







目录
计算机视觉是人工智能领域最热门的研究领域之一,并且是近几年发展最快的人工智能领域之一。CV(Computer Vision)领域的快速发展主要得益于卷积神经网络的使用。
计算机视觉介绍
1、计算机视觉应用
人脸识别

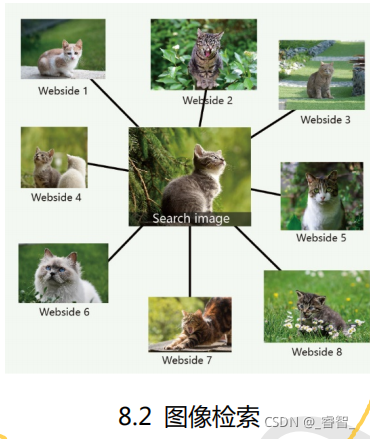
图像检索(搜索引擎图片搜索)
监控


自动驾驶(检测交通标志、路上的行人和车辆等)

2、计算机视觉技术
图像分类
图像分类就是图像识别,识别一张图片中的物体,然后给出类别判断。一般对一张图片我们可能会得到多个类别判断,我们可以根据类别的置信度(模型认为图片属于该类别的概率)从高到低进行排序,然后得到可能性最大的几个类别。
目标检测
有时候我们不仅要识别图片是属于什么类别,还需要把它们给框选出来、确定它们在图片中的位置和大小。
目标跟踪
目标跟踪是指在特定场景跟踪某一个或多个特定感兴趣对象的过程。
语义分割
语义分割可以将图像分为不同的语义可解释类别,例如我们可能会把图片中汽车的颜色都用蓝色的表示,所有行人用红色表示。与图像分类或目标检测相比,语义分割可以让我们对图像有更加细致的了解。
实例分割
实例分割可以将不同类型的实例进行分类,比如用 4 种颜色来表示 4 辆不同的汽车,用8 种颜色表示 8 个不同的人。

BP神经网络的缺点
有一个细节问题当时我们可能没有注意到,当时我们使用的手写数字图片是 28×28 的黑白图片,输入数据一共有 28×28×1 个数据,所以输入层只需要 784 个神经元。假如我们有一张1000 * 1000的彩色图片,那么输入层神经元就需要 1000×1000×3 个,我们使用带有一个隐藏层的神经网络,隐藏层神经元个数为 1000,那么输入层和隐藏层之间权值的个数就会有 30 亿个,这是一个非常巨大的数字。如此大量的权值会带来两个问题,一个问题是计算量巨大,要计算这么多权值就需要花费大量时间。第二个问题是要训练这么多权值就需要大量的训练样本来进行训练,防止模型过拟合。因此我们需要使用卷积神经网络解决计算机视觉任务中权值数量巨大的问题。
一、卷积神经网络简介
1、卷积
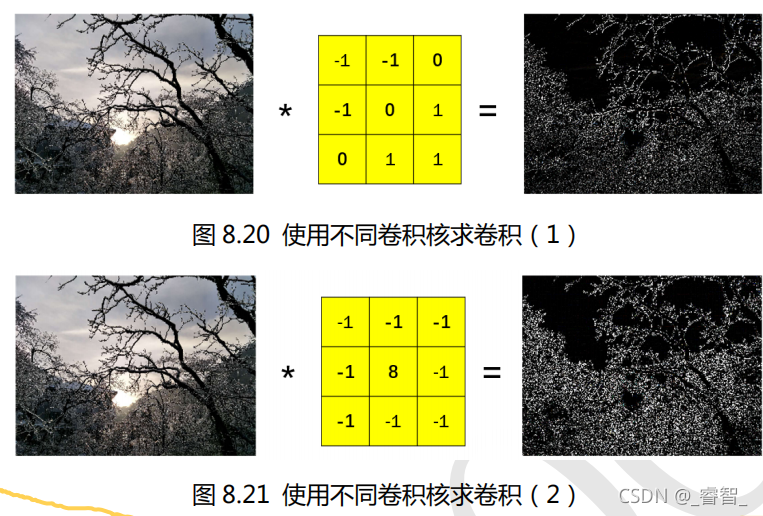
卷积目的:找到特征。
剔除不重要的信息,保留重要的信息。
不同卷积核提取不同特征。

