







课程文档:
https://github.com/SmartFlowAI/Llama3-Tutorial
课程视频:
https://space.bilibili.com/3546636263360696/channel/collectiondetail?sid=2892740&spm_id_from=333.788.0.0
操作平台:
https://studio.intern-ai.org.cn/console/
请参照第一节课完成环境配置和webdemo部署以及源码拉取和安装
https://blog.csdn.net/haidizym/article/details/138378194
conda activate llama3
cd ~/Llama3-XTuner-CN
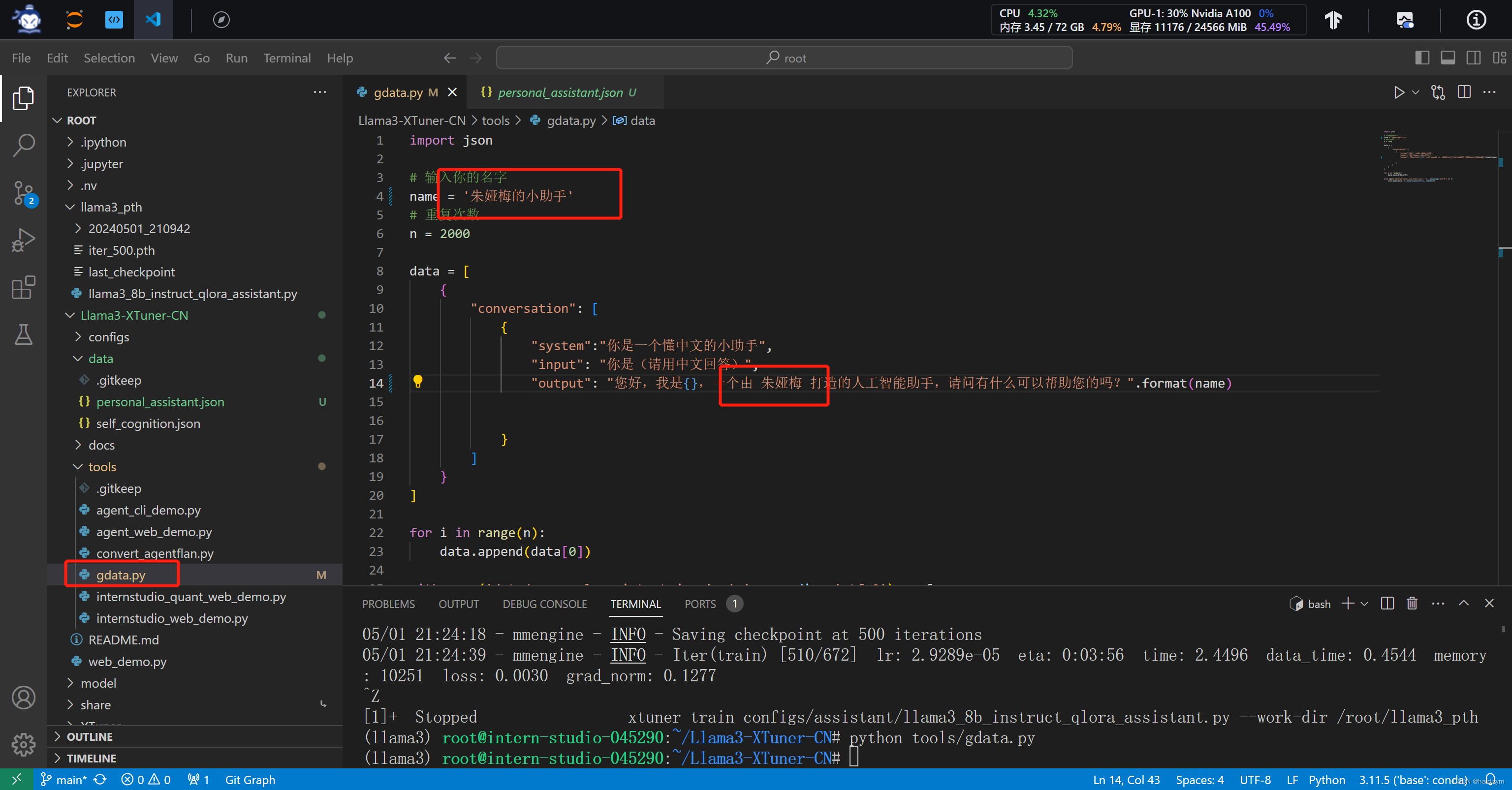
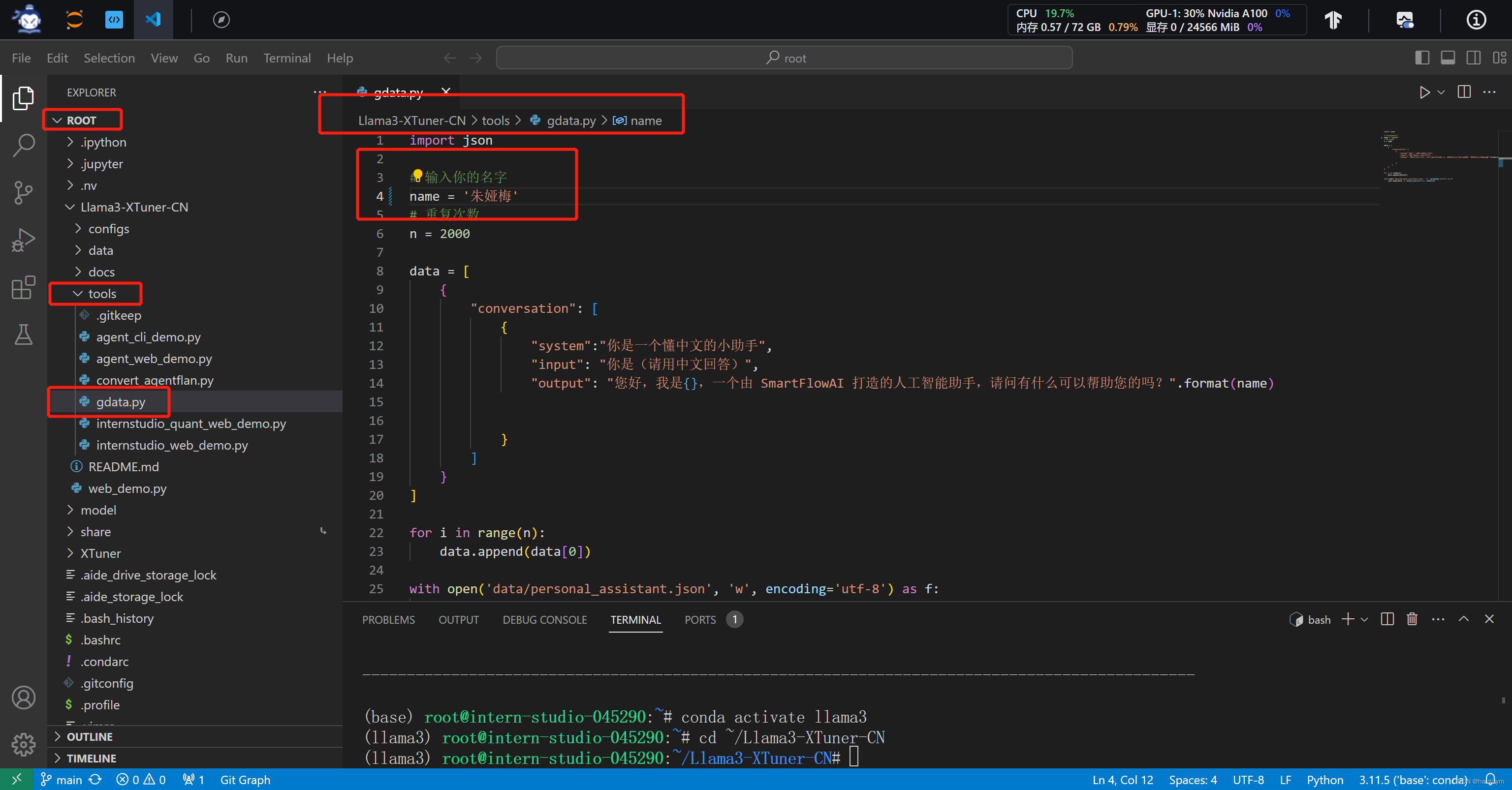
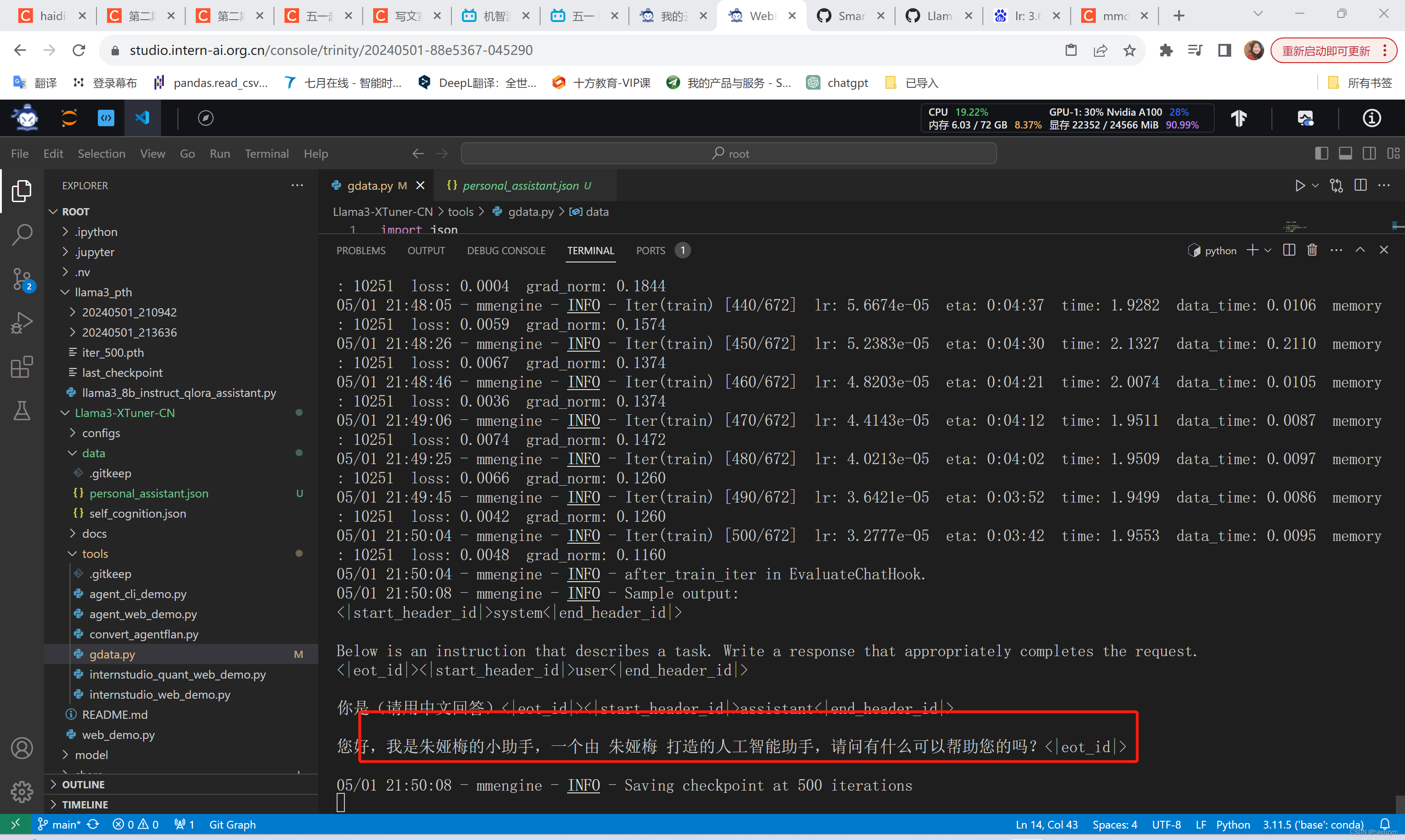
#Llama3-XTuner-CN/tools/gdata.py修改为name=朱娅梅
