







原文链接:
码个嘚:变形金刚Transformer(2017) -万字长文详解
关注我

Transformer是谷歌在2017年的论文《Attention Is All You Need》中提出的,用于NLP的各项任务,在NLP领域中,几乎已经全面取代了RNN;在CV领域也是大放异彩,与CNN分庭抗礼,占据了半壁江山!
Transformer中没有用的RNN也没有CNN(但会用到与RNN、CNN相关的先验的知识)。
Transformer网络架构能够干所有Seq2Seq (with Attention) 能干的事情,并且效果更好。

Transformer网络架构
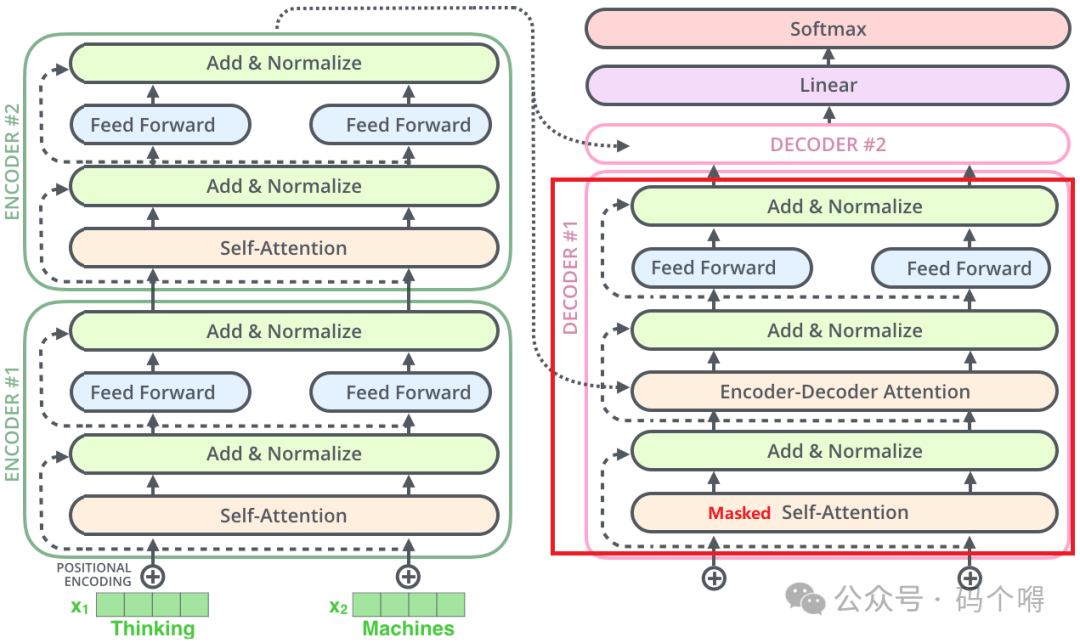
从整体来看,Transformers是很多歌Encoder与Decoder的堆叠,输入数据会经过一系列的encoder进行提取特征(1个encoder特征提取的可能不够好,那么就多来几个),同样有多个decoder,并且最后一个encoder的输出会是每个decoder的输入(每个decoder都会用到原始信息来辅助解码)
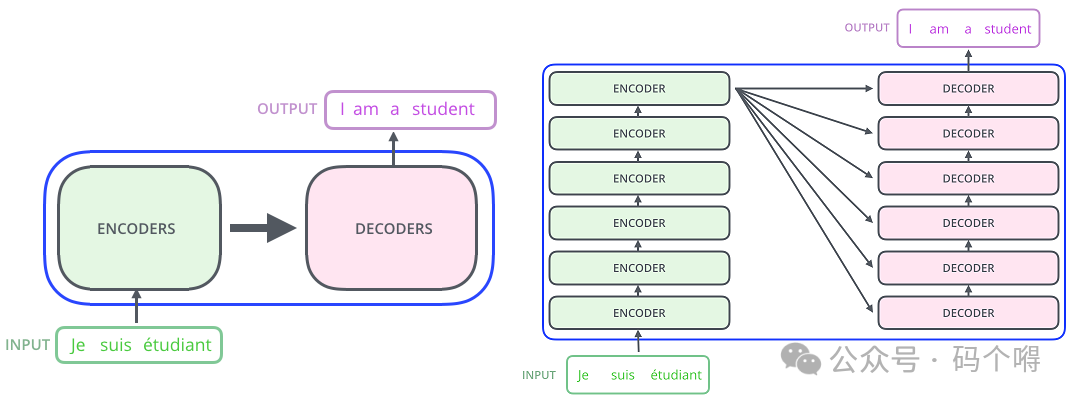
Transformer中的encoder与decoder:
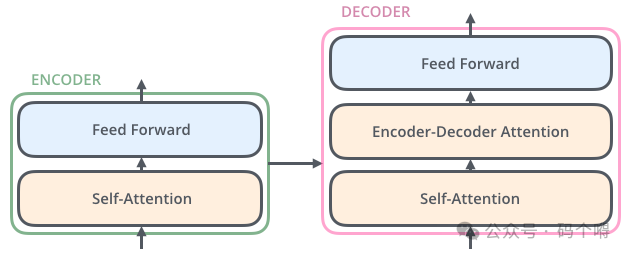
Encoder在结构上都是相同的(但它们不共享权重),每一个都被分解为两个子层:Feed Forwoard和Self-Attention;
输入数据首先流经自注意力层,该层帮助编码器在编码特定单词时查看输入句子中的其他单词。自注意力层的输出被馈送到前馈神经网络(可以理解为是全连接层的正向传播);
Decoder同样有Feed Forwoard层和Self-Attention层,但在它们中间还有Enocder-Decoder Attention层(注意力层,类似上面讲的Attention注意力机制,该层既用到了Encoder的输出也用到了Decoder的输出,
同时加入了Attention机制,所以称为Enocder-Decoder Attention),注意力层帮助解码器专注于输入句子的相关部分(类似于注意力在seq2seq模型中的作用);
Self-Attention
Self-Attention是attention的一个特例,对于一句话,来计算该句话自身每个单词之间的相关性,即对一个词进行编码的时候,不是简单的只考虑这一个词,而是考虑整个上下文语境,同时降整个上下文语境融入到该词的词向量之中。
