







文章目录

在上一篇博客 【AI 大模型】LlamaIndex 大模型开发框架 ① ( LlamaIndex 大语言模型 SDK 简介 | LlamaIndex 软件包安装 | 开发要点说明 | 完整代码示例 ) 中 简单介绍了 LlamaIndex 框架的原理 和 基本使用流程 ;
本篇博客中开始分析 LlamaIndex 框架中 设置 不同的 大语言模型 ( LLM ) 和 嵌入模型 ;
一、LlamaIndex 可配置的 LLM 类型
在 LlamaIndex 框架中 , LLM ( 大语言模型 ) 的配置支持多种类型和方式 , 开发者可根据需求灵活选择 云端 或 本地 部署方案 ;
1、云端 API 类型 LLM
云端 API 类型 LLM :
- OpenAI 系列 LLM : 通过 API-KEY 密钥 调用 GPT-3.5/GPT-4 等模型 , 可配置官方直连 或 国内中转 的 API-KEY 和 API 地址 ;
from llama_index.llms.openai import OpenAI
# 官方直连配置
llm = OpenAI(
api_key="sk-xxx", # 替换为实际API密钥
model="gpt-4", # 指定模型版本
temperature=0.7
)
# 国内中转配置(需自定义API地址)
llm = OpenAI(
api_key="sk-xxx",
api_base="https://your-proxy.com/v1", # 国内代理地址
model="gpt-3.5-turbo"
)
- Claude 系列 LLM : 需 配置对应 API 地址 和 密钥 , 配置 ;
from llama_index.llms.anthropic import Anthropic
llm = Anthropic(
api_key="claude-api-key", # Claude密钥
base_url="https://api.anthropic.com/v1", # 可替换为代理地址
model="claude-3-opus"
)
- Replicate 托管 LLM : 云端机器学习平台部署的大模型 , 支持 Llama3、Mistral、StableLM、GPT-J 等开源模型的云端 API 调用 ;
from llama_index.llms.replicate import Replicate
llm = Replicate(
api_token="r8_xxx", # Replicate平台密钥
model="meta/llama-3-70b-instruct", # 模型标识
temperature=0.5
)
2、本地部署 类型 LLM
本地部署 类型 LLM :
- Ollama 本地模型 : 支持运行 Llama3、DeepSeek 等 本地化部署 的大模型 ;
from llama_index.llms.ollama import Ollama
llm = Ollama(
model="llama3", # 本地模型名称(需提前通过ollama pull下载)
base_url="http://localhost:11434", # Ollama本地服务地址
request_timeout=60
)
- Hugging Face模型 : 通过 Transformers 库加载本地或 Hugging Face 上的模型 , 如 : Zephyr、Falcon ;
from llama_index.llms.huggingface import HuggingFaceLLM
# 本地加载HuggingFace模型
llm = HuggingFaceLLM(
model_name="HuggingFaceH4/zephyr-7b-beta", # 模型ID或本地路径
tokenizer_name="HuggingFaceH4/zephyr-7b-beta",
device_map="auto" # 自动选择GPU/CPU
)
# 使用HuggingFace Inference API(云端)
from llama_index.llms.huggingface import HuggingFaceInferenceAPI
llm = HuggingFaceInferenceAPI(
model_name="mistralai/Mistral-7B-Instruct-v0.2",
api_key="hf_xxx" # HuggingFace令牌
)
3、混合部署 LLM
LlamaIndex 框架 支持配置多个 LLM , 常用的场景是 结合 本地模型处理敏感数据 , 云端模型处理复杂任务 ;
下面的代码中 ,
- 配置了 本地使用 Ollama 部署的 DeepSeek-R1 的 1.5b 蒸馏版本 LLM , 用于处理本地敏感数据 ;
- 同时 配置了 OpenAI 云端模型 , 处理复杂的任务 ;
local_llm = Ollama(model="deepseek-r1:1.5b")
cloud_llm = OpenAI(model="gpt-4")
# 根据数据敏感性选择模型
hybrid_llm = ConditionalLLM(
conditions=[DataPrivacyFilter()],
llms=[local_llm, cloud_llm]
)
4、错误示例 - 设置 云端 DeepSeek 大模型
LlamaIndex 框架 只支持 OpenAI 、Claude 、 Replicate 云端模型 , 不支持国内的云端部署 LLM , 之前尝试配置 DeepSeek 出现错误 , 不同的厂商需要使用不同的 API ;
按照 DeepSeek 接口文档 , 使用 OpenAI 兼容的 API 格式 , 配置 API-KEY 和 API 地址 , 但是 模型名称 是 deepseek-chat 和 deepseek-reasoner ;
尝试为 LlamaIndex 框架 配置 DeepSeek 大语言模型 , 执行后会报错 ;
# 安装必要库(LlamaIndex核心框架)
# pip install llama-index
# 导入核心模块
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings # 索引构建/文档加载/全局配置
from llama_index.embeddings.openai import OpenAIEmbedding # 文本向量化模块
from llama_index.llms.openai import OpenAI # 大语言模型模块
# 配置第三方 OpenAI 兼容服务(核心设置)
Settings.llm = OpenAI(
api_key="sk-a6ac1c7c03b940f69b91ee3ddeb6915e", # 中转服务商提供的API密钥(重要:需保密!)
