






点击蓝字
关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式

源码地址:https://github.com/icey-zhang/SuperYOLO
计算机视觉研究院专栏
Column of Computer Vision Institute
准确及时地从遥感图像中检测包含数十个像素的多尺度小物体仍然具有挑战性。大多数现有的解决方案主要设计复杂的深度神经网络来学习与背景分离的对象的强特征表示,这通常会导致沉重的计算负担。

PART/1
摘要
准确及时地从遥感图像中检测包含数十个像素的多尺度小物体仍然具有挑战性。大多数现有的解决方案主要设计复杂的深度神经网络来学习与背景分离的对象的强特征表示,这通常会导致沉重的计算负担。在今天分享中,提出了一种精确而快速的RSI(remote sensing images)目标检测方法,称为SuperYOLO,该方法融合多模态数据,并利用辅助超分辨率(SR)学习,同时考虑检测精度和计算成本,对多尺度对象进行高分辨率(HR)对象检测。
首先,我们利用对称紧凑多模态融合(MF)从各种数据中提取补充信息,以提高RSI中的小目标检测。此外,我们设计了一个简单灵活的SR分支来学习HR特征表示,该分支可以在低分辨率(LR)输入的大背景中区分小目标,从而进一步提高检测精度。此外,为了避免引入额外的计算,SR分支在推理阶段被丢弃,并且由于LR输入而减少了网络模型的计算。
实验结果表明,在广泛使用的VEDAI RS数据集上,SuperYOLO的准确率为75.09%(以mAP50计),比YOLOv5l、YOLOv5x和RS设计的YOLOR等SOTA大型模型高出10%以上。同时,SuperYOLO的参数大小和GFOLP分别比YOLOv5x小约18x和3.8x。与现有技术的模型相比,我们提出的模型显示出良好的精度-速度权衡。
PART/2
背景
与自然场景相比,遥感图像中的精确目标检测存在几个重大挑战。首先,标记样本的数量相对较少,这限制了DNN的训练以实现高检测精度。其次,RSI中对象的大小要小得多,相对于复杂而宽阔的背景,仅占几十个像素。此外,这些物体的规模是多样化的,有多种类别。