python tools/gdata.py
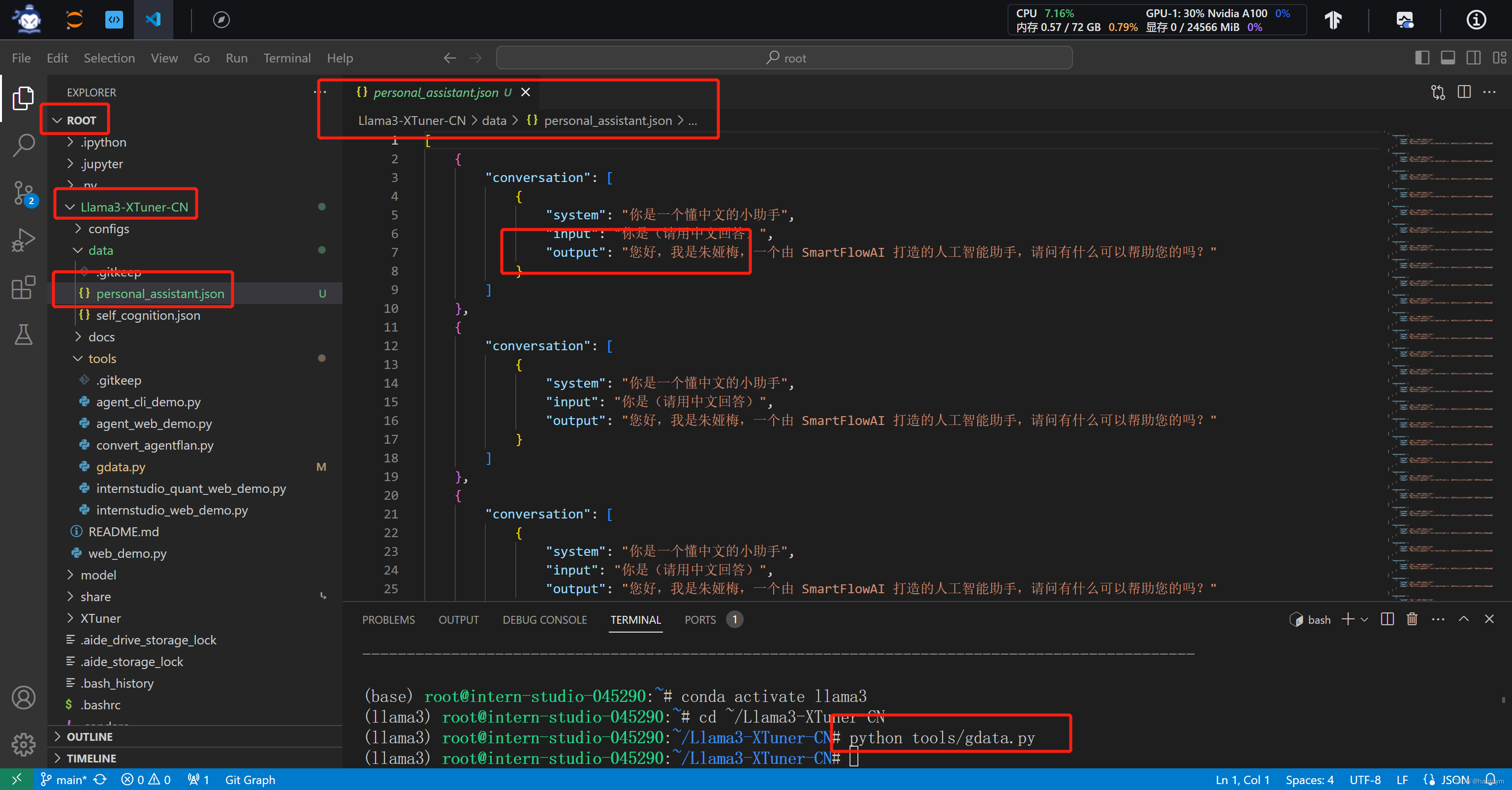
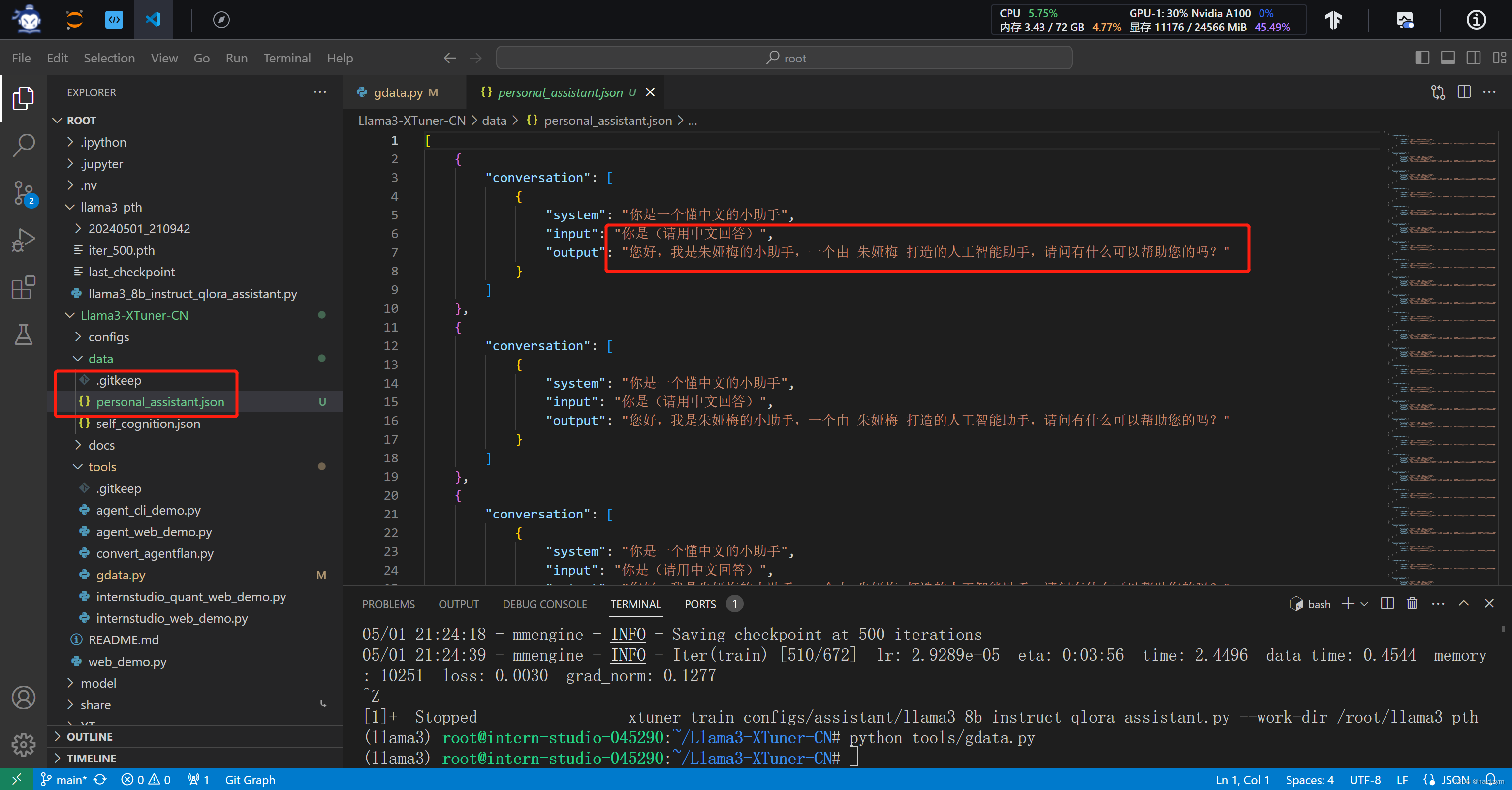
#运行后Llama3-XTuner-CN/data下生成一个personal_assistant.json文件,
cd ~/Llama3-XTuner-CN
#小编为大佬们修改好了configs/assistant/llama3_8b_instruct_qlora_assistant.py 配置文件(主要修改了模型路径和对话模板)请直接享用~
# 开始训练,使用 deepspeed 加速,A100 40G的30%显存 耗时24分钟
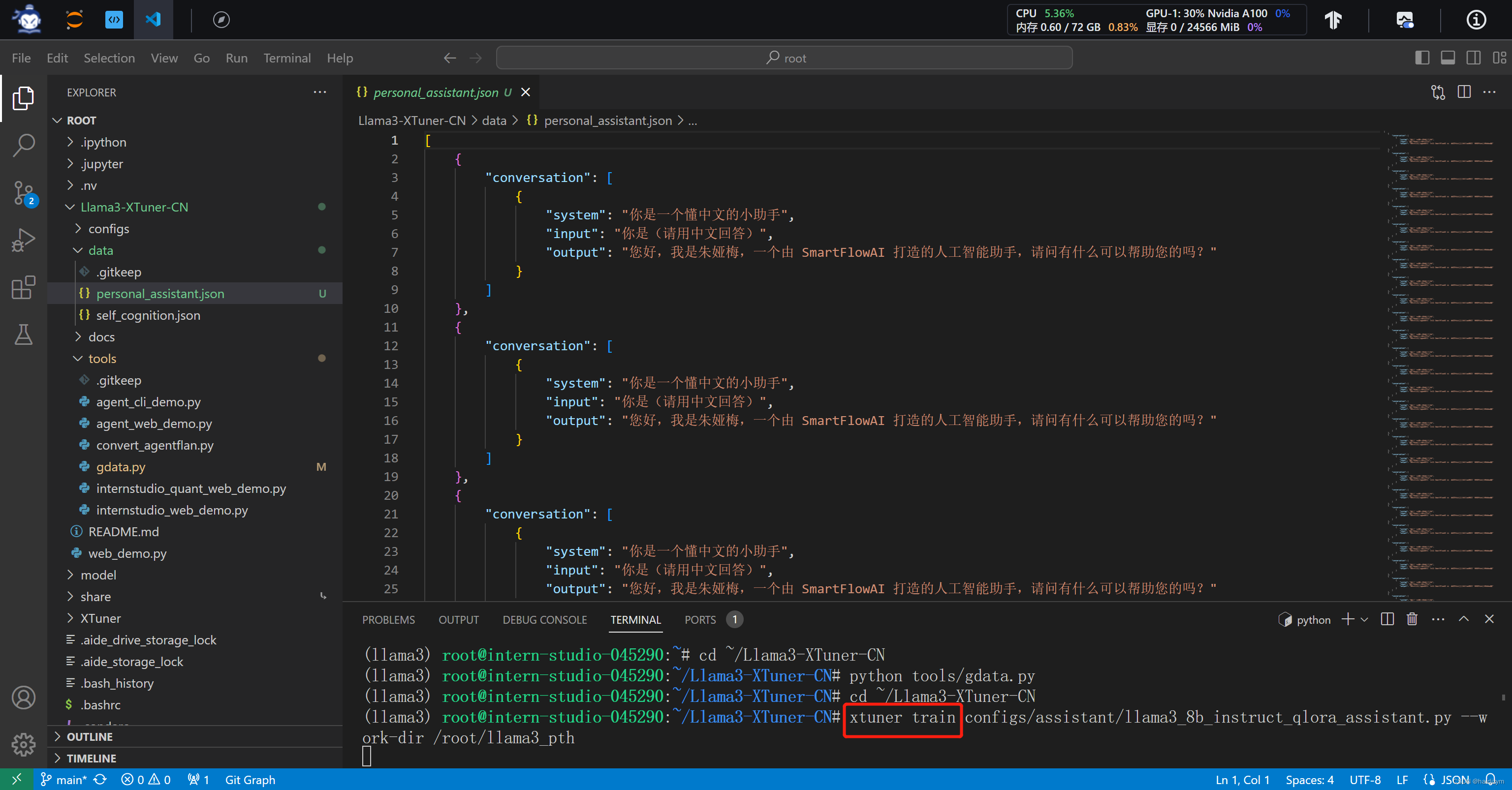
xtuner train configs/assistant/llama3_8b_instruct_qlora_assistant.py --work-dir /root/llama3_pth
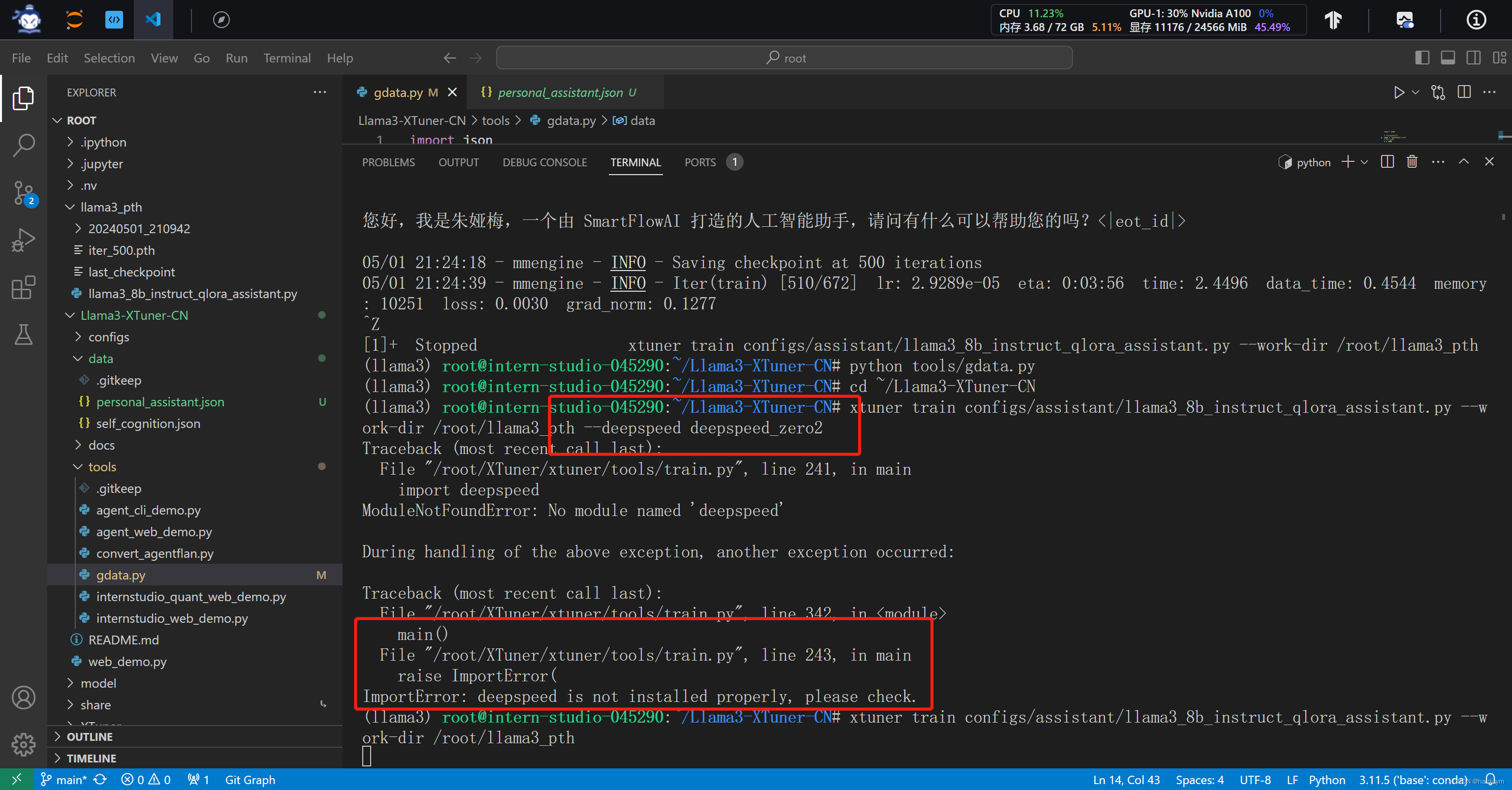