api_base="https://api.deepseek.com/v1", # 替换为第三方API网关地址
model="deepseek-chat", # 需与服务商支持的模型名称一致
temperature=0.1 # 控制输出随机性(0-1,值越小答案越确定)
)
# Settings.llm = OpenAI(
# api_key="sk-i3dHqZygiMb0bQ132c4c602aC2714b8e8cE9A919E7757aF7", # 中转服务商提供的API密钥(重要:需保密!)
# api_base="https://xiaoai.plus/v1", # 替换为第三方API网关地址
# model="gpt-3.5-turbo", # 需与服务商支持的模型名称一致
# temperature=0.1 # 控制输出随机性(0-1,值越小答案越确定)
# )
# 配置嵌入模型使用同一个服务商(文档向量化)
Settings.embed_model = OpenAIEmbedding(
api_key="sk-i3dHqZygiMb0bQ132c4c602aC2714b8e8cE9A919E7757aF7", # 通常与LLM使用相同密钥
api_base="https://xiaoai.plus/v1", # 与LLM保持同一服务商
model="text-embedding-ada-002" # 嵌入模型名称(需服务商支持)
)
# 加载文档(本地文档预处理)
documents = SimpleDirectoryReader("data").load_data() # 读取data文件夹内所有文档
# 创建索引(文档向量化存储)
index = VectorStoreIndex.from_documents(documents) # 自动调用embed_model生成向量
# 创建查询引擎(问答接口封装)
query_engine = index.as_query_engine() # 组合索引与LLM的问答系统
# 执行查询(语义搜索+LLM生成)
response = query_engine.query("文档中的主要观点是什么?并介绍下单纯形法步骤?使用中文回复,分行解析") # 自动检索相关段落并生成答案
print(response) # 输出结构化响应对象
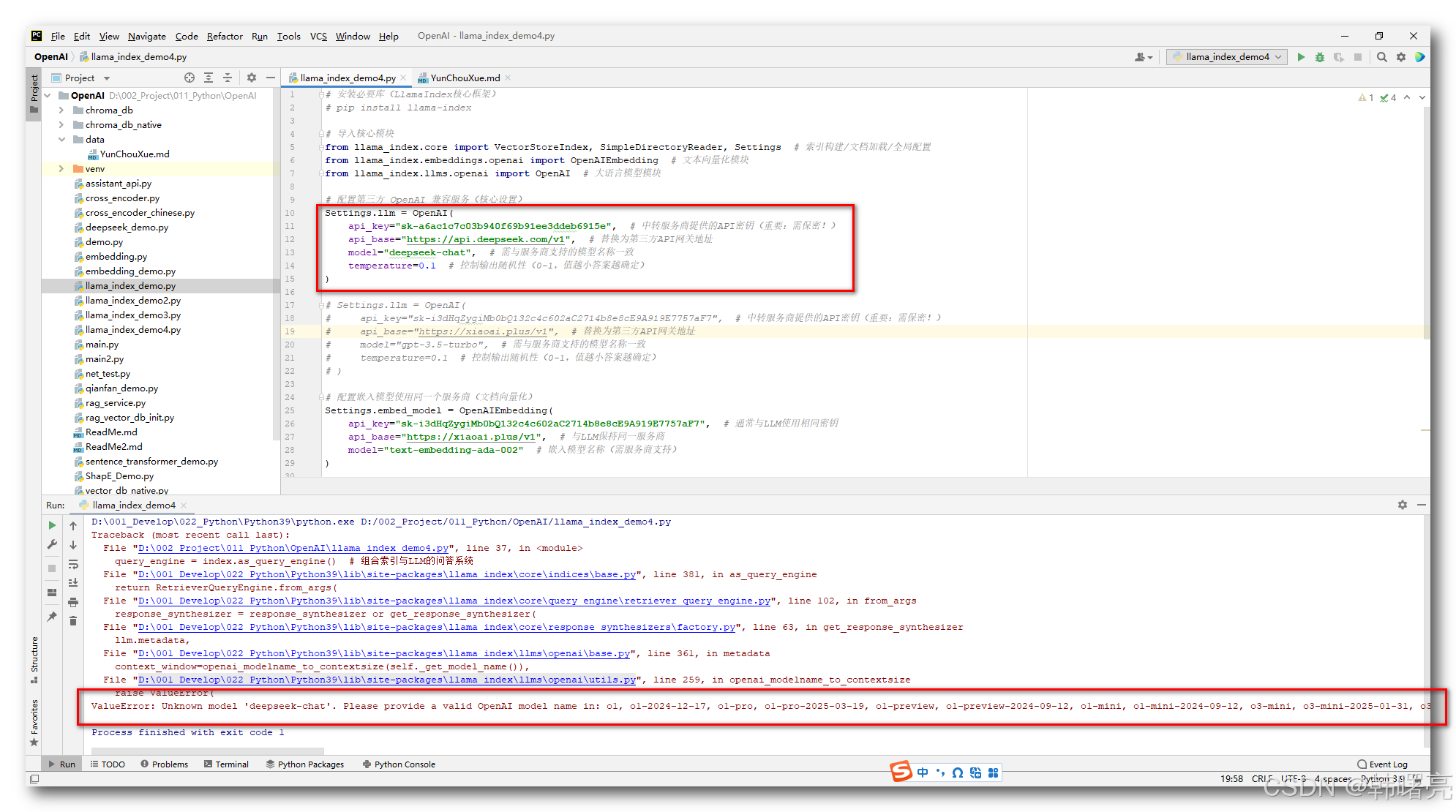
会提示如下错误 : OpenAI 的 API 只支持配置 OpenAI 的模型名称 , 不支持其它模型名称 , DeepSeek 的 OpenAI 兼容调用方式无法使用 ;
D:\001_Develop\022_Python\Python39\python.exe D:/002_Project/011_Python/OpenAI/llama_index_demo4.py
Traceback (most recent call last):
File "D:\002_Project\011_Python\OpenAI\llama_index_demo4.py", line 37, in <module>
query_engine = index.as_query_engine() # 组合索引与LLM的问答系统
File "D:\001_Develop\022_Python\Python39\lib\site-packages\llama_index\core\indices\base.py", line 381, in as_query_engine
return RetrieverQueryEngine.from_args(
File "D:\001_Develop\022_Python\Python39\lib\site-packages\llama_index\core\query_engine\retriever_query_engine.py", line 102, in from_args
response_synthesizer = response_synthesizer or get_response_synthesizer(
File "D:\001_Develop\022_Python\Python39\lib\site-packages\llama_index\core\response_synthesizers\factory.py", line 63, in get_response_synthesizer
