









简介: 本文涉及python、matlab基础、深度学习主流框架(pytorch、tensorflow、Keras)
全文概览
Part1: Python基础
try:
可能出现异常的代码段
excpet 异常情况1: # 有异常,且是异常情况1,执行~
~
excpet 异常情况2: # 有异常,且是异常情况2,执行~~
~~
except: # 有异常,但不是异常情况1和2中任何一个,执行~~~
~~~
else: # 无异常,执行~!
~!
finall: # 无论是否有异常,都执行!!!
!!!
参考文章:python try语句相关(try/except/else/finally)
用上下文管理器 的方式打开一个文件,对其进行读写操作。
好处:不用单独释放内存
参考文章:python 使用 with open() as 读写文件
一般结合上下文管理器使用
with open(文件名,'读写操作w / r')as 变量i: # i就是文件名了
json.dump(待操作的数据,待操作的文件名i)
参考文章:Python json.dump()用法及代码示例
让 方法内的 局部变量 全局可用,并且在别的文件里也可以引用到
参考文章:python global 用法简介
把大写字母变成小写字母
对行来说
loc:works on labels in the index.
iloc:works on the positions in the index (so it only takes integers).
也就是说loc是根据标签名来索引,iloc根据位置索引,所以只能是整数
示例:(jupyter里实现)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
np.random.seed(123)
mm = pd.DataFrame(np.random.random([10,6]),columns=list('ABCDEF'))
mm_ll = mm.loc[1:6,:]
print(mm)
print(mm_ll)

mm_ll = mm.loc[1:6,:]
print(mm)
print(mm_ll)

mm_ll = mm.loc[:,mm.columns!="F"]
print(mm_ll)

可用来判断程序中预想的实际运行的是否一致,不一致触发异常
assert 1==1 # 条件为 true 正常执行
assert 1==2 # 条件为 false 触发异常
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AssertionError
*形参 ——代表这个位置接收任意多个非关键字参数,转成元组方式。
**形参 ——代表这个位置接收任意多个非关键字参数,转成字典方式。
*实参 ——代表的是将输入迭代器拆成一个个元素。
参考文章:【python】*号用法 如nn.Sequential(*layers)

第二种使代码更简洁。(其余写法用的不多,详见参考文章)
参考文章:python 中if-else的多种简洁的写法
-
isinstance
参考文章:isinstance -
hdf5文件加载
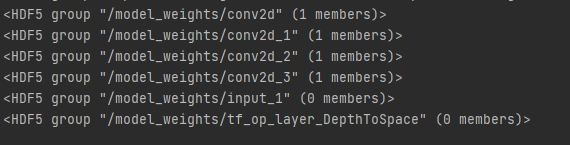
一个h5文件被像linux文件系统一样被组织起来:dataset是文件,group是文件夹,它下面可以包含多个文件夹(group)和多个文件(dataset)。
以SRCNN文件中的.h5为例:

import h5py
from h5py import Dataset, Group, File
with h5py.File('my_modelSRCNN.h5',"r") as f:
for key in f.keys():
# print(f[key], key, f[key].name, f[key].value) # 因为这里有group对象它是没有value属性的,故会异常。另外字符串读出来是字节流,需要解码成字符串。
print(f[key], '|||',key,'|||', f[key].name)
for key in model_group.keys()
print(model_group[key])

对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值
-
关于list
-
深浅拷贝
-
python中的self
(1)和普通数相比,在类中定义函数只有一点不同,就是第一参数永远是类的本身实例变量self,并且调用时,不用传递该参数。除此之外,类的方法(函数)和普通函数没啥区别,你既可以用默认参数、可变参数或者关键字参数(*args是可变参数,args接收的是一个tuple,**kw是关键字参数,kw接收的是一个dict)。
t = Test() t.ppr() # t.ppr()等同于Test.ppr(t)(2)实例在调用方法时,如果发现自身实例中没有定义该方法,沿着继承树往上找父类中有无定义要调用的方法,如果父类中定义了,则可调用成功。
-
pycharm调整字体
-
读取字典中的所有key
新建一个空列表 配合 .keys()和循环取出.keys()的每个元素 并 append到列表中
python中取得字典全部key的方法 -
切片操作
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(a[-10]) # 0 类型:<class 'int'>