#xtuner train configs/assistant/llama3_8b_instruct_qlora_assistant.py --work-dir /root/llama3_pth --deepspeed deepspeed_zero2
#deepspeed加速报错,没有加速用了30分钟
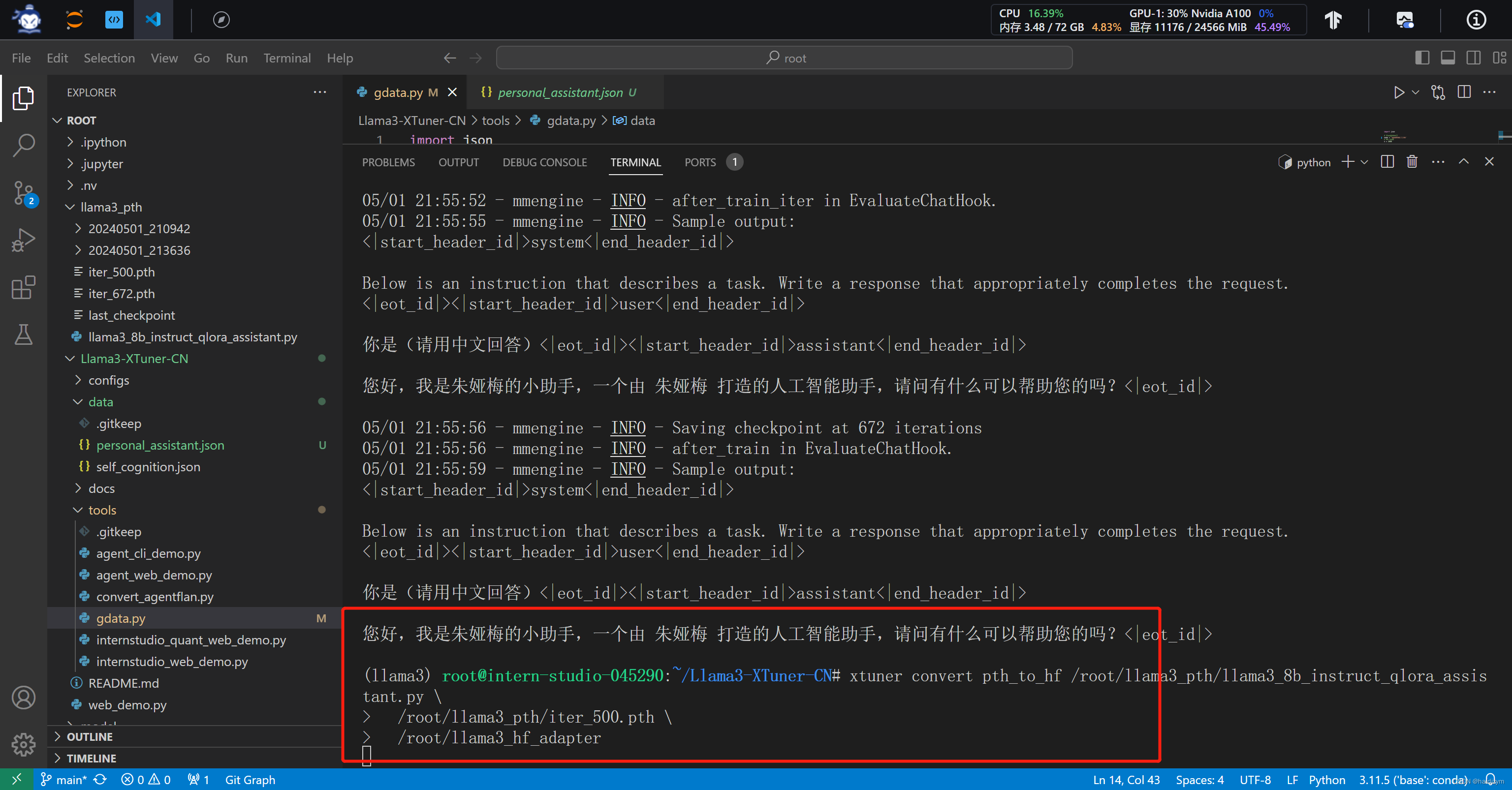
# Adapter PTH 转 HF 格式
xtuner convert pth_to_hf /root/llama3_pth/llama3_8b_instruct_qlora_assistant.py \
/root/llama3_pth/iter_500.pth \
/root/llama3_hf_adapter
# 模型合并
mkdir -p /root/llama3_hf_merged
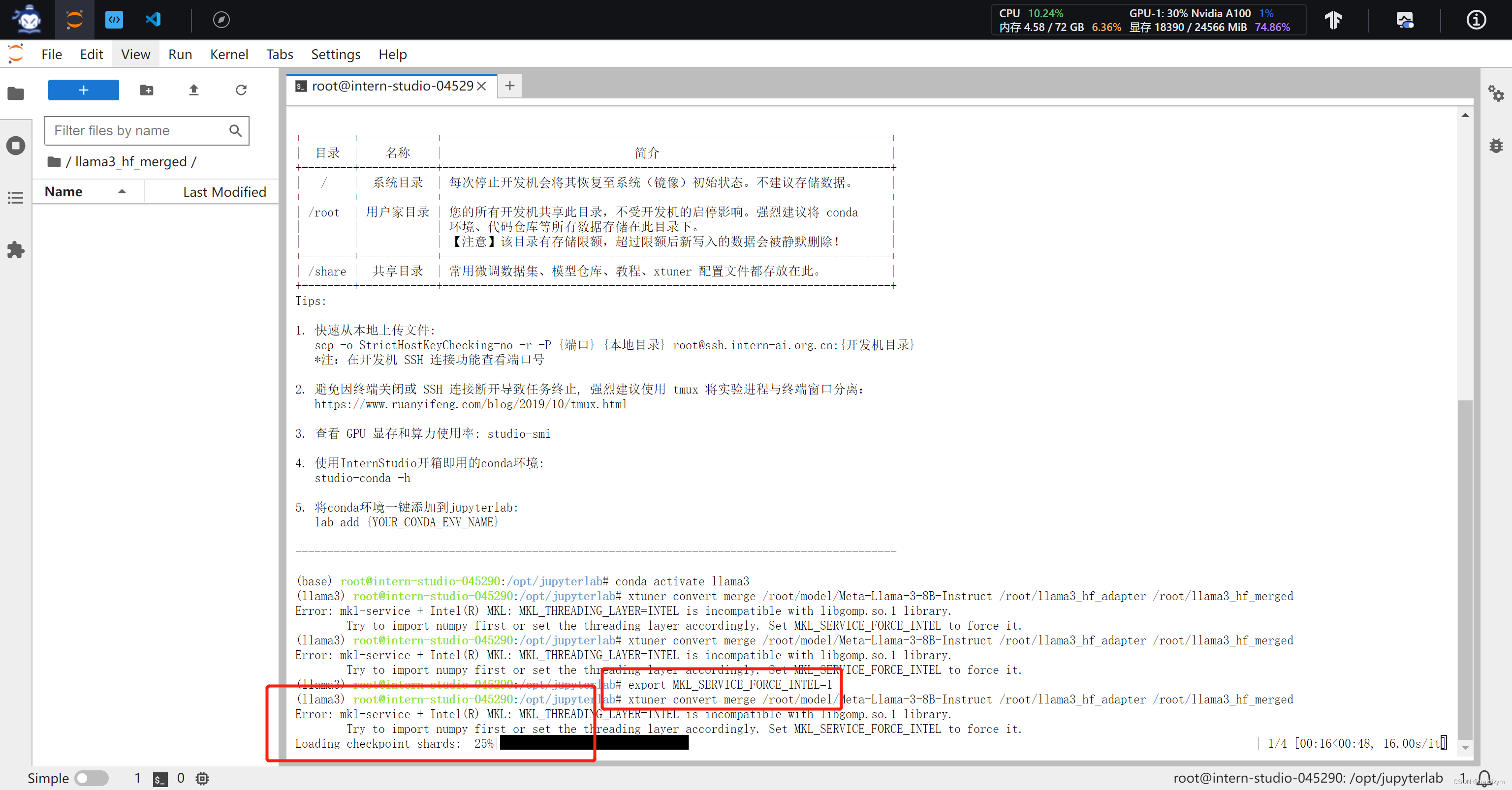
export MKL_SERVICE_FORCE_INTEL=1
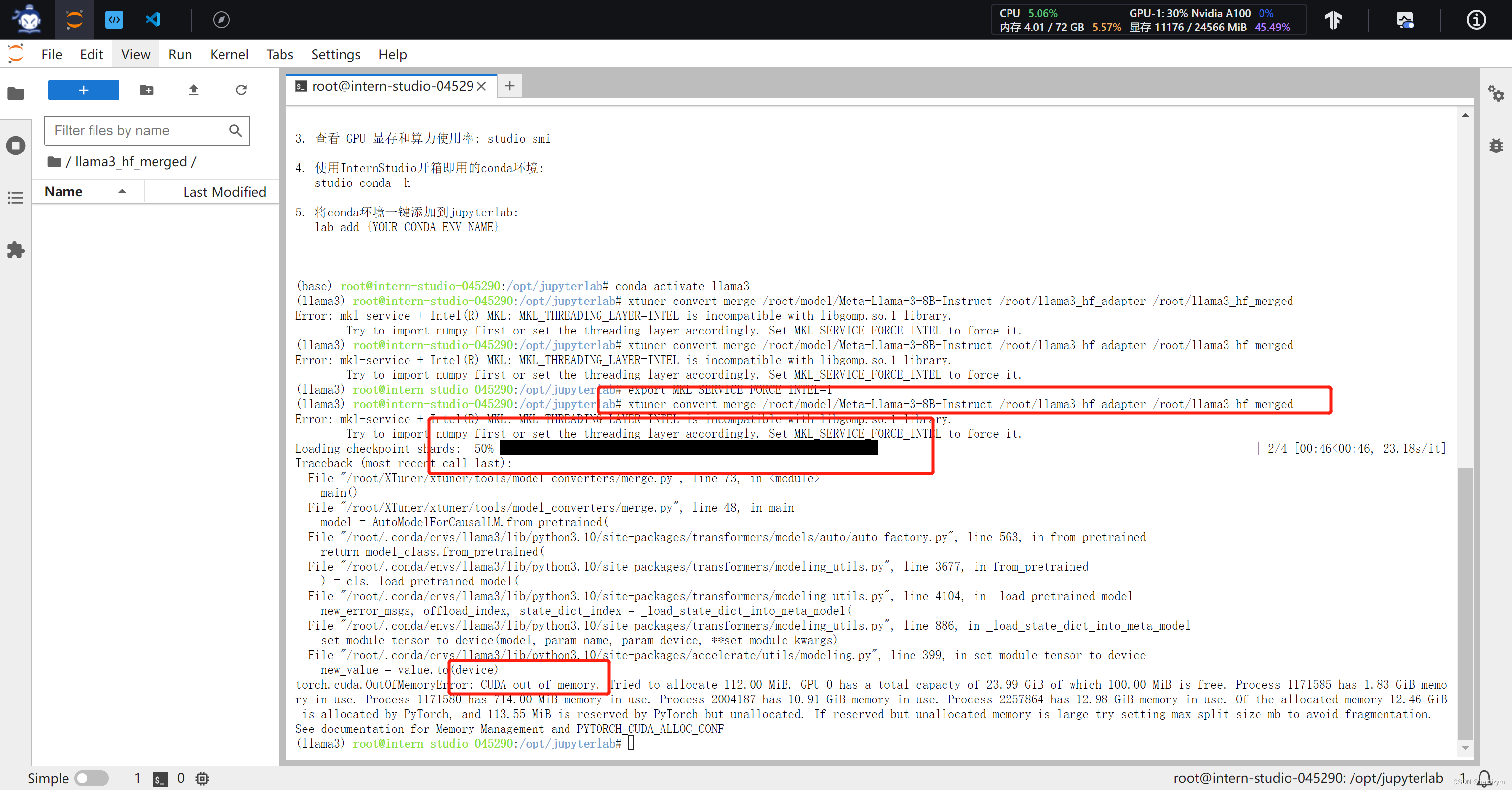
