






1. 卡尔曼滤波器原理
那么, 什么是卡尔曼滤波器, 为什么赫兹量化交易软件感兴趣呢?以下过滤器定义来自 维基百科 :
卡尔曼滤波器 是一种使用一系列随时间观测到的测量值的算法, 包含统计噪声和其它不准确性。
这意味着该滤波器最初是为处理噪声数据而设计的。还有, 它能够处理不完整的数据。另一个优点, 它是为动态系统设计并应用的; 赫兹量化交易软件的价格图表恰好属于这样的系统。
滤波器算法的工作在两个步骤中处理:
-
外推 (预测)
-
更新 (校正)

1.1. 外推, 系统数值的预测
滤波器操作算法的第一阶段是利用已分析过程的基础模型。在此模型基础上, 形成单步前瞻预测。
![]()
编辑
添加图片注释,不超过 140 字(可选)
(1.1)
其中:
-
xk 是动态系统在第 k 步的外推值,
-
Fk 是状态转换模型, 展体现当前系统状态对先前状态的依赖性,
-
x^k-1 是系统的前一个状态 (前一步中的滤波值),
-
Bk 是控制输入模型, 展现控制对系统的影响,
-
uk 是系统上的控制向量。
例如, 控制效果可以是新闻因素。不过, 实际当中效果是未知的, 且被忽略, 而其影响是指噪声。
之后预测系统的协方差误差:
![]()
编辑
添加图片注释,不超过 140 字(可选)
(1.2)
其中:
-
Pk 是动态系统状态向量的外推协方差矩阵,
-
Fk 是状态转换模型, 展体现当前系统状态对先前状态的依赖性,
-
P^k-1 是状态向量的协方差矩阵在前一步的更新,
-
Qk 是过程的协方差噪声矩阵。
1.2. 系统值的更新
滤波器算法的第二步从测量实际系统的状态 zk 开始。考虑到真实系统状态和测量误差, 指定系统状态的实际测量值。在赫兹量化交易软件的案例中, 测量误差是噪声对动态系统的影响。
此刻, 赫兹量化交易软件已有两个不同的数值代表单个动态过程的状态。它们包括第一步计算的动态系统外推值, 和实际的测量值。这些具有一定的几率度的数值, 当中的每一个均表征我们过程的真实状态, 因此, 该值介于这两个值之间。因此, 我们的目标是确定信任度, 即此值或彼值的信任程度。为此目的, 执行卡尔曼滤波器第二阶段的迭代。
利用已有数据, 赫兹量化交易软件判断实际系统状态自外推值的偏差。
![]()
编辑
添加图片注释,不超过 140 字(可选)
(2.1)
此处:
-
yk 是外推之后系统实际状态在第 k 步的偏差,
-
zk 是第 k 步中系统的实际状态,
-
Hk 是显示实际系统状态对于所计算数据依赖性的测量矩阵 (在实际中经常取值一),
-
xk 是动态系统在第 k 步的外推值。
在下一步中, 计算误差向量的协方差矩阵:
![]()
编辑
添加图片注释,不超过 140 字(可选)
(2.2)
此处:
-
Sk 是在第 k 步的误差矢量的协方差矩阵,
-
Hk 是显示实际系统状态对于计算数据依赖性的测量矩阵,
-
Pk 是动态系统状态向量的外推协方差矩阵,
-
Rk 是测量噪声的协方差矩阵。
然后检测优化增益。增益反映了计算值和经验值的置信度。
![]()
添加图片注释,不超过 140 字(可选)
(2.3)
此处:
-
Kk 是卡尔曼增益值的矩阵,
-
Pk 是动态系统状态向量的外推协方差矩阵,
-
Hk 是显示实际系统状态对于计算数据依赖性的测量矩阵,
-
Sk 是在第 k 步的误差矢量的协方差矩阵。
现在, 赫兹量化交易软件使用卡尔曼增益来更新系统状态值和状态向量的协方差矩阵估值。
![]()
编辑
添加图片注释,不超过 140 字(可选)
(2.4)
其中:
-
x^k 和 x^k-1 在在第 k 和 k-1 步的更新值,
-
Kk 是卡尔曼增益值的矩阵,
-
yk 是外推后在第 k 步的系统实际状态的偏差。
![]()
编辑
添加图片注释,不超过 140 字(可选)
(2.5)
其中:
-
P^k 是更新后的动态系统状态向量的协方差矩阵,
-
I 是标识符矩阵,
-
Kk 是卡尔曼增益值的矩阵,
-
Hk 是显示实际系统状态对于计算数据依赖性的测量矩阵,
-
Pk 是外推的动态系统状态向量的协方差矩阵。
以上所有可以概括为以下规划
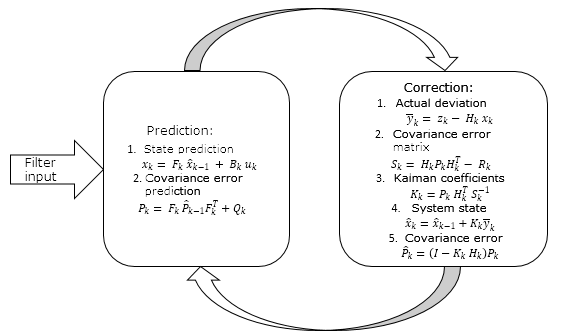
编辑
添加图片注释,不超过 140 字(可选)
2. 卡尔曼滤波器的实现
现在, 赫兹量化交易软件已知晓了卡尔曼滤波器的工作原理。我们进入到实际实现。以上滤波器公式的矩阵形式允许接收若干个来源的数据。我建议在柱线收盘价基础上构建一个滤波器, 并将矩阵形式简化为离散的。
2.1. 输入数据初始化
在开始编写代码之前, 赫兹量化交易软件先定义输入数据。
