







前言
目标检测是计算机视觉领域老生常谈的任务,也是机器人感知理解世界的基础。所采用的方法从最初的图像处理阶段,到成熟运用的Yolo等框架,再到目前的多模态大模型,方法在不断地创新,效果也在逐渐提升。对于开放词汇或者是通用检测任务,顾名思义,在场景当中存在一些新物体,这些物体模型训练过程中没有出现过,整个任务的核心是面向现实世界的问题解决,近两年针对开放数据的检测研究有很多,较突出的如Glee、YoloWorld等。目前这些能否满足实际场景的需求呢,答案肯定是还不能,不过方法值得学习借鉴。

提到万物识别,不得不提到百度识图,想必多数人都用过,主要通过拍照上传得到我们想要识别的结果,(如左上图)针对日常生活常见的物品,百度识图的能力还是不错的,不过针对一些不常见的物体如工业零部件(如上中图),经过识别得到的结果(右上图)就差强人意。这样的结果倒也是意料之中。
方法
对于开放词汇的研究,首先要说的是之前博客自动化图像标注是否可靠?人人可尝试的方案中提到的GLEE。GLEE可以在开放世界场景中完成任意物体的检测、分割、跟踪、接地和识别,以完成各种物体感知任务,主要是通过对来自不同基准的500多万张图像进行广泛的训练,以及集成大量的自动标注数据,增强其泛化化能力。此外,GLEE能够被集成到大型语言模型中,作为基础模型为多模态任务提供通用的对象级信息。
1)、YOLO-World
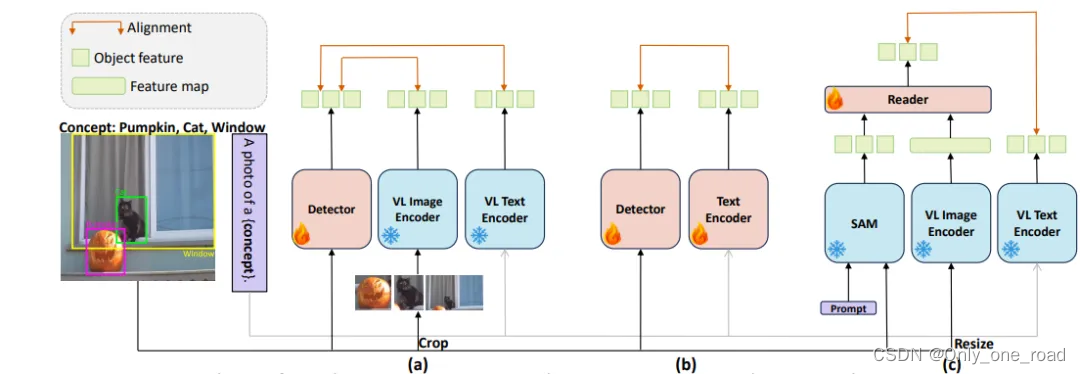
YOLO-World,通过视觉语言建模和在大型数据集上的预训练,将YOLO与开集检测能力相结合。主要是通过一种新的可重参化的视觉语言路径聚合网络(RepVL-PAN)和区域文本对比损失,以促进视觉和语言信息之间的交互。论文方法在以零样本方式检测广泛范围的物体时表现出色,且效率高,在LVIS上达到35.4 AP的同时,还能保持52.0 FPS的速度。
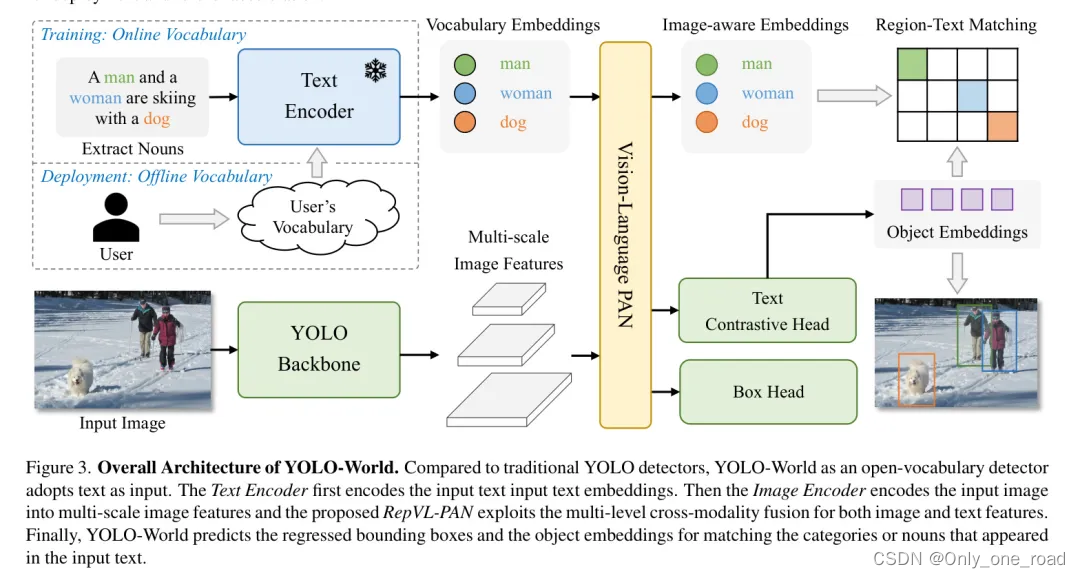
