







 本文介绍如何使用Python和cURL绕过浏览器自动完成校园网Web认证的过程。通过分析认证页面源码,利用cURL发送POST请求实现命令行下登录和注销功能,并提供Python脚本实现自动认证。
本文介绍如何使用Python和cURL绕过浏览器自动完成校园网Web认证的过程。通过分析认证页面源码,利用cURL发送POST请求实现命令行下登录和注销功能,并提供Python脚本实现自动认证。
基于python和cURL实现网络服务自动认证
bigben@seu.edu.cn 2016/4/15
Tags: Python, cURL, 网络接入
如今校园网上网一般都采用Web认证方式,即首先登陆网关页面,输入用户名和密码,认证成功后可以进行Internet接入,服务器端开始计费。例如移动的CMCC-EDU、联通的ChinaUnicom、电信的ChinaNet无线接入,都采用这种认证方式。此外东南大学校园网Internet接入也采用这种方式,当用户连接上seu-wlan后,客户端会自动获得一个IP地址,但是此时用户还不能访问外网。当用户在浏览器地址栏中输入www.baidu.com时,网页会自动重定向到w.seu.edu.cn。这就是东南大学上网认证的portal。
但是这样每次上网都需要启动浏览器,并输入用户名和密码,操作比较繁琐。此外,如果是通过ssh连接到远程主机,则用户只有一个虚拟终端,只能通过命令行进行操作,无法启动浏览器。此时如果用户需要连接外网怎么办?显然,如果这些认证工作能够绕开浏览器,直接在命令行下完成,那么所有问题都可以迎刃而解。这样只需在命令行下敲几行命令或者将相关操作写成脚本,下次直接运行这个脚本进行自动认证,无疑能极大提高效率。下面我们就对东南大学的网络认证portal做一下小小的hack来实现这一设想。
首先,我们获取w.seu.edu.cn的首页https://w.seu.edu.cn/portal/index.html源码,具体操作步骤为:
在浏览器中输入网址:https://w.seu.edu.cn/portal/index.html,右键点击查看源码即可。
如果用户安装了wget或者cURL, 也可以输入以下命令来获取首页:
wget https://w.seu.edu.cn/portal/index.html
OR
curl https://w.seu.edu.cn/portal/index.html
接下来我们分析一下首页的源码。搜索并定位到网页认证表单相关的代码,如下所示:
<form id="loginForm" name="loginForm" method="post" action="">
我们重点关注一下method和action属性。由代码可知:系统采用POST方式上传数据,但是action属性为空(一般action属性都设置为某个网址,即将表单数据上传到那个网址进行处理。此处action为空是因为网页通过JavaScript脚本进行处理,与数据提交相关的代码在JavaScript脚本中)。
接着我们发现在网页头部加载了一个JavaScript脚本,如下所示:
<script type="text/javascript" src="js/portal.js"></script>
下载这个js文件,我们对其源码进行分析。
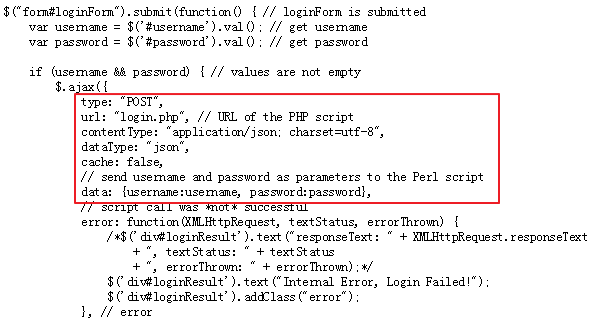
这份代码不是很长,经过分析我们可以找到下面两处代码,分别对应login和logout的处理(熟悉jQuery的童鞋应该能够看懂)。
Login:
Logout:
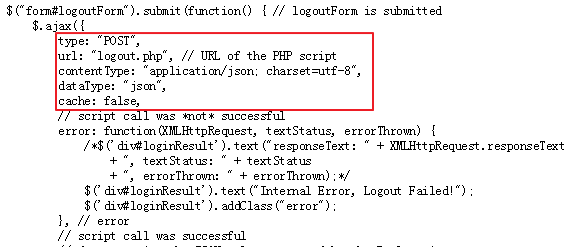
注意图中红色框中的内容,从中可知login和logout时是利用ajax将表单中数据POST到远端地址,并且数据格式为json,编码方式为utf-8。login时,提交的URL为login.php,即https://w.seu.edu.cn/portal/login.php, 提交的数据包括两项:username和password。对相应地,logout时向https://w.seu.edu.cn/portal/logout.php提交数据即可,数据为空。
至此,我们已经弄清楚了Web认证的全部流程。下面就可以在命令行下模拟这一过程,从而实现命令行下的网络服务认证登录。
如果用户已经安装了cURL,直接输入下面的命令。
Login
curl -A 'Mozilla' -d "username=<username>&password=<password>" http://w.seu.edu.cn/portal/login.php
将<username>和<password>换成你自己的用户名和密码即可。
Logout
curl -A 'Mozilla' -d "" http://w.seu.edu.cn/portal/logout.php
cURL -A选项用于设置User-Agent,可以省略不写。而cURL通过-d选项POST数据,正是本次hack的核心所在。
为了实现自动登录,只需要将上述命令保存为一个shell脚本,下次直接运行这个脚本即可。或者将该命令加入rc.local中。
#! /bin/bash
function do_login() {
username=$1
password=$2
curl -d "username=${username}&password=${password}" http://w.seu.edu.cn/portal/login.php
}
function do_logout() {
curl -d "" http://w.seu.edu.cn/portal/logout.php
}
case "$1" in
login)
shift
echo "connecting server at w.seu.edu.cn/portal/login.php"
do_login "$@"