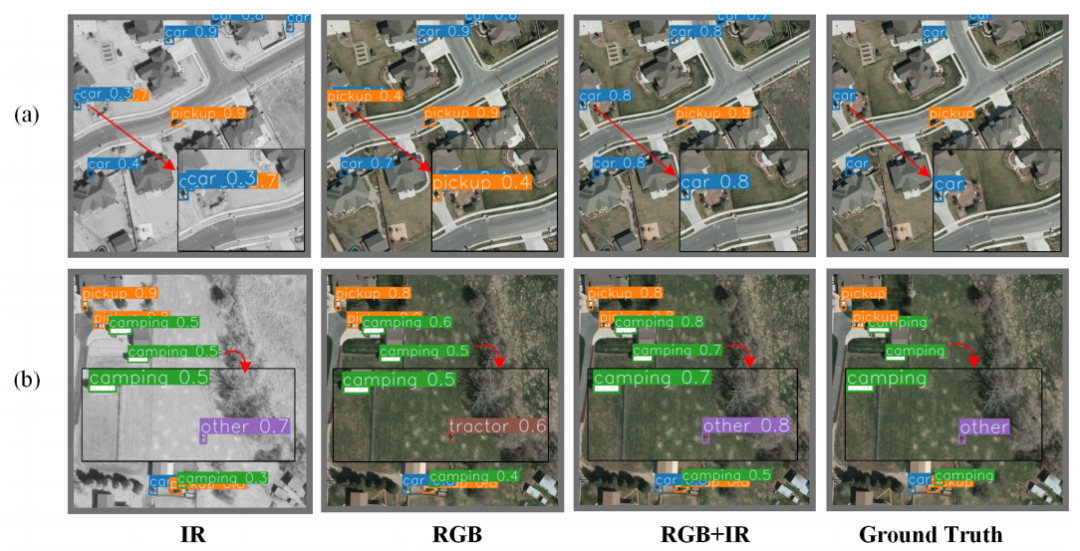
如上图(a)所示,物体车在广阔的区域内相当小。如图(b)所示,物体具有大规模变化,汽车的规模小于露营车的规模。目前,大多数物体检测技术都是独立的签署并应用于诸如RGB和红外(IR)的单一模态。因此,在物体探测方面,由于不同模态之间缺乏互补信息,其识别地球表面物体的能力仍然不足。随着成像技术的蓬勃发展,从多模态中收集的RSI变得可用,并提供了提高检测精度的机会。
例如,如上图所示,将两种不同的多模态(RGB和IR)融合可以有效地提高RSI中的检测精度。有时一种模态的分辨率较低,这需要提高分辨率以增强信息的技术。近年来,超分辨率技术在遥感领域显示出巨大的潜力。得益于卷积神经元网络(CNN)的蓬勃发展,遥感图像的分辨率实现了高纹理信息的解释。然而,由于CNN网络的计算成本高,SR网络在实时实际任务中的应用已成为当前研究的热点。
PART/3
相关技术
Super Resolution in Object Detection
在最近的文献中,可以通过多尺度特征学习、基于上下文的检测来提高小目标检测的性能。这些方法总是在不同尺度上增强网络的信息表示能力,而忽略了高分辨率的上下文信息保留。在预处理步骤中进行的SR已被证明在各种物体检测任务中是有效和高效的。Shermeyer等人通过RSI的多分辨率量化了其对卫星成像检测性能的影响。基于生成对抗性网络(GANs),Courtrai等人[Small object detection in remote sensing images based on super-resolution with auxiliary generative adversarial networks]利用SR生成HR图像,并将其输入检测器以提高其检测性能。