YOLO-World的整体架构如图所示,它由YOLO检测器、文本编码器以及可重参化的视觉-语言路径聚合网络(RepVL-PAN组成)。在给定输入文本的情况下,YOLO-World中的文本编码器将文本编码为文本嵌入。YOLO检测器中的图像编码器从输入图像中提取多尺度特征。然后利用RepVL-PAN通过利用图像特征与文本嵌入之间的跨模态融合来增强文本和图像的表现。
2)、DETECT EVERY THING WITH FEW EXAMPLES
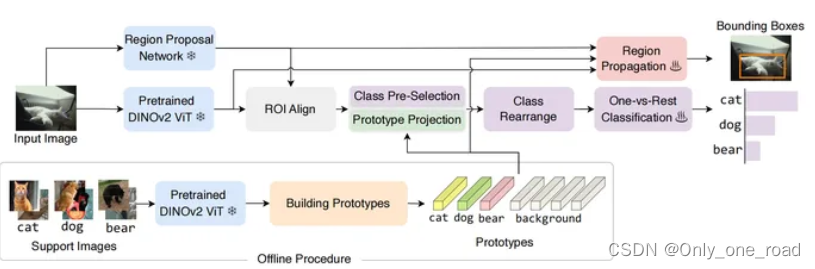
DE-ViT,是一种不需要微调的少样本物体检测器。主要将多类别分类转化为多个二元分类,对所有类别进行分类而无需微调,并且在冻结的DINOv2上提出了一个新的传播定位机制。
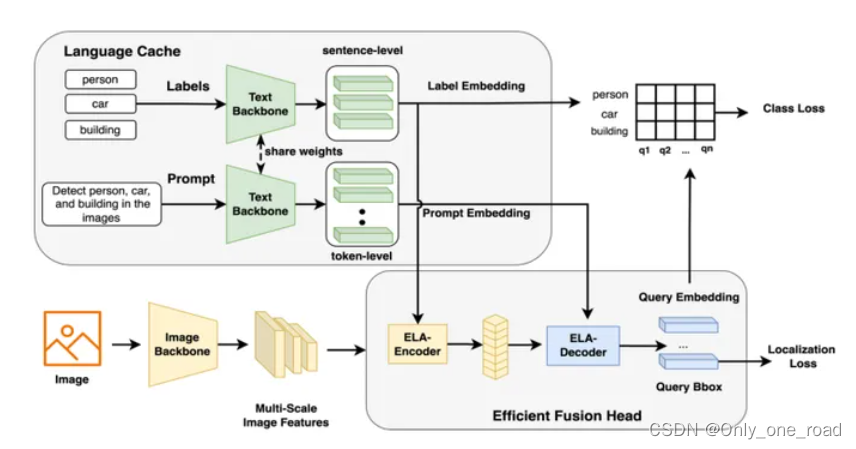
3)、OmDet-Turbo
基于Transformer的实时开放词汇目标检测模型,其中包括创新的Efficient Fusion Head (EFH)模块,旨在缓解OmDet和Grounding-DINO中观察到的瓶颈。OmDet-Turbo-Base 在应用 TensorRT 和语言缓存技术的情况下实现了 100.2 帧/秒 (FPS)。值得注意的是,在COCO和LVIS数据集上的零样本场景中,OmDet-Turbo的性能水平几乎与当前最先进的监督模型相当。此外,它还在 ODinW 和 OVDEval 上建立了新的最先进的基准测试,分别拥有 30.1 的 AP 和 26.86 的 NMS-AP。OmDet-Turbo在工业应用中的实用性体现在其在基准数据集上的卓越性能和卓越的推理速度,使其成为实时目标检测任务的有力选择。
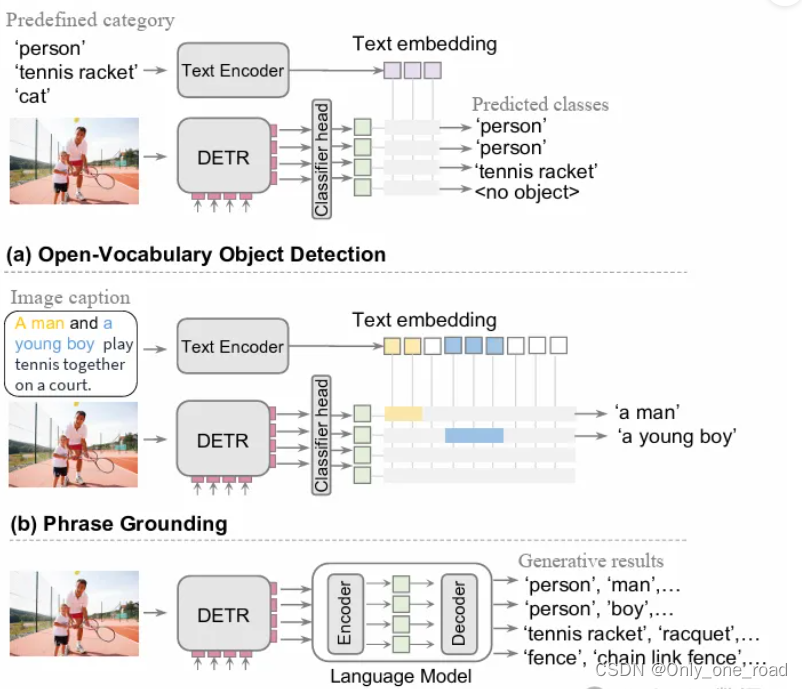
4)、GenerateU
将物体检测形式化为生成问题,并提出名为GenerateU的简单框架,可以以自由形式检测密集物体并生成它们的名称。使用Deformable DETR作为区域提议生成器,配合一个语言模型将视觉 区域翻译为物体名称。为了评估自由形式物体检测任务,引入了一个评估方法,旨在定量衡量生成结果的性能。第一个关键步骤是从图像中提取准确的物体区域, 为此开发了一个开放世界的物体检测器。