






Automatic Validation of Textual Attribute Values in E-commerce Catalog by Learning with Limited Labeled Data
Yaqing Wang, Yifan Ethan Xu, Xian Li, Xin Luna Dong and Jing Gao
State University of New York at Buffalo, Amazon.com
https://dl.acm.org/doi/pdf/10.1145/3394486.3403303
产品目录在电子商务网站中是非常重要的资源。在目录中,产品跟多个属性都有关联,这些属性基本都是短文本,比如产品名,品牌,功能以及特点等。
通常,零售商会自报这些关键属性,因此,目录信息会不可避免的包含一些噪声。非常有必要验证这些属性的正确性,这有利于提升消费者的购物体验以及更高效的产品推荐。由于产品量非常大,所以需要高效且自动验证的方法。
这篇文章,提出一种自动验证方法,来验证产品文本属性的正确性。它可以作为一种文本属性跟商品画像之间交叉验证的任务,这里的产品画像是指电子商务网站中对商品进行描述的短文本信息。尽管现有的深层神经网络模型在交叉验证两段文本中已经取得不错的效果,但是这依赖大量高质量标注数据,而本文研究的验证任务很难获得大量标注数据,因为商品类别多种多样。由于类别不同,所有类别必须有标注,这在现实中不可能做到。
为了解决上述挑战,作者们提出一种新的元学习隐含变量方法,MetaBridge,这种方法可以从类别子集中学到迁移知识,只需要少量有标记的数据,并且可以从无标注样本中捕获未见类别的不确定信息。
这篇文章具有以下几个贡献
1. 在few-shot学习场景中,将具有多种类别前提下,验证商品文本属性的问题转为自然语言推理问题,提出一种元学习隐含变量模型,可以从商品画像和文本属性中联合处理两种信息。
2. 将元学习和隐含变量集成在一个统一模型中,高效捕捉多种类别中的不确定性。利用这种模型,标注成本可以显著缩减,因为这种模型可以充分利用有限类别中的标注数据。
3. 提出一种新的目标函数,该目标函数基于few-shot学习场景中的隐含变量模型,这可以保证无标注样本和标注样本分布的一致性,通过所学分布中采样不同的记录可以防止过拟合。
作者们在涵盖数百类别的真实电商数据上进行了大量实验,结果表明MetaBridge在文本属性验证中的有效性,相对STOA方法,表现也比较突出。
这篇文章的主要贡献如下

下面是问题定义

更详细的问题描述如下

作者们所提模型的基础MAML简介如下

maml的目标函数、局限性以及作者们的解决方案如下

作者们所提出的算法框架图示如下

关于隐含变量模型,作者们采用了以下做法


下面是目标函数

模型训练伪代码如下

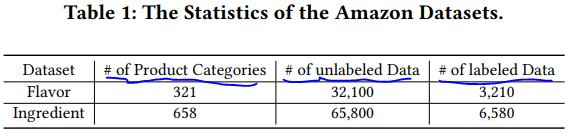
数据集简介如下


下面是数据集信息统计
作者们采用的指标有以下两个指标

为了证明所提方法的有效性,参与对比的方法有以下几个




下面是一些实现细节

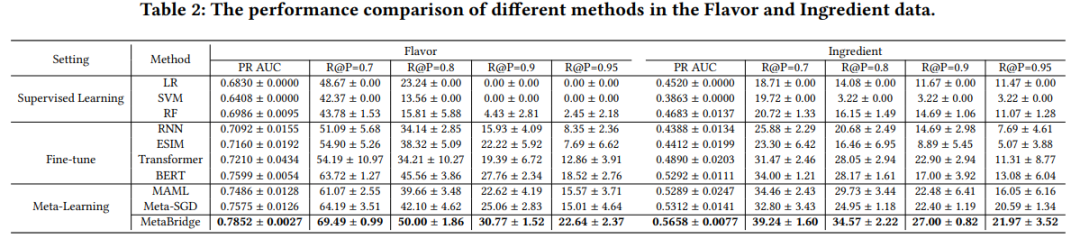
几种方法的效果对比如下
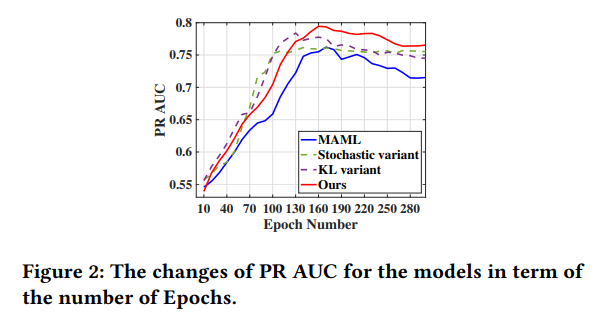
关于消融实验,作者们得到以下效果
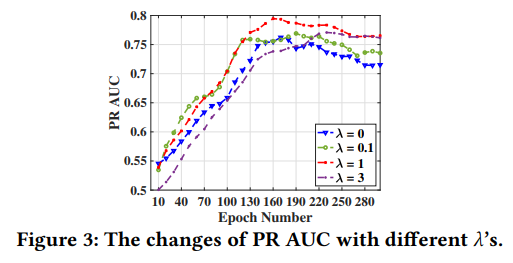
不同的lambda对模型效果影响如下
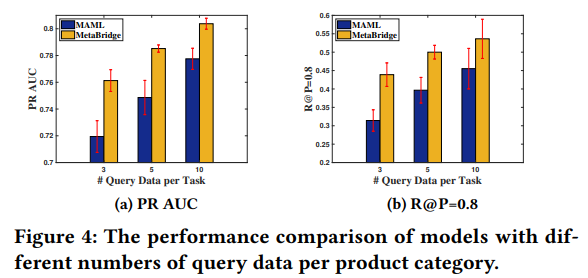
有标记样本数对模型效果影响如下
 我是分割线
我是分割线
您可能感兴趣
KDD2020|腾讯基于app使用行为提出AETN用于构建通用型user-embedding(已开源)
KDD2020|阿里联合武大提出对偶异构图注意力网络DHGAT用于提升长尾商铺搜索效果
KDD2020|蚂蚁金服提出人群扩展算法Hubble用于智能营销
深度神经网络在Youtube推荐中的应用--开篇作之一--含部分实用技巧














 1005
1005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









