










想学Transformer的理论前,最好了解一下Attention与Self-Attention的起源,这样方便抓住整个脉络,这种东西慢慢来才会快。
1.Attention first show is in Seq2Seq architecture[Year2015]
2.Self-Attention first show is in Lstm network[Year2016]
Attention is all you need
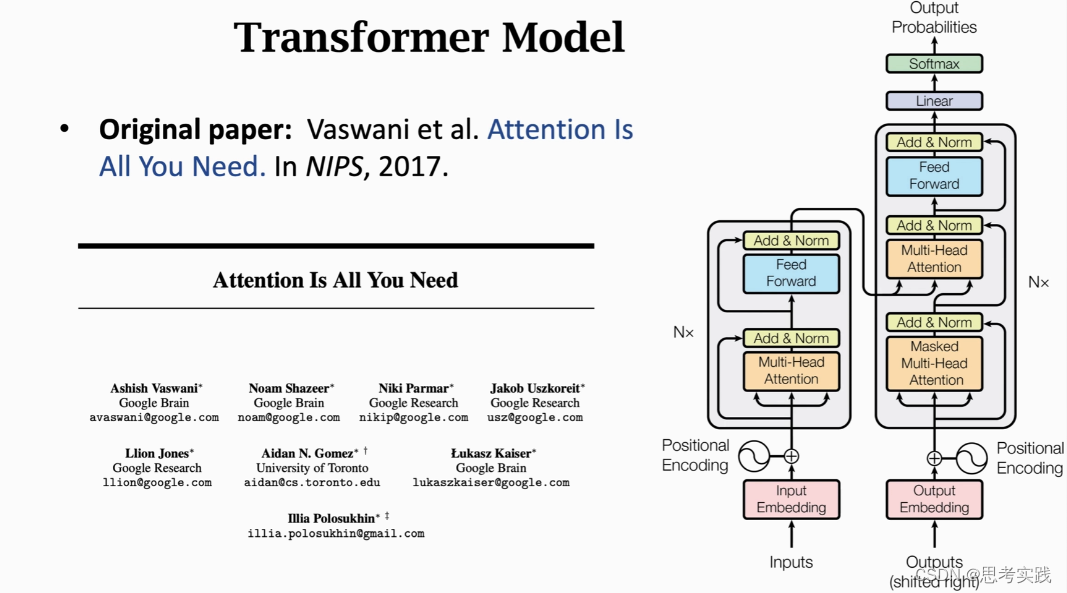
浅浅的了解Transformer的前世今生从Attention出发
目录
首先咱们回顾一下Attention for Rnn(attention in Seq2Seq)