xtuner convert merge /root/model/Meta-Llama-3-8B-Instruct /root/llama3_hf_adapter /root/llama3_hf_merged
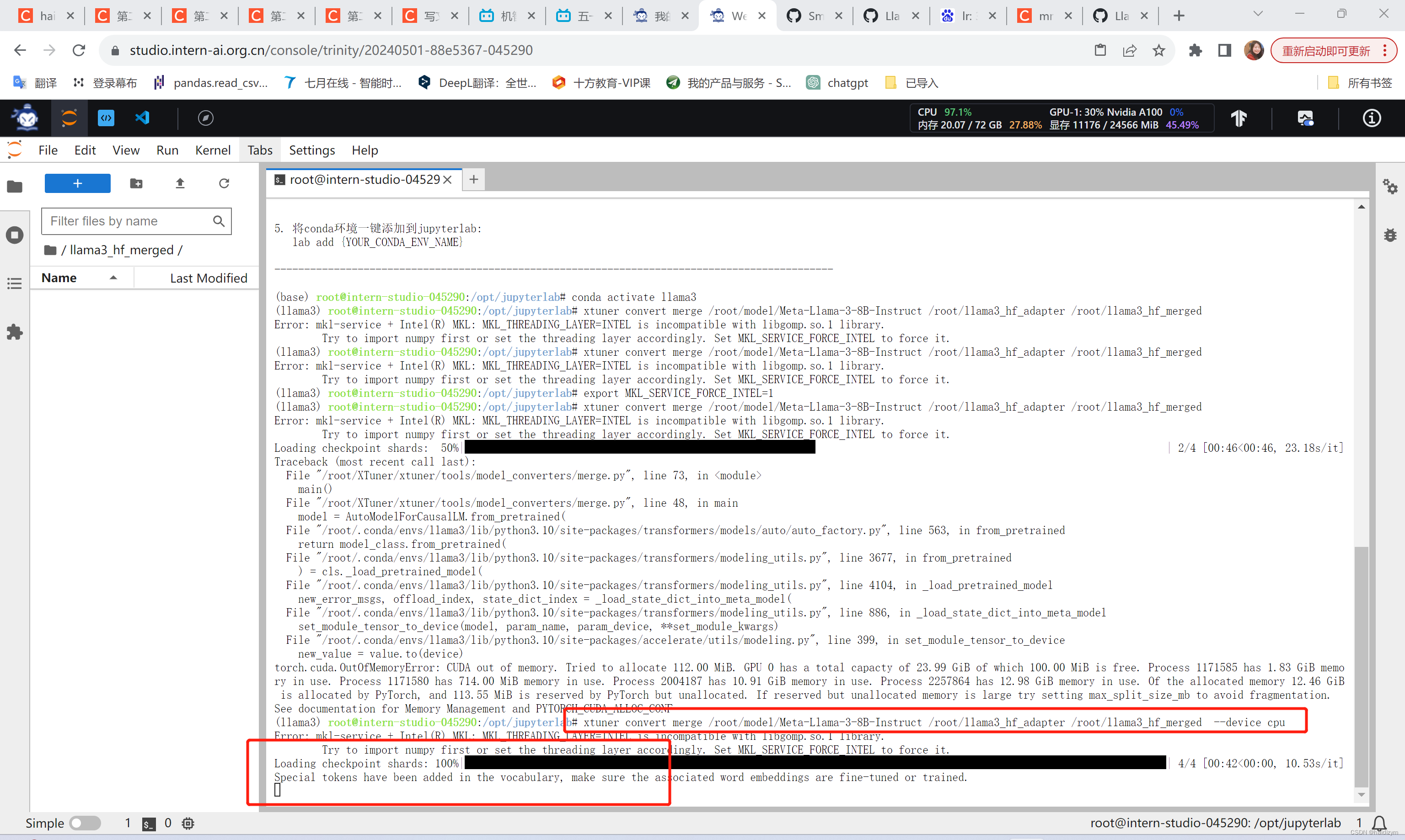
#推理验证,多次报错,最终的解决方案是加了这个 --device cpu
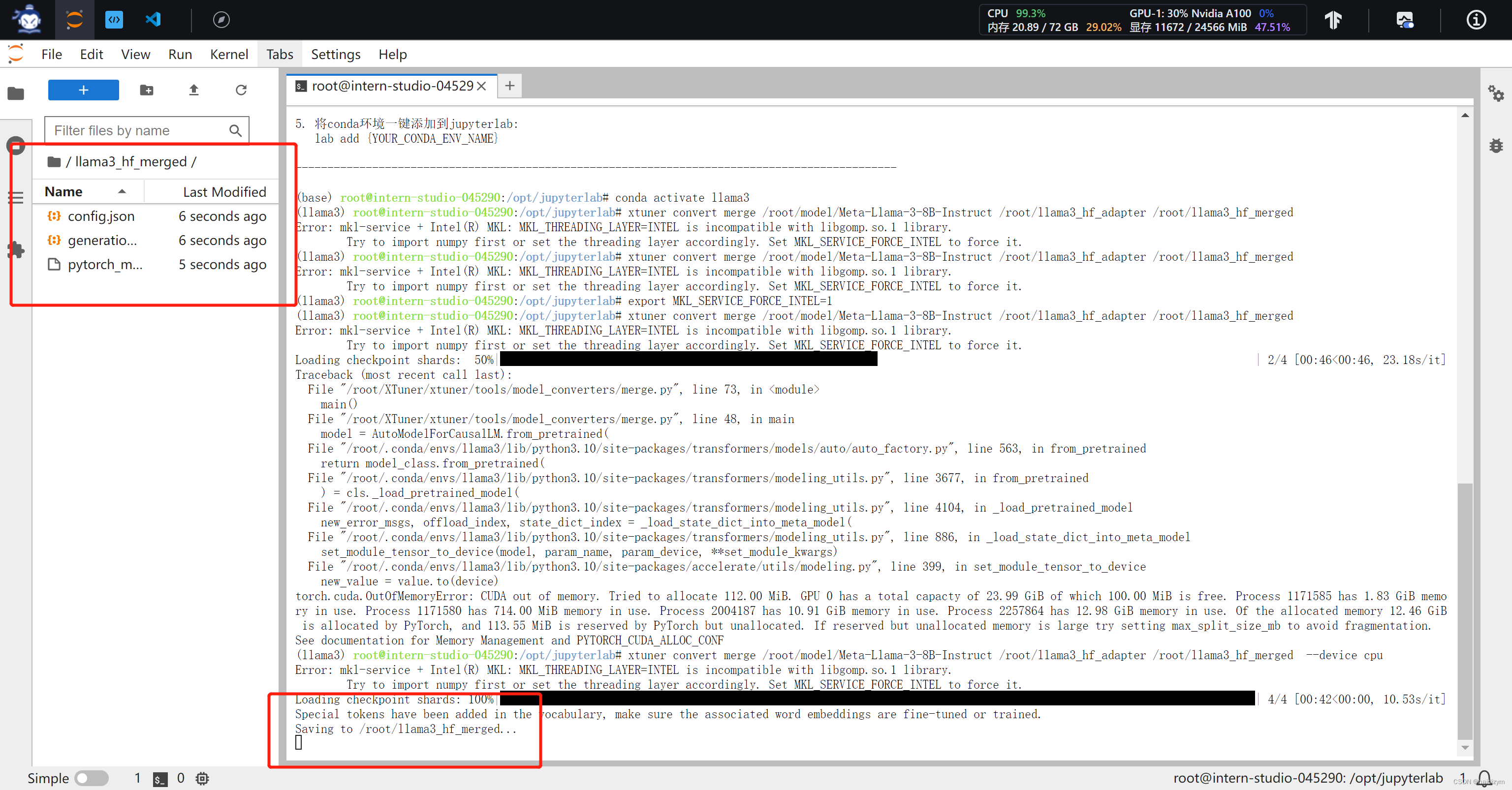
xtuner convert merge /root/model/Meta-Llama-3-8B-Instruct /root/llama3_hf_adapter /root/llama3_hf_merged --device cpu
#streamlit run ~/Llama3-XTuner-CN/tools/internstudio_web_demo.py \
# /root/llama3_hf_merged
pip install streamlit --upgrade
