






在介绍fasttext之前,首先介绍下背景知识,即word2vec中的skip-gram模型和cbow模型。
word2vec是在2013年由谷歌提出的一种将词语转变成向量的算法。
相关论文和链接如下
【1】Efficient Estimation of Word Representations in Vector Space
https://arxiv.org/pdf/1301.3781.pdf
【2】Distributed Representations of Words and Phrases and their
Compositionality
https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf
下面是CBOW以及skip-gram示例
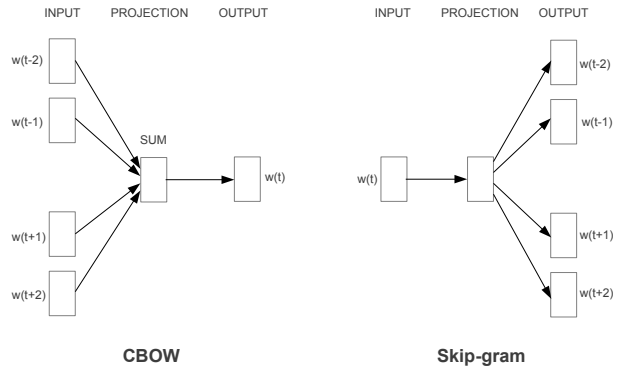
图片来自【1】
skip-gram模型
在skip-gram模型中,目的在于预测某个词的上下文中会出现哪个词。
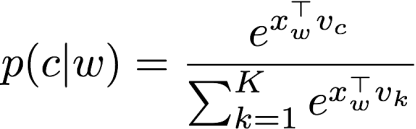
其中
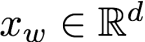
是词向量,k是该词附近的近邻词的个数。
skip-gram的目标函数如下
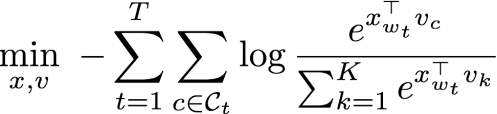
其目标在于最小化负对数似然度。为了对上述目标函数进行近似,可以将其利用多个二分类的损失函数来代替。基于负采样方法可以得到
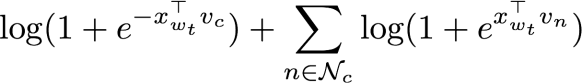
为了进行分类还需要借助hierarchical softmax方法,每个类都用一个编码集合来表示,这里的编码可以通过霍夫曼树来生成,出现频次较多的类对应的编码就越短。
cbow模型
在cbow(continuous bag of words)模型中,目标在于给定上下文,预测某个词出现的概率。
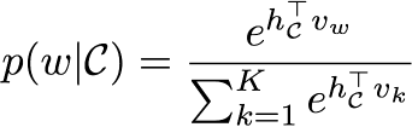
其中

是上下文特征向量。
初步了解了skip-gram和cbow,下面来介绍下fasttext。
fasttext
fasttext是由Facebook提出的一种能够高效的进行文本分类和词语表示的库。
相关论文及链接如下
【3】Bag of Tricks for Efficient Text Classification
https://arxiv.org/pdf/1607.01759.pdf
【4】Enriching Word Vectors with Subword Information
https://arxiv.org/pdf/1607.04606.pdf
该工具的作者有以下四位

早在2013年,Mikolov et al. 就提出了用向量来表示词语,即word2vec。利用词向量来表示词语这种方法具有一定的缺陷,比如不能表示句子。一种比较粗暴的方式是对单词的向量表示取平均作为句子的表示,但是这种做法通常效果不好。虽然word2vec这种方法具有一定的缺陷,但由于其简单高效,所以得以广泛应用。
fasttext提供了文本表示以及文本分类的框架,其本质在于给定一个索引集合,来预测某个索引。基于cbow,skip-gram或者bow的文本分类都是该库的示例。
在fasttext中,目标在于给定一个段落,可以预测某个标签的概率。公式如下
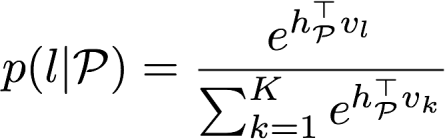
其中段落特征如下
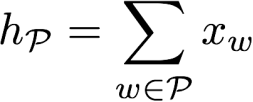
通过n-gram可以添加高阶特征。另外,可以利用hash编码来代替n-gram,这样可以缩减空间。

