






理论依据
参考
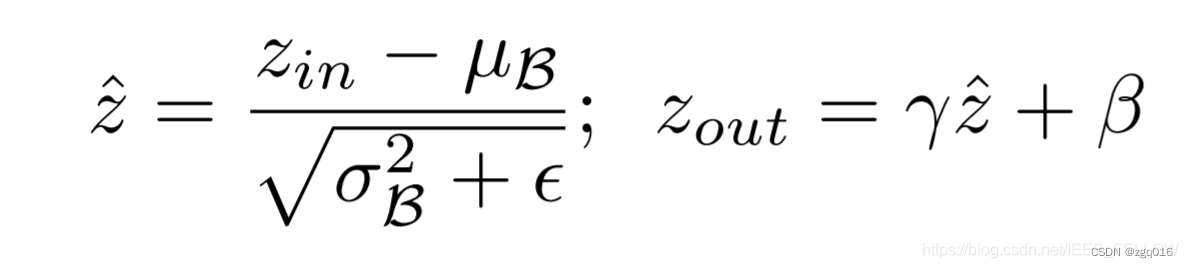 简单来说就是利用lameda的值来判断这个bn层的输出,如果输出太小,我们把他去掉后对模型的影响会比较小。
简单来说就是利用lameda的值来判断这个bn层的输出,如果输出太小,我们把他去掉后对模型的影响会比较小。
并通过在损失函数中引入正则化约束来稀疏化参数,稀疏训练后,我们可以得到稀疏分离的,靠近0的lameda直方图分布。选取合适的减枝参数。
实现以及调试
git clone https://github.com/midasklr/yolov5prune.git
这里把他切换到v6版本。
按照步骤执行
初始化训练
+ 不建议使用wandb工具 ,相关代码屏蔽
+ 由于`numpy`工具的更新 ,`np.int_`替换调`np.int`
+ 在log包中`__init__.py` `self.key`需要调整以适应与后面稀疏训练的不同。初始训练不需要`,'sr'`,把他屏蔽调。对应`train.py`中的部分根据输入参数作出修改。
self.keys = ['train/box_loss', 'train/obj_loss', 'train/cls_loss', # train loss
'metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95', # metrics
'val/box_loss', 'val/obj_loss', 'val/cls_loss', # val loss
'x/lr0', 'x/lr1', 'x/lr2','sr'] # params ,'sr'
+ 训练之前可能需要准备数据集。如果是VOC格式的数据。需要修改label加载程序。自行查找。如果不行,请删除data文件夹中的.cache文件再次训练,或者检查自定义数据集生成问题。
def img2label_paths(img_paths):
# Define label paths as a function of image paths
sa, sb = os.sep + 'JPEGImages' + os.sep, os.sep + 'labels' + os.sep # /images/, /labels/ substrings
return [sb.join(x.rsplit(sa, 1)).rsplit('.', 1)[0] + '.txt' for x in img_paths]
初始化训练后模型yaml文件中backbone可能会发生变化,可能是程序中对yaml文件进行了更新。这将影响到后面的模型减枝操作。
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
稀疏训练
具体操作便是在反向传播
# Backward
# scaler.scale(loss).backward()
loss.backward()
# # ============================= sparsity training ========================== #
srtmp = opt.sr*(1 - 0.9*epoch/epochs)
if opt.st:
ignore_bn_list = []
for k, m in model.named_modules():
if isinstance(m, Bottleneck):
if m.add:
ignore_bn_list.append(k.rsplit(".", 2)[0] + ".cv1.bn")
ignore_bn_list.append(k + '.cv1.bn')
ignore_bn_list.append(k + '.cv2.bn')
if isinstance(m, nn.BatchNorm2d) and (k not in ignore_bn_list):
m.weight.grad.data.add_(srtmp * torch.sign(m.weight.data)) # L1
m.bias.grad.data.add_(opt.sr*10 * torch.sign(m.bias.data)) # L1
# # ============================= sparsity training ========================== #
callbacks.run('on_fit_epoch_end', log_vals, bn_weights.numpy() ,epoch, best_fitness, fi)
将会传回记录权重,形成直方图供减枝参数分析。
减枝
- 获得剪枝参数
加载模型后,遍历模型中的各层。生成
model_list字典是当前模型中需要考虑剪枝的BN层以及权重,计算阈值,稍后将结合权重值进行操作
for i, layer in model.named_modules(): # 遍历层
# if isinstance(layer, nn.Conv2d):
# print("@Conv :",i,layer)
if isinstance(layer, Bottleneck): # 属于主干
if layer.add: # add 属性层 忽略
ignore_bn_list.append(i.rsplit(".",2)[0]+".cv1.bn") # 为什么这样命名 21
ignore_bn_list.append(i + '.cv1.bn')
ignore_bn_list.append(i + '.cv2.bn')
if isinstance(layer, torch.nn.BatchNorm2d): # BN层
if i not in ignore_bn_list:
model_list[i] = layer # 不属于add层 45
print(i, layer)
# bnw = layer.state_dict()['weight']
model_list = {k:v for k,v in model_list.items() if k not in ignore_bn_list}
收集各个BN层的权重,通过设计的百分比设计消剪阀值。
bn_weights = gather_bn_weights(model_list)
sorted_bn = torch.sort(bn_weights)[0] # 提取张量部分
.................