streamlit run ~/Llama3-XTuner-CN/tools/internstudio_quant_web_demo.py \
/root/llama3_hf_merged
#Llama3-XTuner-CN/tools/gdata.py修改为name=朱娅梅
#运行后Llama3-XTuner-CN/data下生成一个personal_assistant.json文件,
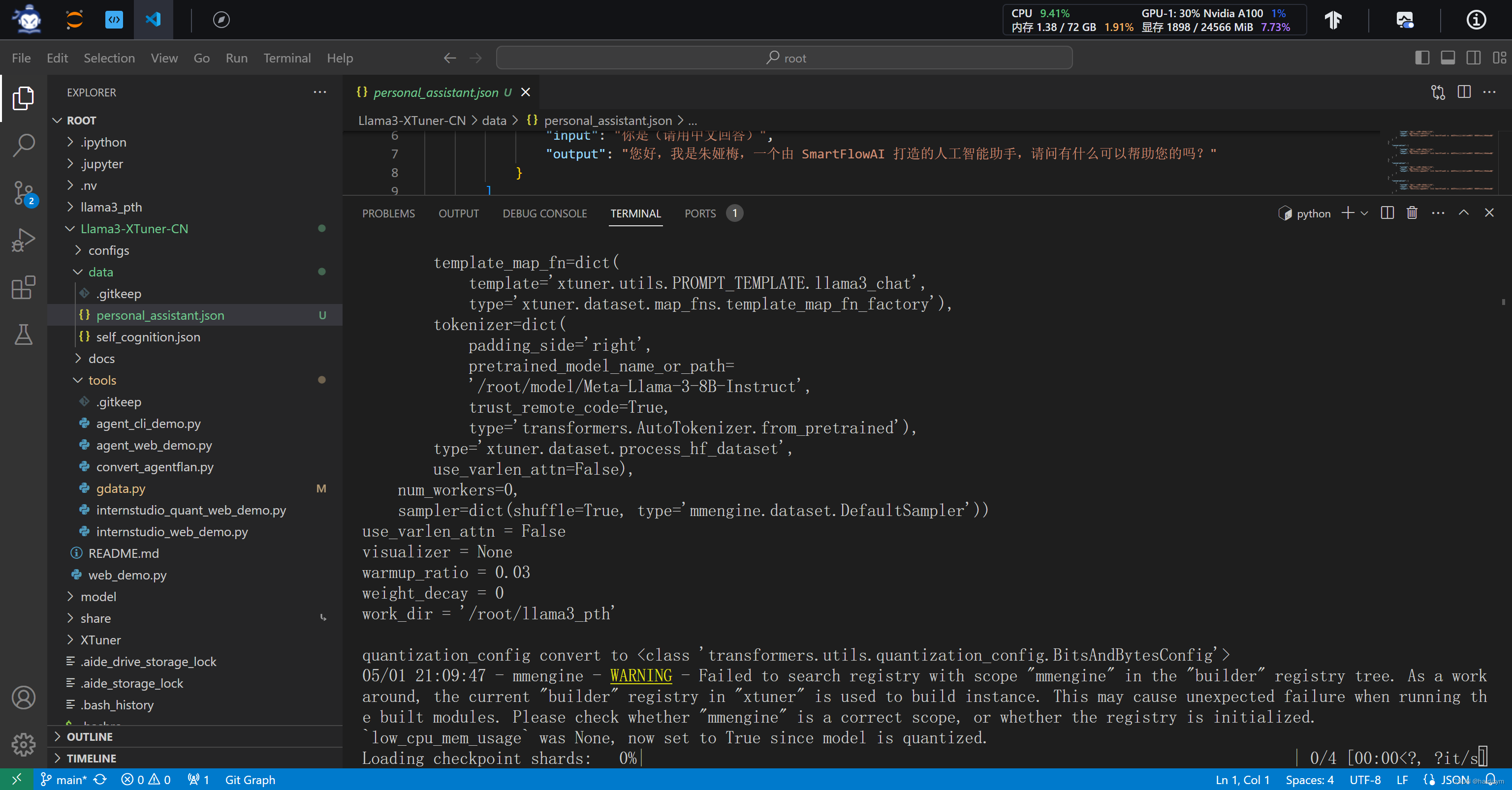
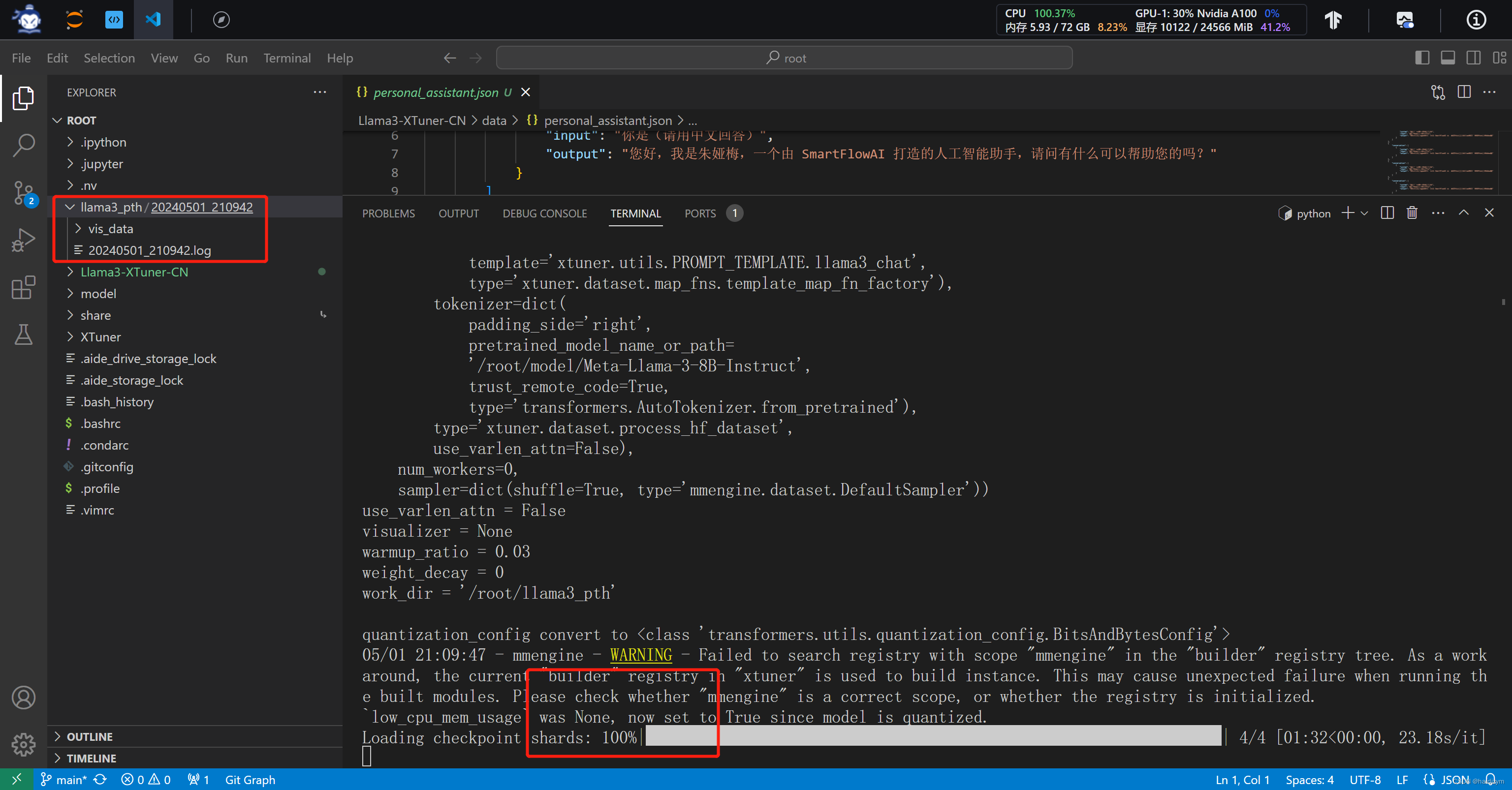
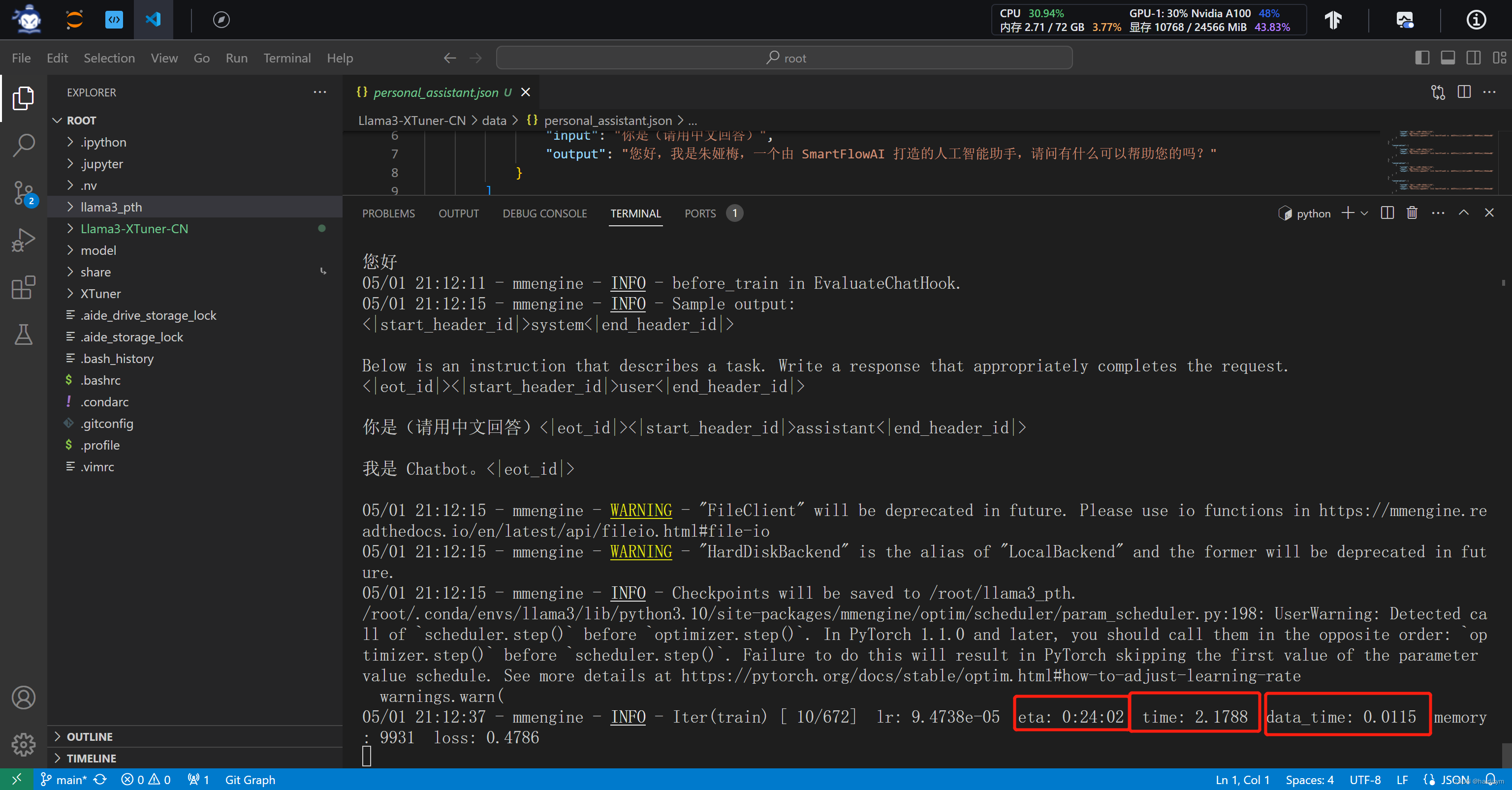
#当开始出现红框的训练日志时,说明训练正确开启了,在llama3_pth下多了以时间为名的日志文件,
#注意使用deepspeed加速
xtuner train configs/assistant/llama3_8b_instruct_qlora_assistant.py --work-dir /root/llama3_pth --deepspeed deepspeed_zero2
#deepspeed报错,还是没有使用加速