思考一下如何才能剥离Rnn,只保留attention?(Transformer是纯attention)
Transformer:From Shallow to Deep
首先咱们回顾一下Attention for Rnn(attention in Seq2Seq)
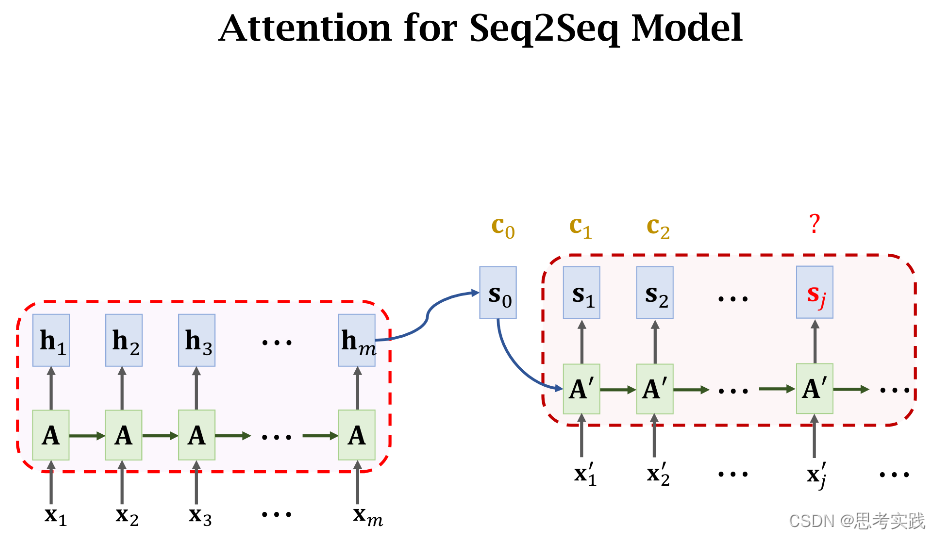
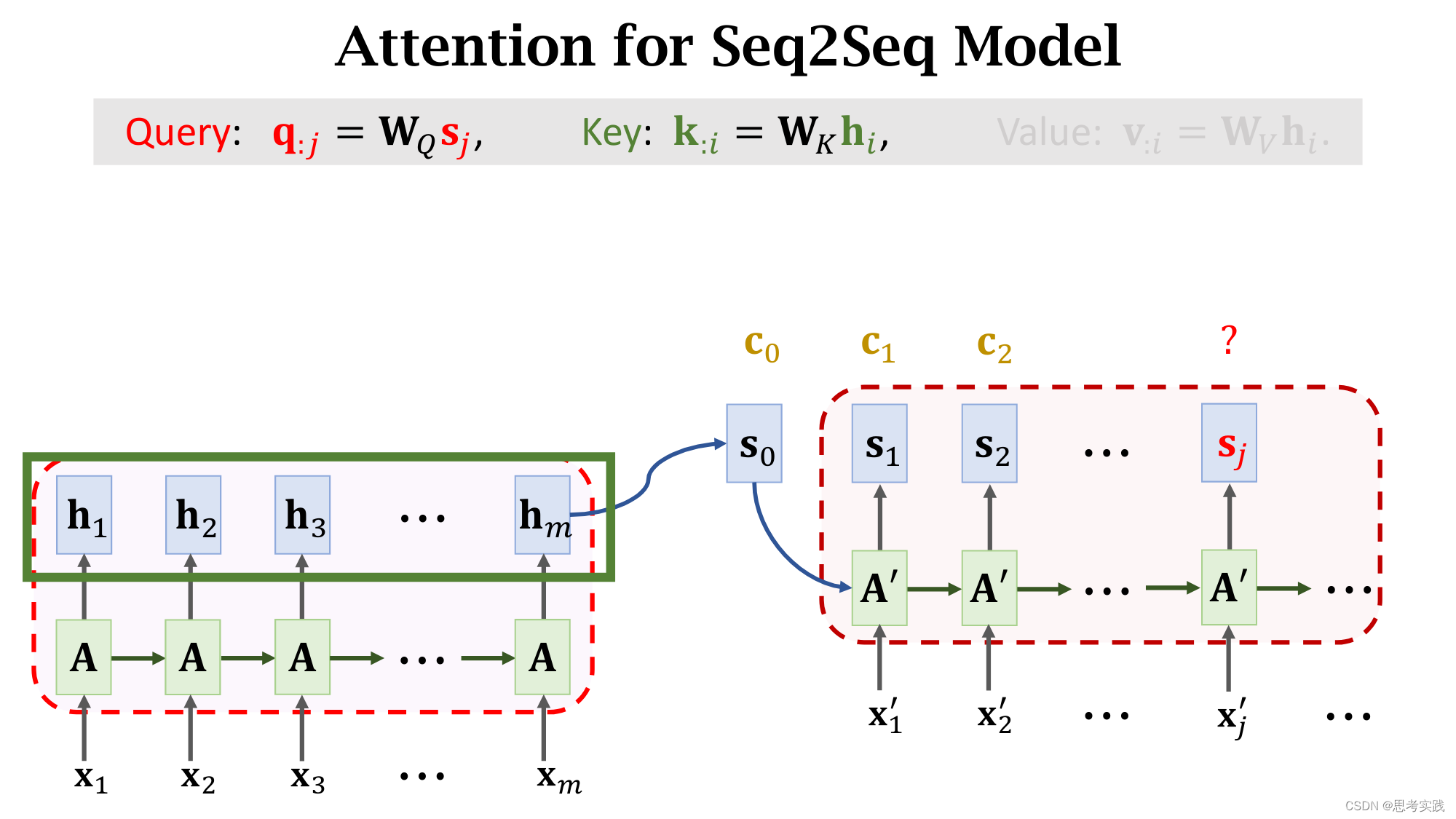
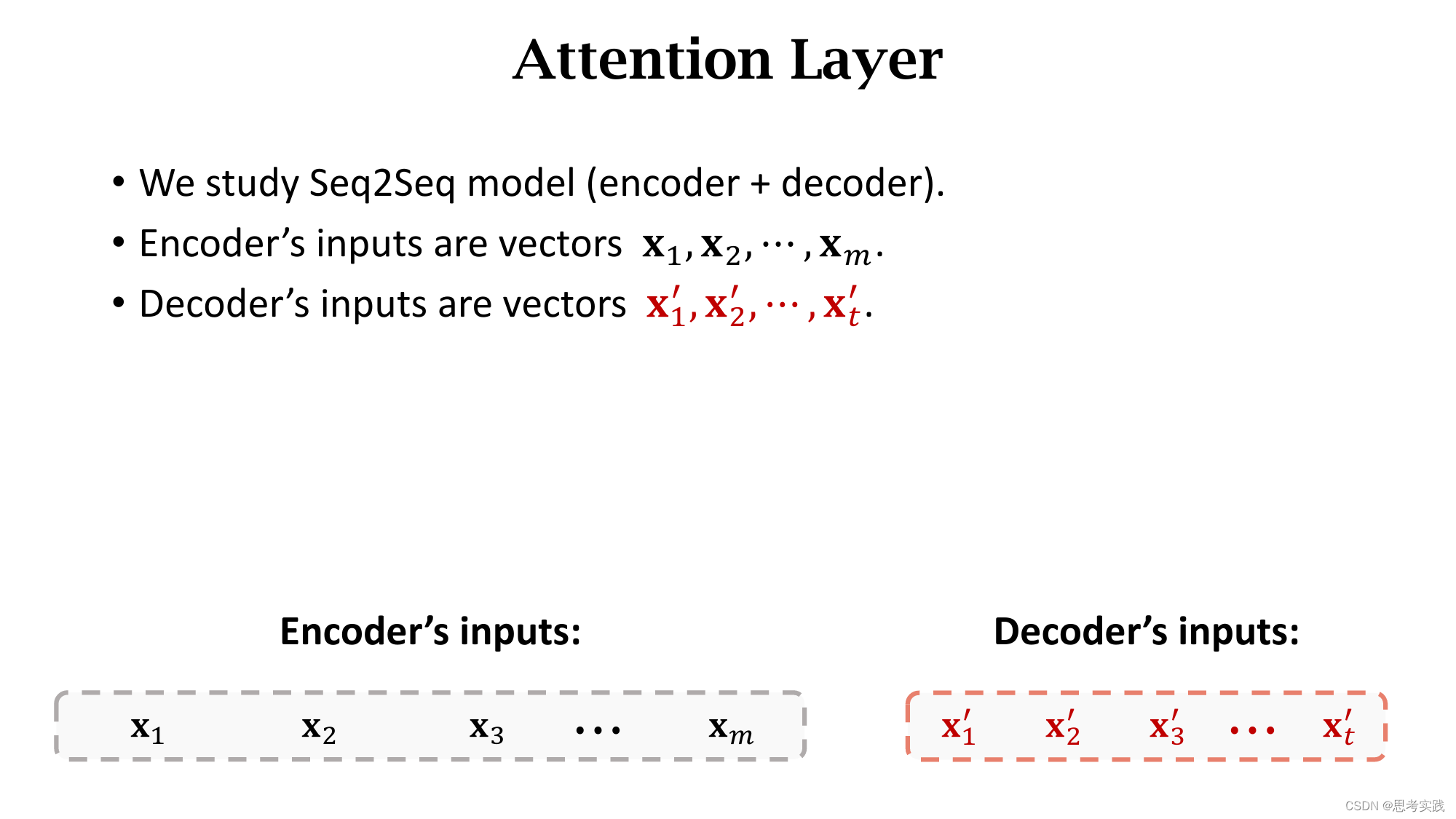
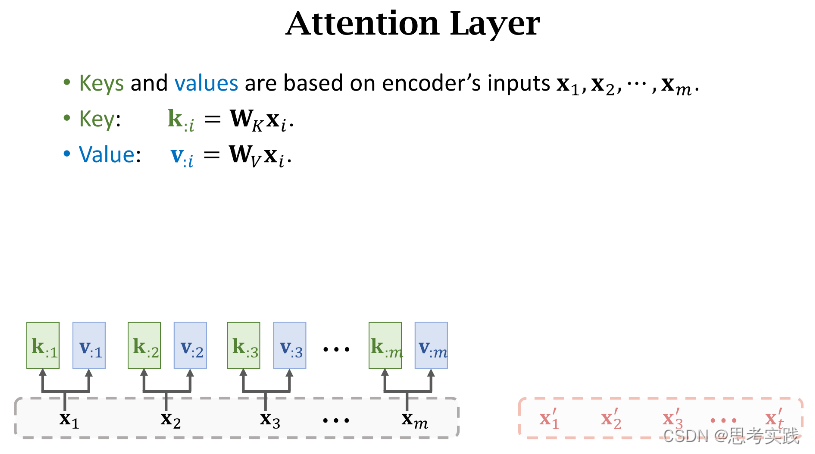
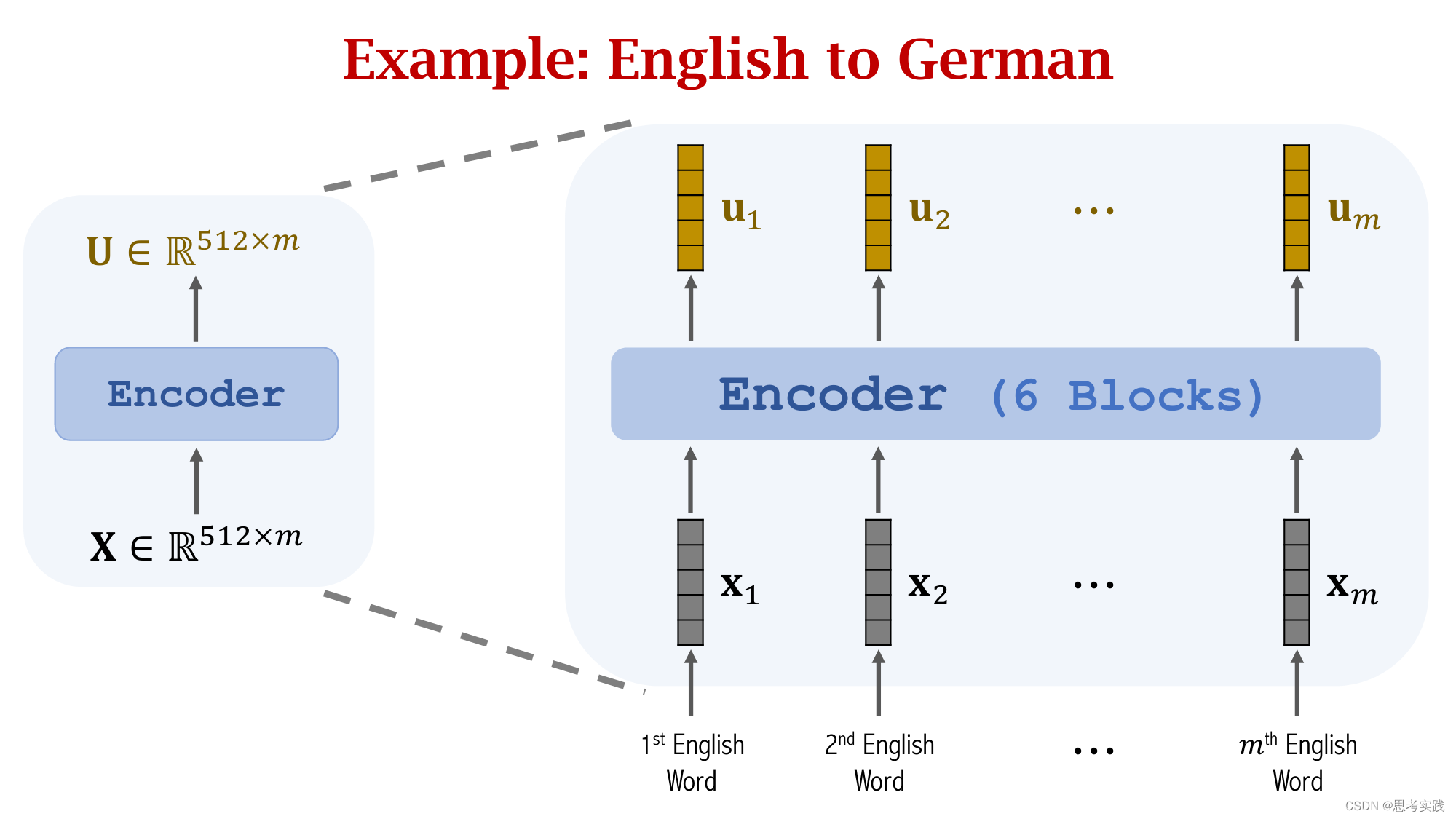
