







目录
1. 生成式模型的基本介绍
2. 扩散模型原理
3. DDPM源码解析
4. 资料
一、生成式模型的基本介绍
生成模型(Generative Model)是机器学习领域的一个重要分支,用于从训练数据中学习数据的概率分布,从而生成新的、与训练数据相似的数据。它的目标是通过学习训练数据的分布 ( p(x) ),来生成逼真的样本。在生成任务中,我们见证了多种模型的崛起与发展,从早期的变分自编码器(VAE)到风靡一时的生成对抗网络(GAN),再到近年来表现突出的扩散模型(Diffusion Model),这些模型对比如下图所示
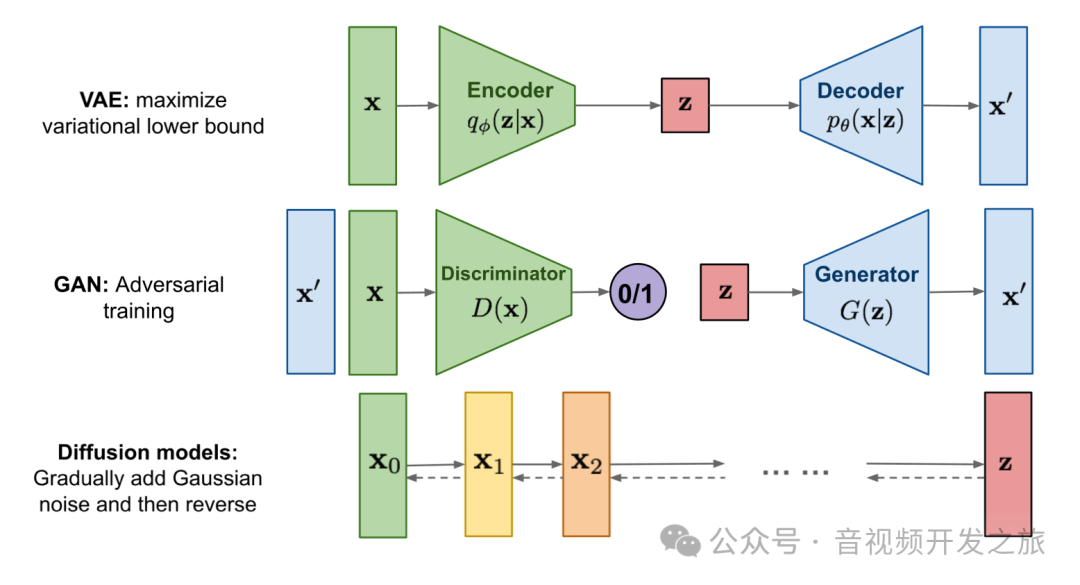
1.1 变分自编码器(VAE)
VAE 是生成模型中较早出现的模型之一,由 Kingma 和 Welling 于 2013 年提出。VAE 的基本思想是通过将输入数据编码到一个符合高斯分布的低维的潜在空间(Latent Space)中,并从中进行采样,然后通过解码器将采样值映射回数据空间,从而生成新的数据。
VAE生成的样本往往显得比较模糊,缺乏细节,这是由于 VAE 在采样时引入了随机性,导致解码器生成的图像缺乏高频细节
1.2 生成对抗网络(GAN)
GAN 由 Ian Goodfellow 等人在 2014 年提出,作为生成模型的一个突破性创新,GAN 不同于传统生成模型的最大特点是通过一个对抗训练过程来生成高质量的数据样本。GAN 包含两个神经网络,生成器(Generator) 和 判别器(Discriminator)。生成器负责从随机噪声中生成伪造样本,试图“欺骗”判别器;而判别器则试图区分真实样本(GroundTruth)和伪造样本。两者通过一个博弈过程相互对抗,直到生成器能够生成足以“欺骗”判别器的逼真样本。
GAN 在生成任务中的效果极为突出,尤其在图像生成任务中,生成的图像往往具有高度的逼真性和细节。但也存在训练不稳定 难以收敛的问题:GAN 的训练过程非常不稳定,生成器和判别器之间的对抗往往容易失衡,很多情况下很难找到一个稳定的最优点,导致模型出现模式崩溃(Mode Collapse),即生成器只生成少量不同类型的样本,忽略了数据分布的多样性,且生成的样本质量不稳定。
1.3 扩散模型(Diffusion Model)
Diffusion Model 是近年来生成模型中的新兴技术,在图像生成、文本生成、音频生成等领域大放异彩。扩散模型的工作原理与 GAN 和 VAE 有显著不同,它通过逐步破坏和重构数据来生成样本,灵感来自于物理学中的扩散过程。
Diffusion Model的工作流程可以分为两个阶段:前向扩散过程和反向去噪过程。
前向扩散过程:是一个逐步加噪的过程,在每一个时间步中,模型对数据 ( x_0 ) 添加少量噪声,逐步将数据扰动为纯噪声数据 ( x_T )
反向去噪过程:通过训练一个神经网络来学习如何逆向地去除噪声,即从纯噪声 ( x_T ) 逐步去噪,直到恢复到原始数据分布。
训练扩散模型时,学习目标是预测噪声,通过和添加的噪声进行比较,逐步优化模型参数
Diffusion Model的特点:
-
生成质量高:扩散模型的生成过程通过逐步去噪的方式生成数据,使得模型可以生成非常高质量的样本。其生成的图像通常具有高度的细节保留和自然感,克服了 VAE 生成样本模糊的问题。
-
稳定训练:扩散模型在训练过程中不会像 GAN 那样不稳定。由于模型的损失函数设计直接从噪声与数据的匹配度出发,训练过程更加稳定,极少出现模式崩溃现象。
-
多样性和控制性:扩散模型能够很好地保留数据分布的多样性,并且通过调整噪声水平等参数,模型可以控制生成图像的模糊程度和特性,增强了生成过程的可控性。
Diffusion Model的不足:
-
计算开销大:扩散模型的生成过程需要多步迭代,通常比 GAN 和 VAE 的生成过程耗时更长,计算资源消耗也更大。
-
复杂的参数调试:尽管扩散模型的训练过程较为稳定,但要获得最佳的生成效果,模型的超参数(如噪声步数、噪声强度等)需要进行复杂的调试。
从 VAE 到 GAN,再到Diffusion Model,生成模型经历了逐步发展的过程,每种模型都有其独特的优势和应用场景。然而,扩散模型凭借其卓越的生成质量和稳定的训练过程,受到了学术界和工业界的广泛关注,已成为生成领域的前沿技术。尽管其计算成本较高,但随着技术的进步和优化,扩散模型有望在未来的生成任务中继续大放异彩。
下面我们基于DDPM(论文地址:https://arxiv.org/pdf/2006.11239)一起学习下扩散模型的原理,并对其实现源码(源码地址:https://github.com/zoubohao/DenoisingDiffusionProbabilityModel-ddpm-)进行分析
二、扩散模型的原理
2.1 扩散模型是如何工作的
扩散模型包含两个过程,前向过程(Forward Process)和反向过程(Reverse Process)
数据从初始状态X_0(右侧的清晰图像)逐步加如噪声至最终状态X_T(随机的噪声图像),通过模型反向逐步降噪,最终还原初始数据
前向过程: 用虚线箭头表示的q(x_t∣x_t−1)表示的是 从时间步t-1到时间步t,加入噪声的过程,随着t的增加,图像会逐渐加入更多噪声
反向过程:用实线箭头表示的pθ(x_t−1∣x_t)表示的是 对噪声图像逐步去噪还原原始清晰图像的过程.