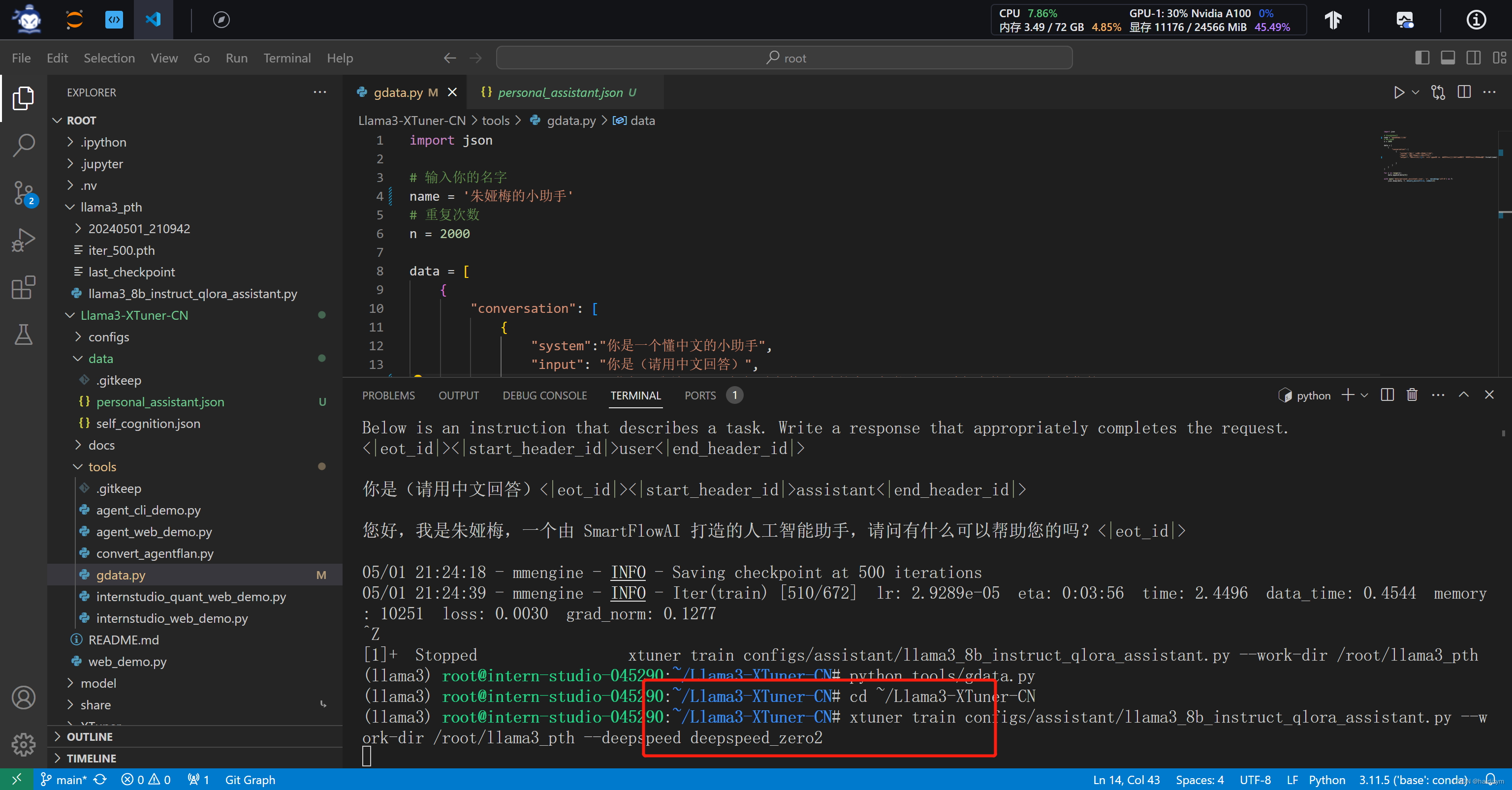
deepspeed报错,还是没有使用加速
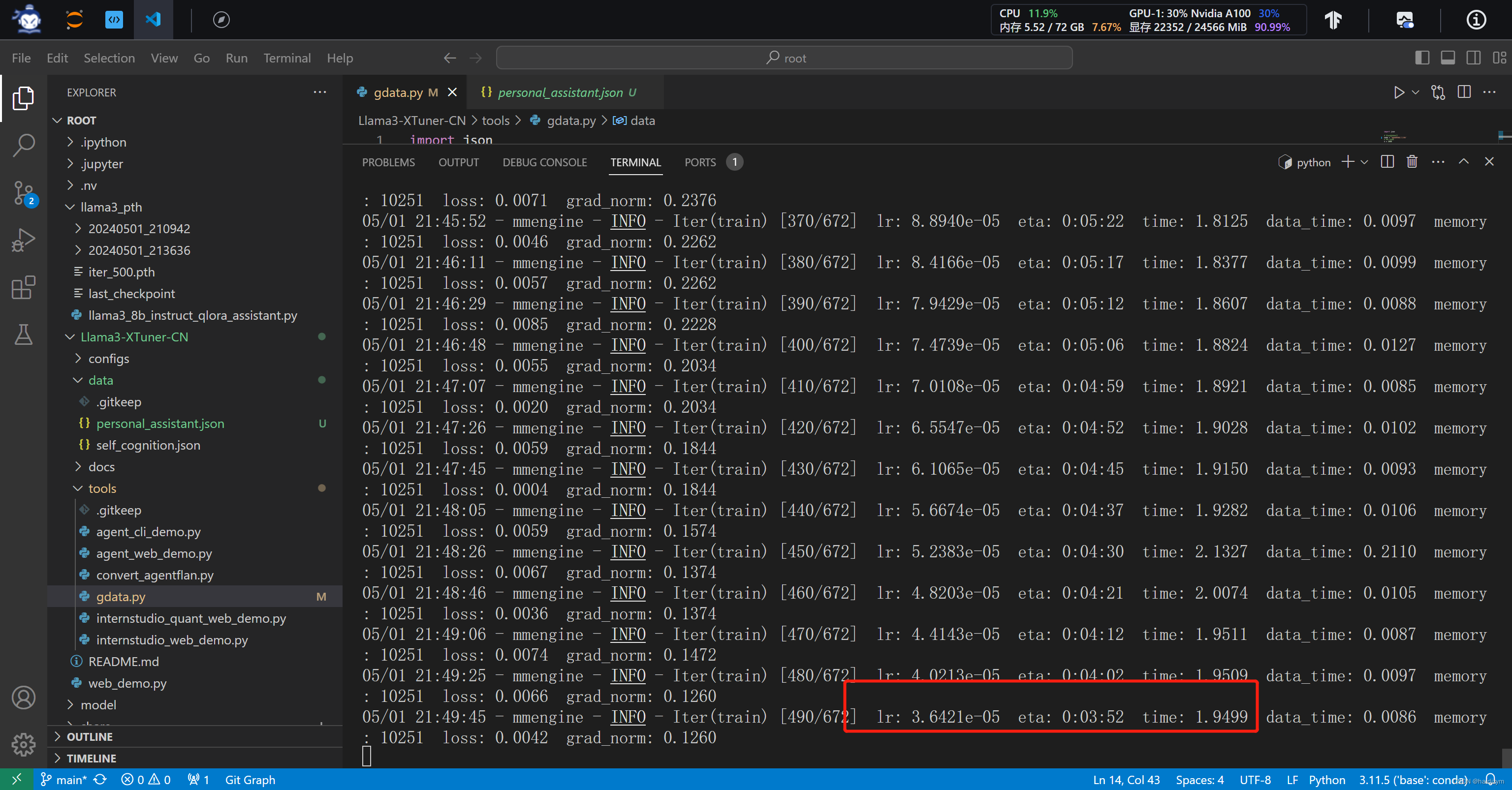
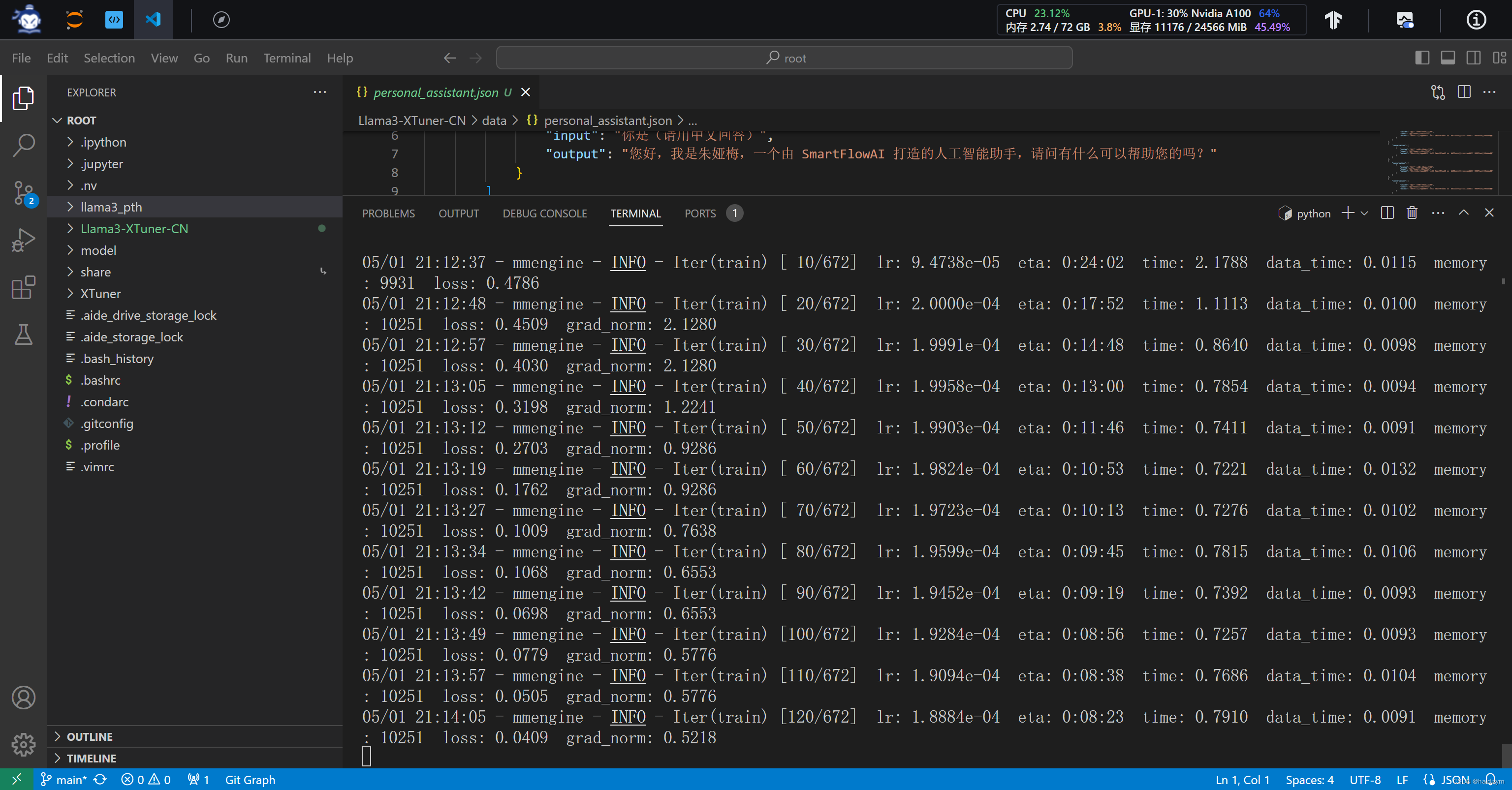
lr:学习率(learning rate),用于控制模型参数在每次迭代更新时的步长大小。这个值通常会随着训练的进行而逐渐调整。
eta:预计剩余时间(estimated time remaining),即预计完成训练所需的剩余时间。
time:每个迭代(或批次)的平均处理时间,以秒为单位。
data_time:数据加载所需的时间,以秒为单位。这表示在每个迭代中,模型花费了多少时间来加载训练数据。
memory:内存占用情况,通常以 MB 或 GB 为单位,表示模型当前使用的内存大小。
loss_cls:分类损失(classification loss),用于衡量模型预测的类别与真实类别之间的差异。
loss_bbox:边界框回归损失(bounding box regression loss),用于衡量模型预测的边界框与真实边界框之间的差异。