fasttext可以用于情感分类,其效果如下
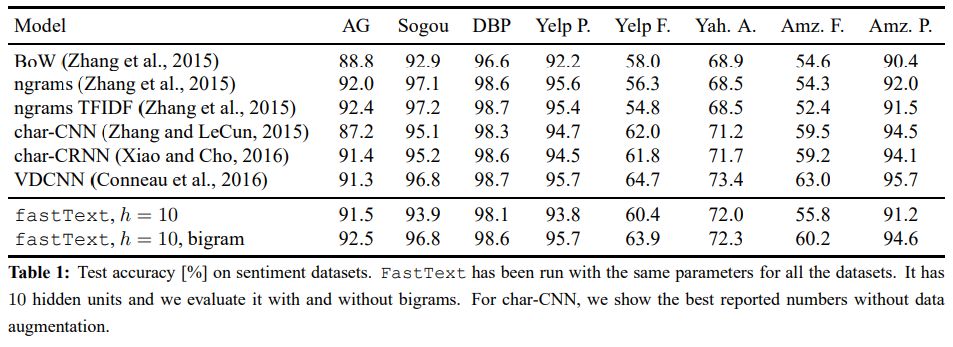
图来自【3】
下面是情感分类的各种方法在运行时间上的对比,可以看出fasttext运行效率最高,而且相比其他算法快很多倍。
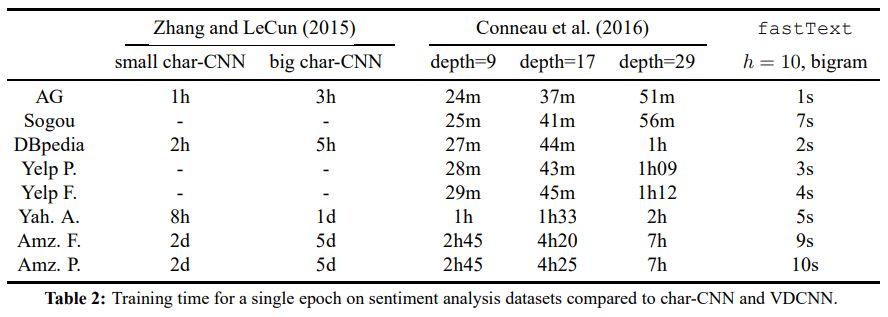
图来自【3】
fasttext也可以用于标签预测。以Flickr为例,给定一个图片的描述,预测最可能的标签。数据示例如下
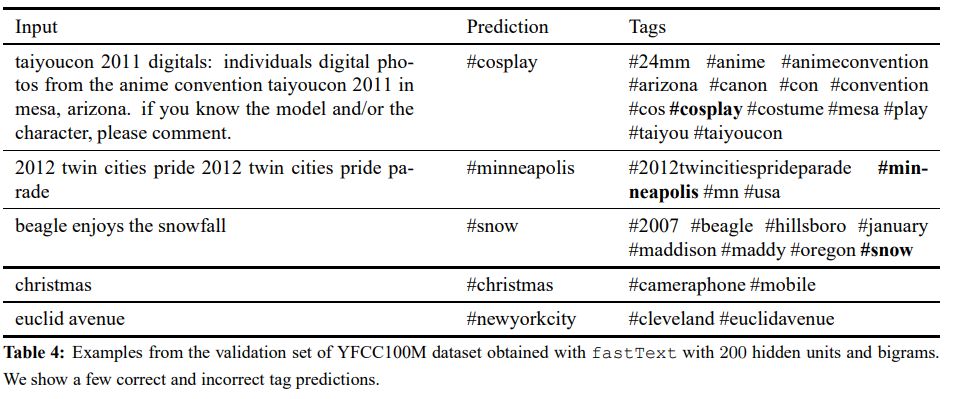
图片来自【3】
实验结果如下
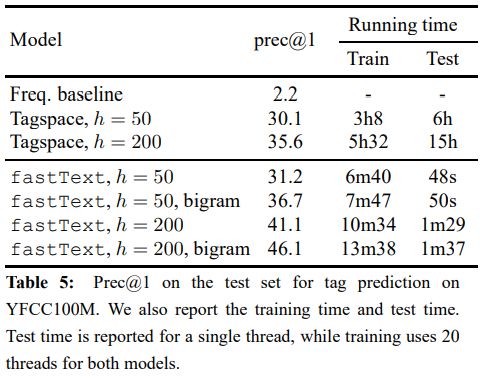
图片来自【3】
测试时间比训练时间长是因为训练时线程数是测试时的20倍。
为了丰富词向量,可以通过子词的n-gram来扩充。此时可以通过子词的n-gram模型求和来表示词。具体模型如下,对于给定的词来预测上下文的词,
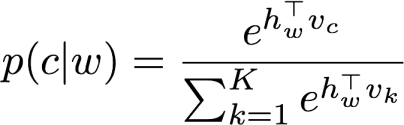
词特征利用n-gram来表示,
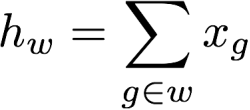
n-gram仍然利用hash编码来表示。