模型的目标是通过学习Pθ来逐步去除噪声,从而还原时间步X_0(原始清晰图像)
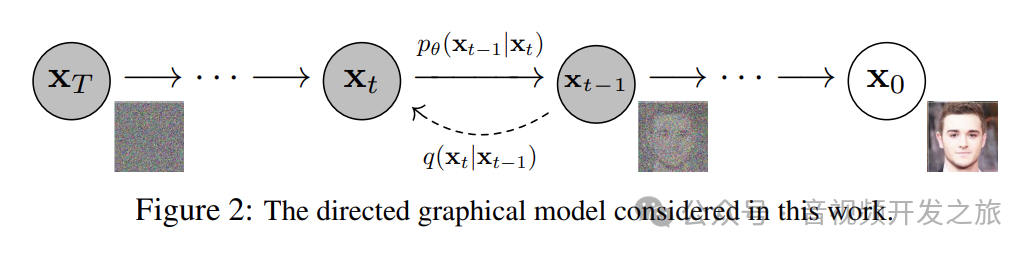
图片来自:论文DDPM
具体实现上采样U-Net网络进行模型的训练,训练的目的是学习预测噪声的能力.
2.1.1 训练过程
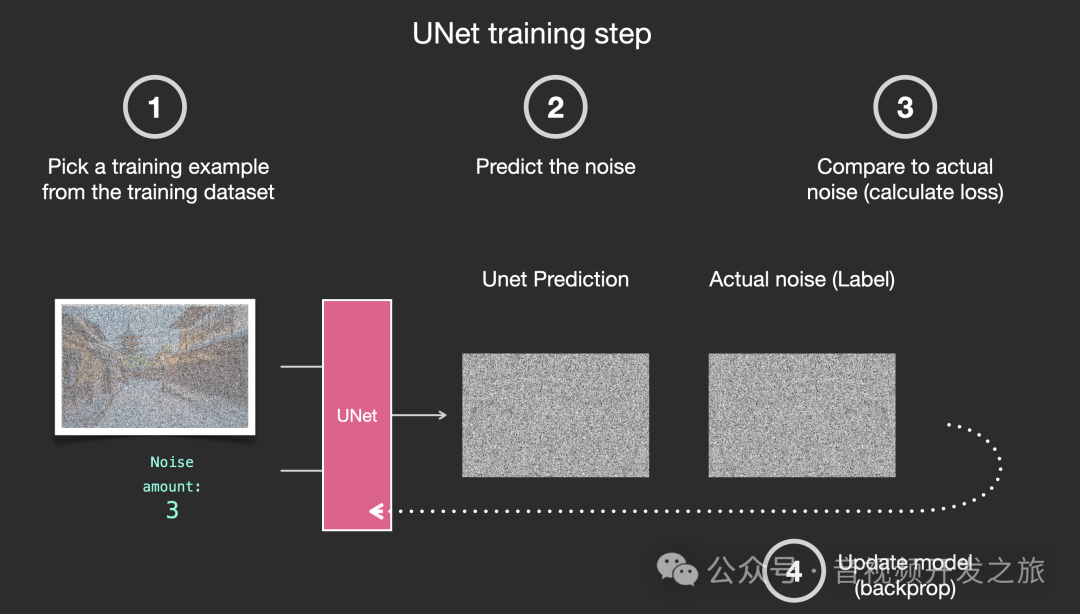
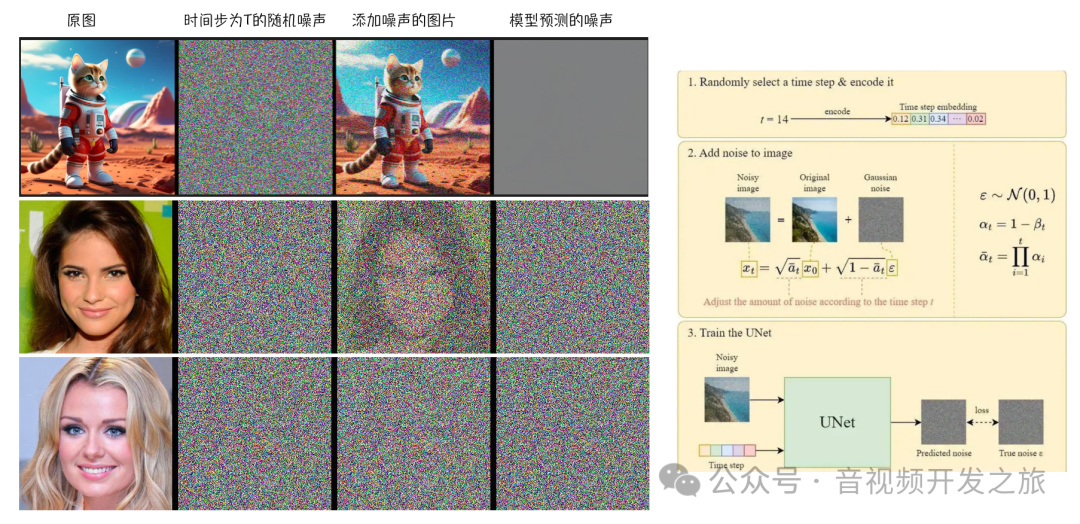
假设我们有一张图片,生成一些不同强度的随机噪声,然后选择某个等级强度的噪声 添加到图像中,把原始图片 噪声等级 作为训练的样本DATASET


有个这个数据集我们就可以训练噪声预测器,流程如下所示:
1. 从数据集中随机选择一个样本(包含 原图 噪声等级 添加噪声后的图片)
2. 使用U-Net模型进行预测噪声
3. 预测的噪声和输入的真实噪声(GroundTruth)进行计算loss
4. 反向传播更新U-Net模型权重
对大量的数据集经过多轮次训练 不断重复上述步骤,直到得到一个很好的噪声预测器
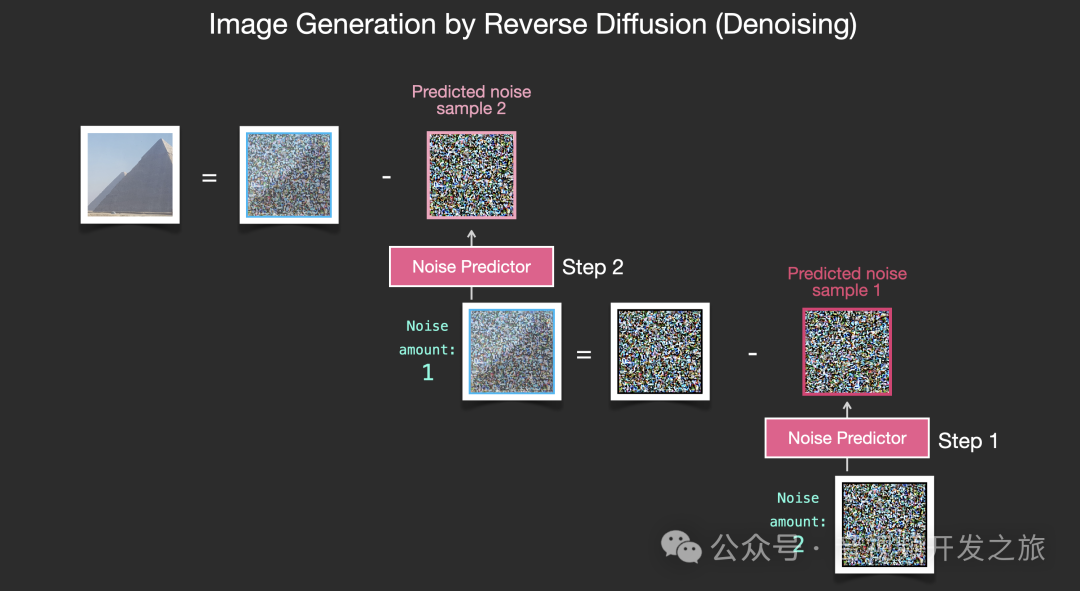
2.1.2 去噪过程
1. 首先根据噪声强度(可以理解为时间步数)生成符合对应的随机噪声
2. 使用噪声预测器,进行预测噪声
3. 把第一步的随机噪声减去 第2步预测的随机噪声 得到经过一步去噪的图片.
4. 再上一步得到的图片输入到噪声预测器进行预测噪声
重复步骤3和步骤4, 从Z_T到Z_0 得到去噪的图片
2.2 两个重要的特性
2.2.1. 扩散过程的一个重要特性:X_T可以看成原始数据X_0和随机噪声ϵ的线性组合
前向扩散过程是往图片上加噪声的过程, 给定真实图像X_0, 通过T次累计添加高斯噪声,得到,X_1,X_2,...X_T, 构建训练样本GT