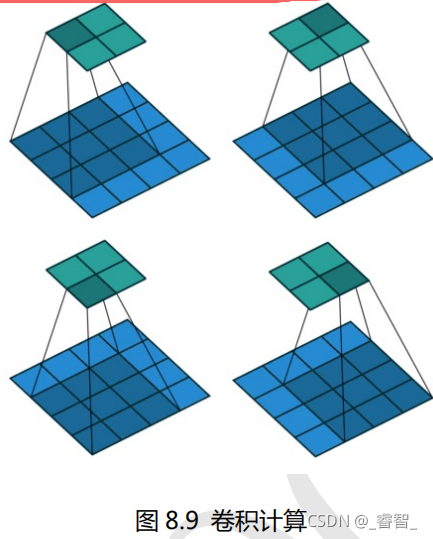
卷积神经网络就是一种包含卷积计算的神经网络。卷积计算是一种计算方式,有一个卷积 窗口(Convolution Window) 在一个平面上滑动,每次滑动会进行一次卷积计算得到一个数值,卷积窗口滑动计算完成后会得到一个用于表示图像特征的特征图。
2、全连接与局部感受野

3、权值共享
外卷积神经网络还用到了权值共享(Weight Sharing)。这里的权值共享指的是同一卷积层中的同一个卷积窗口的权值是共享的。
例:
使用 3×3 的卷积窗口(也就是后一层的一个神经元连接前一层 3×3 的区域)对 1000×1000的图片求卷积, 那么输入层和卷积层之间一共有多少个权值需要训练?

二、卷积计算
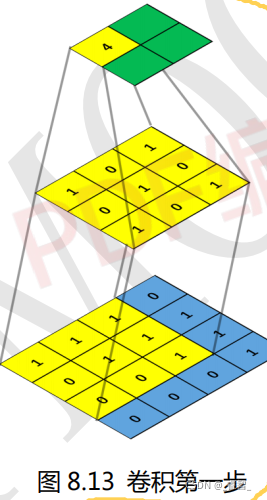
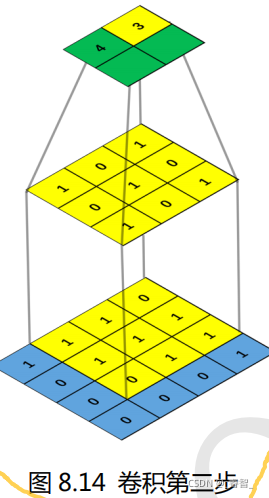
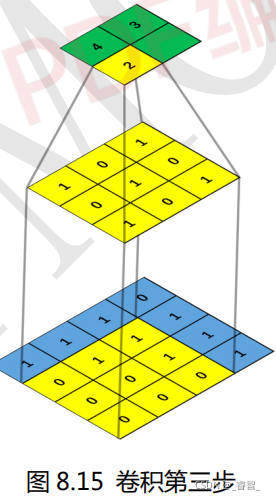
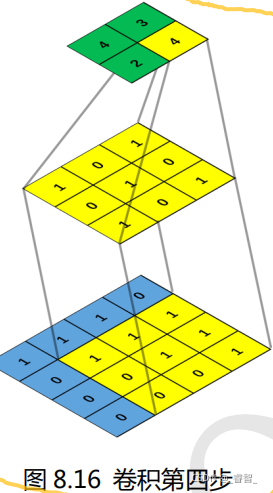
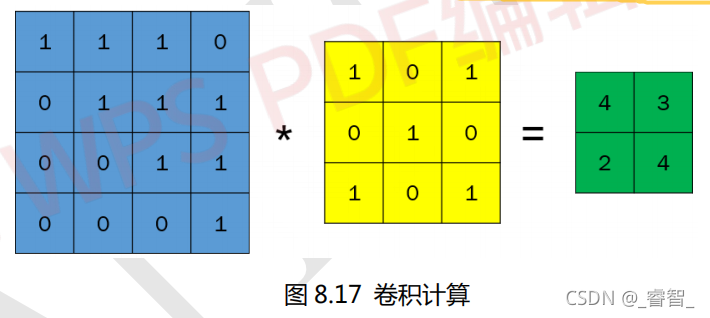
卷积窗口又称为卷积核(Convolution Kernel) ,卷积之后生成的图称为特征图。卷积窗口/卷积核一般都是使用正方形的,比如 1×1,3×3,5×5 等,极少数特殊情况才会使用长方形。对一张图片求卷积实际上就是卷积核在图片上面滑动,并进行卷积计算。卷积计算很简单,就是卷积核与图片中对应位置的数值相乘然后再求和。
例:
1、
![]()
2、
![]()
3、
![]()
4、
![]()
综上:
三、不同卷积核