加入子词n-gram可以比较好的处理OOV(out-of-vocabulary)词。
相似词
词语之间的相似度计算方式如下
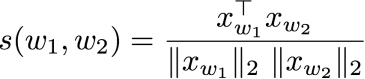
下面是几种在相似词计算中的效果对比
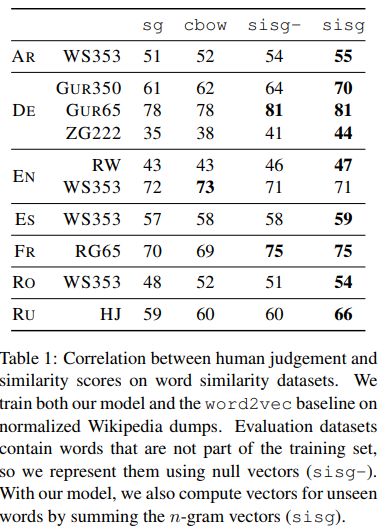
图片来自【4】
词语推理
问题描述如下,给定三个词,推理第四个词语。
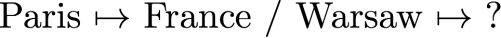
几种方法在词语推理问题中的结果对比如下
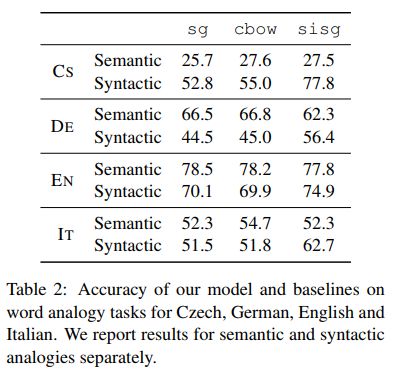
图片来自【4】
图片来自【4】,fasttext效果最好,并且可以较好地处理OOV问题。
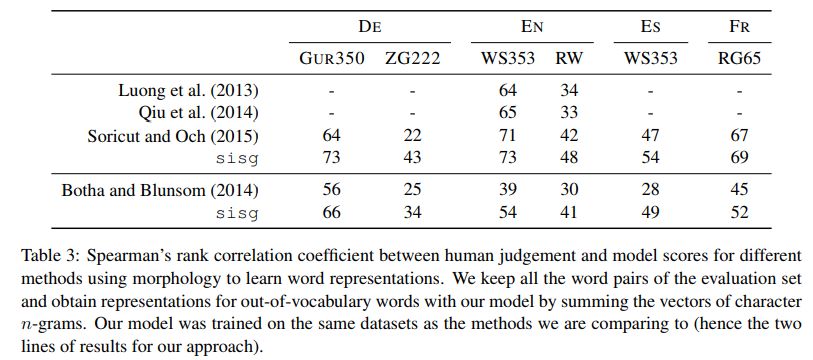
下面是寻找比较少见的词的最近邻的效果示例。其中sg是skip-gram的简写,sisg是Subword Information Skip Gram的简写,sisg即考虑了子词的skip-gram。
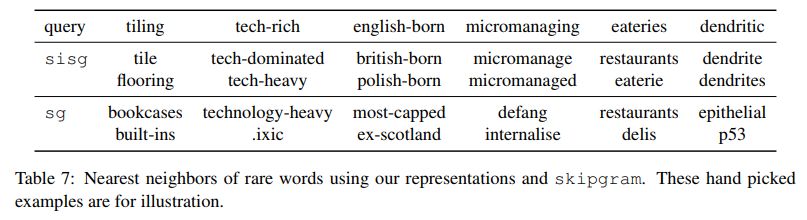
该表格来自【4】
附录
spark中的word2vec源码解读

