会详细讲解训练过程中的先验框匹配原则。
SSD的检测值也与Yolo不太一样。对于每个单元的每个先验框,其都输出一套独立的检测值(其实YOLOv2和YOLOv3都改进成这么做的了)。对应一个边界框,主要分为两个部分。第一部分是各个类别的置信度或者评分,值得注意的是SSD将背景也当做了一个特殊的类别,如果检测目标共有 c c c个类别,SSD其实需要预测 c + 1 c+1 c+1个类别置信度值,其中第一个置信度指的是不含目标或者属于背景的评分。后面当我们说 c c c个类别置信度时,请记住里面包含背景那个特殊的类别,即真实的检测类别只有 [公式] 个。在预测过程中,置信度最高的那个类别就是边界框所属的类别,特别地,当第一个置信度值最高时,表示边界框中并不包含目标。第二部分就是边界框的location,包含4个值 ( c x , c y , w , h ) (cx,cy,w,h) (cx,cy,w,h),分别表示边界框的中心坐标以及宽高。但是真实预测值其实只是边界框相对于先验框的转换值(paper里面说是offset,但是觉得transformation更合适,参见R-CNN)。先验框位置用 d = ( d c x , d c y , d w , d h ) d=\left(d^{c x}, d^{c y}, d^{w}, d^{h}\right) d=(dcx,dcy,dw,dh)表示,其对应边界框用 b = ( b c x , b c y , b w , b h ) b=\left(b^{c x}, b^{c y}, b^{w}, b^{h}\right) b=(bcx,bcy,bw,bh)表示,那么边界框的预测值 l l l其实是 b b b相对于 d d d的转换值:
l c x = ( b c x − d c x ) / d w , l c y = ( b c y − d c y ) / d h {l^{c x}=\left(b^{c x}-d^{c x}\right) / d^{w}, l^{c y}=\left(b^{c y}-d^{c y}\right) / d^{h}} lcx=(bcx−dcx)/dw,lcy=(bcy−dcy)/dh
l w = log ( b w / d w ) , l h = log ( b h / d h ) {l^{w}=\log \left(b^{w} / d^{w}\right), l^{h}=\log \left(b^{h} / d^{h}\right)} lw=log(bw/dw),lh=log(bh/dh)