llm.metadata,
File "D:\001_Develop\022_Python\Python39\lib\site-packages\llama_index\llms\openai\base.py", line 361, in metadata
context_window=openai_modelname_to_contextsize(self._get_model_name()),
File "D:\001_Develop\022_Python\Python39\lib\site-packages\llama_index\llms\openai\utils.py", line 259, in openai_modelname_to_contextsize
raise ValueError(
ValueError: Unknown model 'deepseek-chat'. Please provide a valid OpenAI model name in: o1, o1-2024-12-17, o1-pro, o1-pro-2025-03-19, o1-preview, o1-preview-2024-09-12, o1-mini, o1-mini-2024-09-12, o3-mini, o3-mini-2025-01-31, o3, o3-2025-04-16, o4-mini, o4-mini-2025-04-16, gpt-4, gpt-4-32k, gpt-4-1106-preview, gpt-4-0125-preview, gpt-4-turbo-preview, gpt-4-vision-preview, gpt-4-1106-vision-preview, gpt-4-turbo-2024-04-09, gpt-4-turbo, gpt-4o, gpt-4o-audio-preview, gpt-4o-audio-preview-2024-12-17, gpt-4o-audio-preview-2024-10-01, gpt-4o-mini-audio-preview, gpt-4o-mini-audio-preview-2024-12-17, gpt-4o-2024-05-13, gpt-4o-2024-08-06, gpt-4o-2024-11-20, gpt-4.5-preview, gpt-4.5-preview-2025-02-27, chatgpt-4o-latest, gpt-4o-mini, gpt-4o-mini-2024-07-18, gpt-4-0613, gpt-4-32k-0613, gpt-4-0314, gpt-4-32k-0314, gpt-4.1, gpt-4.1-mini, gpt-4.1-nano, gpt-4.1-2025-04-14, gpt-4.1-mini-2025-04-14, gpt-4.1-nano-2025-04-14, gpt-3.5-turbo, gpt-3.5-turbo-16k, gpt-3.5-turbo-0125, gpt-3.5-turbo-1106, gpt-3.5-turbo-0613, gpt-3.5-turbo-16k-0613, gpt-3.5-turbo-0301, text-davinci-003, text-davinci-002, gpt-3.5-turbo-instruct, text-ada-001, text-babbage-001, text-curie-001, ada, babbage, curie, davinci, gpt-35-turbo-16k, gpt-35-turbo, gpt-35-turbo-0125, gpt-35-turbo-1106, gpt-35-turbo-0613, gpt-35-turbo-16k-0613
Process finished with exit code 1
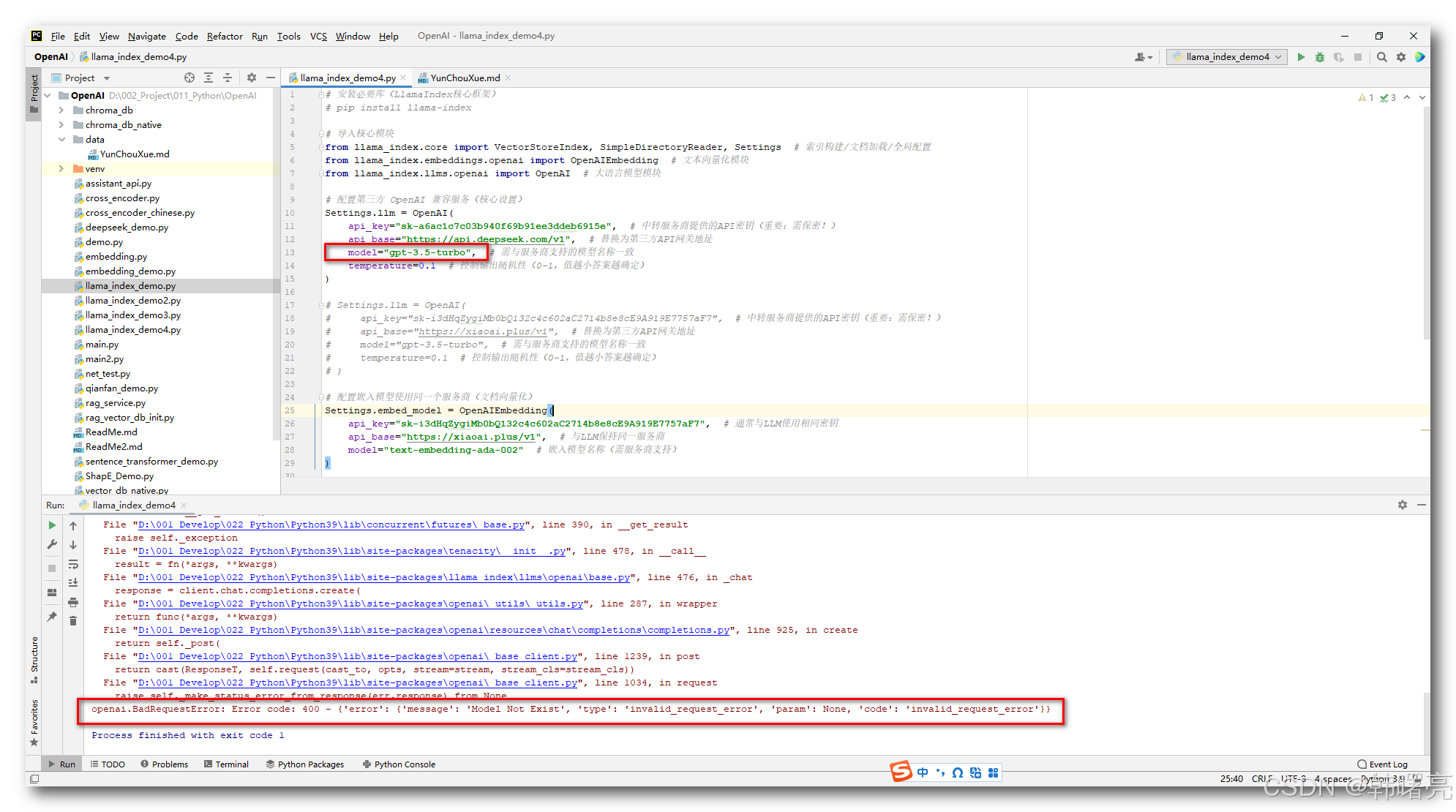
将模型名称修改为 gpt-3.5-turbo , 又会报错