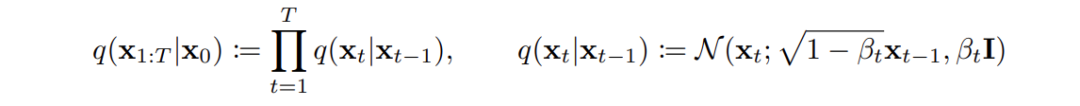
推导过程过下

2.2.2. 去噪过程用到了另个一个重要trick:重参数(reparameterizatio trick)
反向去噪过程是从一个随机噪声开始,逐渐去噪生成一个真实的样本
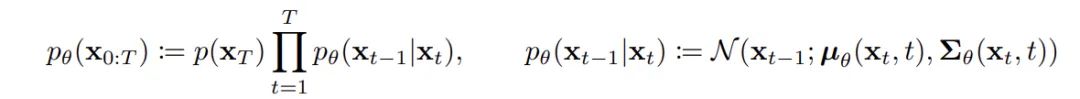
DDPM中存在多个从高斯分布随机采样的环节, 但是这个过程本身是不可导的,使用重参数技巧使其可导,通常的做法是通过一个独立的随机变量ϵ处理.比如从高斯分布中采样一个z,公式如下,z满足高斯分布,并且通过ϵ保留随机性, 这样整个采样过程就可导了
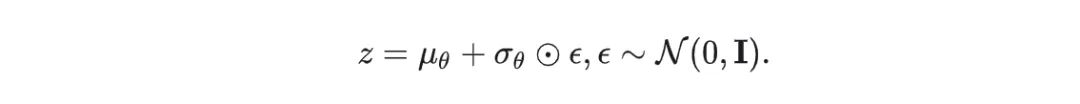
2.3 模型设计
扩散模型的核心在于训练噪声预测模型. DDPM采用基于residual block和attention block的U-Net模型
U-Net是2015提出的一个用于图像分割任务的模型,结构上包含编码器(下采样路径)和解码器(上采样路径),形状呈现U型,因此得名U-Net.
编码器(下采样路径):通过连续的卷积层和池化层降低空间维度,同时增加特征通道数
解码器(上采样路径):这部分是编码器的逆过程,通过上采样和卷积操作回复图像的空间维度,同时减少特征通道数.在每一步上采样后,通过跳跃连接(Skip Connection)将编码器对应层级的特征图和解码器当前层级的特征图进行拼接,这样可以保留更多的空间和寓意信息.
这种Encoder-Decoder结构具有很强的兼容行,让U-Net不管是在分割领域还是在生成领域,都能和Transformer等新生代模型很好的融合.