默认将单词映射到100维的向量
窗口大小
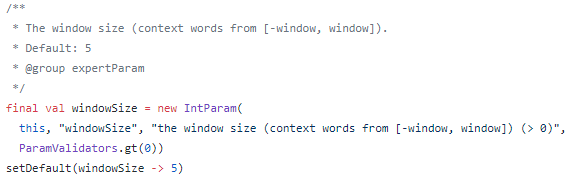
单边上下文单词个数为5

句子的最大长度为1000,超过1000会被分成每个句子最大长度为1000的子句。
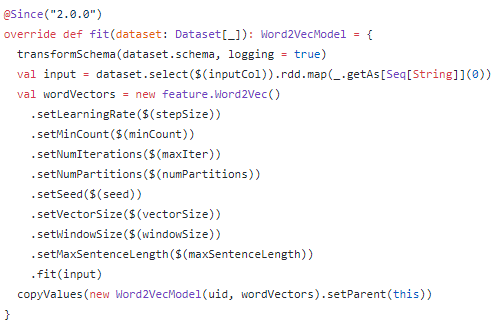
参数主要有学习率、迭代次数、向量大小、窗口大小、句子最大长度等。
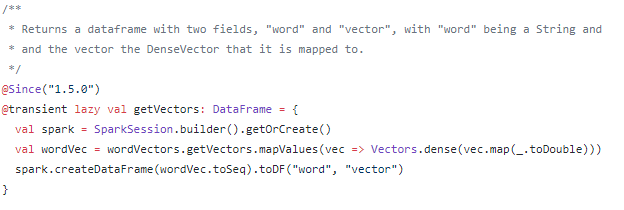
返回单词和对应的向量。

查找给定单词最相近的若干单词

返回给定向量最相近的若干单词
fasttext源码解读

这是训练过程,该过程是多线程的。

这是各个训练线程,其中有一个细节,即学习率衰减。
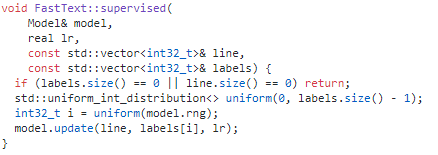
这是分类的代码。

这是cbow关键代码。

这是skip-gram的关键代码。

这是预测的关键代码。
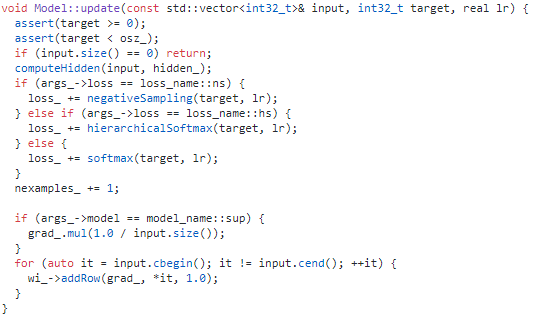
这是更新模型的关键代码
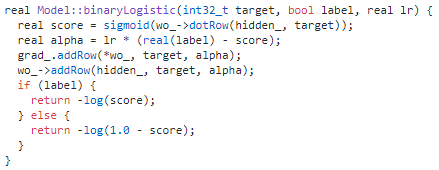
这是逻辑回归的关键代码

这是负采样的关键代码
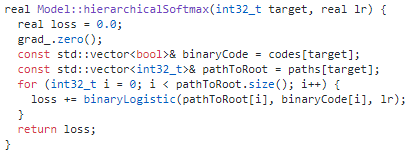
这是分层softmax的关键代码

这是softmax的关键代码

这是预测的关键代码

这是寻找k个最优的代码

这是深度优先搜索的关键代码。

这是构建霍夫曼编码树的关键代码
参考资料
https://github.com/apache/spark/blob/master/mllib/src/main/scala/org/apache/spark/ml/feature/Word2Vec.scala
https://github.com/facebookresearch/fastText/blob/master/src/model.cc
https://github.com/facebookresearch/fastText/blob/master/src/fasttext.cc
【1】Efficient Estimation of Word Representations in Vector Space
https://arxiv.org/pdf/1301.3781.pdf
【2】Distributed Representations of Words and Phrases and their
Compositionality
https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf
【3】Bag of Tricks for Efficient Text Classification
https://arxiv.org/pdf/1607.01759.pdf
【4】Enriching Word Vectors with Subword Information
https://arxiv.org/pdf/1607.04606.pdf














 211
211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