print(a[0::-1]) # 从0往回数 step为1 结果为 [0] 类型:<class 'list'>
print(a[4::-1]) # [4, 3, 2, 1, 0]
print(a[9::-3]) # [9, 6, 3, 0]
print(a[:3:-2]) # [9, 7, 5] -2代表从后往前; :3表示从9到3停止(算9不算3);step=2
Python re.findall中正则表达式(.*?)和参数re.S使用
-
os.path.basename() —— 返回path最后的文件名
os.path.basename()作用
import os
path='D:/CSDN/s/pp.jpg'
print(os.path.basename(path)) # pp.jpg
Part2:Pytorch基础(顺序:上面的是最新的)
pred, pred_idx = torch.max(outputs.data, dim=1)
# dim = 1按第二个维度(预测类别值的维度)索引最大值;返回两个值 分别为最大值pred 和最大值索引pred_idx
# 说明:dim=1不用去记是按列还是行 就是第二个维度 不知道第二个维度是什么就 运行一下 print (对象.shape),就知道了!
-
dataloader中的batch_sampler
[Pytorch] Sampler, DataLoader和数据batch的形成
pytorch之dataloader深入剖析 -
图像通道变换
要求输入网络的是【batch_siaze, channel, height, weight】
# swap color axis because
# numpy image: H x W x C
# torch image: C X H X W
image = image.transpose((2, 0, 1))
Pytorch入门学习(六)— 加载数据以及预处理(初步)— 只为了更好理解流程 ~~ 图像变换的基本写法的部分
-
with torch.no_grad() 和 requires_grad
每个tensor都有参数 requires_grad,设置为True,则反向传播时,该tensor就会自动求导,默认是False。且一个叶子节点(端点)设为True,则依赖他的所有节点都为True。但是如果设置了true后,接的是上下文管理器with torch.no_grad()则在该模块下,所有计算得出的tensor的requires_grad都自动设置为False。
参考文章:【pytorch系列】 with torch.no_grad():用法详解 -
AverageMeter()
训练和测试的时候 用于 管理变量更新 包括 变量更新(.update)以及重置(.reset) 读取变量时通过 对象.属性 的方式读取
参考文章:AverageMeter()的作用与用法
上面内篇文章是截取了这篇文章的内容 ,TSN算法的PyTorch代码解读(训练部分)【指南:大概在这里“接下来就是main函数的第三部分:训练模型”】
class AverageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1): # 此方法就是求loss和 后续可以用.avg方法求平均
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
-
optim.Adam使用
参考文章:torch.optim优化算法理解之optim.Adam() -
划分数据集train_test_split用法(联系k折验证)
X_train,X_test, y_train, y_test =cross_validation.train_test_split(X,y,test_size, random_state)
参考文章:Sklearn的train_test_split用法 -
pytorch自带模型加载
参考文章 -
unsqueeze_和unsqueeze
二者实现同样的功能, 区别在于unsqueeze_是in_place操作,即unsqueeze不会对使用unsqueeze的tensor进行改 变,想要获取unsqueeze后的值必须赋予个新值,unsqueeze_则会对自己改变
引用文章 -
预训练模型 —— save、load、state_dict、load_state_dict
保存加载模型(包括了自己的、经典网络的、只加载网络中的一部分模型以及对这一部模型的截取、只加载参数不要模型的以及过滤出自己网络需要的参数、加载模型时权重参数的加载方式)
(1)经典网络预训练模型:pytorch里torchvision包,包括3个子包: torchvison.datasets ,torchvision.models ,torchvision.transforms ,分别是预定义好的数据集(比如MNIST、CIFAR10等)、预定义好的经典网络结构(比如AlexNet、VGG、ResNet等)和预定义好的数据增强方法(比如Resize、ToTensor等)。models这个包中含有alexnet、densenet、inception、resnet、squeezenet、vgg等常用的网络结构,并且提供了预训练模型。