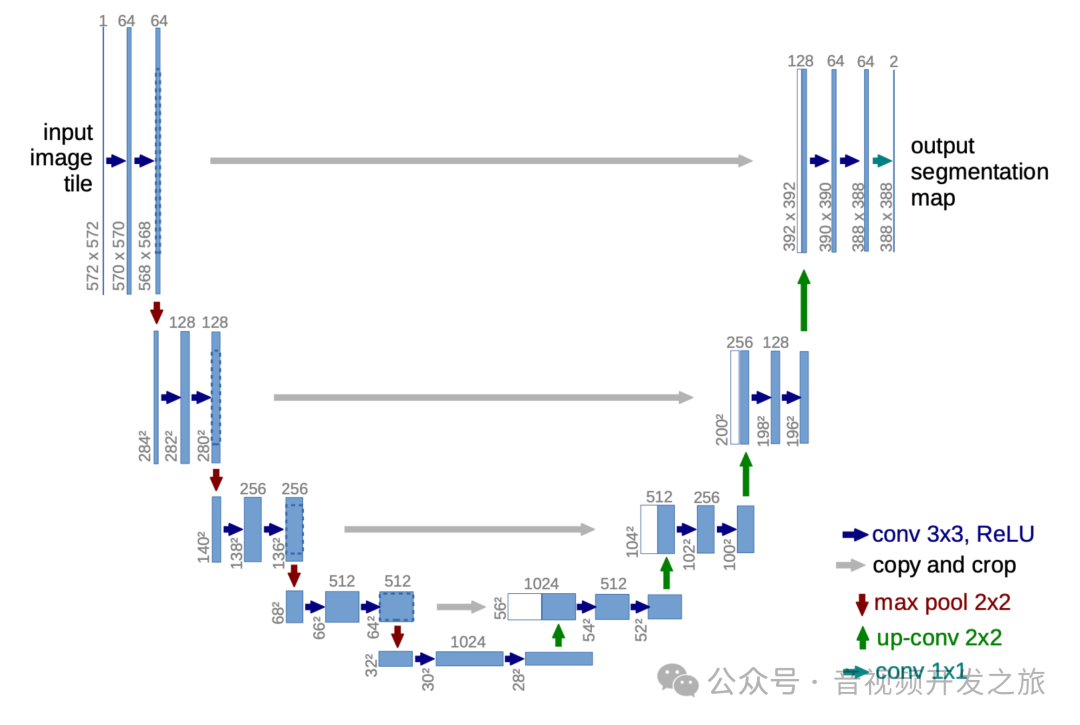
DDPM中的UNet,整体结构遵循UNet经典的U形结构,有下采样-上采样模块,采用基于residual block和attention block组成每个上下采样层
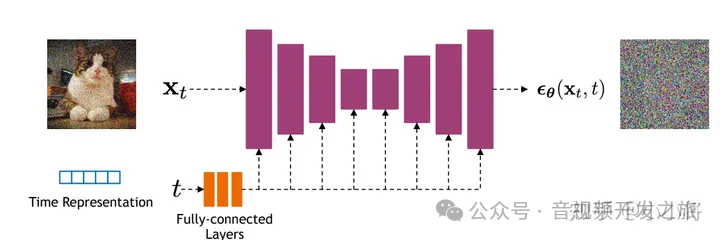
图片来自:扩散模型之DDPM
整体流程如下:
1. 时间嵌入TimeEmbedding:将时间步骤t映射到高维空间. 这个时间嵌入在整个网络中被用来调节每个ResBlock,使得网络能够根据不同的去噪步骤进行调节
2. head头部模块:输入rgb通道的图像机型特征提取为ch通道;
3. 下采样: 使用resblock和downblocks组成的下采样模块 进行多次下采样和特征提取. 其中ResBlock:包含两个卷积块,每个块前有GroupNorm和Swish激活. 包含时间嵌入TimeEmbedding,包含可选的注意力机制模块AttenBlock
4. 中间块:middleblocks,包含两个ResBlock,其中第一个带注意力机制. 这部分的功能是在最低分辨率上处理特征,捕获全局信息
5. 上采样:upblocks:采用最近临近插值后接卷积,逐步增加特征图的空间分辨率,每个upblock模块也包含多个ResBlock, 使用跳跃链接(skip connections)将对应的下采样特征与上采样特征进行连接起来
6. tail尾部模块,使用组归一化 Swish激活函数以及一个3x3的卷积层将特征映射回3通道 并最终输出
三、源码解析
主要是实现下面两个算法

下面我们从 扩散训练器GaussianDiffusionTrainer, 扩散采样/推理器GaussianDiffusionSampler和U-Net网络网络详细分析下代码实现
3.1 扩散训练器
class GaussianDiffusionTrainer(nn.Module):#model是Unet网络; "beta_1": 1e-4; "beta_T": 0.02; "T": 1000def __init__(self, model, beta_1, beta_T, T):super().__init__()self.model = modelself.T = T#torch.linspace(beta_1, beta_T, T),生成等差数列用于定义每个时间步的噪声水平.# beta_1:序列起始值,通常设置的比较小:1e-4; 表示扩散过程开始阶段,噪声水平比较低# beta_T:序列的结束值,通常设置比较大:0.02,表示扩展过程中最后阶段噪声水平较高# T ,1000: 表示扩散过程的总时间步数#register_buffer,把生成的等差数列注册为一个buffer,这样不会优化器优化self.register_buffer('betas', torch.linspace(beta_1, beta_T, T).double())alphas = 1. - self.betas#torch.cumprod 计算alphas的累积乘积alphas_bar = torch.cumprod(alphas, dim=0)# calculations for diffusion q(x_t | x_{t-1}) and othersself.register_buffer('sqrt_alphas_bar', torch.sqrt(alphas_bar))self.register_buffer('sqrt_one_minus_alphas_bar', torch.sqrt(1. - alphas_bar))def forward(self, x_0):"""Algorithm 1."""#生成一个随机范围在[0,1000]且与输入张量x_0有相同的批次大小的整数张量t,#shape:torch.Size([1, 3, 768, 768]) #x_0.shape[0]为batch_size 值为1,例如生成如下的张量t"""eg t 如下tensor([643])或者tensor([355])"""t = torch.randint(self.T, size=(x_0.shape[0], ), device=x_0.device)#生成随机噪声noise = torch.randn_like(x_0)#加噪后的图片,用于输入给mode进行预测噪声,和输入的噪声计算lossx_t = (extract(self.sqrt_alphas_bar, t, x_0.shape) * x_0 +extract(self.sqrt_one_minus_alphas_bar, t, x_0.shape) * noise)#可视化逐步加噪的过程,这里加噪不是想像中的逐步加噪,而是一步完成save_path = '/data4/yabin/project/thirdparty/DenoisingDiffusionProbabilityModel-ddpm--main/SampledImgs/trainstep'curtime =time.time()print(f"t.cpu:{t.cpu()}")predictNoise = self.model(x_t, t)save_horizontally_concatenated_images(x_0, noise, torch.clip(x_t, -1, 1),predictNoise, save_path, f'{curtime}_concat.png')#计算self.model(x_t, t)推理的噪声图 和GT的噪声之间的额lossloss = F.mse_loss(self.model(x_t, t), noise, reduction='none')return lossdef extract(v, t, x_shape):"""Extract some coefficients at specified timesteps, then reshape to[batch_size, 1, 1, 1, 1, ...] for broadcasting purposes."""device = t.deviceout = torch.gather(v, index=t, dim=0).float().to(device)return out.view([t.shape[0]] + [1] * (len(x_shape) - 1))
3.2 扩散推理器
采用从T到0的逆向过程,与训练的正向过程相反,模型试图从添加了噪声的数据中恢复出原始的信号,这个过程通常被看作是一个马尔可夫链,每一步都是基于前一步的信息来噪声预测, UNet模型在每一步预测噪声,而不是直接预测图像
具体过程:从纯噪声x_T开始。逐步从T-1到0进行反向扩散:
a. 计算当前时间步的均值和方差。
b. 如果不是最后一步,添加缩放的高斯噪声。
c. 使用重参数化技巧生成新的样本。
最后,将生成的图像剪裁到[-1, 1]范围内。
class GaussianDiffusionSampler(nn.Module):#model是Unet网络; "beta_1": 1e-4; "beta_T": 0.02; "T": 1000 ,同GaussianDiffusionTrainerdef __init__(self, model, beta_1, beta_T, T):super().