首先,Seq2Seq这个结构由Encoder和Decoder构成,Encoder有m个输入向量(x1,x2,...,xm).
Encoder会把输入的信息压缩到状态向量h中,最后这个状态hm是对所有输入的概括,decoder是一个文本生成器,(这里的文本理解有很多,可以数字,可以是任意一个国家的语言,可以是代码)
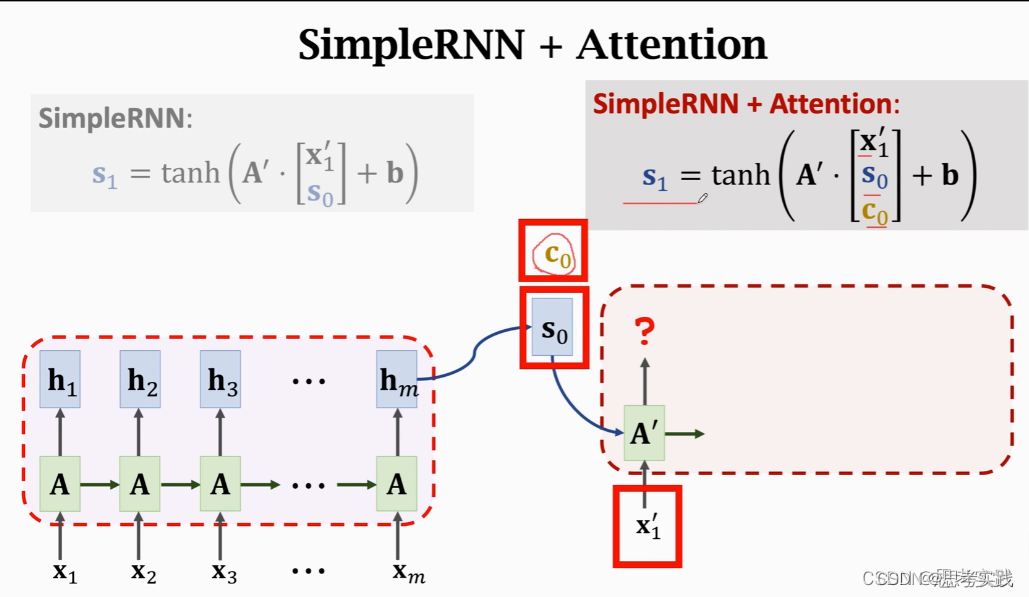
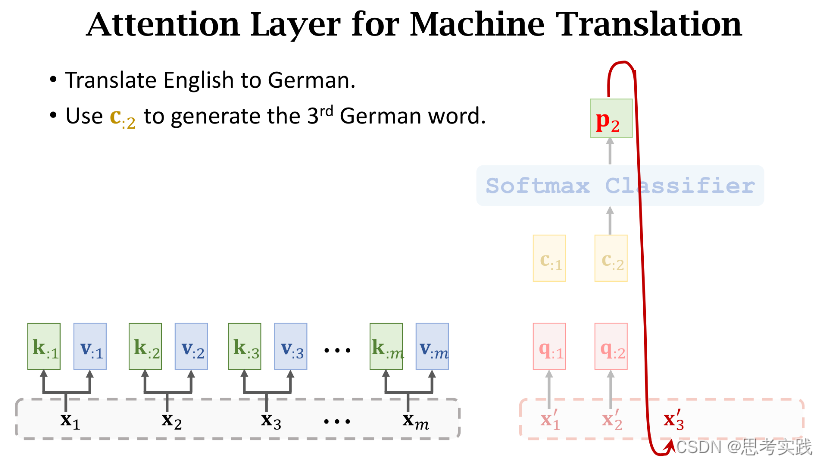
依次生成状态(s1,s2,...,sj),然后根据状态s生成单词(这里是映射),把新生成的单词作为下一个输入x'(读作x-prime),如果要用attention的话,害的计算context vector c,每计算一个s就算出一个context vector c,具体是怎样计算的呢?