(2)state_dict 是Python dictionary对象,它将每个层(具有可学习参数的层(卷积层、线性层等),以及注册的缓存(batchnorm的运行平均值))映射到它的参数张量。优化器对象也有一个state_dict,其中包含关于优化器状态以及所使用的超参数的信息。
(3)预训练模型的权重问题
如果没有初始化权重参数,两种方法如下:(一)在线下载VGG模型(二)所以直接本地下载好之后再load即可
(一):
def __init__(self, weights=False):
super(VGG, self).__init__()
if weights is False:
model = models.vgg19_bn(pretrained=True)
(二):
model = models.vgg19_bn(pretrained=False)
pre = torch.load(weights) # weight是由调用函数时传进来的参数,是个PATH(包括文件名后缀)
model.load_state_dict(pre)
(一)保存和加载整个模型
# 保存模型
torch.save(model, 'model.pth\pkl\pt') #一般形式torch.save(net, PATH)
# 加载模型
model = torch.load('model.pth\pkl\pt') #一般形式为model_dict=torch.load(PATH)
(二)仅保存和加载模型参数(推荐使用,需要提前手动构建模型!!!
# !说明:这里很重要,不同于(一)保存的是整个模型,加载时可直接加载。
# 这里保存的是模型参数,在加载模型参数前需手动构建模型以及优化器)
# 保存模型参数
torch.save(model.state_dict(), 'model.pth\pkl\pt') #一般形式为torch.save(net.state_dict(),PATH)
# 加载模型参数
model.load_state_dict(torch.load('model.pth\pkl\pt') #一般形式为model_dict=model.load_state_dict(torch.load(PATH)),这里的model是手动构建的,将加载的模型的参数给构建的模型。
(三)不仅限于模型参数,实验中往往要保存更多信息,两种保存方法如下:
# 法一:要保存多个组件,则将它们放到一个字典{'':~,'':~,'':~}中,再用torch.save()序列化这个字典。
torch.save({ 'epoch': epochID + 1, # 停止训练时epoch数
'state_dict': model.state_dict(), # 模型参数
'best_loss': lossMIN, # 最新的模型损失
'optimizer': optimizer.state_dict(), # 优化器的缓存和参数
'alpha': loss.alpha,
'gamma': loss.gamma},
checkpoint_path + '/m-' + launchTimestamp + '-' + str("%.4f" % lossMIN) + '.pth.tar')
# 上述最后一行是PATH
# 法二:用checkpoint去接,也是字典的形式
if (epoch+1) % checkpoint_interval == 0: # 几个断点一保存
checkpoint = {"model_state_dict": net.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"epoch": epoch}
path_checkpoint = "./checkpoint_{}_epoch.pkl".format(epoch)
torch.save(checkpoint, path_checkpoint)
(四)加载(接着(三)的保存来说)
# !说明:加载各组件(上述保存的模型参数、优化器参数、loss等信息)之前先初始化模型和优化器!然后使用torch.load()加载保存的字典。
model = TheModelClass(*args, **kwargs)
optimizer = TheOptimizerClass(*args, **kwargs)
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict']) # 要与保存时创建的字典的key一致
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
(五)加载经典网络模型
(六)加载部分模型
class VGG(nn.Module):
def __init__(self, weights=False):
super(VGG, self).__init__()
if weights is False:
model = models.vgg19_bn(pretrained=True)
model = models.vgg19_bn(pretrained=False)
pre = torch.load(weights)
model.load_state_dict(pre)
self.vgg19 = model.features
for param in self.vgg19.parameters():
param.requires_grad = False
参考文章! 有加载经典网络的预训练模型 也有加载自己网络的