如上所述, 卡尔曼滤波器的基础是一个动态过程模型, 用于预测过程的下一个状态。该滤波器最初旨在协同线性系统一起使用的, 其当前状态可轻易地通过前一状态乘以一个系数来定义。赫兹量化交易软件的情况有很更困难: 我们的动态系统是非线性的, 且比率在每一步都有变化。更甚的是, 我们不清楚该系统相邻状态之间的关系。这个任务似乎难以解决。这是一个棘手的解决方案: 我们将利用在这几篇文章中 [1],[2],[3] 描述的自回归模型。
我们开始吧。首先, 我们在这个类中声明 CKalman 类和所需的变量
class CKalman { private: //--- uint ci_HistoryBars; //用于分析的柱线数量 uint ci_Shift; //计算自回归的偏移 string cs_Symbol; //品名 ENUM_TIMEFRAMES ce_Timeframe; //时间帧 double cda_AR[]; //自回归系数 int ci_IP; //自回归系数的数量 datetime cdt_LastCalculated; //最后计算时间; bool cb_AR_Flag; //自回归计算的标志 //--- 卡尔曼滤波器的数值 double cd_X; // X double cda_F[]; // F 数组 double cd_P; // P double cd_Q; // Q double cd_y; // y double cd_S; // S double cd_R; // R double cd_K; // K public: CKalman(uint bars=6240, uint shift=0, string symbol=NULL, ENUM_TIMEFRAMES period=PERIOD_H1); ~CKalman(); void Clear_AR_Flag(void) { cb_AR_Flag=false; } };
我们在类的初始化函数中为变量分配初值。
CKalman::CKalman(uint bars, uint shift, string symbol, ENUM_TIMEFRAMES period) { ci_HistoryBars = bars; cs_Symbol = (symbol==NULL ? _Symbol : symbol); ce_Timeframe = period; cb_AR_Flag = false; ci_Shift = shift; cd_P = 1; cd_K = 0.9; }
我使用了来自文章 [1] 的算法创建一个自回归模型。为此目的, 需要在类中添加两个私有函数。
bool Autoregression(void); bool LevinsonRecursion(const double &R[],double &A[],double &K[]);
LevinsonRecursion 函数按原样使用。Autoregression 函数有略微修改, 所以我们来仔细考察这个函数。在函数伊始, 赫兹量化交易软件检查分析所需的历史数据的可用性。如果没有足够的历史数据, 则返回 false。
bool CKalman::Autoregression(void) { //--- 检查数据不足 if(Bars(cs_Symbol,ce_Timeframe)<(int)ci_HistoryBars) return false;
现在, 赫兹量化交易软件加载所需的历史数据并填充实际状态转移模型系数的数组。
//--- double cda_QuotesCenter[]; //计算的数据 //--- 令所有价格可用 double close[]; int NumTS=CopyClose(cs_Symbol,ce_Timeframe,ci_Shift+1,ci_HistoryBars+1,close)-1; if(NumTS<=0) return false; ArraySetAsSeries(close,true); if(ArraySize(cda_QuotesCenter)!=NumTS) { if(ArrayResize(cda_QuotesCenter,NumTS)<NumTS) return false; } for(int i=0;i<NumTS;i++) cda_QuotesCenter[i]=close[i]/close[i+1]; // 计算系数
在准备操作之后, 赫兹量化交易软件检测自回归模型的系数个数, 并计算它们的值。















 2080
2080











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