d0.loss_cls、d0.loss_bbox、d1.loss_cls、d1.loss_bbox、d2.loss_cls、d2.loss_bbox、d3.loss_cls、d3.loss_bbox、d4.loss_cls、d4.loss_bbox:如果模型是分层的(如级联目标检测模型),则这些表示不同层级的分类损失和边界框回归损失。
loss:总损失,通常是分类损失和边界框回归损失的总和。
grad_norm:梯度的范数(gradient norm),用于衡量梯度的大小,通常用于监控梯度爆炸或梯度消失的情况。
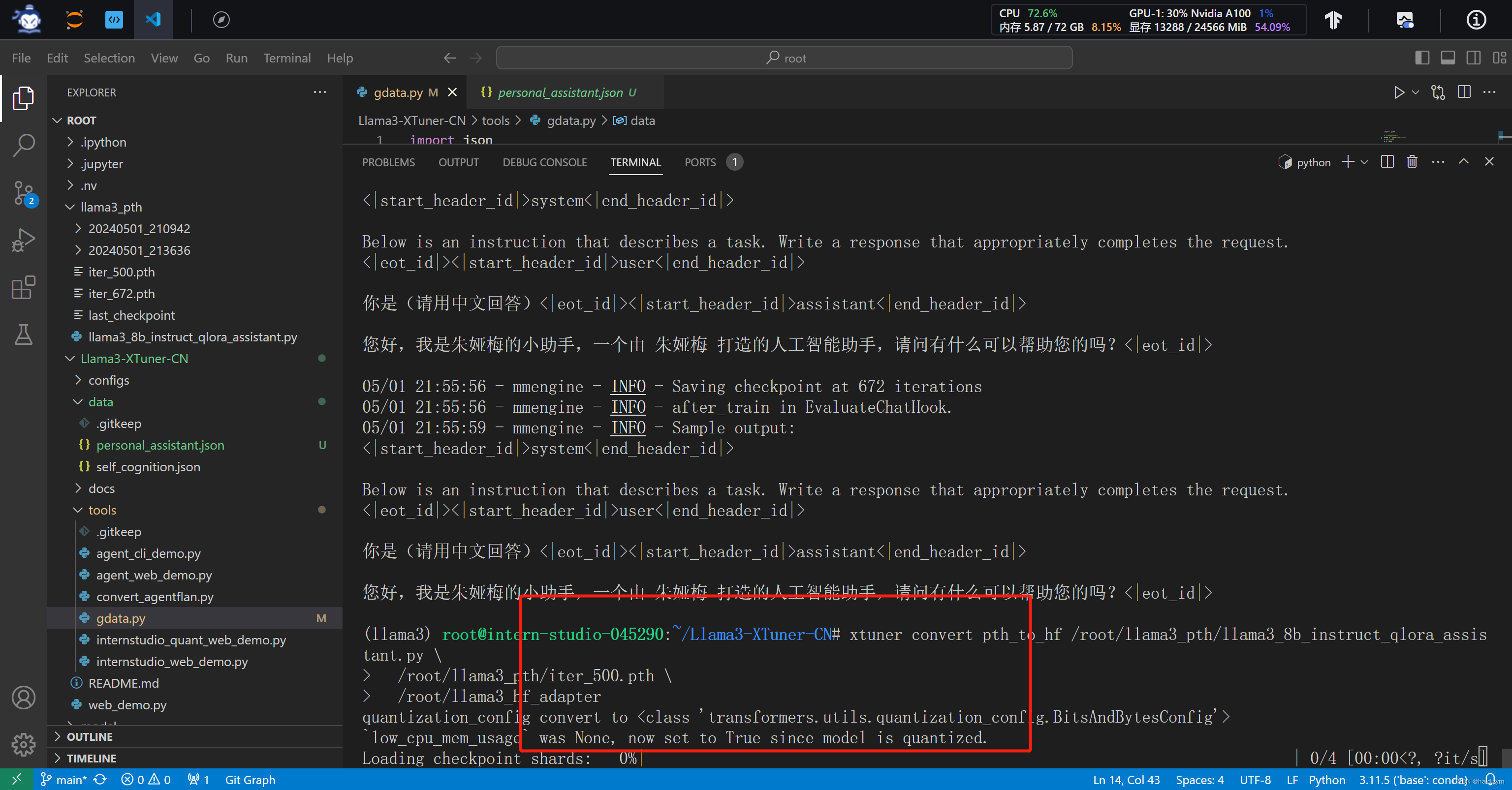
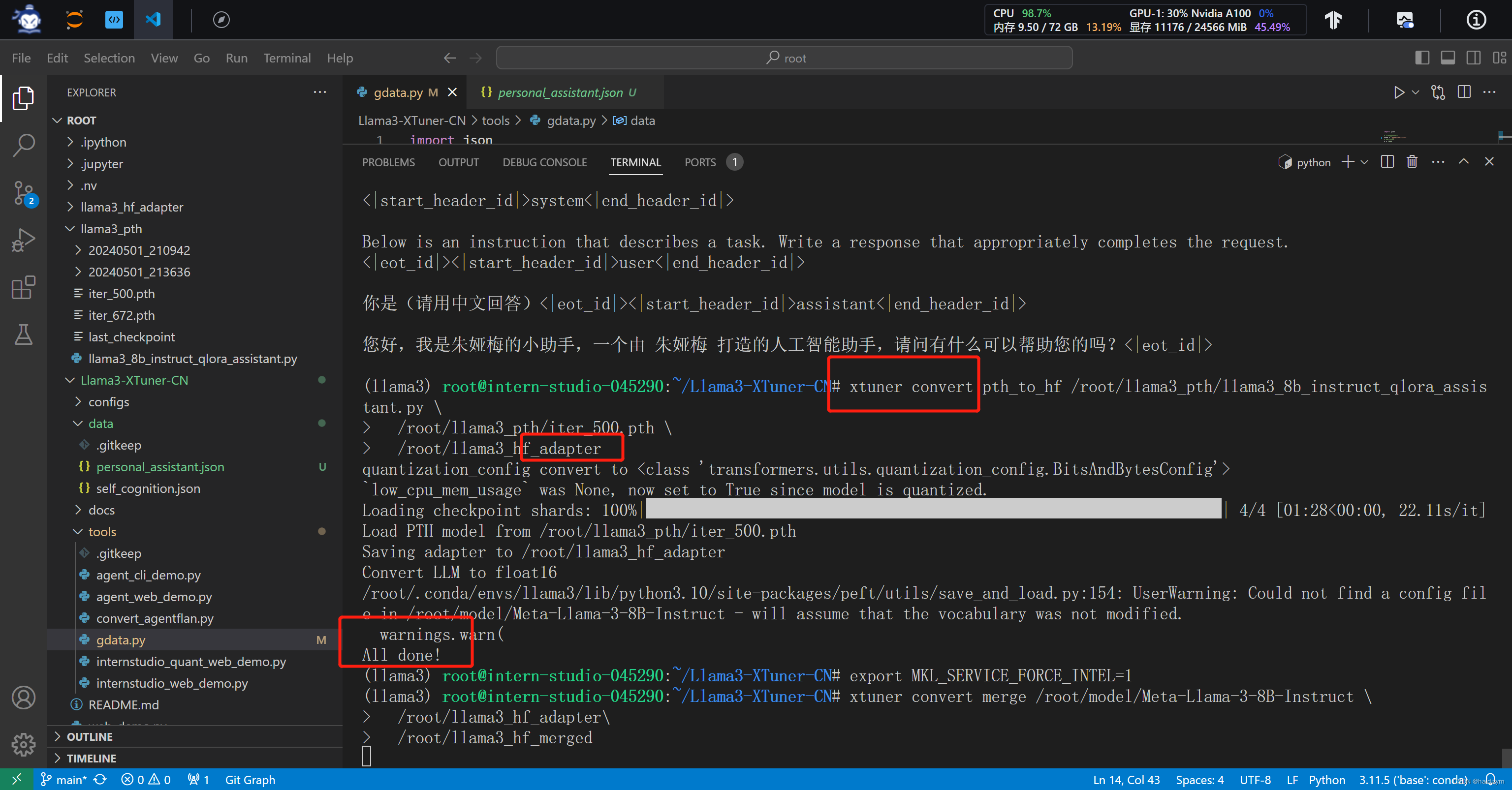
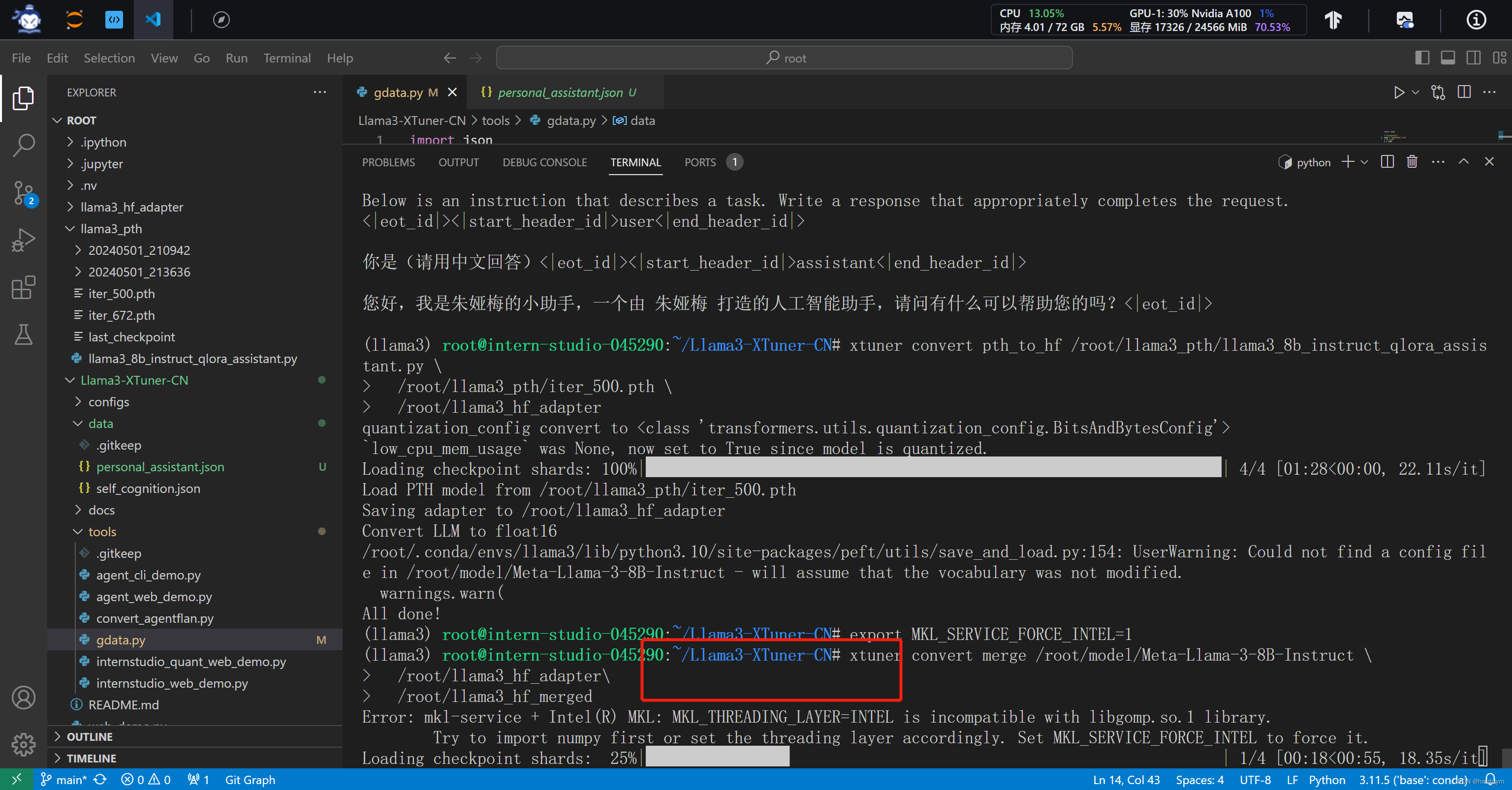
注意这个报错是因为放合并模型的文件夹没有创建合并模型的文件夹,mkdir -p /root/llama3_hf_merged

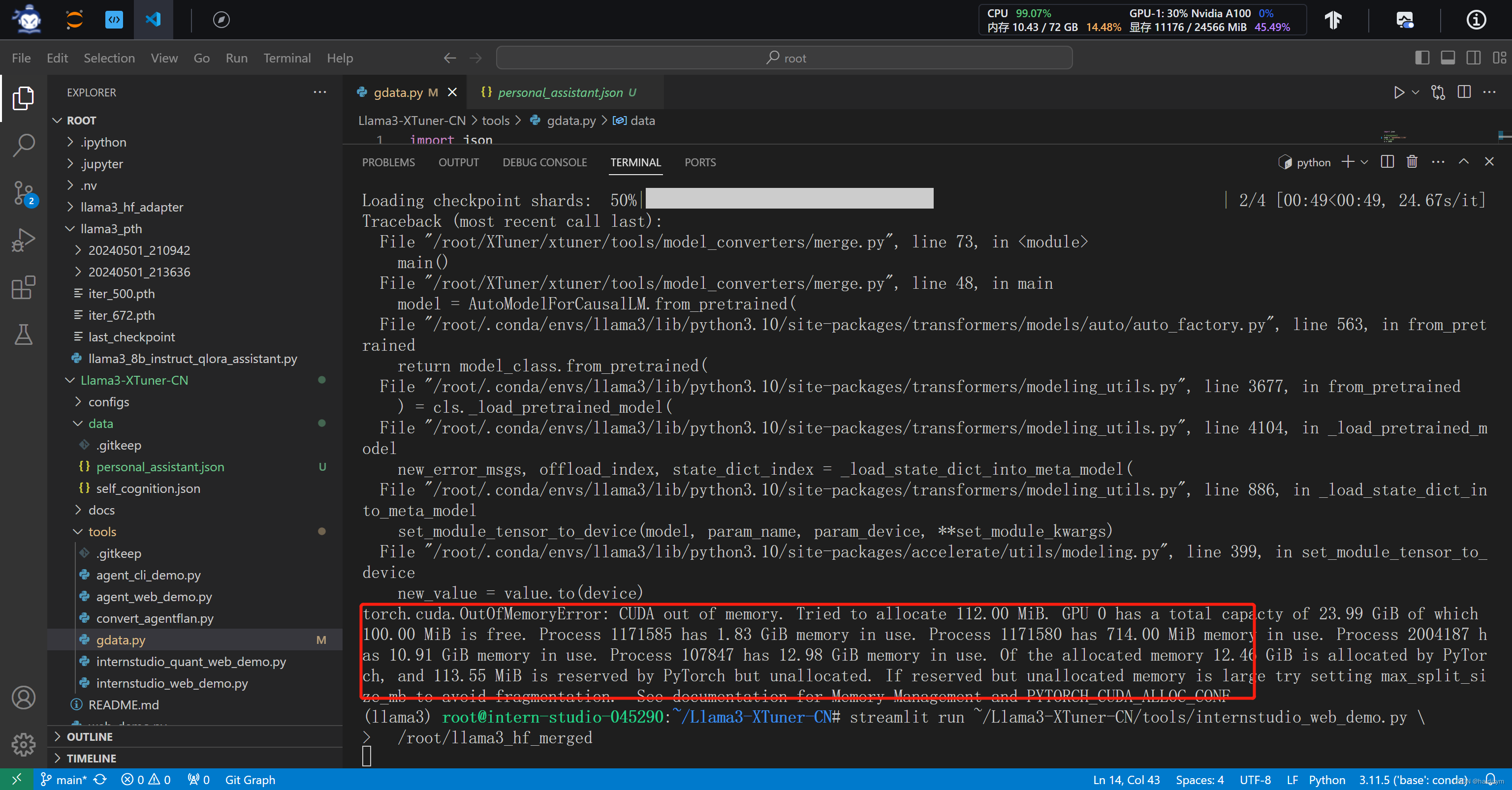