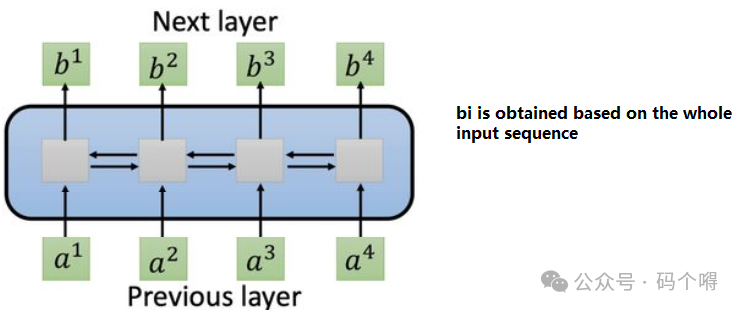
之前学过的双向RNN(BiLSTM),也是能够实现通过上下文来理解一句话的,例如下图。
但是BiLSTM很难去并行计算,在正向传播时,若需要预测b3,那么必须先输入a1,a2,预测出b2,然后再输入a3通过b2,a3才能预测b3,也就说b3需要等待b2先出来;
反向传播也是一样,必须将b1,b2,b3,b4全部预测完成后才能进行反向传播;这就导致它很难进行并行运算,导致训练和预测时比较慢。
然后有人提出使用CNN来代替RNN来处理输入是一个sequence这种情况,如下图:
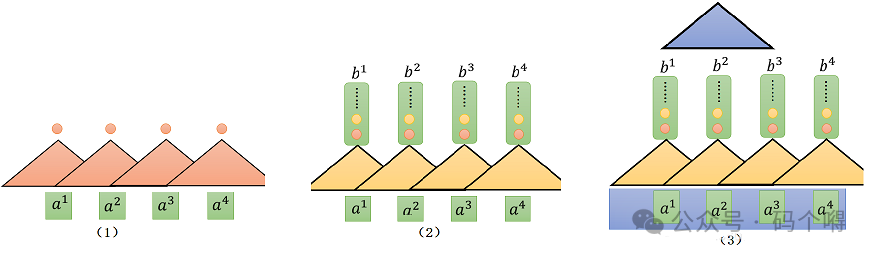
每一个三角形都代表一个filter(卷积核),那现在的输入就变成了序列中的其中一小段:
比如图(1)中红色的filter,三个向量作为输入,然后输出一个数值。该filter将这三个向量做内积,输出一个红色的点,这个红色的点就代表内积之后的结果。这样filter有多个,有红色的卷积核,黄色的卷积核(图(2)所示),当然,黄色的卷积核产生另外一排不同的数值。
所以用CNN确实也可以做到与RNN的输入输出一致的形式,而CNN是可以并行计算的。
但是现在问题是:CNN中的每个filter,只能够考虑非常有限的内容,只是根据句子的部分内容来预测,而不是根据整个句子内容来预测(也就是无法考虑到更多的上下文信息),只有增加网络深度来扩大filter的感受野,才能让filter"看完"整个句子,若句子很长,那么网络深度会很深,增加模型训练难度。
有一个更好的解决方案,叫self-attention,这个层的作用就是取代RNN原来可以做的事情,假设,有一个句子(sequence) 是由x1,x2,x3,x4四个词组成:
1) 先将4个词x1,x2,x3,x4依次输入(输入的是词x经过one-hot编码后得到的向量);
2) 将每个输入都乘以一个词嵌入矩阵W,得到每个输入的embeding(词嵌入向量):a1,a2,a3,a4;
3) 然后将a1到a4丢进self-attention layer,那self-attention layer里面是做什么呢?
它要做的事情就是提取特征,看一下每个词分别对于当前词有什么关联(贡献),比说对a1来说,a1,a2,a3,a4分别与a1的关联度是多少,然后对a1重新进行编码,也就是将各个词之间的关联信息融合到了新的向量中。