# model_copy = deepcopy(model)
thre_index = int(len(sorted_bn) * opt.percent)
thre = sorted_bn[thre_index]
定义剪枝模型。类似
C3Pruned等结构便是设计的剪枝结构。这个网络结构需要与模型的网络结构相对应,不然无法继续剪枝。
with open(cfg, encoding='ascii', errors='ignore') as f:
model_yamls = yaml.safe_load(f) # model dict
# # Define model
pruned_yaml["nc"] = model.model[-1].nc
pruned_yaml["depth_multiple"] = model_yamls["depth_multiple"]
pruned_yaml["width_multiple"] = model_yamls["width_multiple"]
pruned_yaml["anchors"] = model_yamls["anchors"]
anchors = model_yamls["anchors"]
pruned_yaml["backbone"] = [
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3Pruned, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3Pruned, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3Pruned, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3Pruned, [1024]],
[-1, 1, SPPFPruned, [1024, 5]], # 9
]
pruned_yaml["head"] = [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3Pruned, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3Pruned, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3Pruned, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3Pruned, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
与上面的操作类似,再次遍历模型,结合阈值筛选出需要剪枝的BN层,并放入maskbndict
maskbndict = {}
for bnname, bnlayer in model.named_modules():
if isinstance(bnlayer, nn.BatchNorm2d):
bn_module = bnlayer
mask = obtain_bn_mask(bn_module, thre) ###
if bnname in ignore_bn_list:
mask = torch.ones(bnlayer.weight.data.size()).cuda()
maskbndict[bnname] = mask
# print("mask:",mask)
remain_num += int(mask.sum())
bn_module.weight.data.mul_(mask)
bn_module.bias.data.mul_(mask)
# print("bn_module:", bn_module.bias)
print(f"|\t{bnname:<25}{'|':<10}{bn_module.weight.data.size()[0]:<20}{'|':<10}{int(mask.sum()):<20}|")
assert int(mask.sum()) > 0, "Current remaining channel must greater than 0!!! please set prune percent to lower thesh, or you can retrain a more sparse model..."
print("=" * 94)
- 获得剪枝后模型
重要函数或者类
pruned_model = ModelPruned(maskbndict=maskbndict, cfg=pruned_yaml, ch=3).cuda()
通过parse_pruned_model函数实现了剪枝后的模型。下段代码中通过for循环实现了上述提到的pruned_yaml模型。m为层的类型,args是模型参数,f是from,n是number。循环中通过判断m类型完成不同层的实现。如果定义的模型和训练的模型不对应就会产生在maskbndict字典中找不到对key的错误。在后续也会发生前后模型的差异错误。assert pruned_model_state.keys() == modelstate.keys()
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except NameError:
pass
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
named_m_base = "model.{}".format(i)
if m in [Conv,Focus]:
if m==Focus:
named_m_base = named_m_base + '.conv'
named_m_bn = named_m_base + ".bn"
bnc = int(maskbndict[named_m_bn].sum())
c1, c2 = ch[f], bnc
args = [c1, c2, *args[1:]]
layertmp = named_m_bn
if i>0:
from_to_map[layertmp] = fromlayer[f]
fromlayer.append(named_m_bn)
elif m in [C3Pruned]:
...........
- 微调
pruned_model.pt是剪后的模型,一般来说,剪刀后,模型精度会受到影响。利用finetune_pruned.py再训练即可快速收敛。 - 模型导出
参考export.py















 244
244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