__init__()self.model = modelself.T = Tself.register_buffer('betas', torch.linspace(beta_1, beta_T, T).double())alphas = 1. - self.betasalphas_bar = torch.cumprod(alphas, dim=0)alphas_bar_prev = F.pad(alphas_bar, [1, 0], value=1)[:T]self.register_buffer('coeff1', torch.sqrt(1. / alphas))self.register_buffer('coeff2', self.coeff1 * (1. - alphas) / torch.sqrt(1. - alphas_bar))self.register_buffer('posterior_var', self.betas * (1. - alphas_bar_prev) / (1. - alphas_bar))def predict_xt_prev_mean_from_eps(self, x_t, t, eps):assert x_t.shape == eps.shapereturn (extract(self.coeff1, t, x_t.shape) * x_t -extract(self.coeff2, t, x_t.shape) * eps)def p_mean_variance(self, x_t, t):# below: only log_variance is used in the KL computationsvar = torch.cat([self.posterior_var[1:2], self.betas[1:]])var = extract(var, t, x_t.shape)eps = self.model(x_t, t)xt_prev_mean = self.predict_xt_prev_mean_from_eps(x_t, t, eps=eps)return xt_prev_mean, var"""逆向的过程,采用从T到0的逆向过程,与训练的正向过程相反,模型试图从添加了噪声的数据中恢复出原始的信号,这个过程通常被看作是一个马尔可夫链,每一步都是基于前一步的信息来预测的噪声预测,UNet模型在每一步预测噪声,而不是直接预测图像具体过程:从纯噪声x_T开始。逐步从T-1到0进行反向扩散:a. 计算当前时间步的均值和方差。b. 如果不是最后一步,添加缩放的高斯噪声。c. 使用重参数化技巧生成新的样本。最后,将生成的图像剪裁到[-1, 1]范围内。"""def forward(self, x_T):"""Algorithm 2."""x_t = x_T#逆向去噪for time_step in reversed(range(self.T)):print(time_step)t = x_t.new_ones([x_T.shape[0], ], dtype=torch.long) * time_step#计算当前时间步的均值和方差mean, var= self.p_mean_variance(x_t=x_t, t=t)# no noise when t == 0if time_step > 0:noise = torch.randn_like(x_t)else:noise = 0#如果不是最后一步,添加缩放的随机高斯噪声#这里的mean是模型预测的结果, 加上随机噪声 为了模拟在逆向过程中的不确定性 有助于生成更多样化和真实的数据样本。x_t = mean + torch.sqrt(var) * noiseassert torch.isnan(x_t).int().sum() == 0, "nan in tensor."# Save intermediate result#可视化逐步去噪的过程save_path = 'DenoisingDiffusionProbabilityModel-ddpm--main/SampledImgs/sampletstep'if (self.T - time_step) % (self.T // 10) == 0 or time_step == 0:save_image(torch.clip(x_t, -1, 1),os.path.join(save_path, f'sample_step_{self.T - time_step:04d}.png'),normalize=True,value_range=(-1, 1))x_0 = x_treturn torch.clip(x_0, -1, 1)

3.3 U-Net网络
3.3.1 时间Embedding
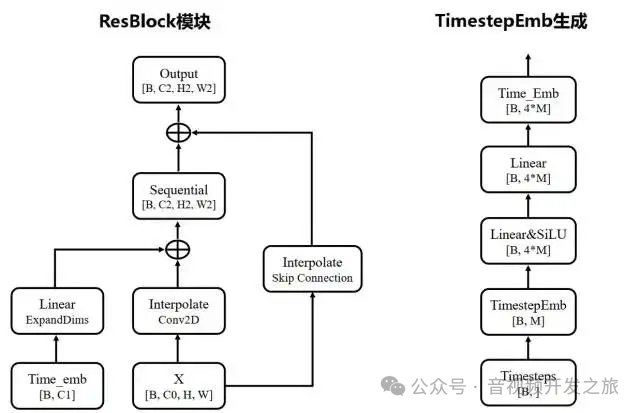
class TimeEmbedding(nn.Module):#时间步数T:1000, 输入的维度d_model:128, 输出的维度dim:512def __init__(self, T, d_model, dim):assert d_model % 2 == 0super().__init__()#实现了类似于Transformer的位置编码,创建一个长度为d_model/2的向量,应用对数和指数,使得值在0到1之间.emb = torch.arange(0, d_model, step=2) / d_model * math.log(10000)emb = torch.exp(-emb)#生成时间步pos,从0到T-1的序列pos = torch.arange(T).float()#通过将时间步和emb相乘,得到形状为[T,d_model//2]的时间嵌入矩阵emb = pos[:, None] * emb[None, :]assert list(emb.shape) == [T, d_model // 2]#对每个元素应用sin和cos进行堆叠重塑为[T,d_model]的矩阵emb = torch.stack([torch.sin(emb), torch.cos(emb)], dim=-1)assert list(emb.shape) == [T, d_model // 2, 2]emb = emb.view(T, d_model)#创建嵌入层和MLP(有两个线性层,中间一个swish激活函数),将输出的维度从d_model(128)扩展到dim(512)self.timembedding = nn.Sequential(nn.Embedding.from_pretrained(emb),nn.Linear(d_model, dim),Swish(),nn.Linear(dim, dim),)self.initialize()def initialize(self):for module in self.modules():if isinstance(module, nn.Linear):#使用Xavier对网络中的权重进行初始化init.xavier_uniform_(module.weight)init.zeros_(module.bias)#前向传播,输入t,输出对应的嵌入向量def forward(self, t):emb = self.timembedding(t)return emb
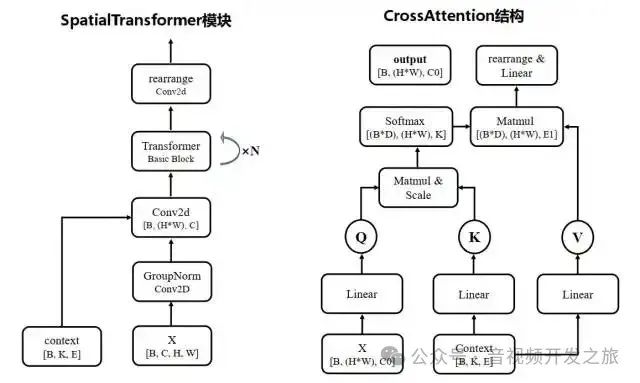
3.3.2 注意力模块 AttnBlock
AttnBlock在U-Net中起着关键的作用,它允许模型捕获全局上下文信息,这对于生成高质量&一致性的图像非常重要,设计上结合自注意力机制的强大能力和卷积神经网络的高效性,使得模型能够在不同尺度上有效的处理图像信息.具体步骤如下:1. 首先使用组归一化,以稳定训练过程2. 使用1x1的卷积生成Q K V矩阵, 1x1卷积保持空间尺寸不变,同时允许跨通道的信息混合3. 计算Q K的注意力权重,应用到V上4. 进行残差连接返回结果,允许网络必要时绕过注意力机制,有助于训练深层网络class AttnBlock(nn.Module):def __init__(self, in_ch):super().