补充:映射可以是双向的,理解很简单,就是词映射到向量,或者向量映射到词。
具体实现可以通过分词再word-embedding到向量,反之亦然。
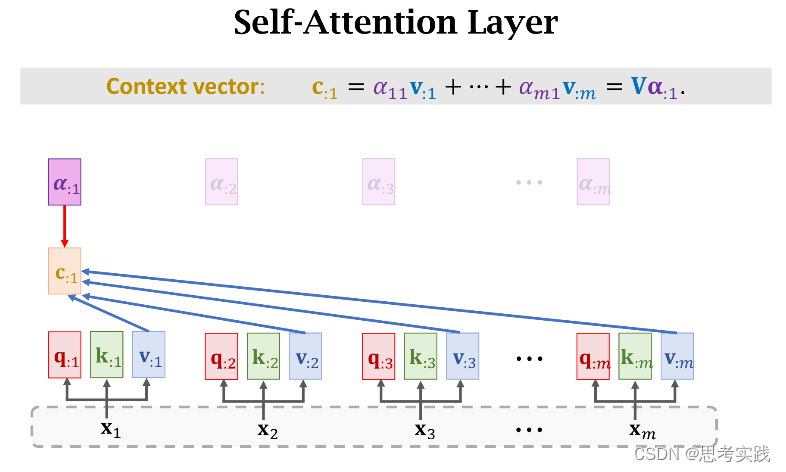
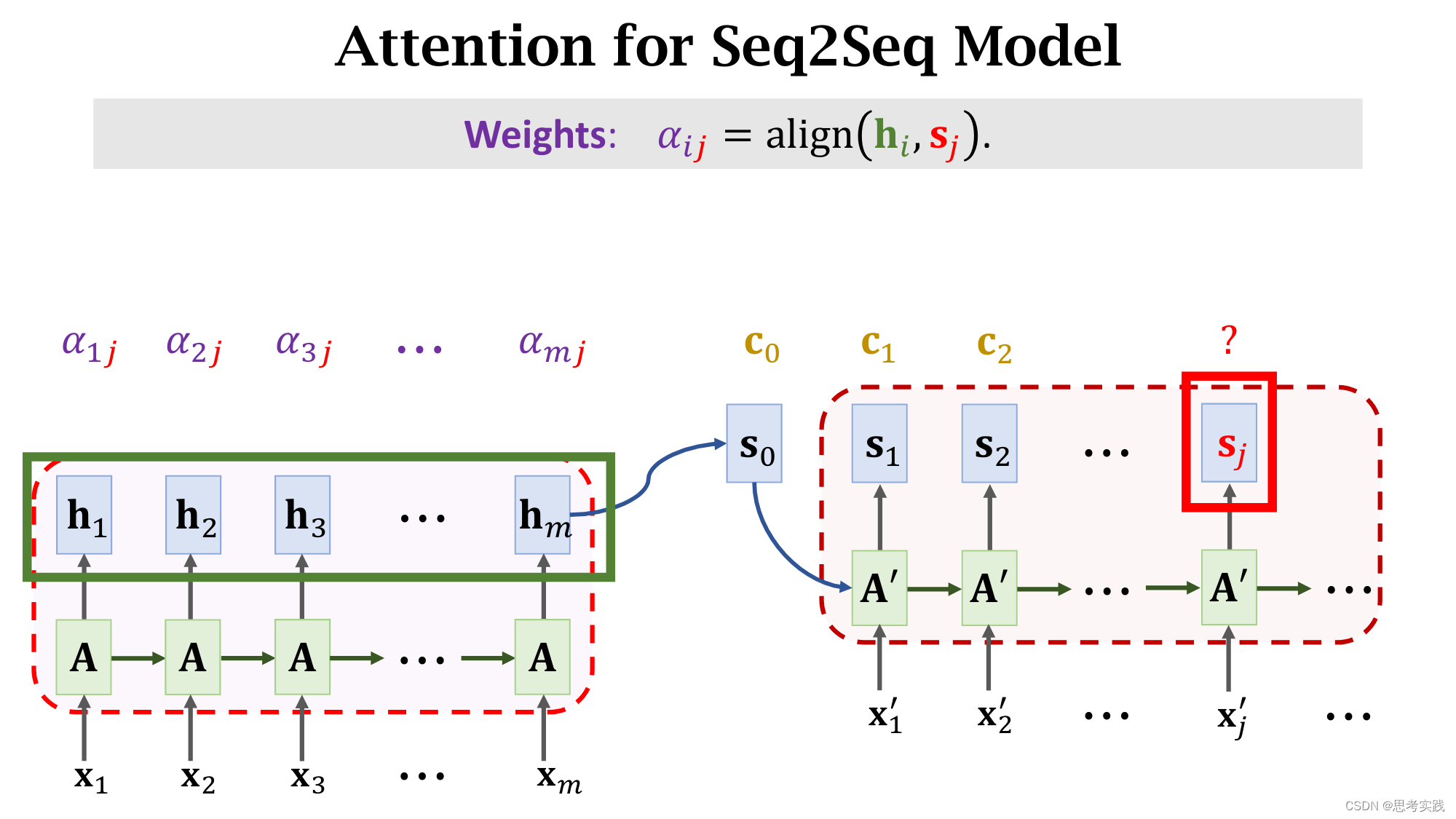 计算Context vector C步骤
计算Context vector C步骤
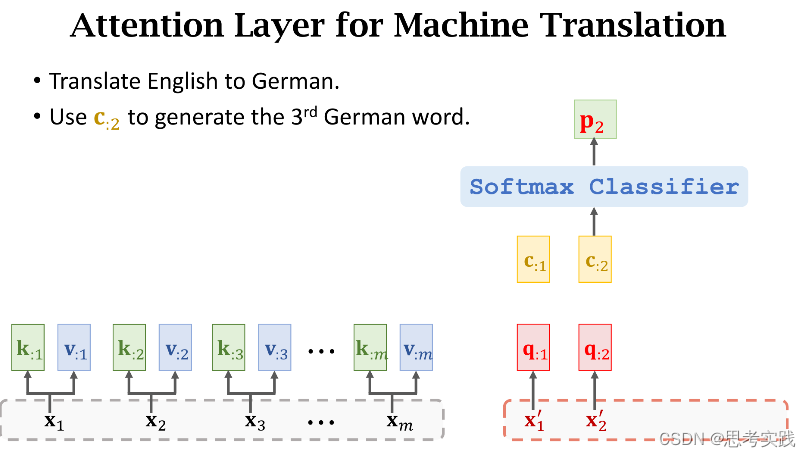
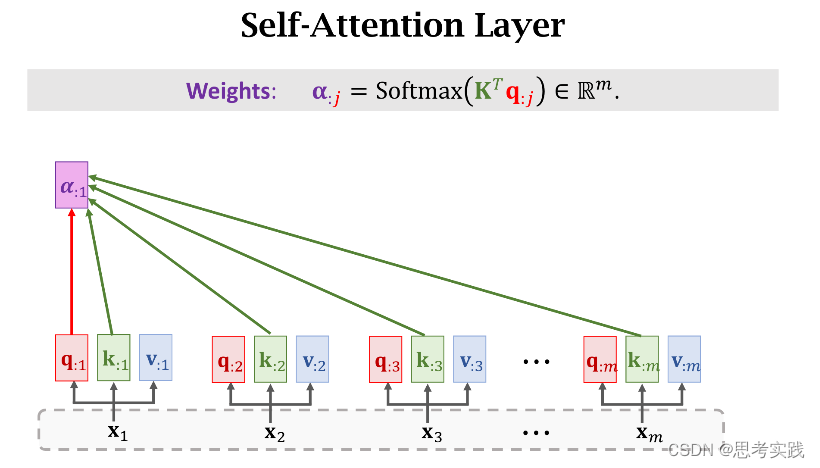