在self-attention layer中,借助了3个矩阵Wq、Wk、Wv来做这件事,对每个输入,都分别乘上3个不同的矩阵Wq、Wk、Wv,产生3个不同的向量,将这3个不同的向量分别命名为q、k、v。
例如将a1分别乘上矩阵Wq、Wk、Wv,得到q1、k1、v1(矩阵Wq、Wk、Wv就是需要训练学习的参数)。
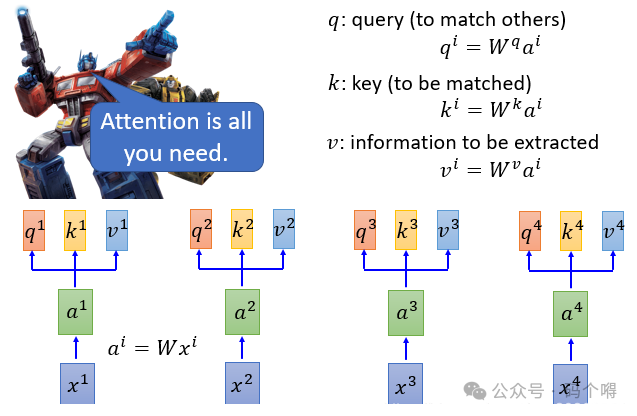
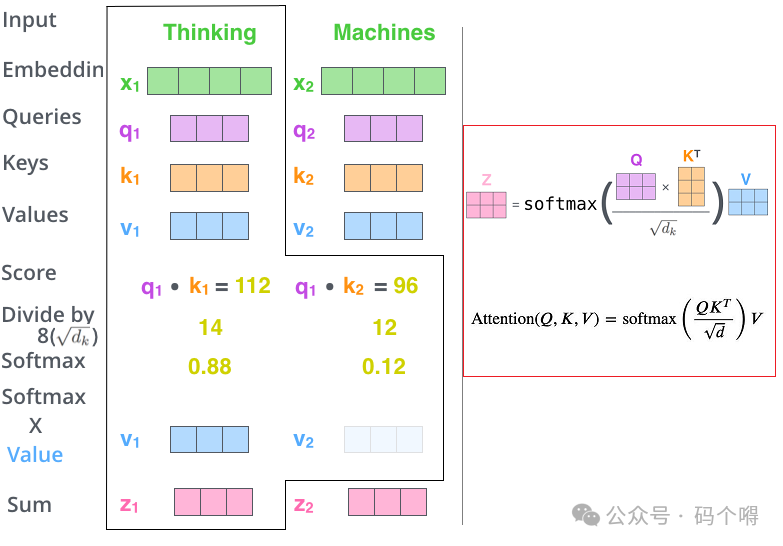
q即query,也就是要去做查的词的向量。查什么呢?就是去逐个match(匹配/查询)句子中其他的词,看一下其他词与当前词有多大关联,例如q1就是词a1用来去做查询的向量;
k即key,是用来被query向量match的向量,例如词a1去逐个match句子中其他的词,就会用q1分别与k1,k2,k3,k4去做计算(k1,k2,k3,k4分别是词a1~a4的key向量),每一个query q去对每一个不同的key k做attention:
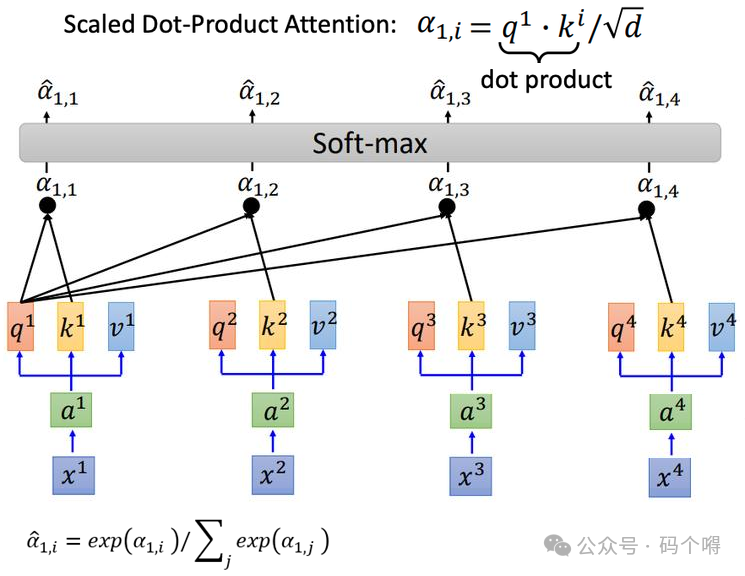
q1对k1做attention得到α1,1;
q1对k2做attention得到α1,2;
q1对k3做attention得到α1,3;
q1对k4做attention得到α1,4;
v即value,v是被抽取出来的特征信息,例如v1就是从词a1中提取出来的特征信息;
补充:
1) attention的本质就是输入两个向量,输出一个值代表这两个向量有多匹配,总之就是输入两个向量,输出一个分数(match分数),表示这两个向量有多匹配;
2) attention计算方式有很多种,这里采取图片中的方式(归一的内积注意力机制),先内积(余弦相似度)再除根号d。d是k和v的维度,因为k和v可以做内积,因此k和v的维度是一样的。至于为什么除以根号d,一个直观的解释是为了防止内积得到的值太大(当k,v维度较多时内积值可能会很大)。
得到α1,1~α1,4,经过一个softmax层进行归一化,这样就计算出了q对k做attention后的权重值α1,1_hat ~ α1,4_hat,过程见下图:
然后使用
![]()
(即α1,1_hat,α1,2_hat,α1,3_hat,α1,4_hat)分别乘以v1, v2, v3, v4,得到4个向量,然后将这4个向量相加求和,得到向量b1;
使用相同的方法得到b2, b3, b4 ,这样b就是一个考虑到了整个句子(Sequence)的上下文向量Context,例如b1就是融合了上下文后的词a1的向量:
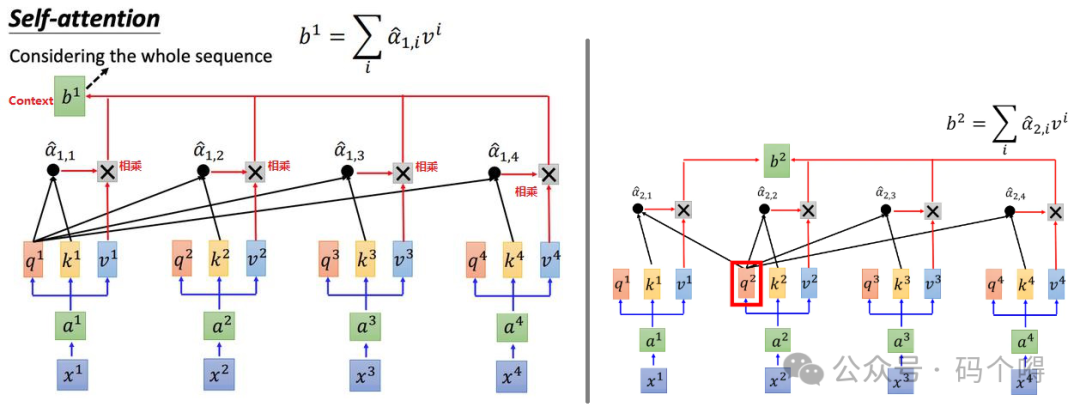
从上面b的计算方式可以看出,b的计算与x1,x2,x3,x4的输入顺序是无关的(只是使用词向量来计算的)。同时我们发现产生b时,例如b1,同样是考虑到了整个Sequence的信息(b1是通过v1~v4加权求和得到的)。
假设在产生b1时不想考虑整个Sequence信息,只想考虑局部信息,self-attention layer也是能够做到的,若只考虑的局部的信息,将其他的α设置为0即可;若想考虑远一点的信息,如a4,只要让α4有值即可;对于b1来说,就有一种天涯若比邻的感觉。
另外,即便是同一个词,例如 "我爱吃苹果" 、"我有一个苹果手机"中的"苹果",因为"苹果"这个词的上下文是不同的,所以经过self-attention层之后,"苹果"这个词对应的向量b也是不同的,这也就实现了不容的语义下同一个词的不同含义。
因为b的计算与输入的顺序无关,所以self-attention layer是可以进行并行计算的:
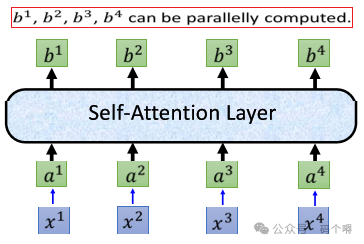
接下来,从数学(矩阵计算)的角度去理解self-attention layer的计算流程:
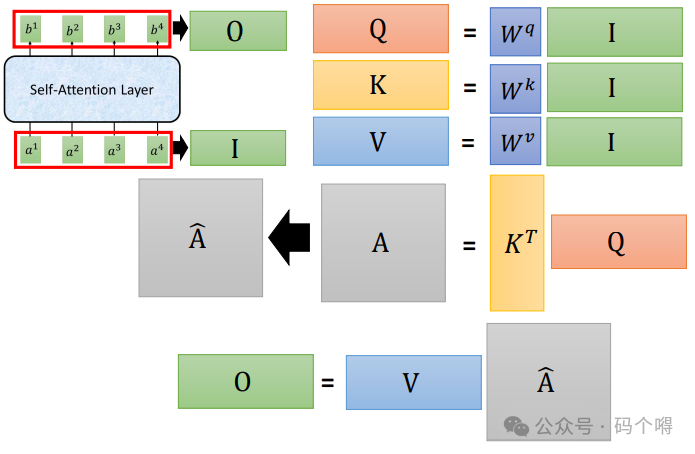
1) 计算q, k, v:
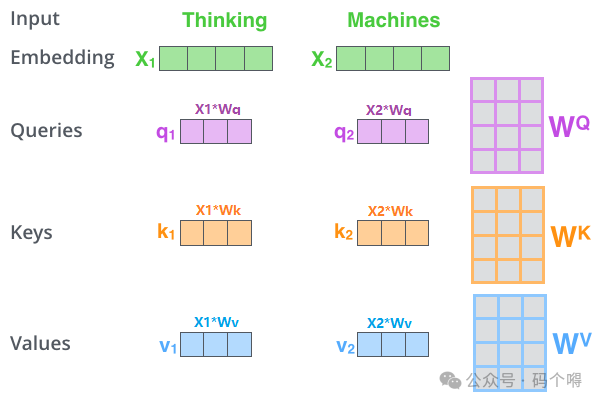
通过下图可看出,只需要将输入序列单词的词向量,进行堆叠后构成序列单词的词向量矩阵,然后分别与Wq、Wk、Wv矩阵相乘,就能够得到Q,K,V矩阵(而我们知道,矩阵是可以并行运算的)
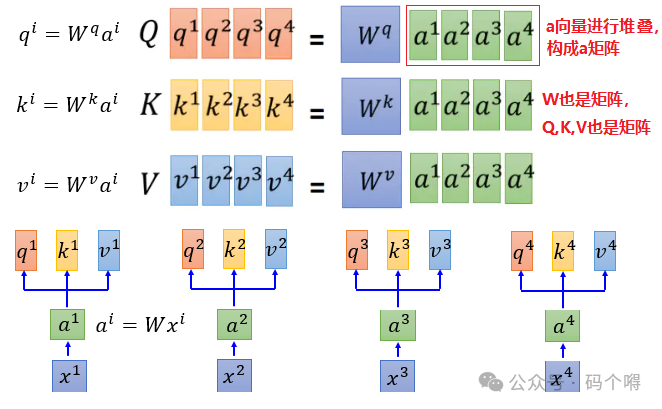
下图同样是表示q,k,v的计算流程:
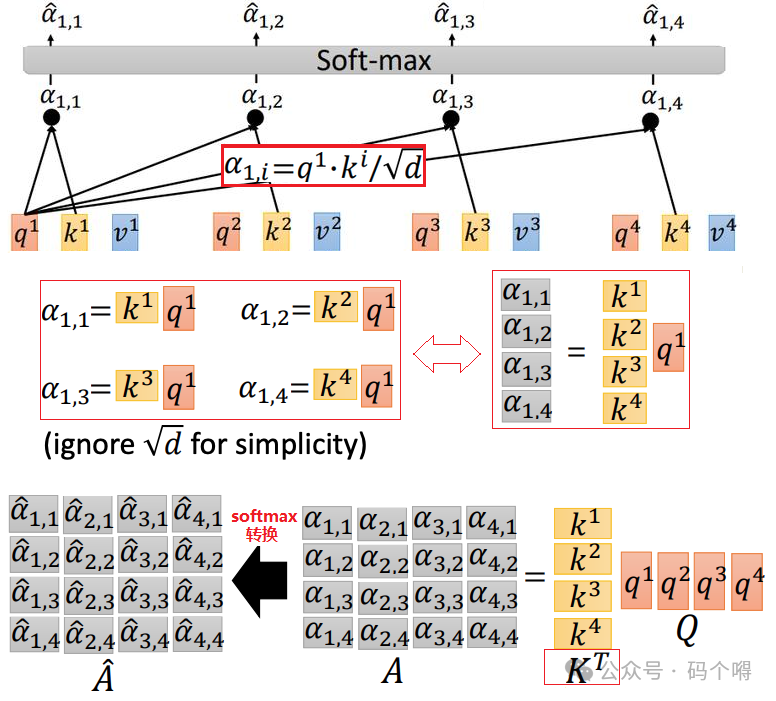
2) 计算权重值α:
使用上面计算出来的q, k, v来计算权重值α,通过下图可看出α的值也可以通过矩阵计算出来KT*Q
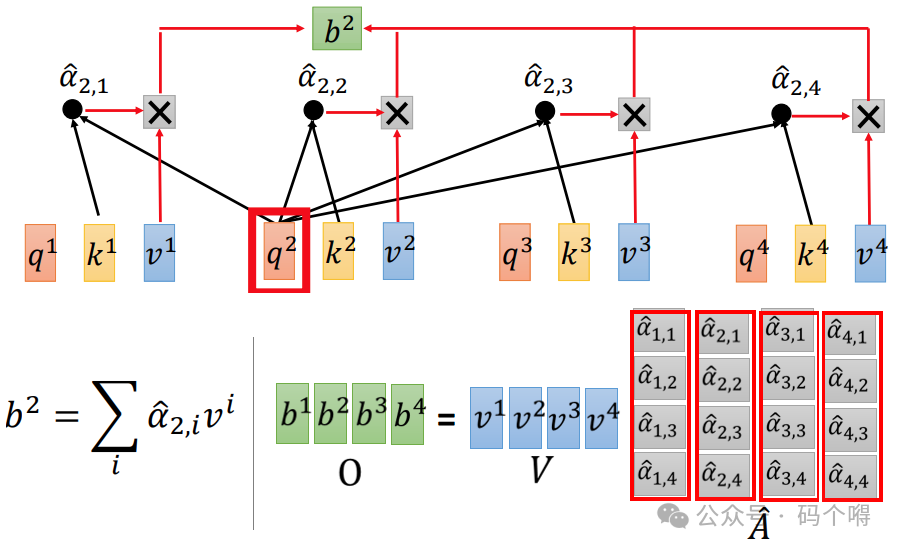
3) 计算b向量:
V是由v1, v2, v3, v4堆叠构成的矩阵,V矩阵与的每一列相乘分别得到b1 ,b2 ,b3 ,b4向量。
下图同样表示的是self-attention layer的整个计算流程(图中的z就是上面提到的b):
总结:Self-attention layer 中的计算流程就是一堆矩阵的乘法,所以可以用GPU可以加速!
