







优雅解读 层次聚类(带Java示例)
🌟 一句话定义
层次聚类像一位耐心的考古学家,通过逐层挖掘数据间的亲缘关系,构建出从微观到宏观的多层次数据族谱,既能俯瞰全局结构,又能细察局部关联。
🌧️ 核心思想图解
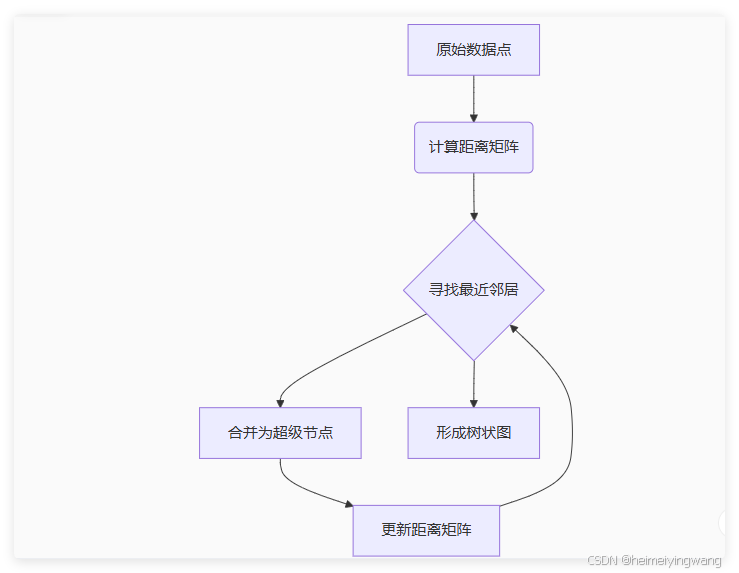
⚙️ 核心特性
-
双模式选择:
-
凝聚式(自底向上):像拼乐高积木逐步合并
-
分裂式(自顶向下):像切蛋糕逐步细分
-
-
距离度量艺术:
// 常用距离计算示例 double singleLinkage(double[] a, double[] b) { double min = Double.MAX_VALUE; for (int i : a) for (int j : b) min = Math.min(min, euclideanDistance(i, j)); return min; } -
动态聚类数:通过切割树状图获得任意粒度的聚类结果
⚡ Java实现示例
import java.util.*;
class Cluster {
int id;
List<Double[]> points = new ArrayList<>();
public Cluster(Double[] point) {
points.add(point);
}
}
public class HierarchicalClustering {
public static void main(String[] args) {
// 样本数据初始化
List<Cluster> clusters = new ArrayList<>();
clusters.add(new Cluster(new Double[]{1.0, 2.0}));
clusters.add(new Cluster(new Double[]{5.0, 6.0}));
clusters.add(new Cluster(new Double[]{1.5, 2.5}));
// 凝聚式聚类过程
while (clusters.size() > 1) {
double minDist = Double.MAX_VALUE;
int[] mergePair = new int[2];
// 查找最近簇对
for (int i=0; i<clusters.size(); i++) {
for (int j=i+1; j<clusters.size(); j++) {
double dist = singleLinkage(clusters.get(i), clusters.get(j));
if (dist < minDist) {
minDist = dist;
mergePair = new int[]{i, j};
}
}
}
// 合并簇
Cluster merged = new Cluster();
merged.points.addAll(clusters.get(mergePair[0]).points);
merged.points.addAll(clusters.get(mergePair[1]).points);
clusters.remove(mergePair[1]);
clusters.remove(mergePair[0]);
clusters.add(merged);
System.out.println("合并后簇数: " + clusters.size());
}
}
// 单链接距离计算
static double singleLinkage(Cluster a, Cluster b) {
double min = Double.MAX_VALUE;
for (Double[] p1 : a.points)
for (Double[] p2 : b.points)
min = Math.min(min, euclidean(p1, p2));
return min;
}
static double euclidean(Double[] a, Double[] b) {
return Math.sqrt(Math.pow(a[0]-b[0],2) + Math.pow(a[1]-b[1],2));
}
}⏱️ 复杂度分析
| 维度 | 基本实现 | 优化方案 |
|---|---|---|
| 时间复杂度 | O(n³) | O(n² log n) |
| 空间复杂度 | O(n²) | O(n) |
n=数据点数,优化方案需使用优先队列等数据结构
🌐 典型应用场景
-
生物信息学:基因表达谱分类
-
社交网络分析:社区结构发现
-
文档聚类:新闻主题演化分析
-
地理信息系统:地震带划分
🧑🏫 学习路线图
新手成长阶梯:
-
理解基础:距离度量 → 树状图 → 切割策略
-
关键参数实践:
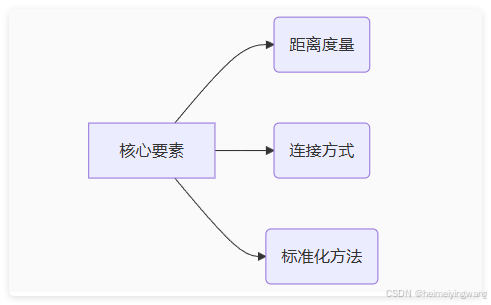
-
可视化工具:学习使用
dendrogram解读聚类层次
高手突破方向:
-
大规模数据优化:开发基于MapReduce的分布式版本
-
动态聚类:实现增量式层次聚类算法
-
混合模型:与密度聚类结合处理异形数据
💡 创新应用思路
-
时间序列分析:将动态时间规整(DTW)作为距离度量
-
图像分割:将像素颜色与空间位置联合聚类
-
推荐系统:构建用户兴趣层次图谱
-
异常检测:通过树状图深度定位异常路径
🚀 性能调优技巧
// 内存优化:稀疏矩阵存储
Map<String, Double> distanceCache = new HashMap<>();
// 计算加速:并行化距离计算
clusters.parallelStream().forEach(cluster -> {
// 并行处理逻辑
});最佳实践提示:当数据量>1万时,建议先使用K-means粗聚类再进行层次分析,像先用望远镜观测再用显微镜研究!

















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