__init__()#使用32个组,进行组归一化,使得训练过程更加稳定self.group_norm = nn.GroupNorm(32, in_ch)#用于生成Q K V的1x1卷积,保持空间尺寸不变的情况下,跨通道信息混合self.proj_q = nn.Conv2d(in_ch, in_ch, 1, stride=1, padding=0)self.proj_k = nn.Conv2d(in_ch, in_ch, 1, stride=1, padding=0)self.proj_v = nn.Conv2d(in_ch, in_ch, 1, stride=1, padding=0)#1x1的投影矩阵,进行进一步的特征转换self.proj = nn.Conv2d(in_ch, in_ch, 1, stride=1, padding=0)self.initialize()def initialize(self):for module in [self.proj_q, self.proj_k, self.proj_v, self.proj]:init.xavier_uniform_(module.weight)init.zeros_(module.bias)init.xavier_uniform_(self.proj.weight, gain=1e-5)def forward(self, x):#应用组归一化,生成Q K VB, C, H, W = x.shapeh = self.group_norm(x)q = self.proj_q(h)k = self.proj_k(h)v = self.proj_v(h)#重塑q k,计算注意力权重wq = q.permute(0, 2, 3, 1).view(B, H * W, C)k = k.view(B, C, H * W)w = torch.bmm(q, k) * (int(C) ** (-0.5))assert list(w.shape) == [B, H * W, H * W]w = F.softmax(w, dim=-1)#重塑v,应用注意力权重到v上v = v.permute(0, 2, 3, 1).view(B, H * W, C)h = torch.bmm(w, v)assert list(h.shape) == [B, H * W, C]#重塑结果回原始的空间维度h = h.view(B, H, W, C).permute(0, 3, 1, 2)#最后的1x1投影变化h = self.proj(h)#添加残差连接return x + h
3.3.3 下采样和上采样模块 DownSample UpSample
下采样: 使用卷积核为3x3,步长为2的卷积 进行下采样, 减少特征图的空间尺寸 即wh减半上采样:首先使用最近邻插值将特征图的空间尺寸增加到原来的2倍,再使用卷积核为3x3,步长为1的卷积细化特征增加通道间的交互,结合间的的确定性操作(插值)和可学习的操作(卷积)来获得更好的性能class DownSample(nn.Module):def __init__(self, in_ch):super().__init__()#输入和输出的通道数不变,使用3*3的卷积,步长为2 减少特征图的空间尺寸 即wh减半,进行下采样self.main = nn.Conv2d(in_ch, in_ch, 3, stride=2, padding=1)self.initialize()def initialize(self):init.xavier_uniform_(self.main.weight)init.zeros_(self.main.bias)def forward(self, x, temb):x = self.main(x)return xclass UpSample(nn.Module):def __init__(self, in_ch):super().__init__()#输入和输出的通道数不变,使用3*3的卷积,步长为1 wh不变 进行卷积self.main = nn.Conv2d(in_ch, in_ch, 3, stride=1, padding=1)self.initialize()def initialize(self):init.xavier_uniform_(self.main.weight)init.zeros_(self.main.bias)def forward(self, x, temb):_, _, H, W = x.shape#先采用最近邻插值进行放到2倍x = F.interpolate(x, scale_factor=2, mode='nearest')#再进行卷积操作x = self.main(x)return x
3.3.4 残差模块 ResBlock
U-Net网络中的ResBlock,结合和残差连接 时间嵌入和可选的注意力机制,其中残差连接有助于梯度流动和特征重用,训练更深层的网络,时间嵌入的加入使得网络能够根据去噪步骤调整其行为,而可选的注意力机制则允许捕获长距离依赖.这种设计使得网络能够有效的学习class ResBlock(nn.Module):#in_ch:输入通道;out_ch:输出通道; tdim:时间嵌入;dropout:Dropout比率;attn:是否使用注意力机制def __init__(self, in_ch, out_ch, tdim, dropout, attn=False):super().__init__()#block1 串联 组归一化 Swish激活 3x3卷积.维度从in_ch转变为out_chself.block1 = nn.Sequential(nn.GroupNorm(32, in_ch),Swish(),nn.Conv2d(in_ch, out_ch, 3, stride=1, padding=1),)#时间嵌入投影,将时间嵌入投影到特征空间self.temb_proj = nn.Sequential(Swish(),nn.Linear(tdim, out_ch),)#类似block2,但增加了Dropoutself.block2 = nn.Sequential(nn.GroupNorm(32, out_ch),Swish(),nn.Dropout(dropout),nn.Conv2d(out_ch, out_ch, 3, stride=1, padding=1),)#短路连接,如果输入输出通道数不同,采用1x1卷积调整if in_ch != out_ch:self.shortcut = nn.Conv2d(in_ch, out_ch, 1, stride=1, padding=0)else:self.shortcut = nn.Identity()#可选的注意力模块if attn:self.attn = AttnBlock(out_ch)else:self.attn = nn.Identity()self.initialize()def initialize(self):for module in self.modules():if isinstance(module, (nn.Conv2d, nn.Linear)):init.xavier_uniform_(module.weight)init.zeros_(module.bias)init.xavier_uniform_(self.block2[-1].weight, gain=1e-5)def forward(self, x, temb):h = self.block1(x)h += self.temb_proj(temb)[:, :, None, None]h = self.block2(h)#实现残差结构,允许信息直接流过网络,有助于训练更深的网络h = h + self.shortcut(x)#应用注意力机制h = self.attn(h)return h
3.3.5 Unet网络
这个UNet为扩散模型(Diffusion Model)设计,整体结构遵循UNet经典的U形结构,有下采样-上采样模块组成. 这种结构允许模型在不同尺度上捕获图像特征, 整体流程如下:
1. 时间嵌入TimeEmbedding:将时间步骤t映射到高维空间. 这个时间嵌入在整个网络中被用来调节每个ResBlock,使得网络能够根据不同的去噪步骤进行调节
2. head头部模块:输入rgb通道的图像机型特征提取为ch通道;
3. 下采样: 使用resblock和downblocks组成的下采样模块 进行多次下采样和特征提取. 其中ResBlock:包含两个卷积块,每个块前有GroupNorm和Swish激活. 包含时间嵌入TimeEmbedding,包含可选的注意力机制模块AttenBlock
4. 中间块:middleblocks,包含两个ResBlock,其中第一个带注意力机制. 这部分的功能是在最低分辨率上处理特征,捕获全局信息
5. 上采样:upblocks:采用最近临近插值后接卷积,逐步增加特征图的空间分辨率,每个upblock模块也包含多个ResBlock, 使用跳跃链接(skip connections)将对应的下采样特征与上采样特征进行连接起来
6. tail尾部模块,使用组归一化 Swish激活函数以及一个3x3的卷积层将特征映射回3通道 并最终输出