下图中颜色的深度表示相关性的强度:
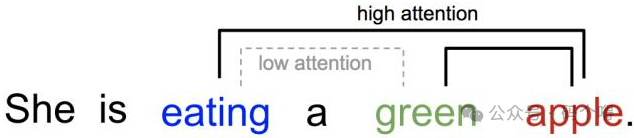
"她正在吃一个绿色的苹果",这句话中,"green"与"apple"有较高相关性,"eating"与"apple"有较高相关性;
在一句话内部,看看各个单词之间的相关性,这就是Self-Attention(自注意力)。
在NLP(自然语言处理)中,Self-Attention是很有必要的,比如语言中有很多代词,it/her/he/它/她/他,在一句话中只有理解了这个代词指代的是什么,才能够更好的理解这句话(计算机也是如此),Self-Attention能够更好的做到“指代消歧”。
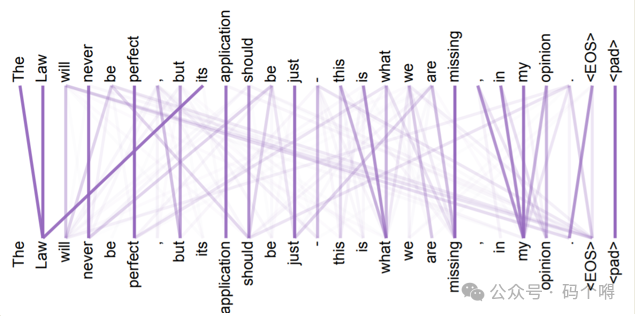
例如下图,使用transformer来训练英语翻译到法语的模型,在encoders中的第5层到第6层中对 "it" 这个词的注意力分布的可视化,可见transformer能够识别出 "it" 指代的词是什么(这就是attention的作用):

Self-attention与Attention的关系
前面学习的Attention机制,关注的是两个句子(Sequence)之间单词的相关性,例如 "i am a student" 、"我是一个学生"这两个句子,Attention机制关注的是 "i"与"我"的相关性,"student"与"学生"的相关性:
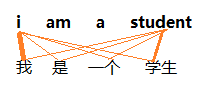
Self-attention关注的是一个句子(Sequence)内部的单词之间的相关性,可看做是attention的一个特例(两个句子,只不过这两个句子是相同的)。Self-attention就是Q, K, V来自于同一个序列(Sequence),于前面的 Encoder-Decoder Attetion,Q, K, V是来自不同的序列(K来自于decoder,Q, V来自于encoder)。
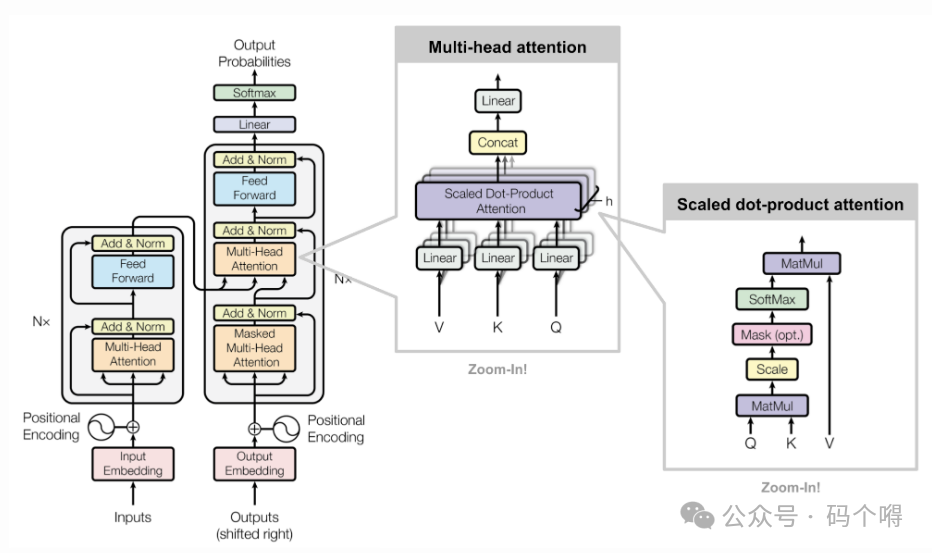
Multi head(多头注意力机制)
Multi head是对Attention注意力机制的优化:
前面在attention中只是训练了一组Wq、Wk、Wv,可能效果不是很好(只提取一组特征),所谓Multi head就是训练多组Wq、Wk、Wv,每组都会有不同的注意力分布,好处就是每个时刻可以同时关注多个地方(提取多组特征)。就类似卷积网络中的卷积核,一个卷积核只能关注某一个特征,多个卷积核就能关注多个不同的特征。