习惯上,我们称上面这个过程为边界框的编码(encode),预测时,你需要反向这个过程,即进行解码(decode),从预测的转换值 l l l中得到边界框的真实位置 b b b:
b c x = d w l c x + d c x , b c y = d y l c y + d c y b^{c x} =d^{w} l^{c x}+d^{c x}, b^{c y}=d^{y} l^{c y}+d^{c y} bcx=dwlcx+dcx,bcy=dylcy+dcy
b w = d w exp ( l w ) , b h = d h exp ( l h ) b^{w} =d^{w} \exp \left(l^{w}\right), b^{h}=d^{h} \exp \left(l^{h}\right) bw=dwexp(lw),bh=dhexp(lh)
然而,在SSD的Caffe源码实现中还有trick,那就是设置variance超参数来调整检测值,通过bool参数variance_encoded_in_target来控制两种模式,当其为True时,表示variance被包含在预测值中,就是上面那种情况。但是如果是False(大部分采用这种方式,训练更容易?),就需要手动设置超参数variance,用来对 l l l的4个值进行放缩,此时边界框需要这样解码:(其实这里不是很重要,相当于后处理再调整一下边界框而已)
b c x = d w ( variance [ 0 ] ∗ l c x ) + d c x , b c y = d y ( variance [ 1 ] ∗ l c y ) + d c y {b^{c x}=d^{w}\left(\text {variance}[0] * l^{c x}\right)+d^{c x}, b^{c y}=d^{y}\left(\text {variance}[1] * l^{c y}\right)+d^{c y}} bcx=dw(variance[0]∗lcx)+dcx,bcy=dy(variance[1]∗lcy)+dcy
b w = d w exp ( variance [ 2 ] ∗ l w ) , b h = d h exp ( variance [ 3 ] ∗ l h ) {b^{w}=d^{w} \exp \left(\text {variance}[2] * l^{w}\right), b^{h}=d^{h} \exp \left(\text {variance}[3] * l^{h}\right)} bw=dwexp(variance[2]∗lw),bh=dhexp(variance[3]∗lh)