class UNet(nn.Module):#时间步数T=1000, ch=128, 通道数乘列表ch_mult=[1, 2, 2, 2], attn=[1],每个像素空间大小的残差块数量num_res_blocks=2, dropout=0.1def __init__(self, T, ch, ch_mult, attn, num_res_blocks, dropout):super().__init__()assert all([i < len(ch_mult) for i in attn]), 'attn index out of bound'#时间嵌入的通道数 128*4=512tdim = ch * 4#初始化时间嵌入self.time_embedding = TimeEmbedding(T, ch, tdim)#头部(Head),使用3x3的卷积层,将输入的rgb3通道图像映射为ch(128)通道的特征图self.head = nn.Conv2d(3, ch, kernel_size=3, stride=1, padding=1)#下采样路径 有ResBlock和DownSample模块构建;通道数逐渐增加,空间尺寸逐渐减少;选择性的添加注意力机制self.downblocks = nn.ModuleList()chs = [ch] # record output channel when dowmsample for upsamplenow_ch = chfor i, mult in enumerate(ch_mult):out_ch = ch * multfor _ in range(num_res_blocks):self.downblocks.append(ResBlock(in_ch=now_ch, out_ch=out_ch, tdim=tdim,dropout=dropout, attn=(i in attn)))now_ch = out_chchs.append(now_ch)if i != len(ch_mult) - 1:self.downblocks.append(DownSample(now_ch))chs.append(now_ch)#中间块 有两个ResBlock模块组成,一个有注意力机制,一个没有self.middleblocks = nn.ModuleList([ResBlock(now_ch, now_ch, tdim, dropout, attn=True),ResBlock(now_ch, now_ch, tdim, dropout, attn=False),])#上采样模块 有ResBlock和UpSample模块构建,通道数逐渐减少,空间分辨率逐渐增加self.upblocks = nn.ModuleList()for i, mult in reversed(list(enumerate(ch_mult))):out_ch = ch * multfor _ in range(num_res_blocks + 1):self.upblocks.append(ResBlock(in_ch=chs.pop() + now_ch, out_ch=out_ch, tdim=tdim,dropout=dropout, attn=(i in attn)))now_ch = out_chif i != 0:self.upblocks.append(UpSample(now_ch))assert len(chs) == 0#尾部,使用组归一化 Swish激活函数以及一个3x3的卷积层将特征映射回3通道的输出self.tail = nn.Sequential(nn.GroupNorm(32, now_ch),Swish(),nn.Conv2d(now_ch, 3, 3, stride=1, padding=1))self.initialize()def initialize(self):init.xavier_uniform_(self.head.weight)init.zeros_(self.head.bias)init.xavier_uniform_(self.tail[-1].weight, gain=1e-5)init.zeros_(self.tail[-1].bias)def forward(self, x, t):#首先计算时间嵌入temb = self.time_embedding(t)#进行head模块处理 rgb3通道映射为ch通道h = self.head(x)hs = [h]#然后进行下采样,同时保存中间特征用于后续的跳跃连接for layer in self.downblocks: #len(self.downblocks):11h = layer(h, temb)hs.append(h)#接着处理中间模块 (两个ResBlock,一个有注意力机制,一个没有注意力机制)for layer in self.middleblocks:h = layer(h, temb)#然后进行上采样,每层ResBlock之前先将下采样过程中保存的中间特征进行连接for layer in self.upblocks:if isinstance(layer, ResBlock):h = torch.cat([h, hs.pop()], dim=1)h = layer(h, temb)#最后通过尾部处理 得到最终输出h = self.tail(h)assert len(hs) == 0return h #h.shape: torch.Size([8, 3, 32, 32])
3.4 训练过程
初始化数据集 CIFAR10/celeba_hq_256 或者自定义数据集
初始化UNet网络模型 优化器 迭代器以及 高斯噪声扩散训练器
进行训练,高斯噪声扩散训练器输出的噪声和U-Net模型预测的噪声计算loss,反向传播优化模型权重
def train(modelConfig: Dict):device = torch.device(modelConfig["device"])# 使用的CIFAR10数据集,进行训练,由于该数据集中的图片分辨率32x32很低,可以把训练的batchsize设置比较大eg80# dataset = CIFAR10( #CIFAR10# root='./CIFAR10', train=True, download=True,# transform=transforms.Compose([# transforms.RandomHorizontalFlip(),# transforms.ToTensor(),# transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),# ]))#使用celeba_hq_256数据集,进行训练,由于数据集分辨率较大,在32G显存上batch设置为2dataset = datasets.ImageFolder(root='DenoisingDiffusionProbabilityModel-ddpm--main/celeba_hq_256',transform=transforms.Compose([transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),]))dataloader = DataLoader(dataset, batch_size=modelConfig["batch_size"], shuffle=True, num_workers=4, drop_last=True, pin_memory=True)#构建UNet网络模型net_model = UNet(T=modelConfig["T"], ch=modelConfig["channel"], ch_mult=modelConfig["channel_mult"], attn=modelConfig["attn"],num_res_blocks=modelConfig["num_res_blocks"], dropout=modelConfig["dropout"]).to(device)if modelConfig["training_load_weight"] is not