Rabbi等人[Small object detection in remote sensing images with end-to-end edge enhanced gan and object detector network]利用拉普拉斯算子从输入图像中提取边缘,以增强重建HR图像的能力,从而提高其在对象定位和分类方面的性能。Hong等人[Vehicle detection in remote sensing images leveraging on simultaneous super-resolution]引入了一种循环一致的GAN结构作为SR网络,并修改了更快的R-CNN结构,以从SR网络生成的增强图像中检测车辆。在这些工作中,SR结构的采用有效地解决了小型物体的挑战。然而,与单个检测模型相比,引入了额外的计算,这归因于HR设计放大了输入图像的比例。
BASELINE ARCHITECTURE
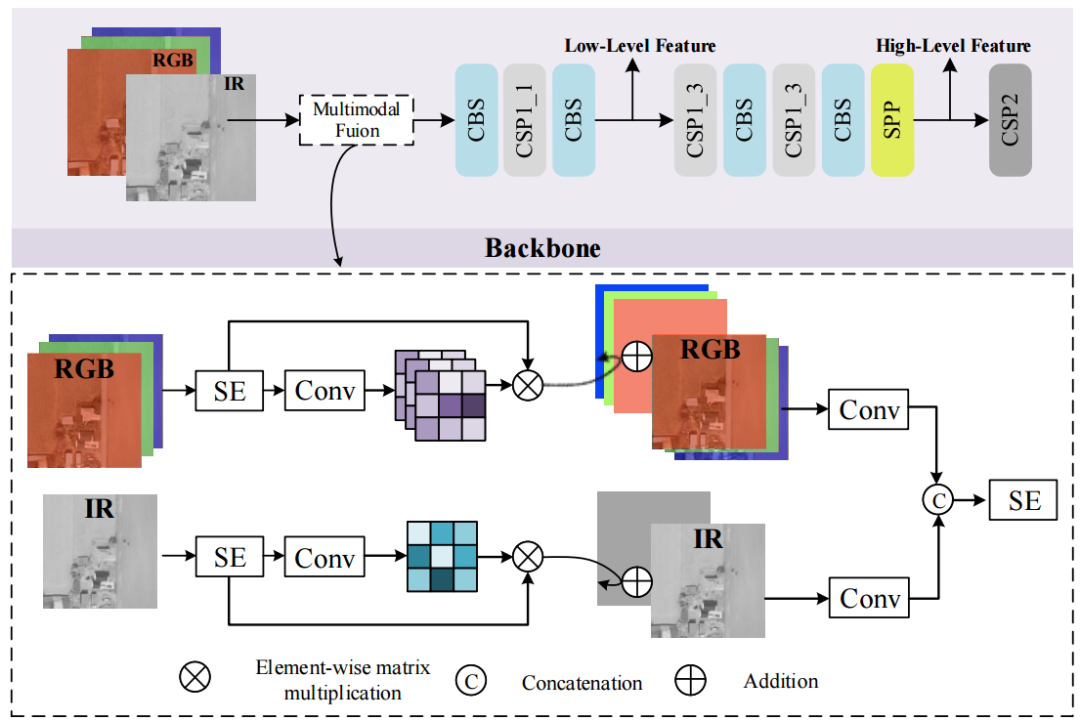
如上图所示,基线YOLOv5网络由两个主要组件组成:主干和头部(包括颈部)。主干被设计用于提取低级纹理和高级语义特征。接下来,这些提示特征被馈送到Head,以从上到下构建增强的特征金字塔网络来传递鲁棒的语义特征,并从下到上传播局部纹理和模式特征的强响应。这通过产生具有不同尺度的检测增强来解决对象的各种尺度问题。
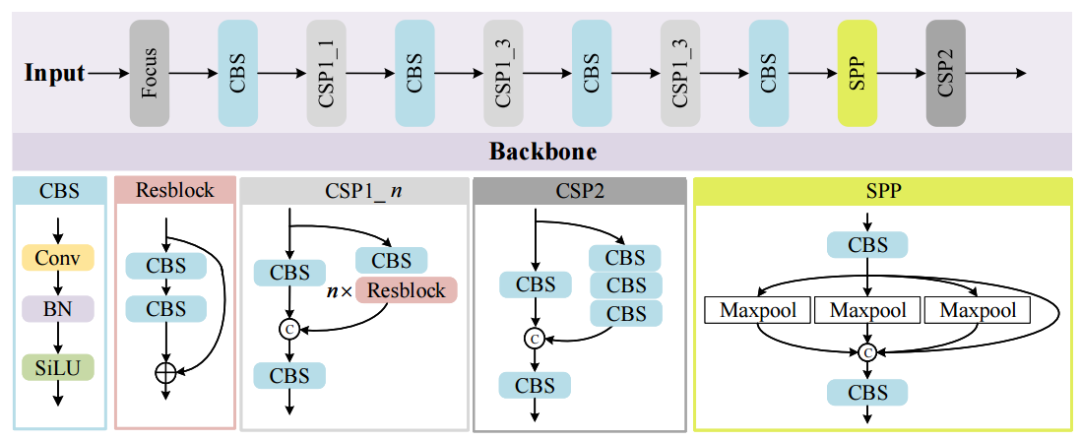
在上图中,CSPNet被用作提取特征信息的主干,由大量样本卷积批量归一化SiLu(CBS)组件和跨阶段部分(CSP)模块组成。CBS由卷积运算、批处理归一化运算和激活函数SiLu运算组成。CSP将前一层的特征图复制到两个分支中,然后通过1×1卷积将通道数减半,从而减少了计算量。关于特征图的两个副本,一个连接到阶段的末尾,另一个被发送到ResNet块或CBS块中作为输入。最后,将特征图的两个副本连接起来以组合特征,然后是CBS块。SPP(空间金字塔池)模块由具有不同内核大小的并行Maxpool层组成,用于提取多尺度深度特征。通过堆叠的CSP、CBS和SPP结构提取低级纹理和高级语义特征。
PART/4
新框架
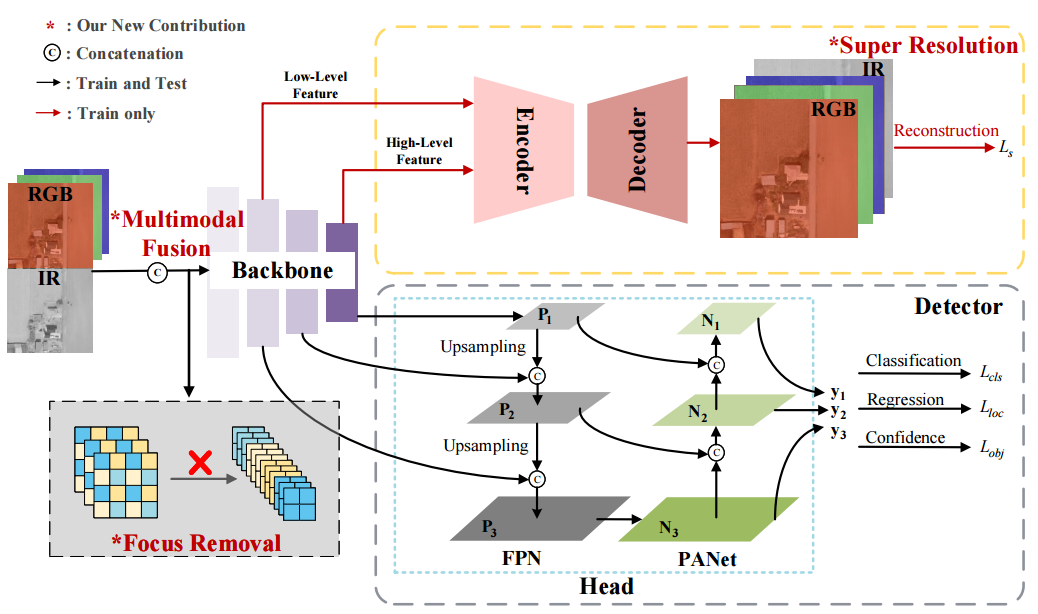