openai.BadRequestError: Error code: 400 - {'error': {'message': 'Model Not Exist', 'type': 'invalid_request_error', 'param': None, 'code': 'invalid_request_error'}}
二、LlamaIndex 可配置的 文本向量模型 类型
文本向量模型 又称为 文本嵌入模型、嵌入模型 ;
LlamaIndex 框架支持多种 文本向量模型 配置方式 , 开发者可根据需求选择 云端 API、本地部署 或 微调适配 等方案 ;
1、云端 文本向量模型
云端 API 类型 文本向量模型 :
- OpenAI Embeddings : 需要 配置 OpenAI 的 API-KEY 和 地址 , 支持 通用语义检索、多语言支持 , 根据 Token 收费 , 每一千 Token 收费 0.13 美元 ; 如 text-embedding-ada-002 ; 该方式 通用性强 , 可生成 高维度向量 , 最高3072维 , 简单易用 , 但依赖云端 API ;
from llama_index.embeddings.openai import OpenAIEmbedding
Settings.embed_model = OpenAIEmbedding(
model="text-embedding-3-large", # 可选128/3072两种维度版本
api_key="sk-xxx",
api_base="https://api.example.com/v1", # 企业定制端点
embed_batch_size=256 # 批量处理加速
)
- Hugging Face Inference API : Hugging Face 托管了数千个开源模型 , 如 : BGE、GPT-2 , 支持本地或云端部署 , 可自定义模型 , 数据隐私控制强 , 支持私有云 ;
- 适用场景 : 研究实验、定制化需求(如法律/医疗领域微调),需平衡成本与数据安全。
- 调用方式 : REST API调用 . 免费额度+按需付费 , 可自托管模型降低费用 , 需要自己 从 Hugging Face 模型广场中 , 查找合适的模型 , 大多数模型只支持少数几种语言 ;
from llama_index.embeddings.huggingface import HuggingFaceInferenceAPIEmbedding
Settings.embed_model = HuggingFaceInferenceAPIEmbedding(
model_name="BAAI/bge-large-en-v1.5",
api_token="hf_xxx",
encode_kwargs={"normalize_embeddings": True} # 归一化向量
)
- Cohere Embed : 商业 API 服务 , 提供 多语言嵌入(如multilingual-22-12) , 针对检索、分类任务优化 , 支持长文本分块处理 ; 需配置 API 密钥调用 , 多任务编码模式 , 如 : 语义搜索 , 分类 , 相似度排序 等 ;
- 适用场景 : 企业级应用(如电商搜索、多语言内容推荐),需快速集成且无需本地部署。
- 调用方式 : API密钥授权,按请求次数计费,提供Python/Node.js SDK。
from llama_index.embeddings.cohere import CohereEmbedding
Settings.embed_model = CohereEmbedding(
cohere_api_key="xxx",
model_name="embed-multilingual-v3.0", # 支持100+语言
input_type="search_document" # 指定编码用途
)
2、本地部署 文本向量模型
本地部署 类型 文本向量模型 :
- Hugging Face 本地模型 : 通过 Hugging Face 的 transformers 库直接加载本地模型文件 , 支持离线推理 , 这类模型通常基于 BERT、RoBERTa 等架构 , 通过预训练捕捉文本语义特征 , 生成高维向量 , 如 : BAAI/bge-large-zh-v1.5 ;
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
