







很多人觉得DDR行命中的访问最快,所以DDR若想达到最大带宽,那就需要所有的命令尽量的访问到同一个row上面去,这个row读完了之后,再跳到下一个row。
首先,“读命令行命中” 仅仅是 “连续读达到最大带宽” 的一个必要条件,而非充分条件;下面从几个维度来进行解释:
- 反证法:如果所有命令访问一个row的场景,带宽最好;那么我们很自然的会问一个问题: 为什么随着工艺和协议的演进,DDR器件的page_size几乎没有变化?为什么不做一个超级大的row,来让几乎全部命令都是row_hit的状态? — 很明显,vendor全都没有选择这么做,说明仅靠row_hit还不能达成DRAM的最大带宽,我们还忽略了其它因素。
- 掰开协议,两个读操作之间的间隔是tCCD,对于DDR4,tCCD分为tCCD_S和tCCD_L,下面分别介绍一下两个参数:
| 参数 | 描述 | 值 |
|---|---|---|
| tCCD_S | 不同BG列命令间隔 | 4nCK |
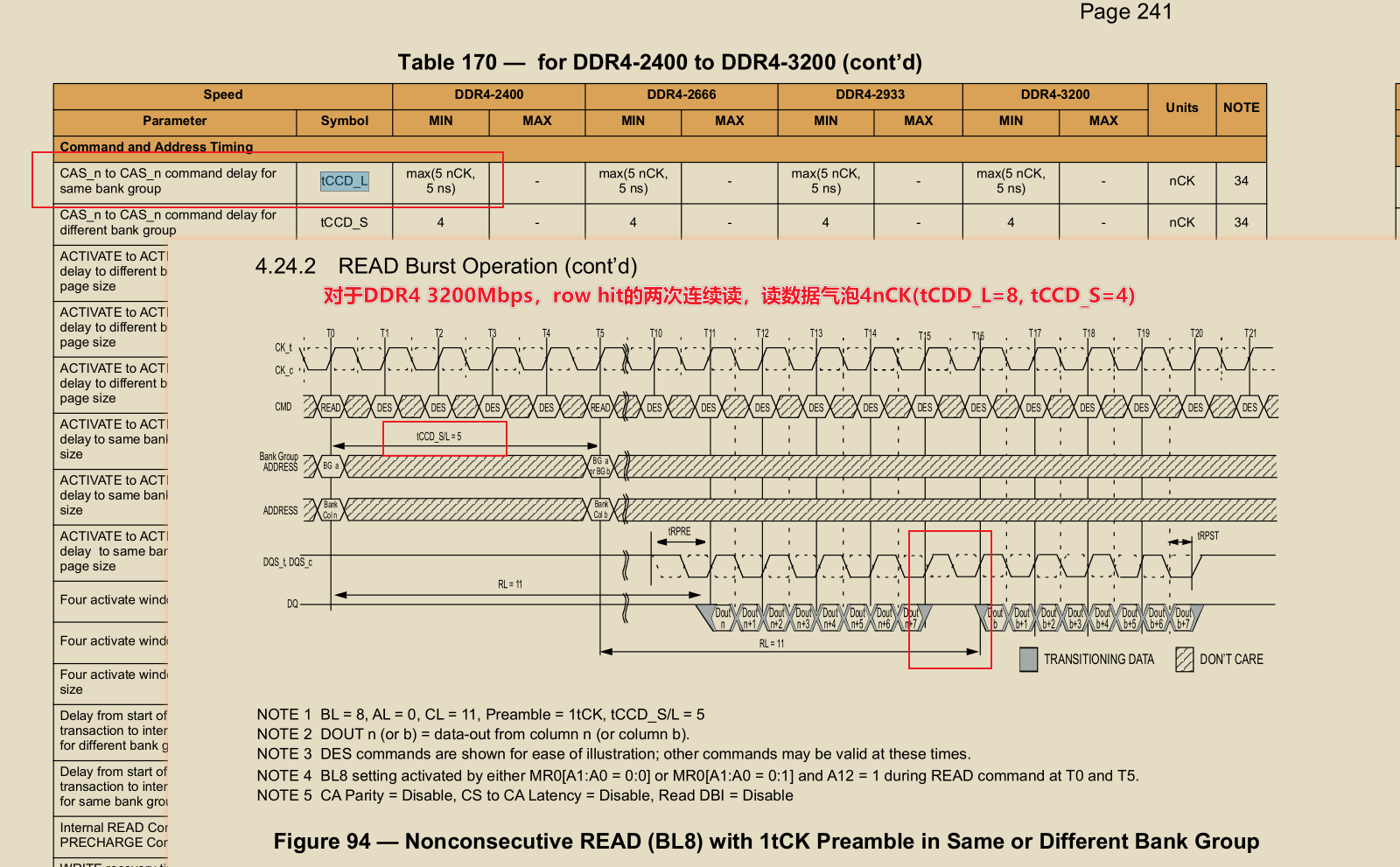