如框架图所示,介0绍了SuperYOLO网络架构的三个新贡献。首先,我们移除主干中的Focus模块,并将其替换为MF模块,以避免分辨率下降,从而避免精度下降。其次,我们探索了不同的融合方法,并选择计算高效的像素级融合来融合RGB和IR模式,以细化不同和互补的信息。最后,我们在训练阶段添加了一个辅助SR模块,该模块重建HR图像,以在空间维度上指导相关的骨干学习,从而维护HR信息。在推理阶段,SR分支被丢弃以避免引入额外的计算开销。
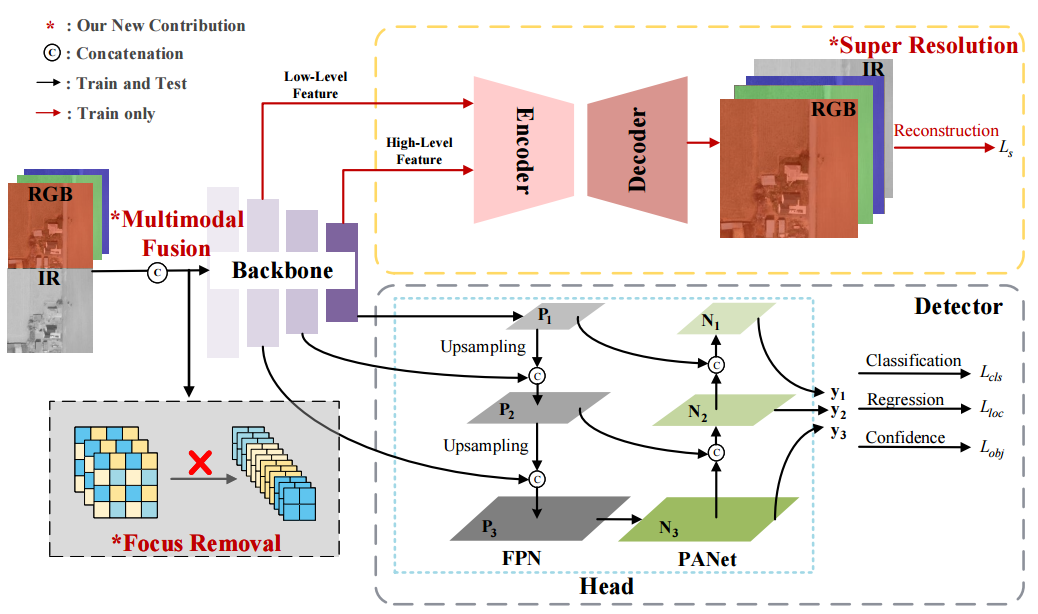
Multimodal Fusion
利用越多的信息来区分物体,就可以在物体检测中获得更好的性能。多模态融合是融合来自各种传感器的不同信息的有效途径。决策级融合、特征级融合和像素级融合是三种主流的融合方法,可以部署在网络的不同深度。由于决策级融合需要大量的计算,因此SuperYOLO中没有考虑这一点。我们提出了一种像素级多模式融合(MF)来从不同的模态中提取共享和特殊的信息。MF可以以对称和紧凑的方式双向组合多模式内部信息。如下图所示,对于像素级融合,我们首先将输入RGB图像和输入IR图像归一化为[0,1]的两个区间。
Super Resolution
具体地,SR结构可以被视为简单的编码解码器模型。我们分别选择主干的低级和高级特征来融合局部纹理和模式以及语义信息。如上图所示,我们分别选择第四和第九模块的结果作为低级和高级特征。编码器集成了主干中生成的低级功能和高级功能。
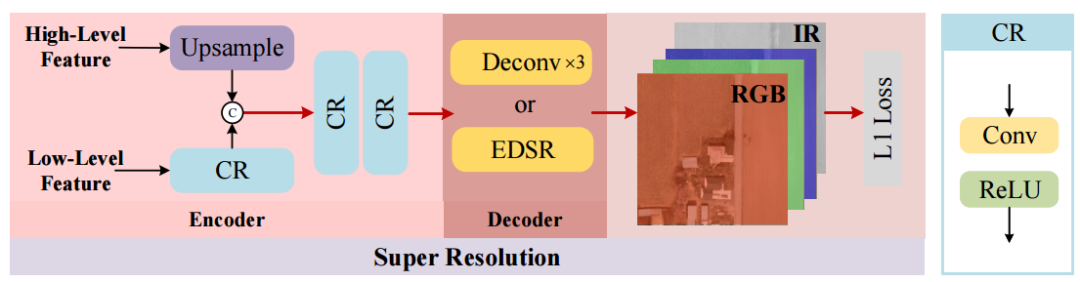
如上图所示,在编码器中,第一个CR模块是对低级特征进行的。对于高级特征,我们使用上采样操作来匹配低级特征的空间大小,然后我们使用级联操作和两个CR模块来合并低级和高级特征。CR模块包括卷积和ReLU。对于解码器,LR特征被放大到HR空间,其中SR模块的输出大小是输入图像的输出大小的两倍。如上图,解码器使用三个去卷积层来实现。SR引导空间维度的相关学习,并将其转移到主分支,从而提高对象检测的性能。此外,我们引入EDSR作为我们的编码器结构,以探索SR性能及其对检测性能的影响。