首先要把decoder当前状态sj与encoder所有状态h1到hm做对比,用align函数计算他们的相关性,把算出来的α(i,j)作为权重,我们来看一下权重α(i,j)是怎么计算的。

这里Wk与WQ是align函数的参数,这俩参数需要从数据里面训练学习。

我们要把sj这一个向量与encoder所有m个状态向量h作对比 。
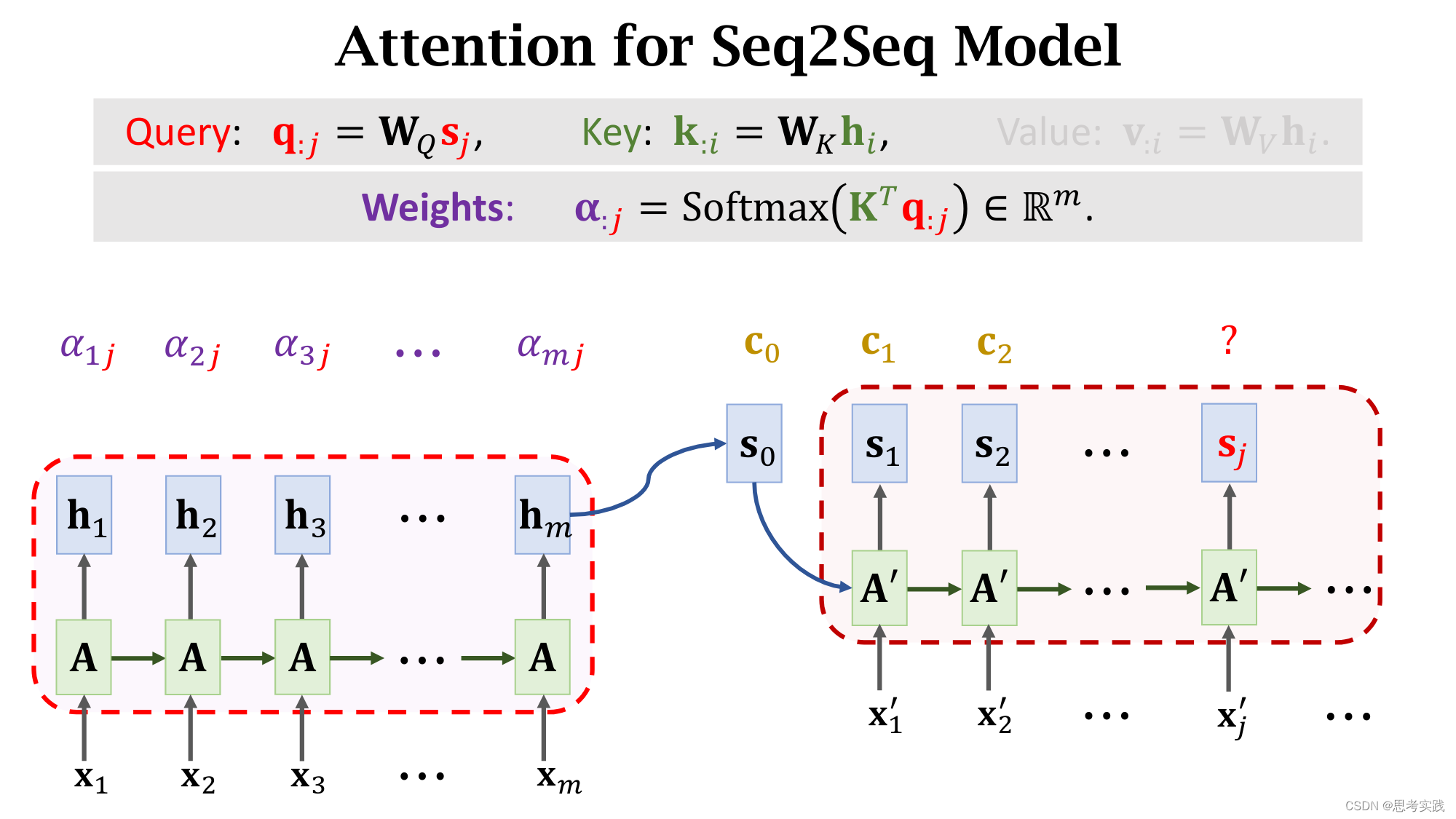
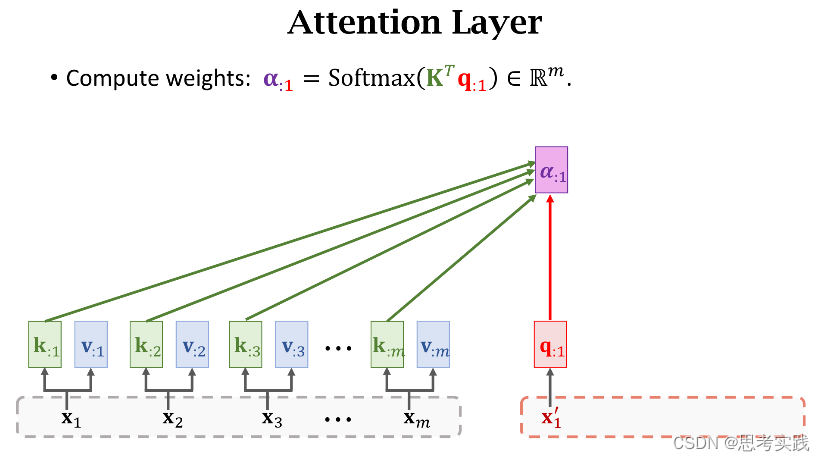
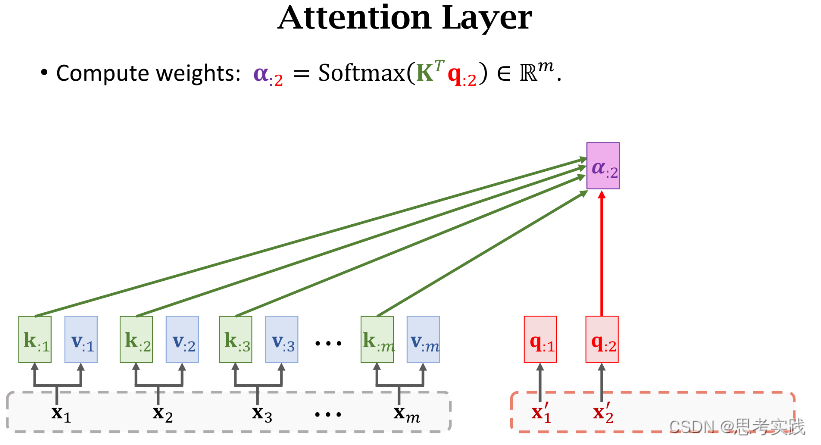