四、池化
池化作用
池化分类
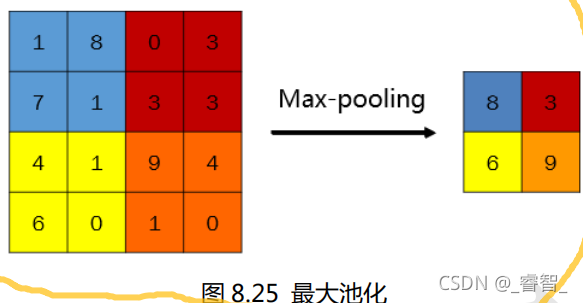
最大池化:
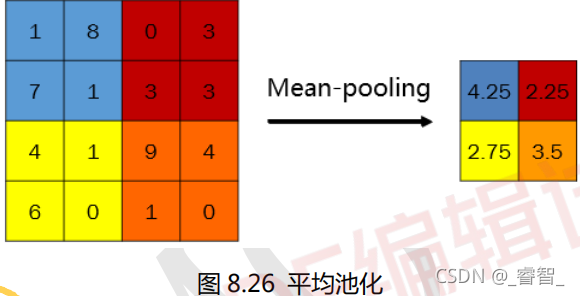
平均池化:
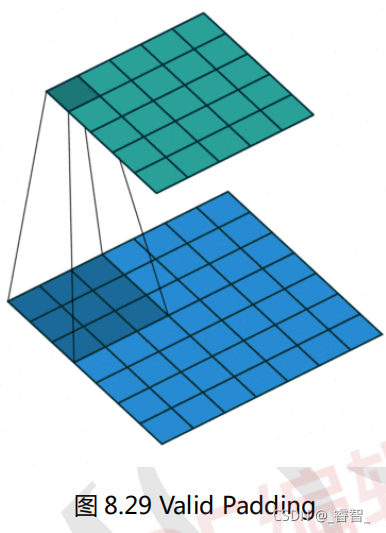
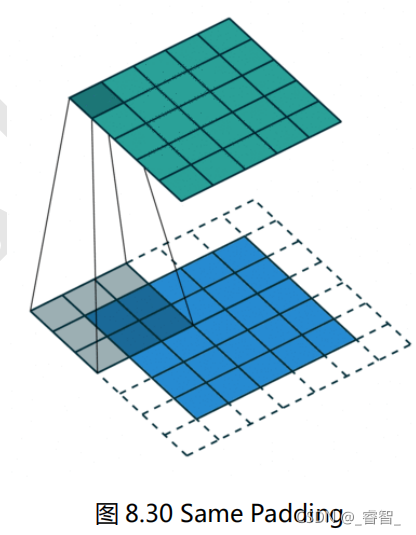
五、Padding
扩充图片,补充像素点。
作用:
1、保留边界信息;
2、对尺寸有差异的图片进行补充,使图片尺寸一致;
3、卷积神经网络的卷积层加入Padding,可以使得卷积层的输入维度和输出维度一致;
4、卷积神经网络的池化层加入Padding,一般都是保持边界信息。

在计算卷积的时候图像中间的数据会重复使用多次,而图像边缘的数据可能只会被用到一次。四个角的四个数据只计算了一次,而图像中心的四个数据则计算了四次,这就表示卷积容易丢失掉图像的边缘特征(不过其实边缘位置的信息一般来说也没这么重要)。我们可以使用 Padding 的方式来解决。卷积和池化操作都可以使用Padding。


六、常见的卷积计算
1、对一张图像卷积生成一张特征图
对一张图像卷积生成一张特征图是最简单的卷积方式:

2、对一张图像卷积生成多张特征图
生成多张特征图需要多个不同的卷积核求卷积。(有几个卷积核生成几张特征图)
3个卷积核(3个特征图):
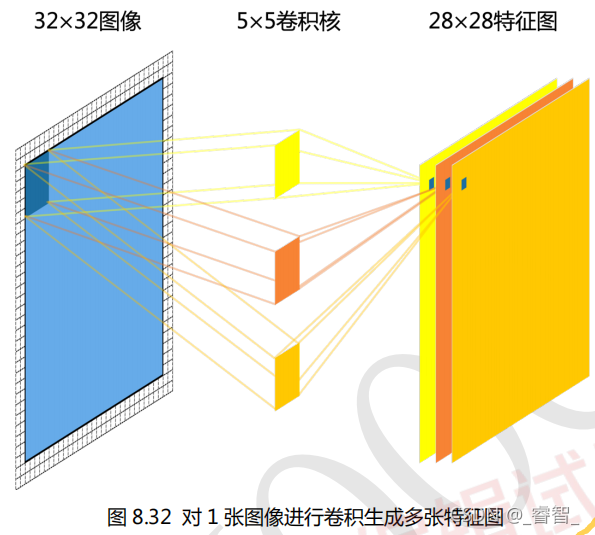
因为每个卷积核中的权值不同,所以使用 3 个不同的卷积核求卷积会得到 3 个不同的特征图。一个卷积核会对原始图像进行 5×5×28×28 次乘法计算,所以总共计算量为5×5×28×28×3=58800。总共有 5×5×3=75 个权值和 3 个偏置值需要训练。偏置值数量主要跟特征图数量相关,每个特征图有 1 个偏置值。
3、对多张图像卷积生成一张特征图
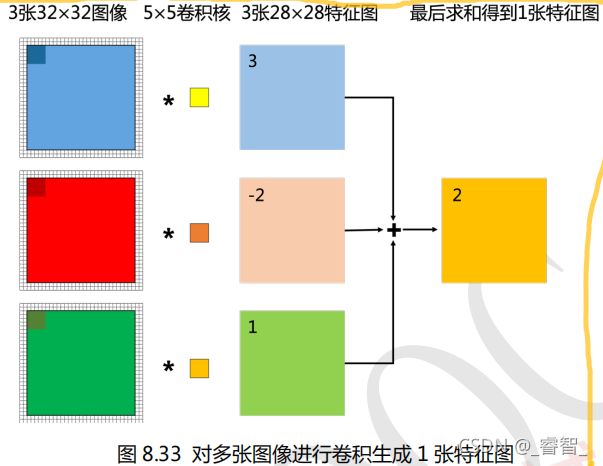
对 3 张图像进行卷积的时候先分别对每张图像进行卷积,得到 3 个大小相同,数值不同的特征图。然后再对每个特征图对应位置的数值进行相加,最后得到 1 个特征图。(我们对不同图像进行卷积的时候,所使用的卷积核也是不同的)
4、对多张图像进行卷积生成多张特征图
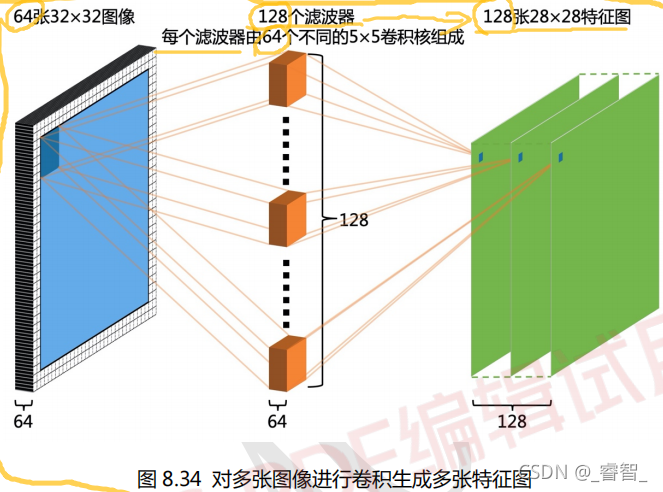

七、经典神经网络
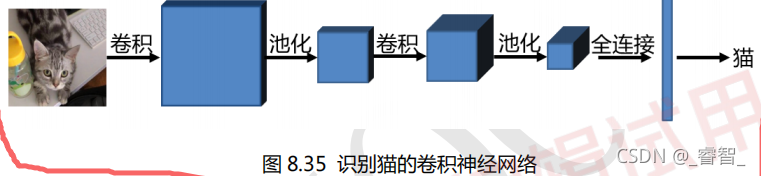
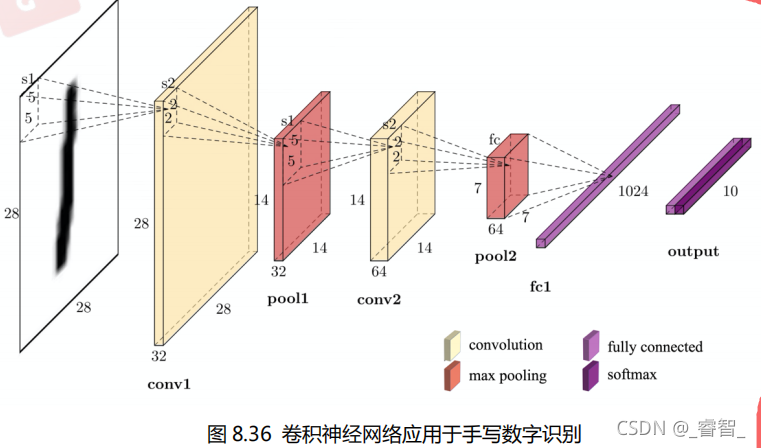
CNN应用在手写数字识别
第一层:卷积层。
第二层:卷积层。
第三层:全连接层。
第四层:输出层。
图中原始的手写数字的图片是一张 28×28 的图片,并且是黑白的,所以图片的通道数是1,输入数据是 28×28×1 的数据,如果是彩色图片,图片的通道数就为 3。该网络结构是一个 4 层的卷积神经网络(计算神经网络层数的时候,有权值的才算是一层,池化层就不能单独算一层)(池化的计算是在卷积层中进行的)。对多张特征图求卷积,相当于是同时对多张特征图进行特征提取。
特征图数量越多说明卷积网络提取的特征数量越多,如果特征图数量设置得太少容易出现欠拟合,如果特征图数量设置得太多容易出现过拟合,所以需要设置为合适的数值。
















 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