Multi head层会同时使用多组self-attention,例如head=7时:
对于词a1就会得到7个包含了上下文信息的向量分别是Z0~Z7,但Z0~Z7是词a1的不同的特征表达,然后将Z0~Z7拼接,也就是将词a1的不同的特征表达融合到了一起,即向量Z包含了词a1多种特征表达。
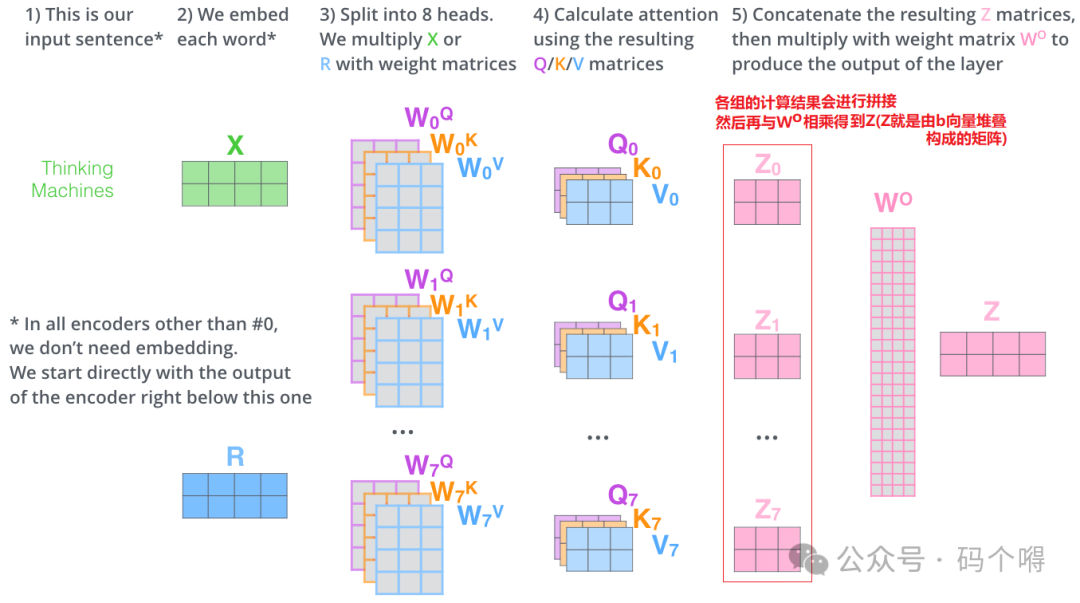
这里解释下Wo矩阵,通常Wo是一个Feed Forward层(全链接层),因为Z0~Z7拼接之后的向量会比较大,所以会使用一个全链接层来进行降维,得到降维后的向量Z。
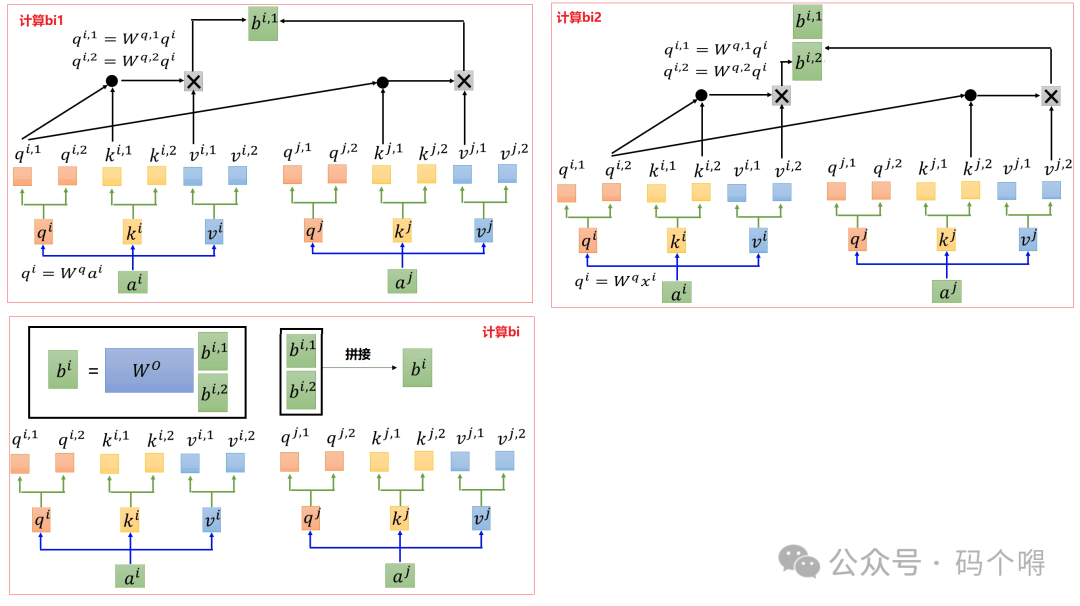
计算过程如下(以head=2为例):
qi、ki、vi可以继续乘以各自的权重获得qi,j、ki,j、vi,j,比如qi,1=Wq,1•qi,qi,2=Wq,2•qi.... ,qi,m=Wq,m•qi,同理获得ki,1、ki,2与vi,1、vi,2;
然后分别将对应的qi,m(qi,1, qi,2)与对应的ki,m(ki,1, ki,2)做attention得到对应的权重αi,j,m(αi,1,1,αi,1,2,αi,2,1,αi,2,2),接着使用权重αi,j,m和vi,j计算出bi,m(即bi,1,bi,2);
然后将进行contact(拼接)后,与权重矩阵Wo相乘得到向量bi,整个过程如下图所示:
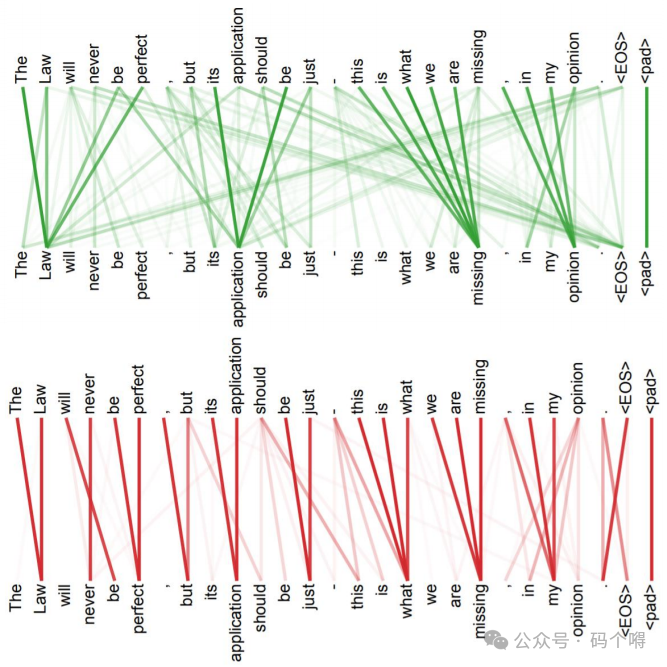
下图展示了Multi-Head Attention的不同head的可视化结果(head=2,即2组self-attention):
绿色,红色各代表一组self-attention的结果,可以看到每组的self-attention的结果是不同的,也就是同一个词的"关注点"是不一样的。
Feed Froward层
Feed Froward层是一个正向传播的网络,该层的输入是某个时刻某个单词x1经过self-attention layer的输出(也就是b1/z1向量),输出是r向量,r向量会被当做单词x1的词嵌入向量,继续输入到下一个Encoder中,依次实现Encoder的串联:
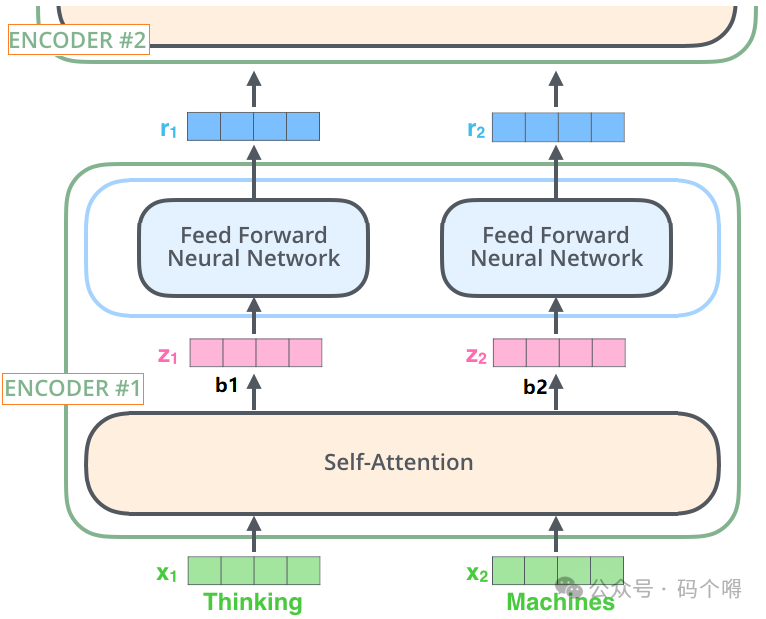