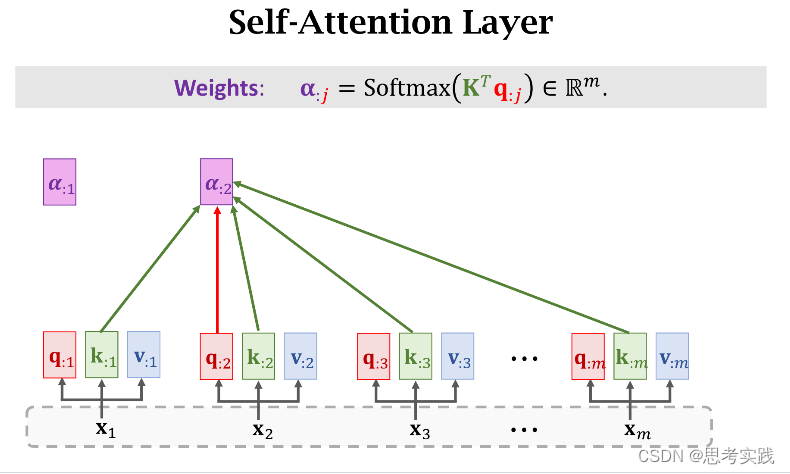
有m个hi向量所以有m个k:i向量,用这些k:i向量组成大K矩阵,每个k:i向量都是大K矩阵的列,计算矩阵大K的转置与向量q:j的乘积,结果是m维的向量,然后用Softmax函数输出一个m维的向量α:j,把α:j的m个元素记作[α1j,α2j,...,αmj]T(这些元素全都介于0和1之间,并且他们相加等于1),

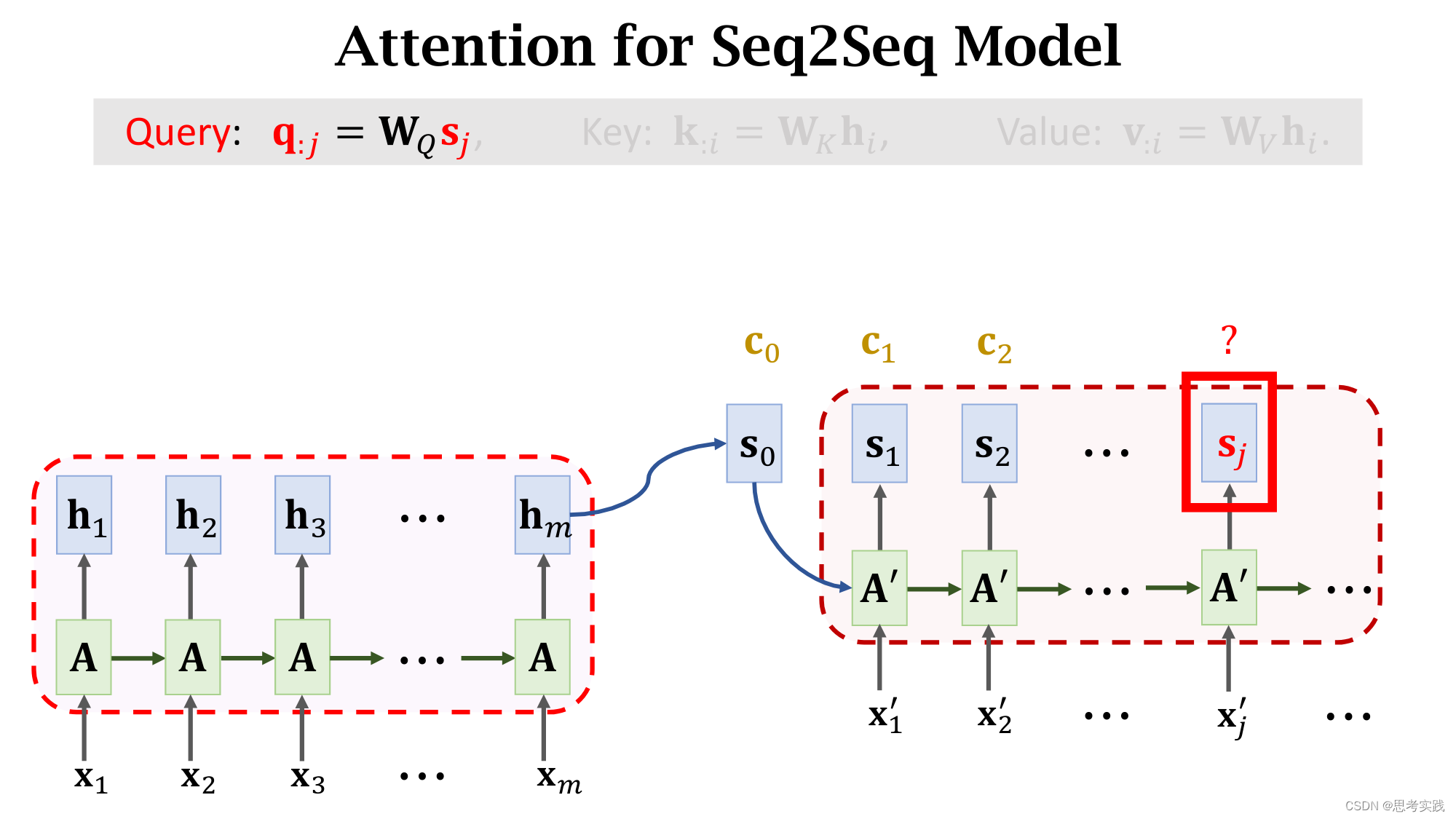