综上所述,对于一个大小 m × n m \times n m×n的特征图,共有 m n mn mn个单元,每个单元设置的先验框数目记为 k k k(即相当于每个点设置了k个anchor),那么每个单元共需要 ( c + 4 ) k (c+4)k (c+4)k个预测值,所有的单元共需要 ( c + 4 ) k m n (c+4)kmn (c+4)kmn个预测值,由于SSD采用卷积做检测,所以就需要 ( c + 4 ) k (c+4)k (c+4)k个卷积核完成这个特征图的检测过程。
网络结构
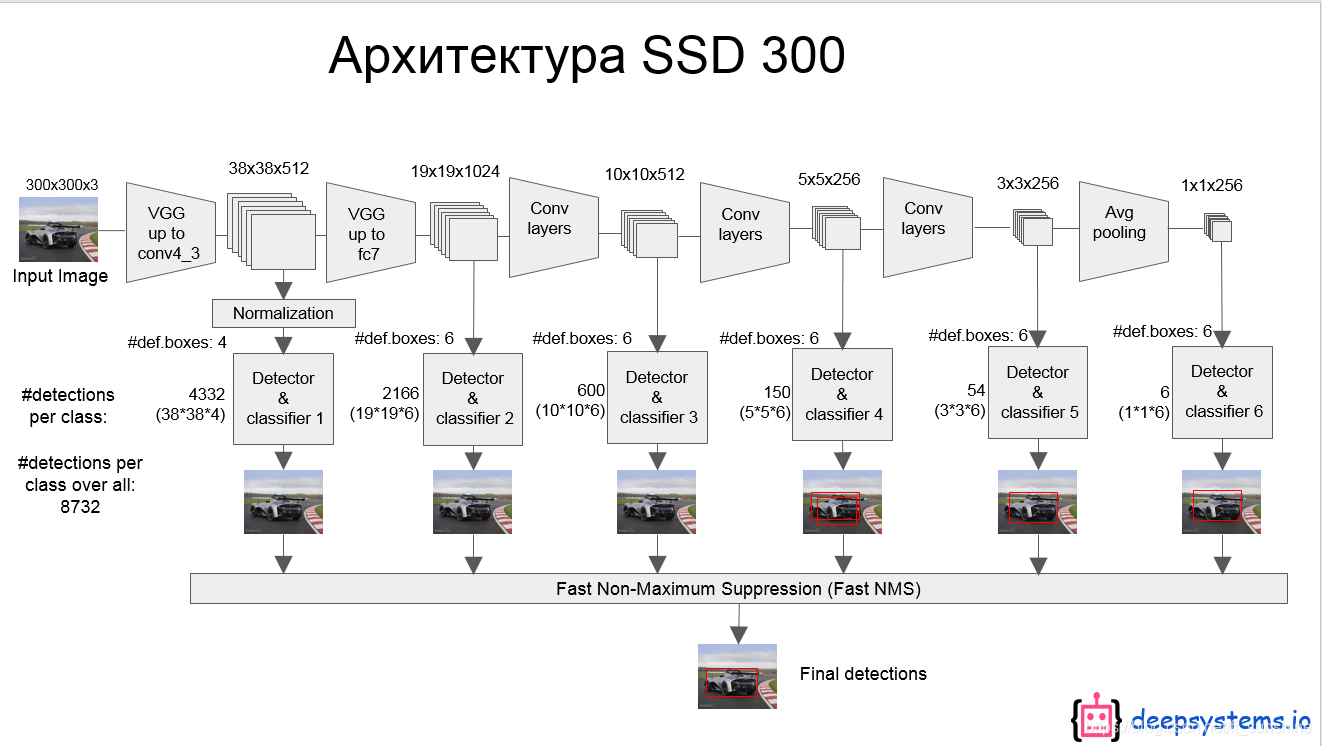
SSD网络结构如图所示:
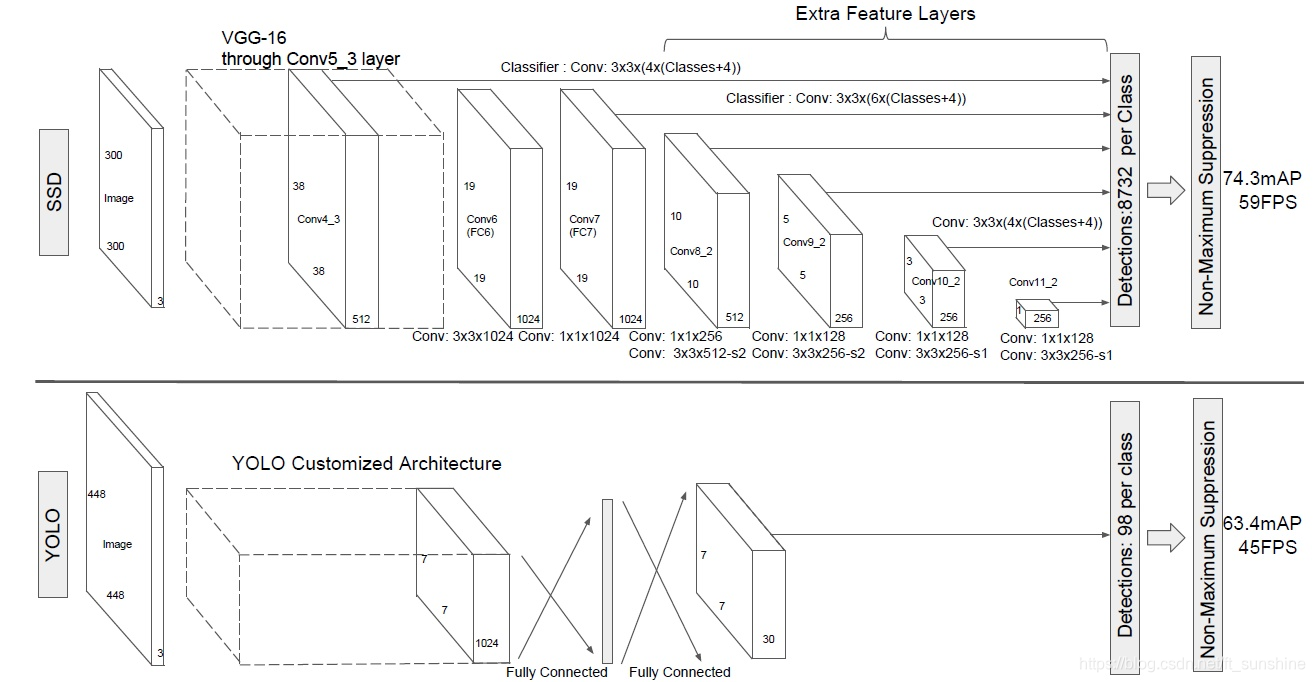
- 网络模型如上图,前面是一个VGG层用于特征提取,与VGG的区别是把FC6和FC7换成了卷积层,SSD在后面又加了8个卷积层。
- 最终用于预测的是从这些具有金字塔结构的层中选出的特定层,这些层分别对不同scale(scale的平方是面积,这个参数是假设不考虑纵横比的时候,box的边长)和不同aspect ratios(也就是纵横比)的 bounding box进行预测。
- bounding box是 detector/classifier 对 default box 进行回归生成的,而 default box 是由一定规则生成的,这里可以认为 default box 比较像 Faster R-CNN 中的anchor。
从后面新增的卷积层中提取Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2作为检测所用的特征图,加上Conv4_3层,共提取了6个特征图。不同特征图设置的先验框数目不同(同一个特征图上每个单元设置的先验框是相同的,这里的数目指的是一个单元的先验框数目)。先验框的设置,包括尺度(或者说大小)和长宽比两个方面。关于每个特征图上设置的先验框(anchor)大小、长宽比以及数量,其遵循一定的规则,请参考文章。
总之,SSD的本质就是密集采样。
训练过程
先验框匹配策略
匹配策略。分类问题中是不需要匹配策略的,这里之所以要使用匹配策略是由于定位问题引入的。可以简单的认为 检测=分类+定位,这里的定位使用的是回归方法。那么这里SSD中的回归是怎么弄的?