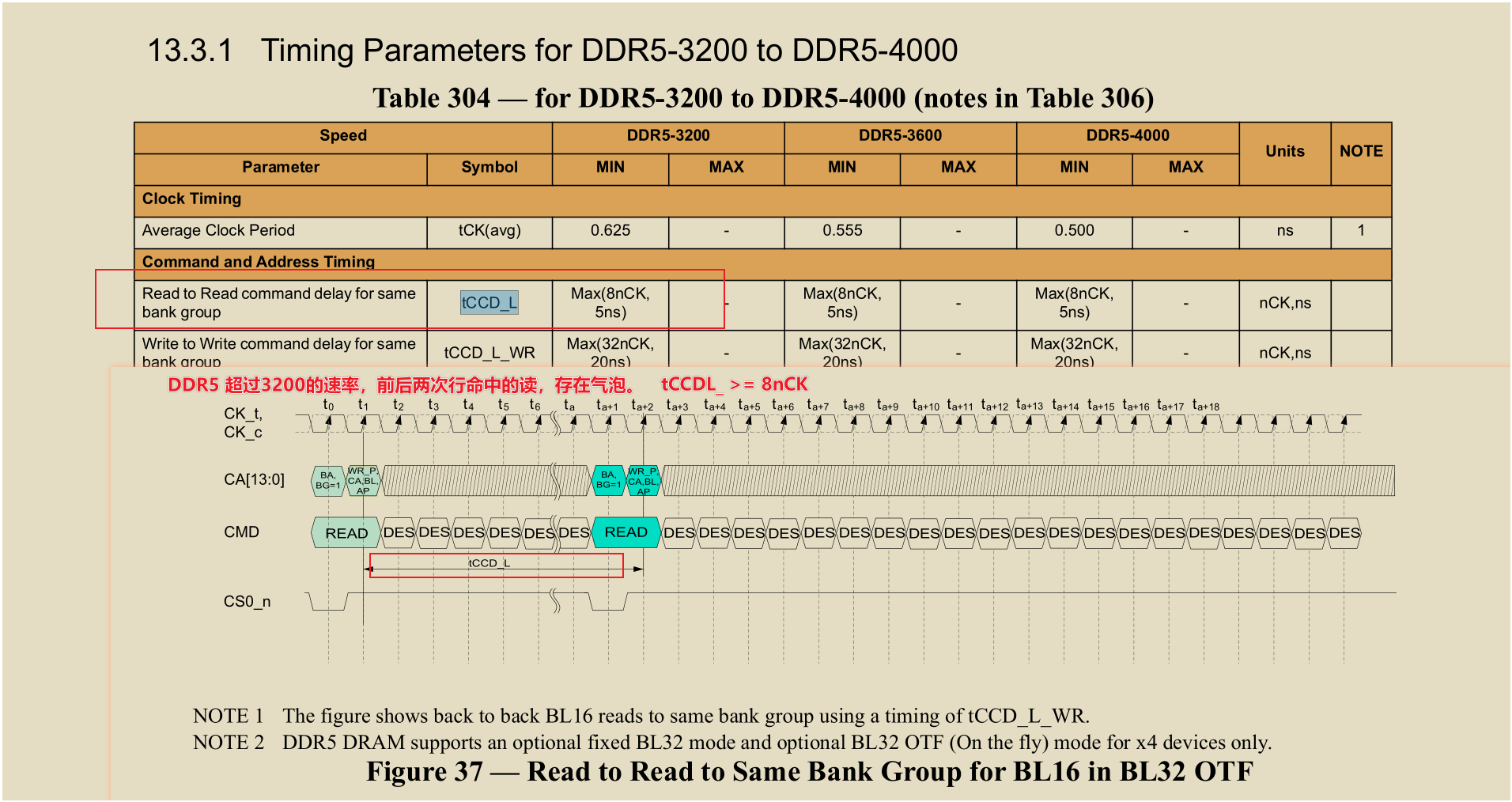
| tCCD_L | 相同BG列命令间隔 | max(5nCK, 5ns) |
注意到了吗,不同bank group的列命令间隔tCCD_S >=4nCK的周期数,但是相同bank group内的列命令时间间隔tCCD_L,则多一个绝对时间的限制(>=5ns 且 >= 5nCK);
在DDR协议中,绝对时间一般都意味着突破了物理电路的极限,比如tREFI(受限于电容器的漏电),比如tRFC(受限于电容器的充电); 所以tCCD_L想必也是因为相同BG内的bank共享部分电路资源,连续列操作时,这些资源由于物理条件限制,无法及时切换;但是不同BG有着各自的外围电路和缓存资源,因此没有这个限制,tCCD_S纯纯的只因DDR4是burst8(4nCK)而已,两个读如果小于4拍, 数据就多驱了。
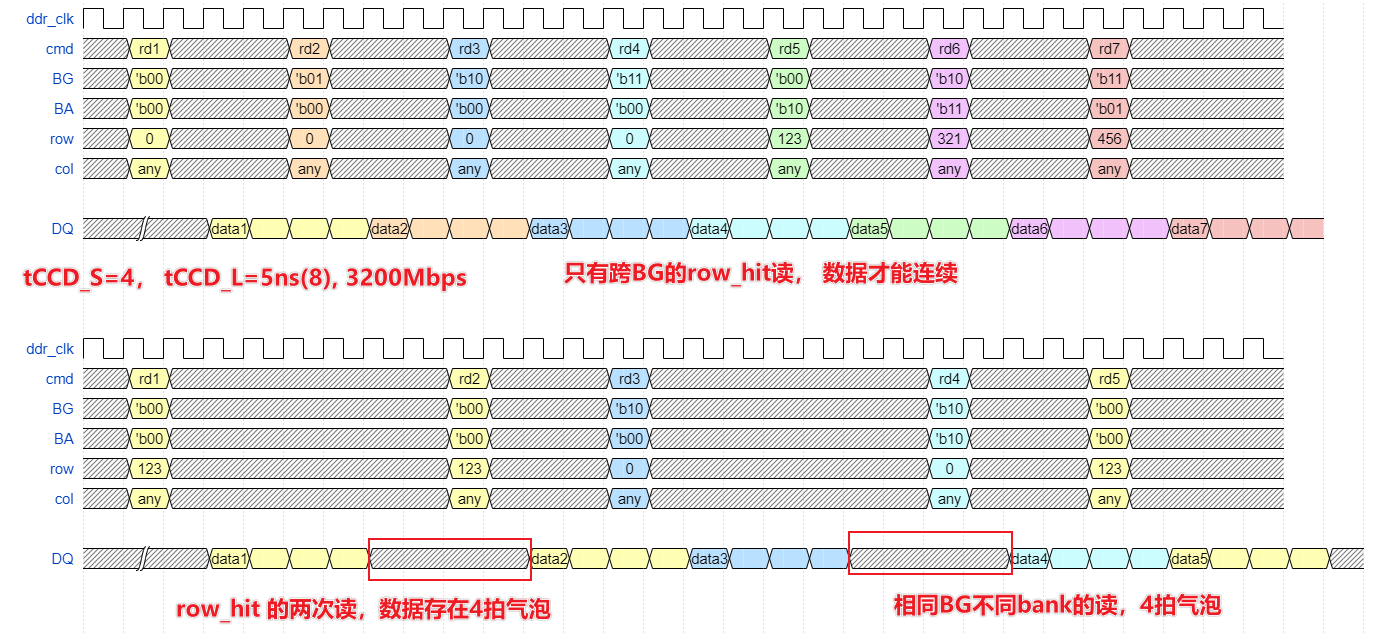
以DDR4 3200为例,tCCD_S是4nCK, tCCD_L是5/0.625 = 8nCK,倘若所有的读都处于同一行,则命令间隔是8nCK,对于DQ线来说,有4拍在传输burst8的数据,有4拍是空闲的。那么DDR4的带宽利用率仅有可怜的50%(还没考虑刷新,act, pre的影响呢!)。
总结:连续读场景,如果要达到接近100%的带宽利用率, row_hit读仅仅是必要条件; BG轮转(也叫BG交织访问) + 每个BG操作均是row_hit, 才是达到最大带宽的充分条件。
因此,对于系统地址连续递增的读访问,DDRC的设计最简单的方式就是RRCBBC(rank - row - col - bank - bank_group - col)映射,把bank插在col中间,每burst8的数据量,即切换BG,这样才能达到最大的带宽。当然,为了均衡各个场景的带宽,实际的DDRC地址映会做的更加复杂。
OK文字描述完了,看一些时序图理解一下:















 1485
1485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