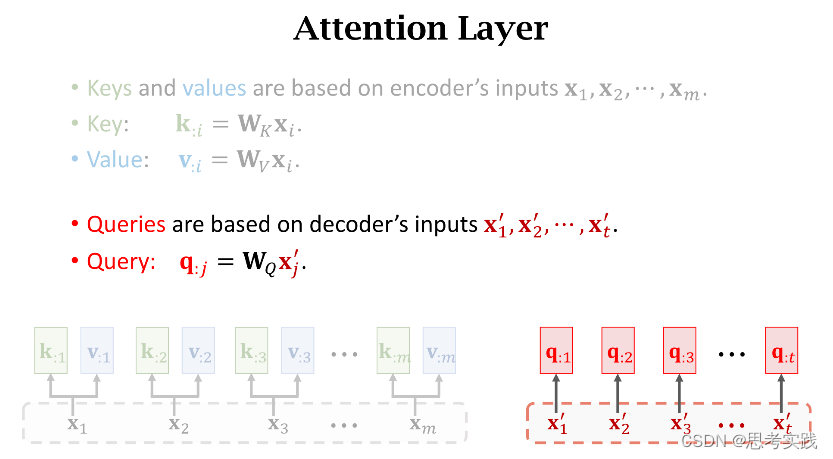
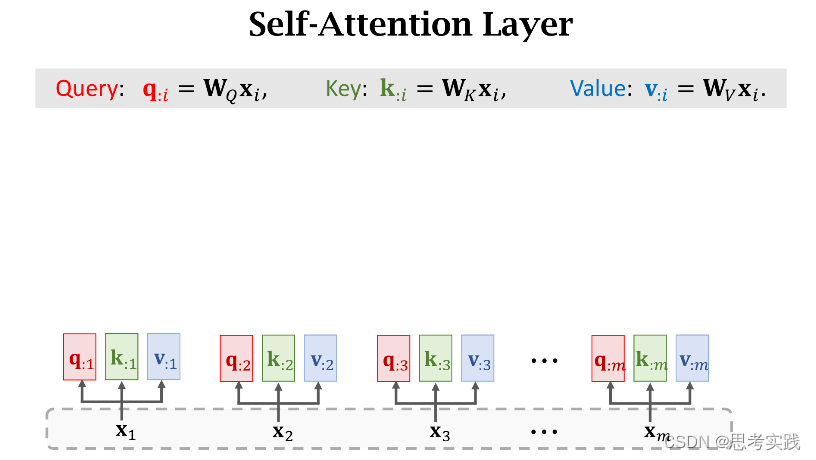
把decoder的状态sj与encoder的状态hi分别作线性变换(得到、增添可学习的参数),得到向量q:j与k:i,分别被称为Query与Key,Query的意思是用来匹配Key值,而Key的意思是被Query匹配。
我们拿一个Query向量q:j去对比所有m个Key向量,算出m个权重α:j,这m个α就说明这个Query向量q:j去与每个Key的匹配程度(相似程度),匹配程度越高说明,对应权重α越大。
