







 本文介绍了如何将3D目标检测模型Group-Free 3d中的PointNet++骨干网络替换为Transformer模块Pointformer。关键在于保证输入输出的匹配,包括查看网络参数设置,确保新旧骨干网络的输入输出尺寸一致,并通过debug模式检查替换后的模型输入输出是否与原始模型匹配。替换可能带来性能提升,但也可能存在兼容性问题,需要不断调试和优化。
本文介绍了如何将3D目标检测模型Group-Free 3d中的PointNet++骨干网络替换为Transformer模块Pointformer。关键在于保证输入输出的匹配,包括查看网络参数设置,确保新旧骨干网络的输入输出尺寸一致,并通过debug模式检查替换后的模型输入输出是否与原始模型匹配。替换可能带来性能提升,但也可能存在兼容性问题,需要不断调试和优化。
前言
说实话这篇文章是没有在计划之内的,但是有读者说让我出一个使用transformer替换其他骨干网络的示例,想了想,最近好像没啥状态的,论文有点看不下去,正好整理一下自己的经验把。说实话替换骨干网络说简单也简单,说麻烦也麻烦,替换骨干网络个人感觉就是一个debug代码匹配输入输出的问题,作为菜鸡的一种能想到的改进模型方式之一,替换骨干网络也不失为一种锻炼自己看懂代码、改代码的能力,废话就到这里,下面开始文章的内容。
替换骨干网络的原则
为什么一些模型能够把其内部的模块进行替换?理由很简单,就是把里面的模块看作一个黑盒子,黑盒子有着输入和输出,那么作为网络中的一个部分,前面有着输入过来,后面也需要输出到其他模块,要想替换该模块而让模型能够运行起来,关键是输入输出的匹配问题,下面就以我自己实验过模型作为例子。
我要替换的骨干网络是3D目标检测的一个方法叫Group-Free 3d,它使用的骨干网络是PointNet++,就是下面的图中用红色框框出来的部分。
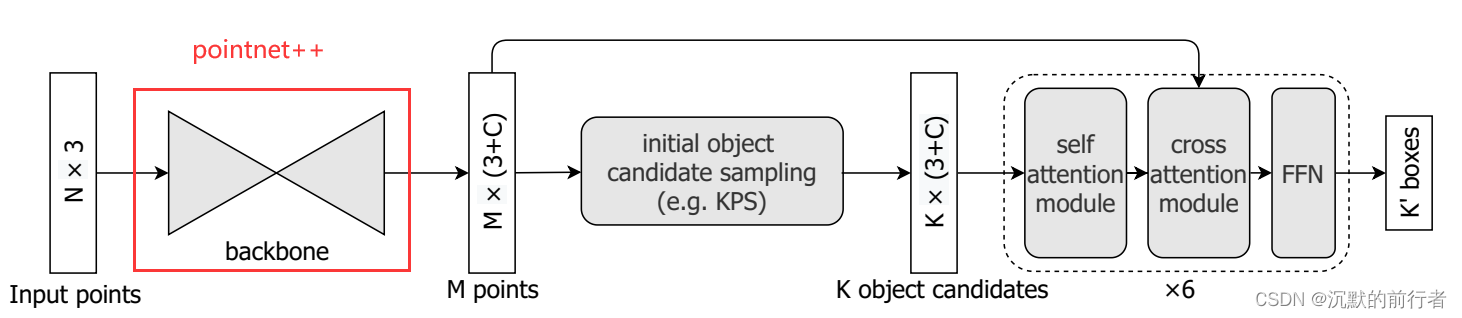
而我想用一个transformer的骨干网络Pointformer替换掉PointNet++。首先这里我说一下为什么我想用Pointformer来替换PointNet++,因为在Pointformer这个论文中,它说Pointformer这个骨干网络可以替换PointNet++来获得更好的性能,我观察到Grou
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1442
1442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









