







论文题目:MLCVNet: Multi-Level Context VoteNet for 3D Object Detection
论文题目:3D Object Detection with Pointformer
两篇文章要对比着来看
首先,我们来看看mlcvnet做了些什么
万物的起源:mlcvnet将attention模块引入了点云目标检测中:

文章主要由三个部分组成:ppc ooc及GSC
首先我们利用pointnet++作为backbone生成一系列的patches,这些patch的生成显然是通过一层层叠加的SA层得到的,他们有着周围信息的丰富语义信息。
将他们打包输入到PPC中。
之前提出的votenet是怎么对这些patch进行操作的呢?
他主要是采用了一个vote block的环节,将这些patch作为输入,同时回归物体中心的偏移量,这个预测值是通过mlp模仿hough voting过程得到的。
而本文中则采用的是一个自注意力模块,提取patch之间的信息。
具体的操作如下所示:
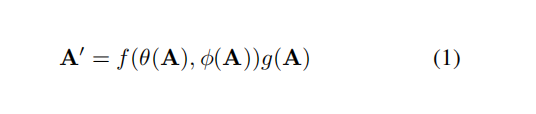

这一块主要是通过CGNL模块来得到实现的,具体的可以看《Compact Generalized Non-local Network》,主要是transformer的一个小trick,用来降低transformer的计算量。
后面的ooc模块也是类似的操作,对于前面ppc所得到的聚合了local feature的patches,我们对他们进行聚类,后进行cgnl操作。

最后作者引入了一个GSC模块,用于全局场景的理解。

我们再来看看pointformer怎么做的

上述为本文提出的一个backbone,是一个unet的结构
pointformer block主要由lt lgt和gt三个模块组成,而upsample block则是类似pointnet++
的FP操作,主要是resolution的还原。
我们主要介绍pointformer block是怎么做的:

首先对于input点云,我们先进行fps操作,选取点后,进行聚类处理,对于所聚类进行local transformer:
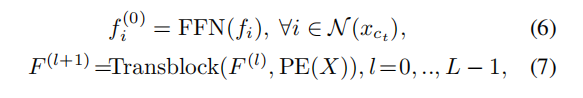
作者还引入了坐标优化的模块,这主要是针对fps对噪声敏感和防遮挡的问题。
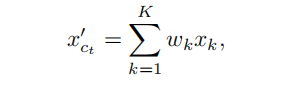
主要是依据attention map的权重计算偏移后的中心点。
随后是global transformer
主要是对于聚类点进行全局feature的赋予。
作者还引入了linformer来降低计算量。
我的思考
两篇文章的做法比较相似 我主要想从宏观和微观来探讨两个方法的异同与各自的优势:
从宏观上来说,mlcv首先通过pointnet++收集patch,实际上是进行了一次点的下采样,随后对于patches进行自注意力操作取代简单的mlp 的vote操作,实现了点向物体中心拉拢,且包含它自己的局部特征,还包含与所有其他点补丁相关的信息。随后的ooc操作,mlcv实际上是将聚类后的feature使用了自注意力处理而非mlp,这样做的好处是相比votenet不仅挖掘了自己本聚类的特征,还挖掘了物体之间的特征。同时相比votenet,mlcv引入的GSC模块还对场景进行了识别。
而pointformer则是一个unet的结构,每一个小block都是local和global feature的一个聚合。同时他们之间还有两个不同feature之间的一个聚合操作(LGT)。
总的来看,pointformer实际上是在完成mlcv前面的pointnet++的操作,是一个通用的模块,而mlcv则是一个完整的模块。
从微观上来讲:
pointformer引入了linformer的操作,是对于transformer计算力的一个解放。















 1790
1790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