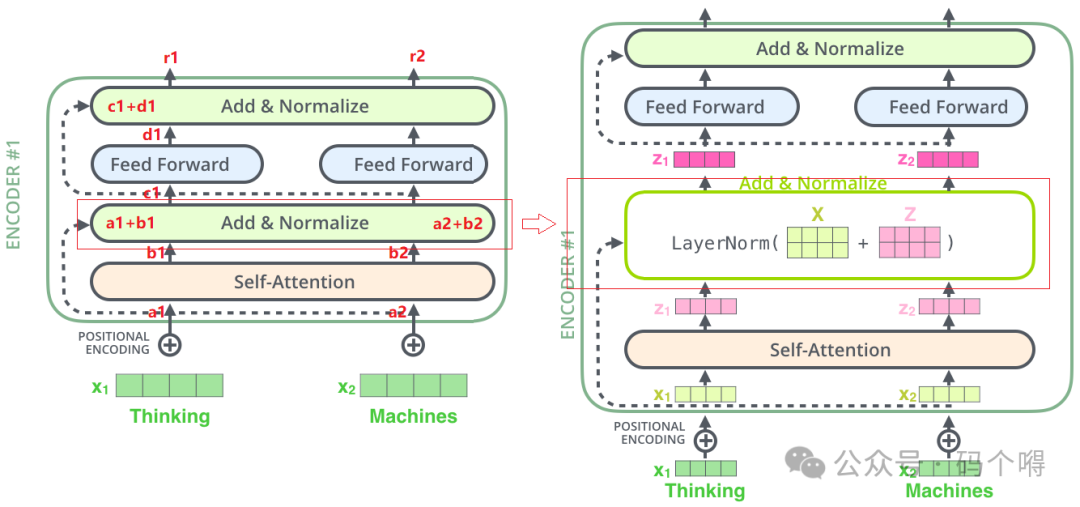
Encoder中残差与归一化
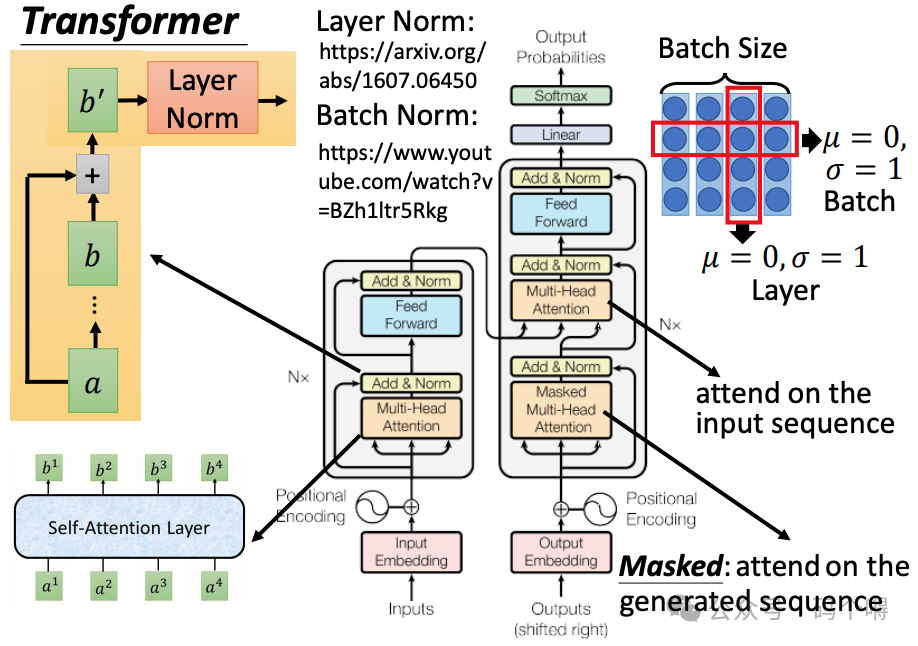
Encoder中除了使用了正向传播,还引入了残差思想,说白了就是将前面的层直接抛给后面的层,前面的层和后面的层采用相加的方式进行融合(shortcut[短接])。
同时还使用了归一化,在CNN中我们使用的归一化是Batch Normalization,BN是在不同样本之间进行计算的。在RNN中归一化常用Layer Normalization,LN是在同一个样本上计算的。在Transformer中使用的是Layer Normalization;
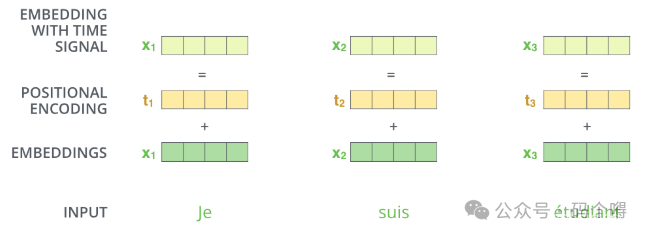
Position Embedding位置信息
上面我们提到,self-attention layer是不关注单词的输入顺序的,是一个词袋模型(BoW)不考虑词语在句子中的先后顺序,有些任务对词序不敏感,有些任务词序对结果影响很大。
例如机器翻译,"我爱你" 和 "你爱我" 的 翻译结果是不相同。不考虑位置信息的话,"我爱你" 和 "你爱我"Encoding 的结果是相同。
Position Embedding 一般用于:
1) 非RNN网络(RNN网络是有顺序的),由于不能编码序列顺序,需要显示的输入位置信息,如CNN seq2seq;
2) 需要加强位置信息。如句子中存在核心词,需要对核心词的周边词着重加权等。
《Attention is All You Need》中的Transformer模型用到了Position Embedding。Transformer 摒弃了之前机器翻译任务中常用的 RNN 结构,使得并行性更好。RNN的这种结构天生考虑了词语的先后顺序关系。当Transformer 模型不使用 RNN 结构时,它就要想办法通过其它机制把位置信息传输到 Encoding 的部分。
所以在该模型中中,每个时刻的输入是 Word Embedding+Position Embedding,也就是输入词的词向量与位置编码向量加和后再传入到self-attention layer中。
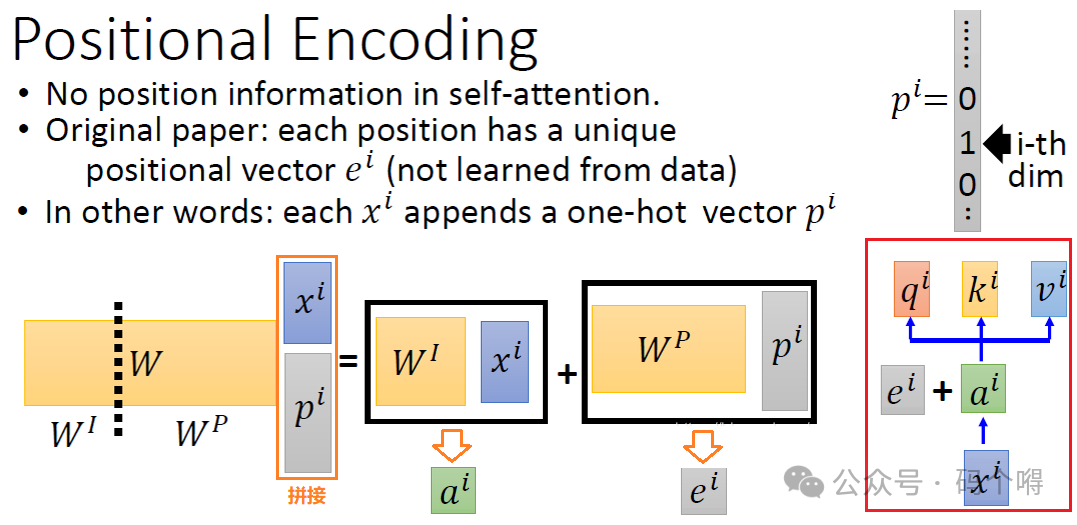
为什么是词向量ai与位置编码ei向量相加而不是词的one-hot编码xi与位置编码pi(位置的one-hot编码)拼接呢?