参考文章:pytorch模型的保存和加载、checkpoint ~ 这篇写的很全
(六)的参考
参考简书:学号叁拾的《PyTorch之保存加载模型》(参考了定义)
参考文章:源码详解Pytorch的state_dict和load_state_dict
知乎答主科技猛兽——PyTorch 13.模型保存与加载,checkpoint (大概看了一下,transforms.Compose那里写得全)
nn.Module —— 父类,不管是自定义层、自定义块、自定义模型,都是通过继承Module类完成的,这点很重要!其实Sequential类也是继承自Module类的。
nn.Sequential —— 合并层操作
torch.nn.Parameter —— 作为nn.Module中的可训练参数使用。
【torch.nn.Parameter与torch.Tensor的区别就是前者会自动被认为是module的可训练参数,即加入到parameter()这个迭代器中去;而后者是不在parameter中的。nn.Parameter的对象的requires_grad属性的默认值是True,即是可被训练的,而后者的属性默认值与之相反。】
参考文章:pytorch教程之nn.Module类详解——使用Module类来自定义模型
参考文章:nn.Module、nn.Sequential和torch.nn.parameter学习笔记
-
可视化loss
pytorch中保存网络损失loss简单代码
Part3:Tensorflow 基础
-
keras 和 tensorflow 关系
keras是一个模型级的库,提供了快速构建深度学习网络的模块。Keras并不处理如张量乘法、卷积等底层操作。这些操作依赖于某种特定的、优化良好的张量操作库。Keras依赖于处理张量的库就称为“后端引擎”。 Keras原来独立存在,后来被tensorflow吸收,tf即成为了他的后端。 Keras提供了两种后端引擎Theano/Tensorflow,可修改依赖的后端。
关于keras的后端 -
keras中的GlobalAveragePooling2D和AveragePooling2D
tensorflow中keras的GlobalAveragePooling2D和AveragePooling2D的区别 -
self.sess.run
# 代码来自李重仪UColor的model_train中的def train(self, config)
_, err1,err2,err3= self.sess.run([self.g_optim, self.MSE, self.loss_vgg_raw, self.loss], feed_dict={self.images: batch_input, self.labels_image:batch_image_input,self._depth:batch_depth_input})[0]
(1) [self.g_optim, self.MSE, self.loss_vgg_raw, self.loss]为网络输出,可以看到等号左边用四个变量去接_, err1,err2,err3
(2) feed_dict作用是将数据喂入网络。拓展说明:创建了各种形式的常量和变量后,但TensorFlow 同样还支持占位符。占位符并没有初始值,它只会分配必要的内存。在会话中,占位符可以使用 feed_dict 馈送数据。[0]表第一批次。
(3) self.images、self.labels_image、 self._depth在之前的build_model中用占位符定义的
(4) batch_input、batch_image_input、batch_depth_input是批量读入的batch_size个数据
参考文章: self.sess.run(self.out,feed_dict)
参考文章:Tensorflow 学习笔记——占位符和feed_dict(二)
Part4: Keras基础
model = Model(inputs=a, outputs=b)
model = Model(inputs=[a1, a2], outputs=[b1, b2, b3])
# 通过inputs 和 outputs 构造多输入(a1,a2)和多输出(b1,b2,b3)的Model
Keras学习(一)—— Keras 模型(keras.model): Sequential 顺序模型 和 Model 模型 ~~~~~【这篇文章很全】
Part5: Matlab基础
-
卷积、相关操作
-
cat
C = cat(dim, A1, A2, A3, …) 表示按dim联结所有输入的数组
dim=1 —— 沿竖着堆叠
dim=2 —— 沿横着堆叠
dim=3 —— 沿第三维度堆叠
例如:A = [1 2; 3 4];
B = [5 6; 7 8];
C = [1,2; 3,3];cat(1, A, B) % 沿着竖着的方向堆叠,列数要一致
ans =
1 2
3 4
5 6
7 8cat(2, A, B) % 沿着横着的方向堆叠,行数要一致
ans =
1 2 5 6
3 4 7 8cat(3, A, B,C) % 沿第三个维度(对图像来说就是channel)
ans(:,:,1) =
1 2
3 4
ans(:,:,2) =
5 6
7 8
ans(:,:,3) =
1 2
3 3

LogX(Y)=Log(Y) / Log(X)
常见底:
lg(x) —— log10(x)