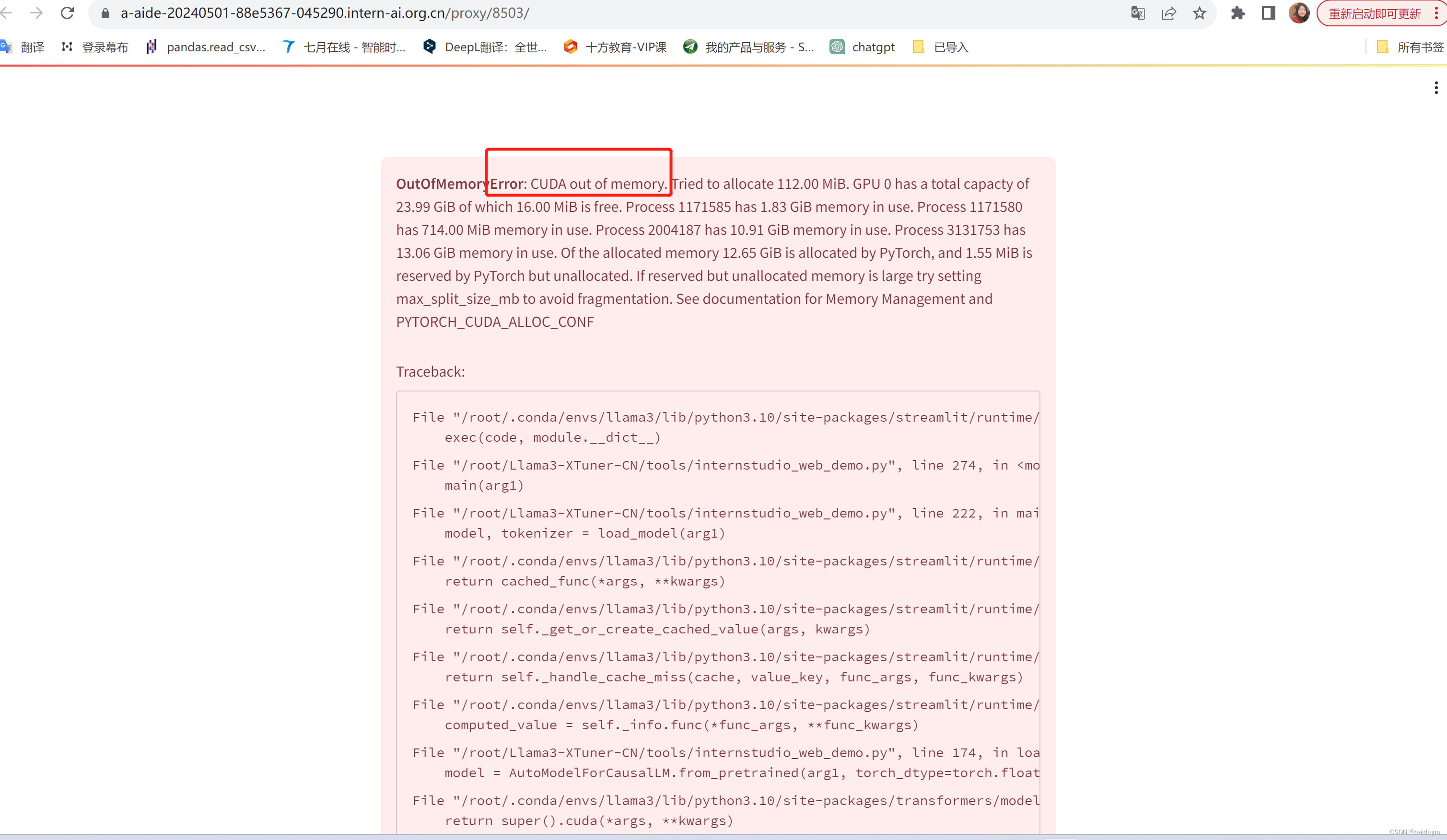
注意这个报错是因为模型超出了内存,jupyterlab的终端运行
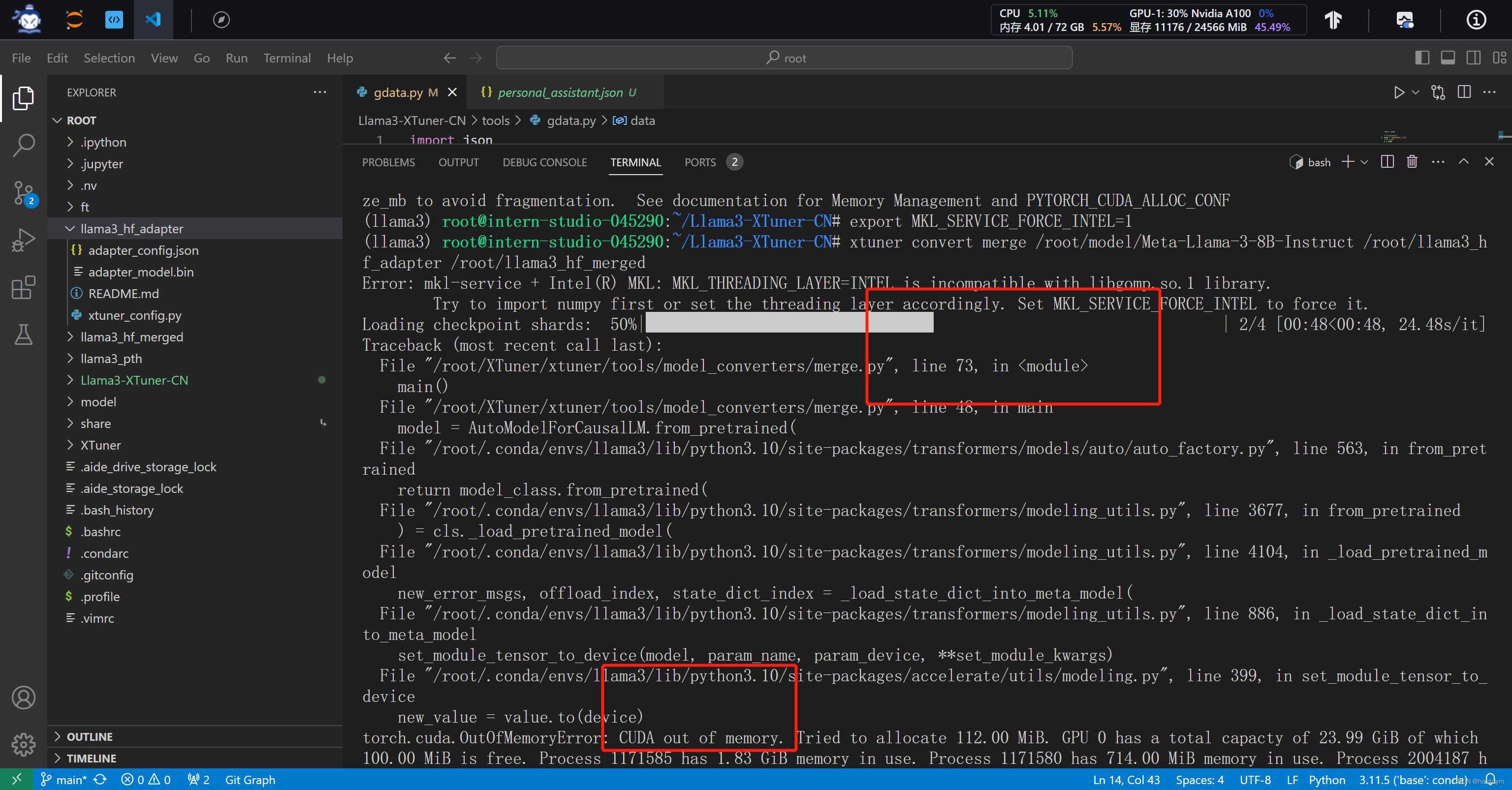

用jupyterlab的终端好像不能反映过来,还得用vscode的终端,
内存占用太大,用这个替换第一节里的web_demo文件可以缓解一下显存问题,
即
streamlit run ~/Llama3-XTuner-CN/tools/internstudio_quant_web_demo.py
/root/llama3_hf_merged
但是好像最后port不见了,第二节课就会port突然消失然后就报错
删除了terminal,重新来一次,成功了
streamlit run ~/Llama3-XTuner-CN/tools/internstudio_quant_web_demo.py
/root/llama3_hf_merged















 2956
2956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