Deformable DETR或 原始的DETR采用匈牙利匹配来学习从预测查询到地面 真实对象的映射,然后通过组合分类损失和边界框回 归损失来训练匹配的物体查询以回归到其相应的地面 真实对象。在开放集问题的背景下,不依赖于物 体类别信息。相反,采用一种开放世界检测方法, 即类别不可知的物体检测器,其中匹配的查询仅被分 类为前景或背景。因此,检测过程涉及三种损失:二 元交叉熵、广义IoU和L1回归损失。
5)、RegionSpot
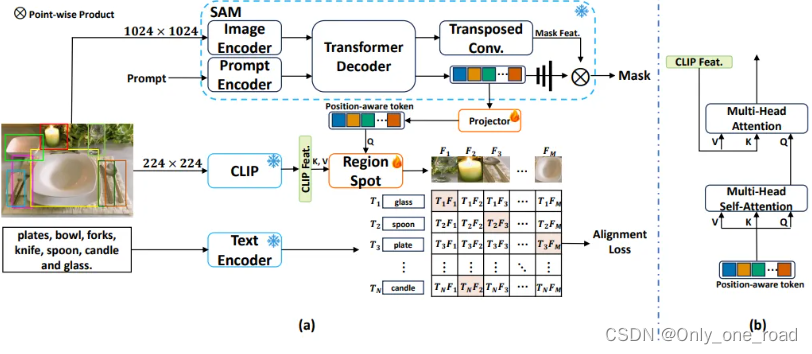
RegionSpot,其核心思想是将来自局部基础模型的位置感知信息与来自ViL模型的语义信息相结合。这种方法的优势在于能够充分利用预训练的知识,同时最小化训练的开销。此外,文中还介绍了一种轻量级的基于注意力机制的知识集成模块,以优化模型性能。
其中使用冻结基础模型的区域文本对齐,重点关注下如何获取位置感知标记和图像级语义特征,并通过交叉注意力机制进行区域文本对齐。区域级别的位置感知标记:使用手动标注的目标边界框来表示图像的兴趣区域。对于这些区域,文中是使用SAM模型来提取位置感知标记。这些标记通过一个Transformer解码器生成,这个过程有点像DETR的架构,生成一个称为“位置感知”的标记,它包含了有关目标的重要信息,包括其纹理和位置。图像级语义特征图:将输入图像调整到所需的尺寸,然后输入到 ViL 模型中,获得图像级语义特征图。关联位置感知标记和语义特征图:RegionSpot 中使用了交叉注意力机制来建立区域级别的位置感知标记和图像级语义特征图之间的联系。
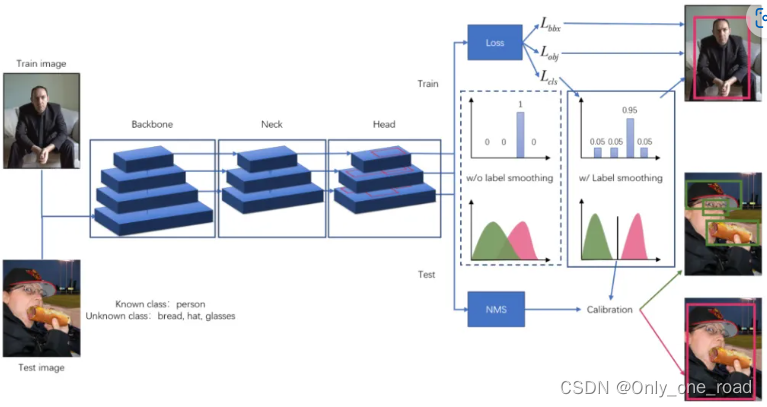
6)、YOLOOC
YOLOOC是基于YOLO架构但适用于开集设置的新型OWOD检测器。通过引入标签平滑技术,以防止检测器过于自信地将新类别映射到已知类别,从实实现发现新类别。基于单阶段的检测器架构。该架构包含三个模块:骨干网、颈部和头部。骨干网首先提取输入图像的分层特征图。颈部收集并融合来自不同特征级别的特征图。使用一键式标签训练的模型往往对学到的特征赋予较高的权重。这些权重使得模型对与已知类别共享相似特征的新类别产生激活,并将它们自信地映射到已知类别。可以使用阈值来区分已知类别和新兴类别,从而发现新兴类别。