None:net_model.load_state_dict(torch.load(os.path.join(modelConfig["save_weight_dir"], modelConfig["training_load_weight"]), map_location=device))optimizer = torch.optim.AdamW(net_model.parameters(), lr=modelConfig["lr"], weight_decay=1e-4)cosineScheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=modelConfig["epoch"], eta_min=0, last_epoch=-1)#渐进式调度器warmUpScheduler = GradualWarmupScheduler(optimizer=optimizer, multiplier=modelConfig["multiplier"], warm_epoch=modelConfig["epoch"] // 10, after_scheduler=cosineScheduler)#扩散训练器trainer = GaussianDiffusionTrainer(net_model, modelConfig["beta_1"], modelConfig["beta_T"], modelConfig["T"]).to(device)# start trainingfor e in range(modelConfig["epoch"]):with tqdm(dataloader, dynamic_ncols=True) as tqdmDataLoader:for images, labels in tqdmDataLoader:# trainoptimizer.zero_grad()x_0 = images.to(device)loss = trainer(x_0,e).sum() / 1000.loss.backward()torch.nn.utils.clip_grad_norm_(net_model.parameters(), modelConfig["grad_clip"])optimizer.step()tqdmDataLoader.set_postfix(ordered_dict={"epoch": e,"loss: ": loss.item(),"img shape: ": x_0.shape,"LR": optimizer.state_dict()['param_groups'][0]["lr"]})warmUpScheduler.step()torch.save(net_model.state_dict(), os.path.join(modelConfig["save_weight_dir"], 'ckpt_' + str(e) + "_.pt"))
3.5 推理过程
构造UNet网络模型,加载训练好的模型权重
初始化 高斯扩散采样器
生成一个随机噪声,进行推理,从噪声中生成图像
def eval(modelConfig: Dict):# load model and evaluatewith torch.no_grad():device = torch.device(modelConfig["device"])#构造UNet网络模型model = UNet(T=modelConfig["T"], ch=modelConfig["channel"], ch_mult=modelConfig["channel_mult"], attn=modelConfig["attn"],num_res_blocks=modelConfig["num_res_blocks"], dropout=0.)#加载模型权重ckpt = torch.load(os.path.join(modelConfig["save_weight_dir"], modelConfig["test_load_weight"]), map_location=device)model.load_state_dict(ckpt)print("model load weight done.")#设置推理模式model.eval()#初始化samplersampler = GaussianDiffusionSampler(model, modelConfig["beta_1"], modelConfig["beta_T"], modelConfig["T"]).to(device)#创建batch_size为batch_size张 img_size*img_size的rgb 符合标准正态分布(均值为0,标准差为1,取值范围在[-1,1])的随机噪声noisyImage = torch.randn(size=[modelConfig["batch_size"], 3, modelConfig["img_size"], modelConfig["img_size"]], device=device)#对随机噪声进行标准化和约束,使得像素值约束在[0,1]saveNoisy = torch.clamp(noisyImage * 0.5 + 0.5, 0, 1)#torchvision的这个save_image这个功能很好用save_image(saveNoisy, os.path.join(modelConfig["sampled_dir"], modelConfig["sampledNoisyImgName"]), nrow=modelConfig["nrow"])#对图片进行sample,从随机噪声到图片sampledImgs = sampler(noisyImage)sampledImgs = sampledImgs * 0.5 + 0.5 # [0 ~ 1]save_image(sampledImgs, os.path.join(modelConfig["sampled_dir"], modelConfig["sampledImgName"]), nrow=modelConfig["nrow"])
四、资料
1. DDPM论文: https://arxiv.org/pdf/2006.11239
2. DDPM源码:https://github.com/zoubohao/DenoisingDiffusionProbabilityModel-ddpm-
3. latent-diffusion论文:https://arxiv.org/pdf/2112.10752
latent-diffusion源码: https://github.com/CompVis/latent-diffusion
4. The Illustrated Stable Diffusion:https://jalammar.github.io/illustrated-stable-diffusion/
5. What are Diffusion Models?:https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
6. 扩散模型之DDPM: https://zhuanlan.zhihu.com/p/563661713
7. 由浅入深了解Diffusion https://zhuanlan.zhihu.com/p/525106459
8. AIGC爆火的背后——扩散模型DDPM浅析: https://zhuanlan.zhihu.com/p/590840909
9. 生成扩散模型漫谈(一):https://zhuanlan.zhihu.com/p/535042237
10. 超详细的扩散模型(Diffusion Models)原理+代码https://zhuanlan.zhihu.com/p/624221952
11. 深入浅出完整解析Stable Diffusion(SD)核心基础知识 https://zhuanlan.zhihu.com/p/632809634
感谢你的阅读
接下来我们继续学习输出AI相关内容,欢迎关注公众号“音视频开发之旅”,一起学习成长。
欢迎交流

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