ln(x) —— log(x)
e —— exp(1)
e^5 —— exp(5)
-
滤波
- ordfilt2
Y=ordfilt2(X,5,ones(3,3)),相当于3×3的中值滤波
Y=ordfilt2(X,1,ones(3,3)),相当于3×3的最小值滤波
Y=ordfilt2(X,9,ones(3,3)),相当于3×3的最大值滤波
Y=ordfilt2(X,1,[0 1 0;1 0 1;0 1 0]),输出的是每个像素的东、西、南、北四个方向相邻像素灰度的最小值。 - imfilter
g = imfilter(f, w, filtering_mode, boundary_options, size_options)
其中, f 为输入图像, w 为滤波掩模, g 为滤波后图像。 filtering_mode 用于指定在滤波过程中是使用“相关”还是“卷积”。 boundary_options 用于处理边界充零问题,边界的大小由滤波器的大小确定。size_options为最终输出图像的size问题。

参考:论坛 —— ordfilt2函数功能说明
- ordfilt2
Part6:相关库
-
matplotlib
(1)ion()、ioff()、legend():用它可实现交互模式,即 可同时打开两个窗口
参考:matplotlib中ion()和ioff()的使用
# 交互式画图
plt.ion()
ax = plt.subplot(1,1,1)
p1, = ax.plot([1,2,3], label="line 1")
p2, = ax.plot([3,2,1], label="line 2")
p3, = ax.plot([2,3,1], label="line 3")
handles, labels = ax.get_legend_handles_labels()
# reverse the order( 颠倒图例中元素顺序并显示图例 )
ax.legend(handles[::-1], labels[::-1])
plt.ioff()
plt.show()
-
numpy
(1)stack()、vstack()、hstack():前者是堆叠,后两者是串联,其中
stack():按照指定的轴(就是维度)对数组序列进行联结。
vstack():沿第1个维度串联(以0维度开始算)
hstack():沿第0个维度串联(以0维度开始算)
参考:Numpy中stack(),hstack(),vstack()函数的使用方法
(2)random模块生成数组
# random.uniform 生成均匀分布的随机数
a = np.random.uniform(1,2,size=5)
print(a)
# 输出
[1.41399959 1.69592935 1.27264573 1.71349141 1.35462486]
(3) newaxis —— 插入新维度
三种方法:
(1)指定shape
(2)[:,np.newaxis] 或 [np.newaxis, :]
(3)b = a[None]
关于np.newaxis的一点理解
numpy.newaxis
# #创建train_acc.csv和var_acc.csv文件,记录loss和accuracy
# 创建自定义列名的.csv文件 df后面用不到 只是用于创建
df = pd.DataFrame(columns=['time','step','train Loss','training accuracy']) # 列名
df.to_csv("D:/Hynn_useful/code/Ucolor_final_model_corrected/loss/loss_acc1.csv",index=False)
# 将想要输入表格的数据 以二维列表的形式转化为DataFrame columns表明对应的列 但在将list写入.csv文件时,不再写入列名
list = pd.DataFrame([[100,20,30,40]],columns=['time','step','train Loss','training accuracy'])
# header=False很重要 即不会创建默认新的列索引
list.to_csv("D:/Hynn_useful/code/Ucolor_final_model_corrected/loss/loss_acc1.csv", mode='a',index=False,header=False)
演示实例(对李重仪Ucolor 的 model_train.py下操作):
目的:每次训练后能记录epoch 和 loss,并且在下次训练时,接着上一次的epoch训练。
首先定义保存和加载loss、epoch的函数
保存到.csv文件
加载.csv文件的epoch列后将最后一个数据取出 追加到result列表里
加载.csv文件的final_loss列后将最后一个数据取出 追加到result列表里
得到的result为[epoch final_loss],因此result[0]为epoch,result[1]为loss

在def train()里
第一次均赋值为0 之后的根据最后一次的数据给出相应的轮数与loss


调用save_loss将当前的loss保存

















 67
67











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