Settings.embed_model = HuggingFaceEmbedding(
model_name="/path/to/BAAI_bge-base-en-v1.5", # 本地模型路径
device="cuda", # GPU加速
pooling="mean", # 池化策略
query_instruction="为这个句子生成表示:"
)
- Sentence Transformers : 基于 Siamese 网络结构 , 对预训练模型 ( 如BERT ) 进行二次训练 , 优化句子级语义表示 , 生成384维稠密向量 , 适合直接计算余弦相似度 , 如 : all-MiniLM-L6-v2 ;
from llama_index.embeddings.langchain import LangchainEmbedding
from langchain.embeddings import HuggingFaceEmbeddings
lc_embed = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={"device": "cuda"}
)
Settings.embed_model = LangchainEmbedding(lc_embed)
- Ollama 托管模型 : 通过本地 Ollama 服务托管模型 , 将模型权重、配置和依赖封装为标准化包 , 自动管理GPU/CPU资源分配 , 支持动态量化 ( 如4-bit压缩 ) 以降低显存占用 ;
from llama_index.embeddings.ollama import OllamaEmbedding
Settings.embed_model = OllamaEmbedding(
model_name="nomic-embed-text",
base_url="http://localhost:11434",
ollama_additional_kwargs={"num_ctx": 4096} # 上下文窗口扩展
)
3、适配器微调模型 AdapterEmbeddingModel
EmbeddingAdapterFinetuneEngine 是一种 结合 嵌入(Embedding) 和 微调(Fine-tuning) 技术的引擎 , 主要用于优化语义搜索和特定任务适配 ;
EmbeddingAdapterFinetuneEngine 引擎用于 微调适配 任务 , 在预训练模型(如GPT-3)顶层添加轻量级适配层,针对特定任务(如财税问答)调整参数,避免全参数微调的高成本 ;
微调流程 : 下面的微调操作 是 在 BAAI/bge-base-en 预训练模型 的基础上 , 加载 特定领域的数据 作为训练数据 , 用于将该模型 微调为 特定领域的 模型 ;
微调完成后 , 将 微调结果 保存到 medical_adapter 模型中 ;
微调后的效果 可以 使 新模型 在 特定领域 有更好的性能 , 如 : 眼科诊断准确率提升 20% ;
from llama_index.finetuning.embeddings.adapter import EmbeddingAdapterFinetuneEngine
# 准备领域数据(示例:医疗文本)
train_docs = load_medical_reports()
val_docs = load_clinical_notes()
# 初始化微调引擎
finetune_engine = EmbeddingAdapterFinetuneEngine(
base_model=HuggingFaceEmbedding("BAAI/bge-base-en"),
train_dataset=train_docs,
output_dir="med_adapter",
output_dim=512, # 扩展向量维度
epochs=10,
batch_size=32
)
# 执行微调并保存
finetune_engine.finetune()
finetune_engine.save("medical_adapter")
在 LlamaIndex 框架中 , 使用上述 适配微调模型 作为 嵌入模型 ;
from llama_index.embeddings.adapter import AdapterEmbeddingModel
adapter_model = AdapterEmbeddingModel(