[ ! $? == 0 ] && echo "abc.sh login <username> <password>"
echo -e "\n"
;;
logout)
echo "connecting server at w.seu.edu.cn/portal/logout.php"
do_logout
version)
echo "version: 1.0.0"
;;
help|*)
echo "abc.sh login|logout|version|help"
;;
esac我们也可以利用Python脚本来实现这些功能。对于这种简单的操作来说,使用Python似乎有点小题大做,但是利用Python可以实现更强大的功能,例如从命令行输入用户名和密码,以及对服务器返回状态的解析等等。以下是Python代码,供参考。
#! /usr/bin/python
import sys, getopt
import urllib, json
__author__ = "bigben@seu.edu.cn"
__version__ = "1.0.0"
# login
def login(params):
response = _post_data("http://w.seu.edu.cn/portal/login.php", params)
_dump_status(response)
# logout
def logout():
response = _post_data("http://w.seu.edu.cn/portal/logout.php", '')
_dump_status(response)
def _post_data(url, data):
return urllib.urlopen(url, urllib.urlencode(data)).readlines()[1]
# dump_status (response is JSON-formatted string)
def _dump_status(response):
status = json.loads(response)
print("Status: ")
for k in status:
print("%-15s: %s" %(k, status[k]))
def usage():
print("abc v 1.0.0\nby bigben@seu.edu.cn\nabc help|version|login|logout")
def do_login(args):
try:
opts, args = getopt.getopt(args, "u:p:", ["help", "version", "user=", "password="])
except getopt.GetoptError as err:
# print help information and exit:
print str(err)
usage()
sys.exit(2)
params = {'username' : "", 'password' : ""}
for o, a in opts:
if o == "-v":
print("Version: %s", "1.0.0")
elif o in ("-h", "--help"):
usage()
sys.exit()
elif o in ("-u", "--user"):
params['username'] = a
elif o in ("-p", "--password"):
params['password'] = a
else:
assert False, "unhandled option"
login(params)
def do_logout():
logout()
if __name__ == '__main__':
if (len(sys.argv) < 2):
print("operation must be specified, valid operation(s) are help|version|logint|logout")
usage()
sys.exit(-1)
cmd = sys.argv[1]
if cmd == "help":
usage()
sys.exit()
elif cmd == "version":
print("Version: %s" %"1.0.0")
sys.exit()
elif cmd == "login":
do_login(sys.argv[2:])
elif cmd == "logout":
do_logout()
else:
print('Invalid command: %s' %(cmd))运行结果如下:
Login
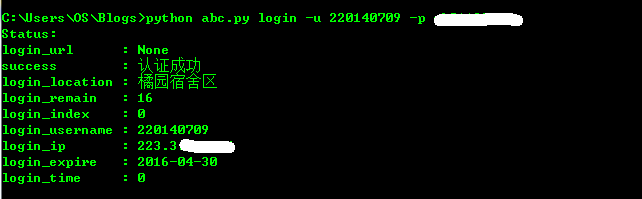
此时如果刷新http://w.seu.edu.cn/portal/页面就会看到此时已经登录成功。
Logout

最后,再补充点题外话,在Windows系统下,拨号连接也可以通过命令行来完成。
例如,橘园宿舍网口可以访问IPV6教育网资源,账号为test@seujs,密码为1234,接入后可以访问教育网内部资源。
用户需要首先新建一个拨号连接,将其命名为“Bras Seu”(名字可以随便起)。然后插入网线,在命令行输入以下命令进行即可连接:
rasdial "Bras Seu" test@seujs 1234
连接成功后在浏览器地址栏中输入"www.6rank.edu.cn"进行测试,若能正常访问,代表成功接入教育网。
在命令行下输入”rasdial /?”可以查看rasdial命令的帮助。
有兴趣的同学可以试试。
后记:这是半年前写的一篇技术博客,今天偶然翻出来了。最近校园网认证系统正在进行升级,不知道上面的脚本是否还能生效,等改天有时间再好好研究一下。

















 3497
3497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









