






摘要
2025年3月,人工智能领域迎来新突破——多模态融合与语音交互技术迈入新阶段。本文以行业技术演进为背景,解析智能助手如何通过技术升级解决用户核心痛点。
一、原生多模态:让AI成为“全能大脑”
1. 多模型融合调度:打破单一模型的局限性
文小言此次升级的核心,在于构建了一个开放的多模型协作生态。通过整合百度自研的文心X1(深度推理模型)、文心4.5(原生多模态模型),并接入DeepSeek-R1等第三方顶尖模型,文小言实现了“超脑级”协同能力。
• 场景示例:用户提出“设计三种风格的南偏东客厅效果图”,文心X1可自动调用AI绘图工具,生成浅色奶油风、暗黑轻奢风等迥异设计方案,并附图文解析。

• 技术突破:文心4.5通过跨模态联合预训练,将图像、文本、语音深度融合,例如拍摄茅台镇照片,可精准识别建筑风格、产业特征等多维度信息。
 |  |
2. 图片问答:从“看图说话”到“深度解析”
文小言的多模态能力已进化到“思考级”:
• 解题神器:拍摄数学题可实时生成解题思路与视频解析,甚至能通过概率空间分析解决争议性难题(如“二孩悖论”)。
• 购物助手:上传多款商品图,AI自动对比参数、价格,并生成同款手机壳等衍生设计。
• 冷知识彩蛋:预设“历史学者”视角,一张猫咪图片可解读出狩猎本能、领地意识等科学真相。
3. 创意生成:从设计到视频的“一键生产力”
文小言支持吉卜力风格图片与视频生成,用户输入“女孩站在樱花树下”等描述,AI可输出宫崎骏风作品,甚至生成5秒动态视频。这种能力源于文心X1的工具调用链技术,可连续完成推理、绘图、视频合成等复杂任务。
二、端到端语音大模型:成本砍半,方言自由
1. 技术突破:成本直降90%,响应快至1秒
百度推出的业界首个端到端语音语言大模型,基于全新互相关注意力(Cross-Attention)架构,实现两大飞跃:
• 成本革命:电话语音场景调用成本较行业降低50%-90%。
• 极速响应:语音交互等待时间从3-5秒压缩至1秒,接近人类对话流畅度。
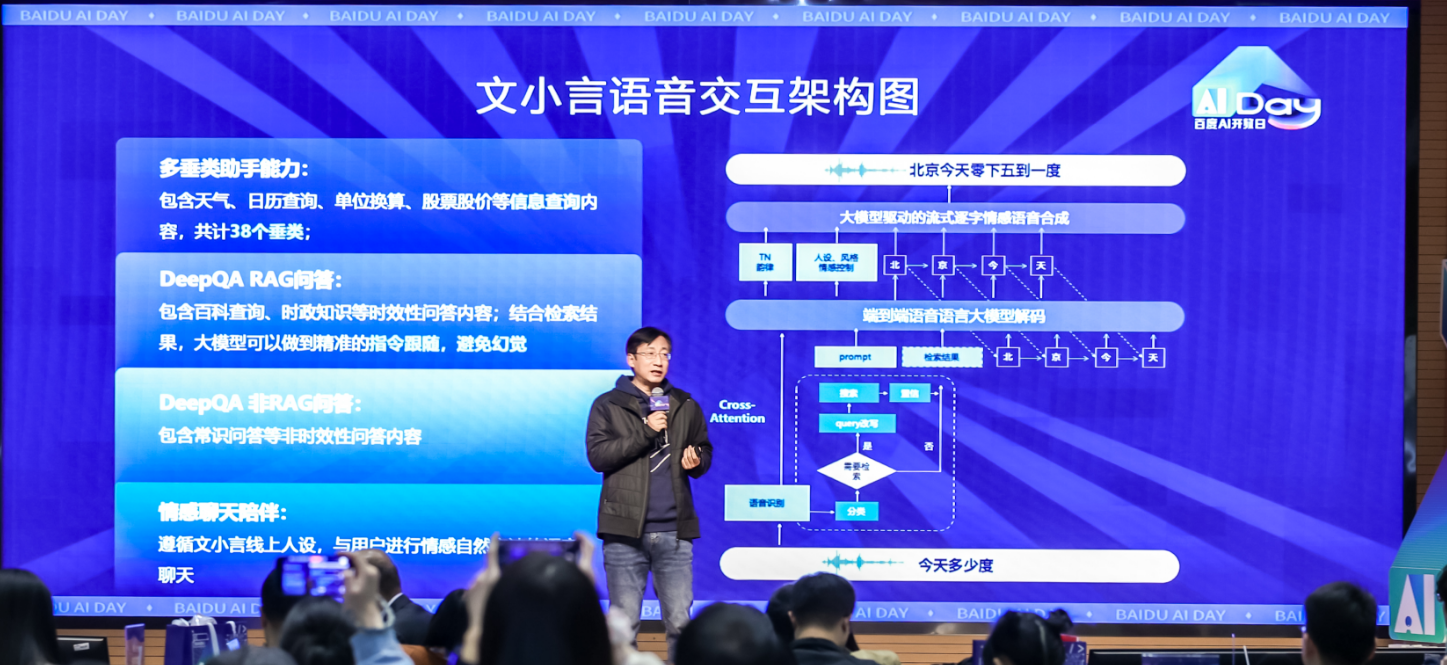
2. 方言自由与情感交互:AI的“人情味”升级
• 方言支持:重庆话、河南话、广西话等特色方言自由切换,甚至能用蜡笔小新音色讲睡前故事。
• 情感合成:通过流式逐字多情感语音合成,AI可根据场景切换情感,如兴奋、温柔、幽默,拟真度媲美真人。

3. 复杂场景应对:从知识问答到角色扮演
用户可随时打断对话,进行深度知识问答(如量子物理科普),或开启“孙悟空”“科技达人”等角色扮演模式。这种能力的背后,是语音大模型与LLM(大语言模型)的深度耦合,实现听-思-说一体化。

三、未来展望:AI如何重塑生活?
文小言的升级释放了三大信号:
- 技术民主化:低成本、高效率的AI技术正从实验室走向大众,未来人人都能拥有“私人智能助理”。
- 场景无界化:从教育、电商到创意设计,AI渗透至生活全场景,甚至能替代部分专业服务(如装修设计、旅游规划)。
- 生态开放化:百度通过引入DeepSeek等第三方模型,打破封闭生态,推动AI行业从“单打独斗”走向“协作共赢”。
结语
本次技术突破标志着智能交互从单一功能向系统性解决方案演进。随着多模态融合、低时延响应等技术的普及,预计到2026年,相关技术将赋能超过80%的在线服务场景。体验官网:https://www.wenxiaoyan.com/


















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