base_embed_model=HuggingFaceEmbedding("BAAI/bge-base-en"),
adapter_path="medical_adapter"
)
Settings.embed_model = adapter_model
4、混合部署 嵌入模型
LlamaIndex 混合 嵌入模型 部署 , 核心原理 是 按数据敏感度自动选择本地或云端模型 , 平衡隐私与成本 ,
- 敏感数据用本地模型 , 如 : BAAI/bge-base-en , 离线运行 ;
- 非敏感数据用 OpenAI 云端 API , 成本较低 ;
下面的代码中 , 自动判断 数据的敏感性 , 如果是敏感数据 使用本地部署的 HuggingFace 嵌入模型 , 非敏感数据使用 OpenAI 云端嵌入模型 ;
# 敏感数据用本地模型
local_embed = HuggingFaceEmbedding(model_name="BAAI/bge-base-en")
# 非敏感数据用OpenAI
cloud_embed = OpenAIEmbedding()
# 智能路由
from llama_index.embeddings import RouterEmbedding
router_embed = RouterEmbedding(
routes=[
(lambda x: "机密" not in x.text, local_embed),
(lambda x: True, cloud_embed)
]
)
Settings.embed_model = router_embed
5、完整代码示例
首先 , 安装必要的 软件包 , 执行如下命令 , 安装 Hugging Face 相关软件包 ;
pip install llama-index-core llama-index-llms-openai llama-index-embeddings-huggingface sentence-transformers
然后 , 设置 Hugging Face 镜像 , 国内无法访问 , 注意 下面两行代码必须写在 Python 代码的第一行 ;
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 设置Hugging Face模型的下载镜像地址,核心配置用于加速模型下载
最后 , 为 LlamaIndex 框架配置 HuggingFace 本地部署的 向量模型 BAAI/bge-large-zh-v1.5 , 通过 cache_folder=“./models” 指定向量本地部署位置为 本代码层级目录的 models 目录下 ;
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-large-zh-v1.5", # 指定中文嵌入模型
cache_folder="./models", # 模型缓存目录(自动从镜像站下载)
)
完整代码示例 :
# 安装必要库(LlamaIndex核心框架)
# pip install llama-index-core llama-index-llms-openai llama-index-embeddings-huggingface sentence-transformers
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 设置Hugging Face模型的下载镜像地址,核心配置用于加速模型下载
# 导入核心模块
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings # 索引构建/文档加载/全局配置
from llama_index.llms.openai import OpenAI # 大语言模型模块
from llama_index.embeddings.huggingface import HuggingFaceEmbedding # Hugging Face 嵌入模型
# 配置第三方 OpenAI 兼容服务(核心设置)
Settings.llm = OpenAI(
api_key="sk-i3dHqZygiMb0bQ132c4c602aC2714b8e8cE9A919E7757aF7", # 中转服务商提供的API密钥(重要:需保密!)