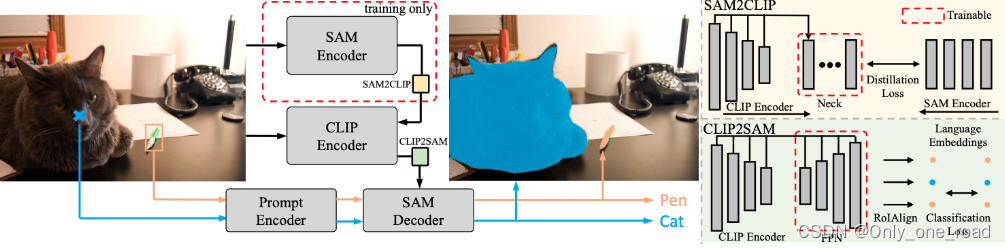
7)、Open-VocabularySAM
Open-VocabularySAM,利用两个独特的知识转移模块:SAM2CLIP和CLIP2SAM。前者通过蒸馏和可学习的Transformer适配器将SAM的知识适应到CLIP中,而后者则将CLIP的知识转移给SAM,提升其识别能力。对各种数据集和检测器进行的大量实验表明,Open-Vocabulary SAM在分割和识别任务中的有效性,显著优于简单组合SAM和CLIP的朴素基线。此外,结合图像分类数据训练,可以分割和识别大约22,000个类别。
 8)、CoDA
8)、CoDA
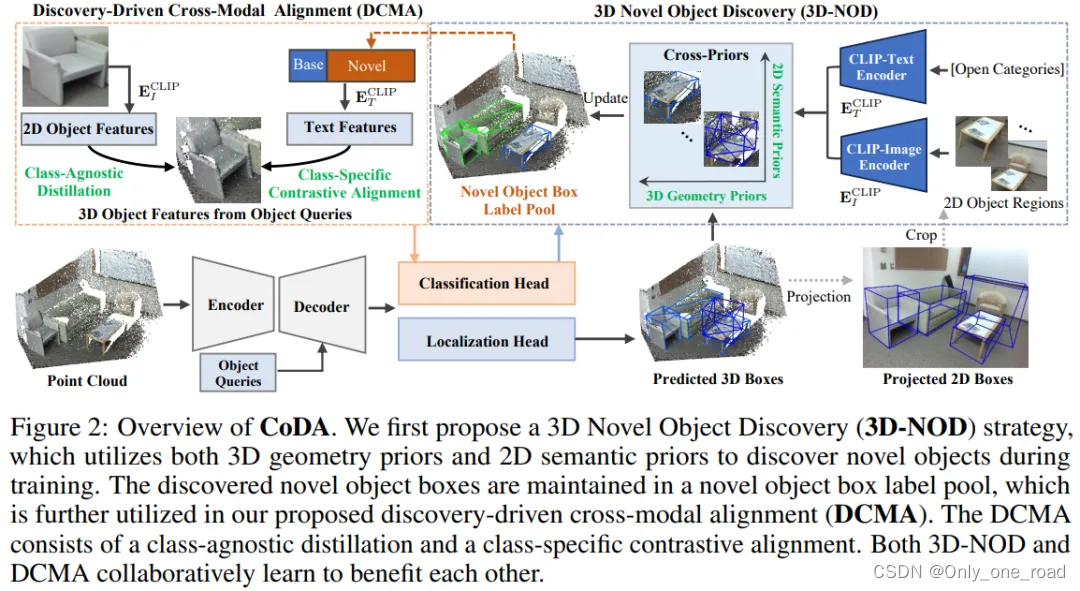
CoDA是开放词汇3D检测框架,通过设计协同式3D新物体发掘(3D Novel Object Discovery)与发掘驱动的跨模态对齐方法(Discovery-driven Cross-modal Alignment)解决了开放词汇3D目标检测中对新类别物体进行定位和分类问题。主要是结合3D Novel Object Discovery (3D-NOD)模块,通过利用3D几何先验和2D开放语义先验,实现了对新类别对象的定位,Discovery-Driven Cross-Modal Alignment (DCMA)模块,是基于3D-NOD发现的新物体,对3D点云、2D图像、文本之间进行跨模态对齐,实现对新类别对象的分类。
9)、OV-Uni3DETR:Towards Unified Open-Vocabulary 3D Object Detection via Cycle-Modality Propagation
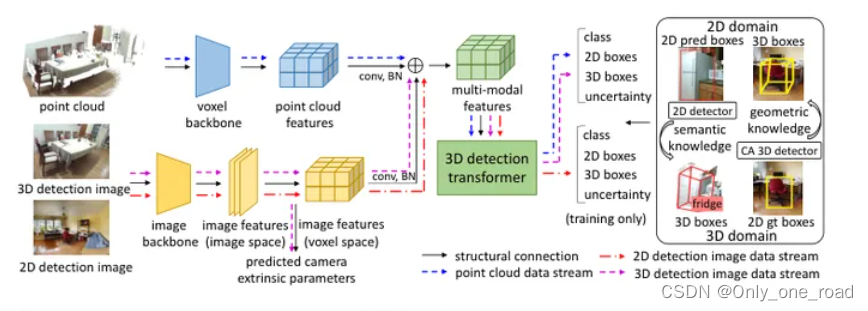