我们知道平面上任意两个不重合的框都是可以通过对其中一个框进行一定的变换(比如线性变换+对数变换)使二者重合的。
在SSD中,通俗的说就是先产生一些预选的default box(类似于anchor box),然后标签是 ground truth box,预测的是bounding box,现在有三种框,从default box到ground truth有个变换关系,从default box到prediction bounding box有一个变换关系,如果这两个变换关系是相同的,那么就会导致 prediction bounding box 与 ground truth重合,如下图:
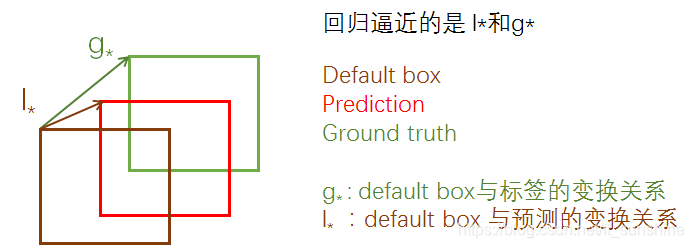
所以回归的就是这两个 变换关系:
l
∗
l_*
l∗与
g
∗
g_*
g∗ ,只要二者接近,就可以使prediction bounding box接近 ground truth box 。上面的
g
∗
g_*
g∗是只在训练的时候才有的,inference 时,就只有
l
∗
l_*
l∗了,但是这时候的
l
∗
l_*
l∗已经相当精确了,所以就可以产生比较准确的定位效果。
现在的问题是生成的 default box (即上面说的先验框,类似anchor)是有很多的,那么势必会导致只有少部分是包含目标或者是与目标重叠关系比较大的,那当然只有这一少部分先验框才是我们的重点观察对象,我们才能把他用到上述提到的回归过程中去。因为越靠近标签的default box回归的时候越容易,如果二者一个在最上边,一个在最下边,那么回归的时候难度会相当大,而且也会更耗时间。
确定这少部分重点观察对象的过程就是匹配策略。原文是这么所的:ground truth information needs to be assigned to specific outputs in the fixed set of detector outputs ,实际上就是确定正样本的过程,这在YOLO,Faster R-CNN ,Multi-box中也都用到了。
做法如下:
在训练过程中,首先要确定训练图片中的ground truth(真实目标)与哪个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。 在Yolo中,ground truth的中心落在哪个单元格,该单元格中与其IOU最大的边界框负责预测它。但是在SSD中却完全不一样,SSD的先验框与ground truth的匹配原则主要有两点。首先,对于图片中每个ground truth,找到与其IOU最大的先验框,该先验框与其匹配,这样,可以保证每个ground truth一定与某个先验框匹配。通常称与ground truth匹配的先验框为正样本(其实应该是先验框对应的预测box,不过由于是一一对应的就这样称呼了),反之,若一个先验框没有与任何ground truth进行匹配,那么该先验框只能与背景匹配,就是负样本。一个图片中ground truth是非常少的, 而先验框却很多,如果仅按第一个原则匹配,很多先验框会是负样本,正负样本极其不平衡,所以需要第二个原则。第二个原则是:对于剩余的未匹配先验框,若某个ground truth的IOU大于某个阈值(一般是0.5),那么该先验框也与这个ground truth进行匹配。这意味着某个ground truth可能与多个先验框匹配,这是可以的。但是反过来却不可以,因为一个先验框只能匹配一个ground truth,如果多个ground truth与某个先验框IOU大于阈值,那么先验框只与IOU最大的那个先验框进行匹配。第二个原则一定在第一个原则之后进行,仔细考虑一下这种情况,如果某个ground truth所对应最大IOU小于阈值,并且所匹配的先验框却与另外一个ground truth的IOU大于阈值,那么该先验框应该匹配谁,答案应该是前者,首先要确保某个ground truth一定有一个先验框与之匹配。但是,这种情况我觉得基本上是不存在的。由于先验框很多,某个ground truth的最大IOU肯定大于阈值,所以可能只实施第二个原则既可以了,这里的TensorFlow版本就是只实施了第二个原则,但是这里的Pytorch两个原则都实施了下图为一个匹配示意图,其中绿色的GT是ground truth,红色为先验框,FP表示负样本,TP表示正样本。
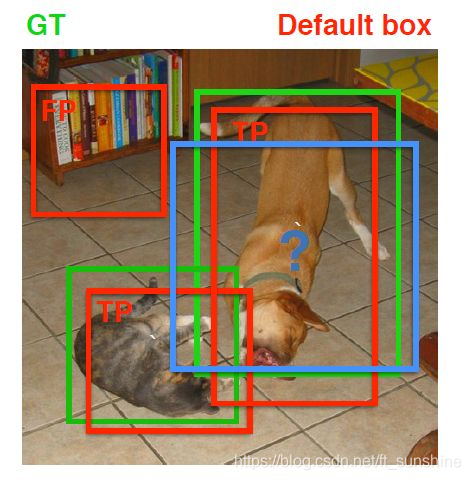
尽管一个ground truth可以与多个先验框匹配,但是ground truth相对先验框还是太少了,所以负样本相对正样本会很多。为了保证正负样本尽量平衡,SSD采用了hard negative mining,就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
损失函数
训练样本确定了,然后就是损失函数了。损失函数定义为位置误差(locatization loss, loc)与置信度误差(confidence loss, conf)的加权和:
L
(
x
,
c
,
l
,
g
)
=
1
N
(
L
c
o
n
f
(
x
,
c
)
+
α
L
l
o
c
(
x
,
l
,
g
)
)
L(x, c, l, g)=\frac{1}{N}\left(L_{c o n f}(x, c)+\alpha L_{l o c}(x, l, g)\right)
L(x,c,l,g)=N1(Lconf(x,c)+αLloc(x,l,g))
其中 N N N是先验框的正样本数量。这里 x i j p ∈ { 0 , 1 } x_{ij}^p \in \{0,1\} xijp∈{0,1}为一个指示参数,当 x i j p = 1 x_{ij}^p = 1 xijp=1时表示第 i i i个先验框与第 j j j个ground truth匹配,并且ground truth的类别为 p p p。 c c c为类别置信度预测值。 l l l为先验框的所对应边界框的位置预测值,而 g g g是ground truth的位置参数。对于位置误差,其采用Smooth L1 loss,定义如下:
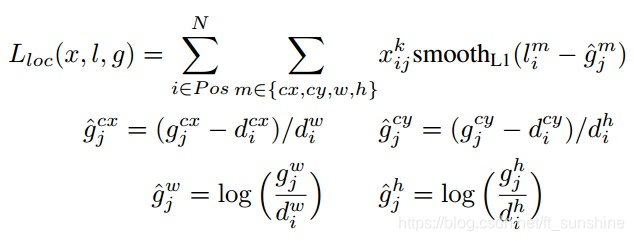
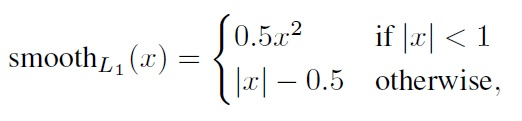
由于 x i j p x_{ij}^p xijp的存在,所以位置误差仅针对正样本进行计算。值得注意的是,要先对ground truth的 g g g进行编码得到 g ^ \hat g g^,因为预测值 l l l也是编码值,若设置variance_encoded_in_target=True,编码时要加上variance:
g ^ j c x = ( g j c x − d i c x ) / d i w / variance [ 0 ] , g ^ j c y = ( g j c y − d i c y ) / d i h / variance [ 1 ] \hat{g}_{j}^{c x}=\left(g_{j}^{c x}-d_{i}^{c x}\right) / d_{i}^{w} / \text {variance}[0], \hat{g}_{j}^{c y}=\left(g_{j}^{c y}-d_{i}^{c y}\right) / d_{i}^{h} / \text {variance}[1] g^jcx=(gjcx−dicx)/diw/variance[0],g^jcy=(gjcy−dicy)/dih/variance[1]
g ^ j w = log ( g j w / d i w ) / variance [ 2 ] , g ^ j h = log ( g j h / d i h ) / variance [ 3 ] \hat{g}_{j}^{w}=\log \left(g_{j}^{w} / d_{i}^{w}\right) / \text {variance}[2], \hat{g}_{j}^{h}=\log \left(g_{j}^{h} / d_{i}^{h}\right) / \text {variance}[3] g^jw=log(gjw/diw)/variance[2],g^jh=log(gjh/dih)/variance[3]
对于置信度误差,其采用softmax loss:
L c o n f ( x , c ) = − ∑ i ∈ P o s N x i j p log ( c ^ i p ) − ∑ i ∈ N e g log ( c ^ i 0 ) where c ^ i p = exp ( c i p ) ∑ p exp ( c i p ) L_{c o n f}(x, c)=-\sum_{i \in P o s}^{N} x_{i j}^{p} \log \left(\hat{c}_{i}^{p}\right)-\sum_{i \in N e g} \log \left(\hat{c}_{i}^{0}\right) \quad \text { where } \quad \hat{c}_{i}^{p}=\frac{\exp \left(c_{i}^{p}\right)}{\sum_{p} \exp \left(c_{i}^{p}\right)} Lconf(x,c)=−i∈Pos∑Nxijplog(c^ip)−i∈Neg∑log(c^i0) where c^ip=∑pexp(cip)exp(cip)
权重系数 α \alpha α通过交叉验证设置为1。
各种Trick分析
文章还对SSD的各个trick做了更为细致的分析,下图为不同的trick组合对SSD的性能影响,从图中可以得出如下结论:
- 数据扩增技术很重要,对于mAP的提升很大;
- 使用不同长宽比的先验框可以得到更好的结果;

同样的,采用多尺度的特征图用于检测也是至关重要的,这可以下图中看出:

done~

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