为了提供更直观可解释的描述,我们在下图中可视化了YOLOv5s、YOLOv5x和SuperYOLO的主干特征。将特征上采样到与输入图像相同的比例以进行比较。通过比较(c)、(f)和(i)的成对图像;(d) ,(g)和(j);(e) (h)和(k)在图6中,可以观察到,在SR的帮助下,SuperYOLO包含更清晰、更高分辨率的对象结构。最终,我们通过SR分支获得了高质量HR表示的丰收,并利用YOLOv5的头部来检测小对象。

PART/5
实验及可视化
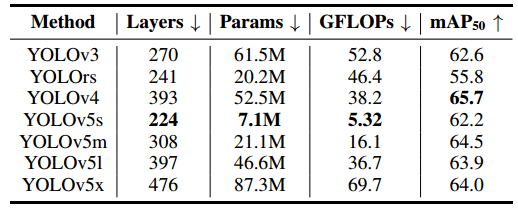
在上表中,根据层数、参数大小和GFLOP来评估不同基础框架的模型大小和推理能力。这些模型的检测性能是通过mAP50来测量的,即,在IOU(并集上的交集)=0.5时mAP的检测度量。尽管YOLOv4实现了最佳的检测性能,但它比YOLOV5多169层(393对224),其参数大小(params)是YOLOV5的7.4倍(52.5M对7.1M),其GFLOP是YOLOv5s的7.2倍(38.2对5.3)。关于YOLOv5s,尽管其mAP略低于YOLOv4和YOLOv5m,但其层数、参数大小和GFLOP远小于其他模型。因此,在实际应用中,在板上部署YOLOv5更容易实现实时性能。上述事实验证了YOLOv5s作为基线检测框架的合理性。
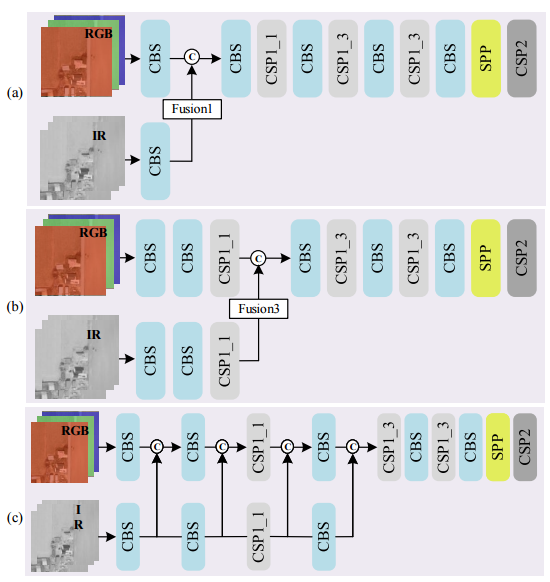
为了评估所设计的融合方法的影响,我们比较了YOLOv5 noFocus的五个融合结果,如上图所示。
比较YOLO方法和SuperYOLO的视觉检测结果如下图所示:


END


转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

往期推荐
🔗


















 2776
2776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