api_base="https://xiaoai.plus/v1", # 替换为第三方API网关地址
model="gpt-3.5-turbo", # 需与服务商支持的模型名称一致
temperature=0.1 # 控制输出随机性(0-1,值越小答案越确定)
)
# 配置嵌入模型使用同一个服务商(文档向量化)
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-large-zh-v1.5", # 指定中文嵌入模型
cache_folder="./models", # 模型缓存目录(自动从镜像站下载)
)
# 加载文档(本地文档预处理)
documents = SimpleDirectoryReader("data").load_data() # 读取data文件夹内所有文档
# 创建索引(文档向量化存储)
index = VectorStoreIndex.from_documents(documents) # 自动调用embed_model生成向量
# 创建查询引擎(问答接口封装)
query_engine = index.as_query_engine() # 组合索引与LLM的问答系统
# 执行查询(语义搜索+LLM生成)
response = query_engine.query("文档中的主要观点是什么?并介绍下单纯形法步骤?使用中文回复,分行解析") # 自动检索相关段落并生成答案
print(response) # 输出结构化响应对象
执行结果 :
- 终端打印信息 :
文档的主要观点是介绍单纯形法在运筹学中的应用,特别是如何通过该方法求解线性规划问题。
单纯形法的步骤如下:
1. **初始基可行解**:首先需要找到一个初始的基可行解,这是进行后续步骤的基础。
2. **判定是否最优解**:使用一个准则来判断当前的基可行解是否为最优解,这是单纯形法的核心问题。
3. **是最优解**:如果当前的基可行解是最优解,则结束迭代过程。
4. **不是最优解**:如果当前的基可行解不是最优解,则需要迭代到下一个基可行解,并继续判定是否为最优解。此过程也需要一个准则来指导如何进行迭代。
在这个过程中,涉及到两个重要的准则:一个是判断基可行解是否为最优解,另一个是如何从一个基可行解迭代到下一个基可行解。
- PyCharm 执行结果 :
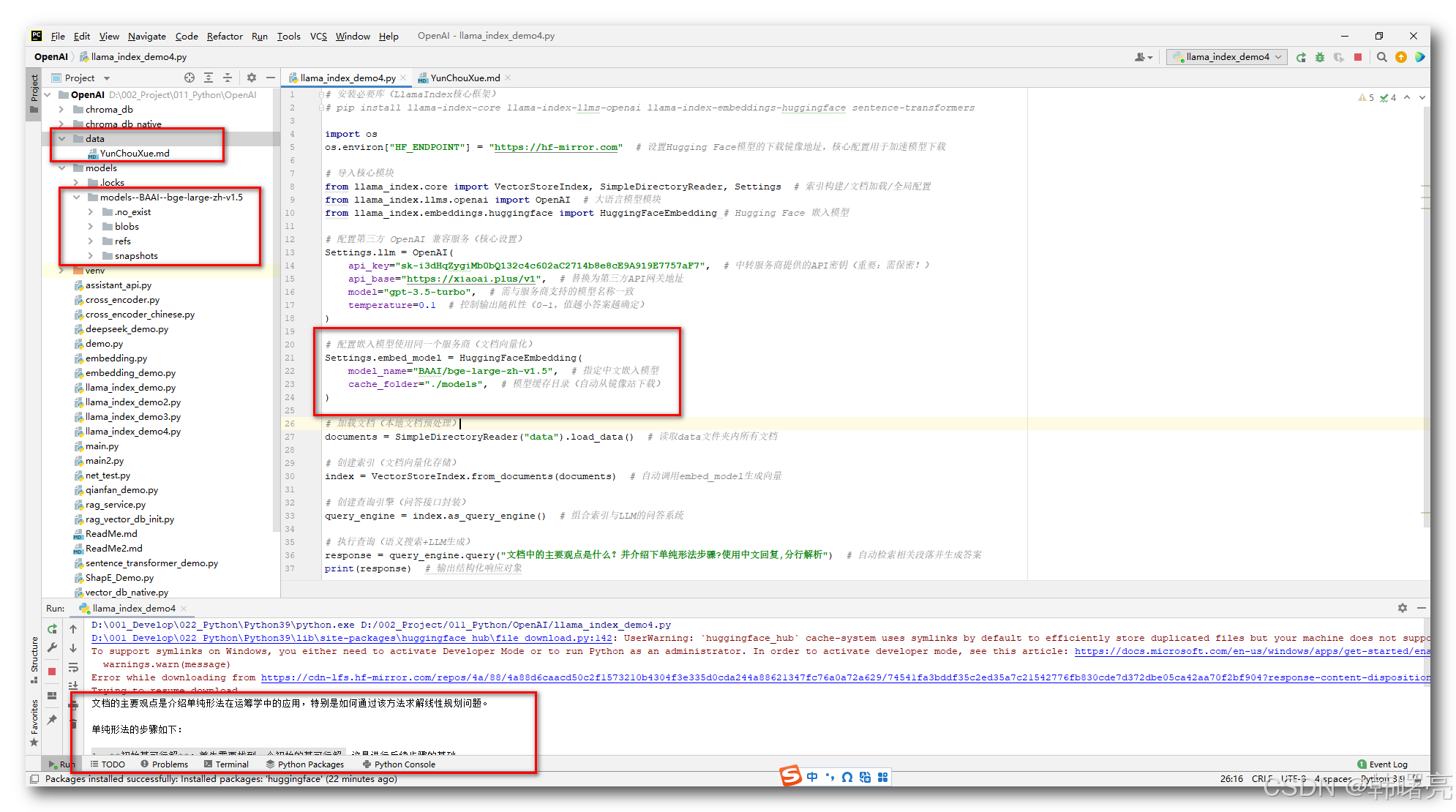
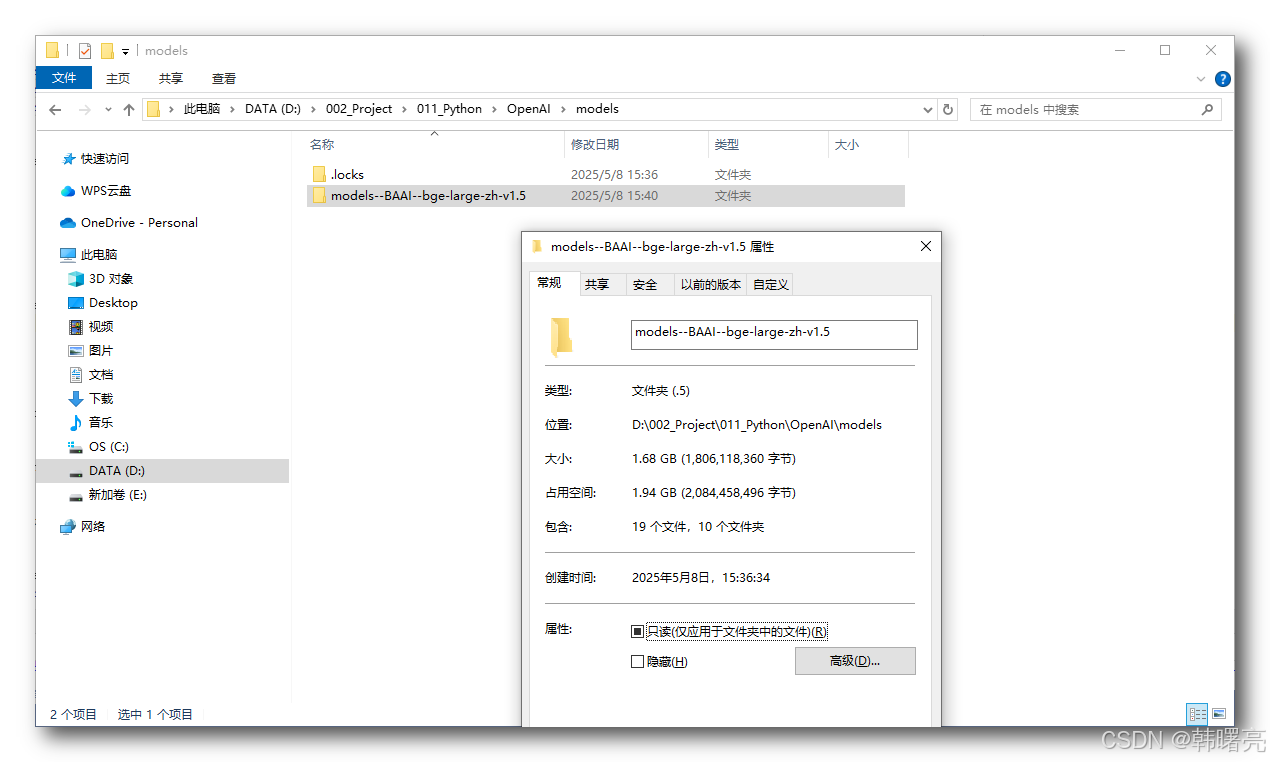
- 模型本地部署位置 : BAAI/bge-large-zh-v1.5 模型被下载到了 models\models–BAAI–bge-large-zh-v1.5 目录中 , 下载了 1.68GB 左右的模型数据 ;

















 1219
1219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