OV-Uni3DETR是一个面向通用开放词汇3D目标检测的多模态检测器论文提出了循环模态传播的概念,目的是在2D和3D模态之间传播知识,以支持上述功能。2D语义知识从大规模词汇学习中引导3D领域的新类发现,而3D几何知识则为2D检测图像提供定位监督。OV-Uni3DETR在各种3D检测任务上都取得了最新的性能,其平均性能比现有方法提高了6%以上。
10)、T-Rex
主要是通过visual prompt来解决counting问题。counting问题往往比较密集且物体不太好用文本描述,把counting问题转化为检测问题并通过visual prompt能更加高效地处理counting问题。T-Rex2则进一步把visual prompt和text prompt融合到一个模型里面,接受多种格式的输入,包括文本提示、视觉提示以及两者的组合,因此它可以通过在两种提示模式之间切换来处理不同的场景。

总结:
目前基于开放词汇的检测以及分割研究都有不错的进展,开源的开集数据种类丰富,能够满足多数的要求,但对于识别万物还是有些遥远。目前针对开集识别,在实际项目中采用基于检索的方法相对更稳定些,可以采用Groundino对物体时间框的检测,或者SAM模型对物体实现分割后得到物体的检测框,基于检测框选用较好的图像特征提取模型多特征提取,再进行图像检索。
此外,DINOv也是一个较好的思路,通过visual prompt来实现visual in-context learning,例如要检测一个新的物体或者某些难以描述的物体,只需要给模型几个样例,模型就可以在target image里面把想要的物体都检测出来,实测这种方法需要进一步训练。
最后放一个关于开集/通用检测分割的论文集合网址,值得收藏:开源集合
参考:
1、https://arxiv.org/abs/2312.09158
2、https//github.com/AILab-CVC/YOLO-World
4、https://arxiv.org/pdf/2403.10191.pdf

















 1918
1918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