假设采用拼接的方式,xi与pi拼接(xi是词的one-hot编码,pi是词所在位置的one-hot编码),拼接之后如果我们想要得到ai,那么就需要用拼接后的结果[xi,pi]与W矩阵相乘,来得到跟原来形状一样的向量ai,若将W看做是由WI与WP拼接而成的,那么就有:
W*[xi,pi]T = [WI,WP]*[xi,pi]T =WI*xi + WP*pi
WI*xi就相当于是向量ai;WP*pi就相当于是向量ei;
所以采用拼接的方式与采用相加的方式效果是一样的!如下图:
Position Embedding 是一个向量,例如是128维的向量(具体长度根据输入的词向量的长度而定),是人为规定的一个向量,用来代表一个位置,是不需要进行训练的。
Position Embedding 有多种方法可以获得每个位置的编码ei,例如:为每个位置随机初始化一个向量,在训练 过程中更新这个向量;
《Attention is All You Need》使用正弦函数和余弦函数来构造每个位置的值。作者发现 该方法最后取得的效果与 Learned Positional Embeddings 的效果差不多,但是这种方法可以在测试阶段接受 长度超过训练集实例的情况

Decoder
Masked Self-Attention Layer:
Decoder中的第1个self-attention是单向的(Endcoder-Decoder Attention层中也是有self-attention的):在Encoder中,self-attention是双向的,因为在编码的时候,输入的是完整的一句话,所以句子中的单词(从开头到结尾)两两之间都可以互相算attention;
在Decoder是预测完成1个词之后再预测下1个词,所以第1个self-attention只能对前面的进行计算 attention(因为此时不知道后面的词是什么);比如现在是要预测 yt,那么肯定已经知道y0, y1, y2一直到yt-1了嘛,就是让yt对y0, y1, y2,...,yt-1这些已经预测好词的来进行self-attention计算;
在预测yt的时候,还不知后面时刻的词是什么,所以在计算attention的时候需要将后面的词屏蔽掉,屏蔽的方式就是在计算softmax的时候把权值降至为一个非常小的值就行了,屏蔽掉后面的相当于是将后面的"遮盖"住,所以Decoder中的第1个self-attention也会被称为Masked Self-Attention。
Masked Self-Attention Layer是对生成后的句子(Sequence)来做self-attention;
Encoder-Decoder Attention:
在encoder-decoder attention层中是把刚讲过的yt对y0, y1, y2一直到yt-1做self-attention的当作Q,之前的encoder 的多个时刻的输出当作K和V,Q作为query,匹配Encoder中输入的每个时刻(K就是to be matched);
Encoder-Decoder Attention是使用生成后的句子来对输入的句子做attention;
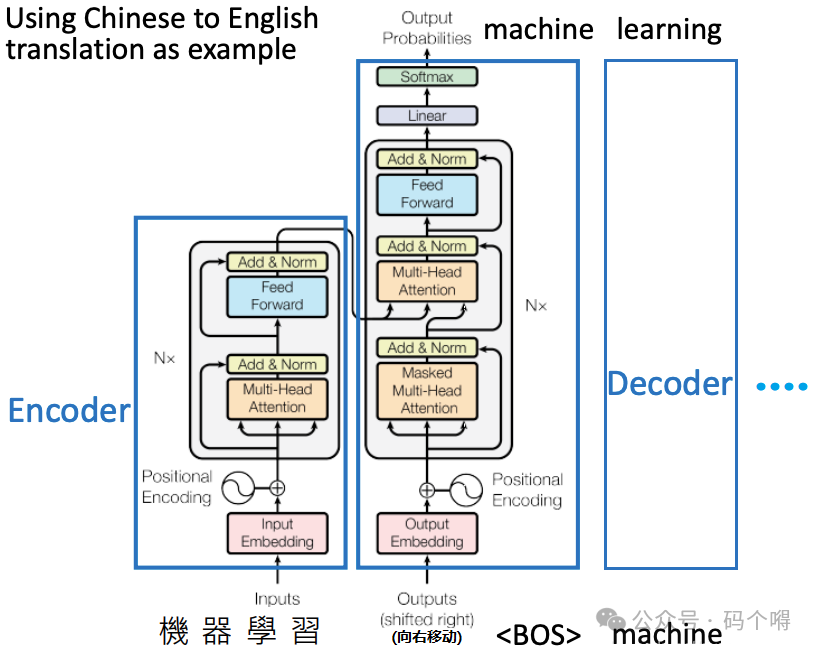
Transformer整体架构流程
以文本翻译(translation)来举例(机器翻译、对话都是如此)说明transformer运作流程,如下图:
Encoder可以一次性将整个句子(Sequence)输入进来,例如输入"机器学习";
Decoder是一个时刻一个时刻来运行的,比如,第1时刻Decoder的输入是"<BOS>",预测出概率最大的单词"mechine",然后将"<BOS> mechine"两个词作为第2时刻的输入,预测第2时刻的输出"learning",然后将"<BOS> mechine learning"三个词作为第3时刻的输入,...,一直到最后一个时刻;
需要注意的是:
每个时刻的Decoder都是使用相同的Encoder的输出;
同时也做了一次Decoder-Encoder的attention,即编码器和解码器之间的attention,用到了Encoder中的K,V和Decoder中的Q,这样就综合的利用了编码器的信息,在Decoder中的每个次也要去考虑在Encoder中的信息中的关系;
都看到这里了,欢迎关注我:


















 2151
2151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









