







在之前,我已经在豆瓣电影top250中爬取了约6w条好评和差评,在此我们来利用这些数据,进行入门级别的文本分类。
一 数据清洗
数据在豆瓣电影top250提供下载,下载后能看到6W条好评和差评,由于爬取时未能完全清除符号,导致一部分毫无意义的颜文字评论混入其中,为了清除这些数据,我在(仅当数据量较小的情况下)excel中替换掉了肉眼可见的一些符号,然后转换成xlsx格式(csv中出现中文时bug太多,在此放弃使用csv格式)。如果数据量较大时,请使用正则表达式进行数据清洗。
二 数据的读取与分词
在此提供清洗完毕的数据下载,您可以下载后自行尝试。
使用xlrd库进行xlsx文件的读取,读取完毕后使用jieba分词工具进行分词。
import numpy as np
import pandas as pd
import re
import jieba
import xlrd
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from nltk.tokenize import word_tokenize
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from nltk.corpus import stopwords
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
# 载入数据
# 从Excel文件中读取出Book对象,并定位到sheet1,也就是具体的数据
douban_data_input = xlrd.open_workbook(r"./douban_xlsx.xlsx").sheet_by_index(0)
douban_data = [[0 for i in range(2)] for j in range(douban_data_input.nrows)]
for i in range(douban_data_input.nrows):
douban_data[i][0] = bool(douban_data_input.cell_value(rowx=i, colx=0))
str = douban_data_input.cell_value(rowx=i, colx=1)
douban_data[i][1] = " ".join(jieba.cut(str, cut_all=False, HMM=True))
三 数据的TF-IDF计算
TF-IDF可以将一段文字映射到多维向量空间中,具体的解释请参见《数学之美》(吴军 著)P104开始的TF-IDF解释。
总的来说,就是把一段话的每个词都配之以重要性指标,某个词在这段话的出现次数多时,它就更重要。比如一段话中提到了三次“中国”,就比另一段只提到了一次的重要。
此外,当这个词在所有话中出现的次数多时(比如“苹果”,“乔布斯”等不常见词),这个词就更加的重要;当这个词在所有的段落中出现次数都多时(比如“的”,“这”等常见词),这个词的重要性下降。
对于每个词都计算这样的重要性并写成一个向量后,映射就完成了。
具体代码:
# 由于内存不够大,只取其中的一部分进行测试
all_star_list = [x[0] for x in douban_data] # 提取出第一列来
all_star_list = all_star_list[20000:34000]
all_comment_list = [x[1] for x in douban_data] # 提取出第二列来
all_comment_list = all_comment_list[20000:34000]
# 数据的TF-IDF信息计算
vectorizer = CountVectorizer() # 该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j],表示j词在i类文本下的词频
transformer = TfidfTransformer() # 该类会统计每个词语的tf-idf权值
# 第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵
tfidf = transformer.fit_transform(vectorizer.fit_transform(all_comment_list))
word = vectorizer.get_feature_names() # 获取词袋模型中的所有词语
weight = tfidf.toarray() # 将tf-idf矩阵抽取出来,元素weight[i][j]表示j词在i类文本中的tf-idf权重,4w条评论需要4GB内存
四 模型拟合
简单起见,只调用最简单的逻辑回归进行拟合,拆分4成数据作为CV集
# 拆分数据为训练集,交叉验证集合
x_train, x_vc, y_train, y_vc = train_test_split(weight, all_star_list, test_size=0.4, random_state=0)
# 开始训练
clf = LogisticRegression()
clf.fit(x_train, y_train)
y_pre = clf.predict(x_vc)
train_scores = clf.score(x_train, y_train)
valid_scores = accuracy_score(y_pre, y_vc)
print(c, train_scores, valid_scores)
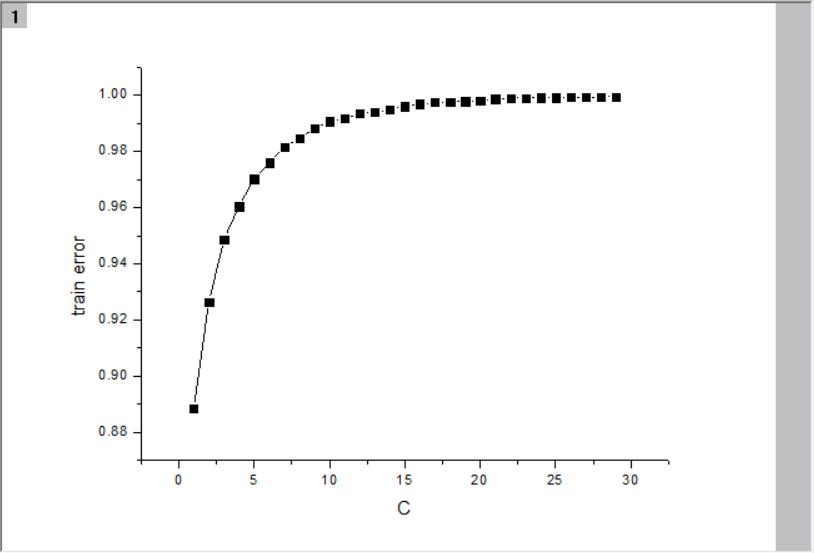
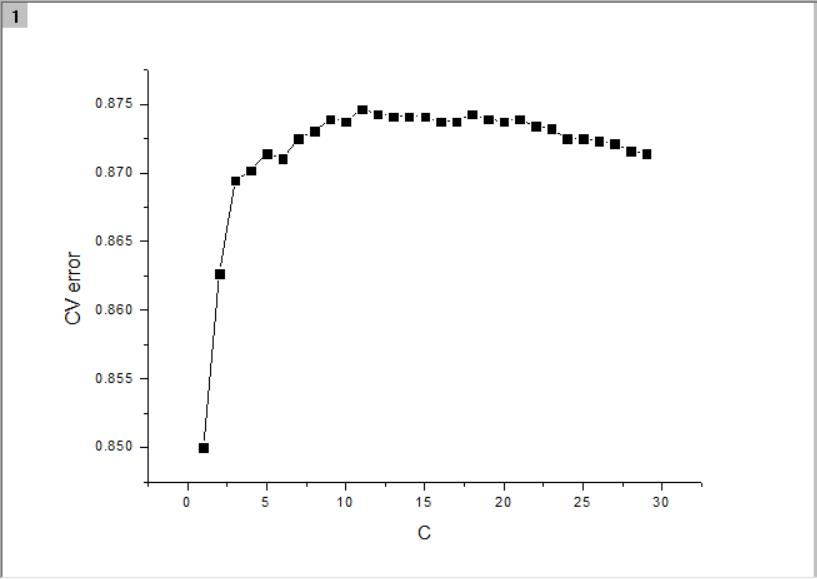
结果:训练集上0.888452380952381 ,CV集上0.85,结果还算可以。
调整正则化强度:将
clf = LogisticRegression()替换为(C从1到30计算多次,取最大值)
clf = LogisticRegression(C=10.0)训练集上0.9907142857142858,CV集上0.87375,提升2.3%
附:调节不同的正则化强度C值后的误差:
豆瓣电影top250下的评论爬取
2018-03-21 19:42:13 yuweiming70 阅读数 2626更多
分类专栏: 爬虫
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/yuweiming70/article/details/79644600
近日想要试试文本分类的小demo,需要有足够大量的好评差评数据,在研究了一些点评网站后,我选择了豆瓣电影top250豆瓣电影TOP250,这个网上的评价质量高,而且网页结构清晰明显,好爬取。美中不足的是每个电影的评价(好评以及差评)只能爬取各前200条,并且爬了太多(估计是访问100页左右)之后就封IP,一天后解封。后来换了手机提供的WLAN热点之后就再也没有封得掉我,不知道其中是什么原理?
思路:
1.需要爬取的页面连接特别好找,需要注意的是有的评论是繁体字,需要转换成简体字,我在这个博客找到了方法 Python 繁体中文与简体中文相互转换
2.因为之后我直接对句子分词,因此在数据爬取的时候直接把标点符号去掉了,只留下汉字
3.得到的评论数据提供下载豆瓣评论数据,有一些评论使用了颜文字,不过实在是有一些特殊符号去不掉了。数据共60856条,好评1(4-5星)差评0(1-2星)各一半左右。
预览:

爬虫代码:(langconv请Python 繁体中文与简体中文相互转换中下载)
import urllib.request
import urllib.error
import re
import time
import langconv
def Traditional2Simplified(sentence): # 将sentence中的繁体字转为简体字
sentence = langconv.Converter('zh-hans').convert(sentence)
return sentence
# 清理一下评论数据
def clear(string):
if '<p class="">' in string:
string = string.replace(r'<p class="">', "")
if "\n" in string:
string = string.replace("\n", "")
if " " in string:
string = string.replace(" ", "")
string = string.strip() # 去掉空格等空白符号
string = re.sub("[A-Za-z0-9]", "", string) # 去掉英文字母 数字
string = re.sub(r"[!!?。。,&;"★#$%&'()*《》+-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃「」『』【】"
r"〔〕〖〗〘〙#〚〛〜〝〞/?=~〟,〰–—‘’‛“”„‟…‧﹏.]", "", string) # 去掉中文符号
string = re.sub(r"[!\'\"#。$%&()*+,-.←→/:~;<=>?@[\\]^_`_{|}~", "", string) # 去掉英文符号
return Traditional2Simplified(string).lower() # 所有的英文都换成小写
# 给一个电影的编号,输出这个电影的评论,好评差评各自200条
def print_movie(movie_num):
for page in range(0, 10):
for judge in ['h', 'l']: # hl对应着好评/差评,中评忽略
try:
url = "https://movie.douban.com/subject/" + str(movie_num) + "/comments?start=" + str(page*20) + \
"&limit=20&sort=new_score&status=P&percent_type=" + judge # 导入总的网址,包括第几页
html = urllib.request.urlopen(url).read().decode("utf-8", "ignore") # 解码这个网页
total_str = re.findall(r'allstar([\s\S]*?)</p>\n', html) # 所有的用户评论数据,应该有20条
for i in range(len(total_str)):
comments = re.findall('<p class="">([\s\S]*?)\n', total_str[i])
cleaned_comment = clear(comments[0]) # 清理一下这个评价
if len(cleaned_comment) > 10: # 太短的评价并不需要
if total_str[i][0] == '1' or total_str[i][0] == '2': # 第一个字就是评价的star数
print("0 " + cleaned_comment)
if total_str[i][0] == '4' or total_str[i][0] == '5': # 并不包括中评
print("1 " + cleaned_comment)
time.sleep(1)
except urllib.error.HTTPError or NameError or ConnectionAbortedError or IndexError as e:
continue
# 首先进入top250界面,查找i页的25个电影编号:
for page in range(1,11):
url_250 = "https://movie.douban.com/top250?start=" + str(25*page) + "&filter="
html_250 = urllib.request.urlopen(url_250).read().decode("utf-8", "ignore") # 解码这个网页
global total_num_str
total_num_str = re.findall(r'https://movie.douban.com/subject/[\d]+/">', html_250) # 所有的用户评论数据,应该有20条
for i in range(len(total_num_str)):
total_num_str[i] = re.sub("\D", "", total_num_str[i])
for movie in total_num_str:
print_movie(movie)

















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