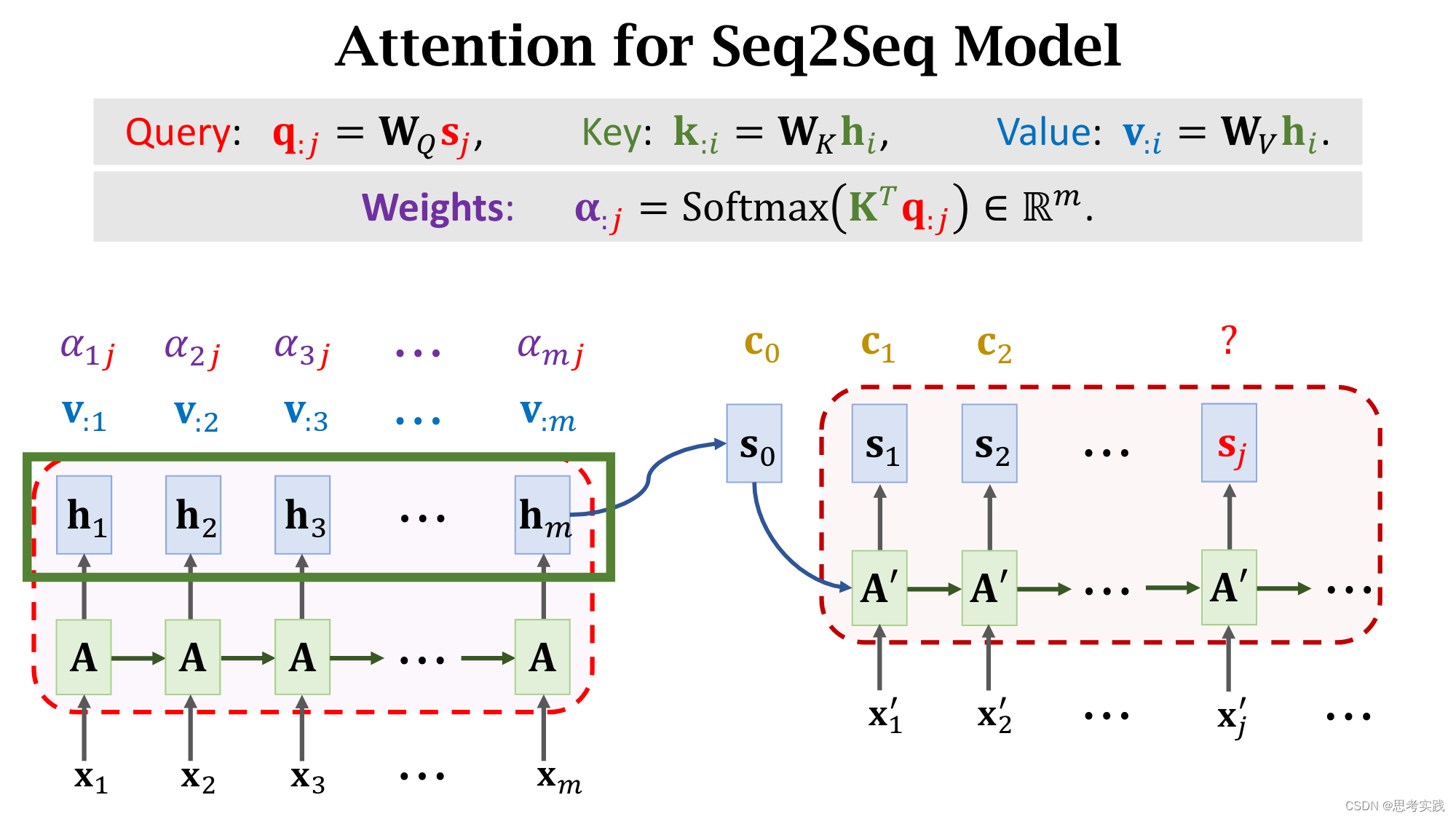
除此之外还要计算Value向量v:i,把hi乘在矩阵向量Wv上得到向量v:i,矩阵Wv也是一个可学习的参数,attention里面一共有三个参数(WQ,WK,WV)矩阵,他们都用从训练数据中学习。
 每一个v:i向量对应一个Encoder向量hi
每一个v:i向量对应一个Encoder向量hi
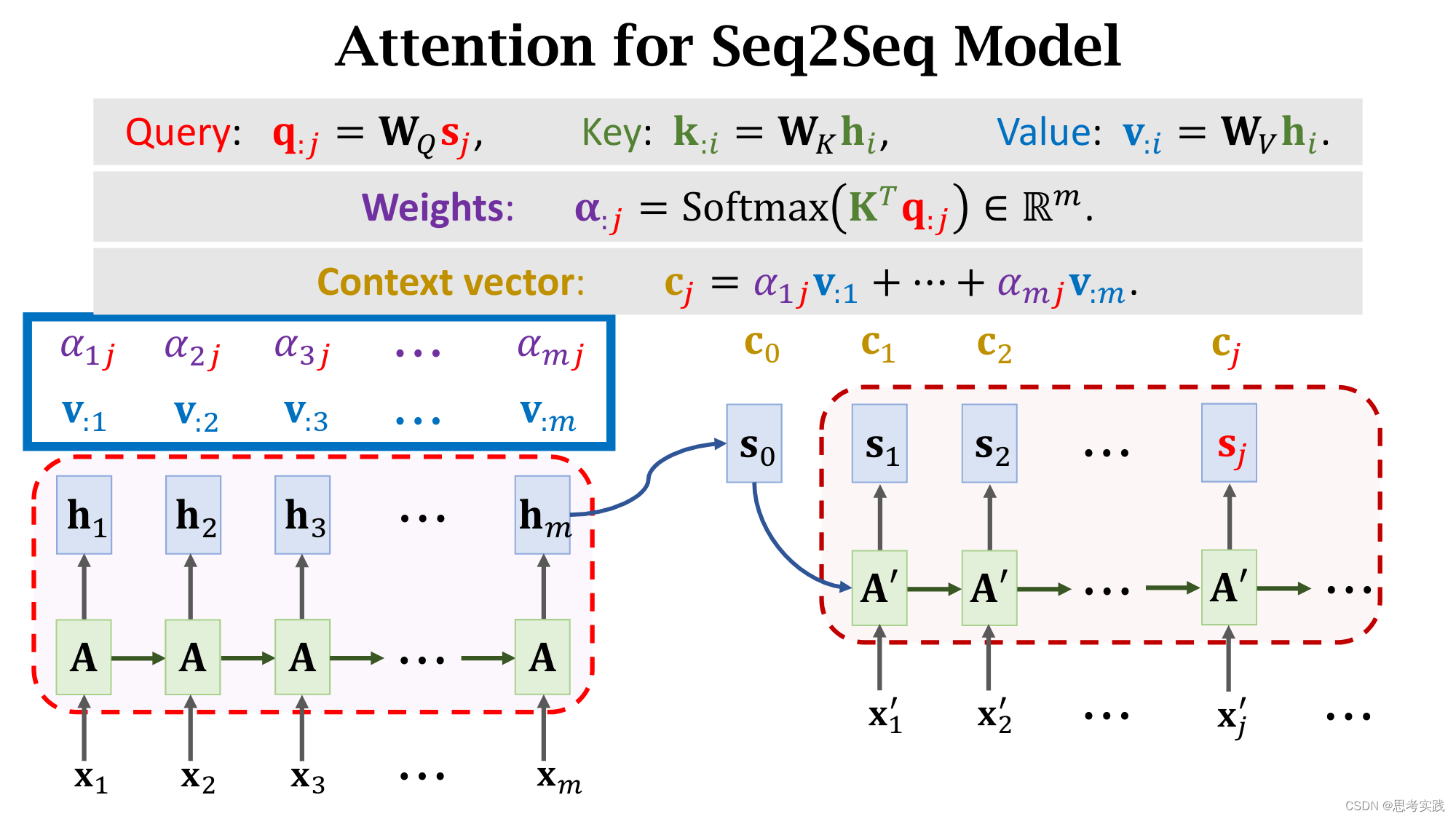
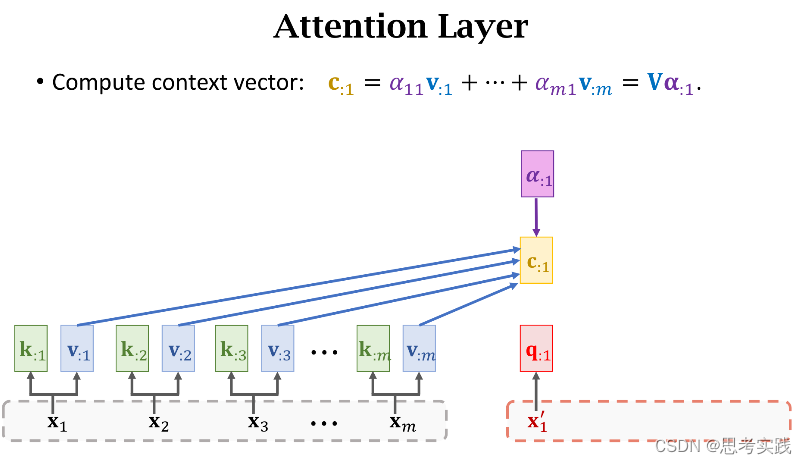
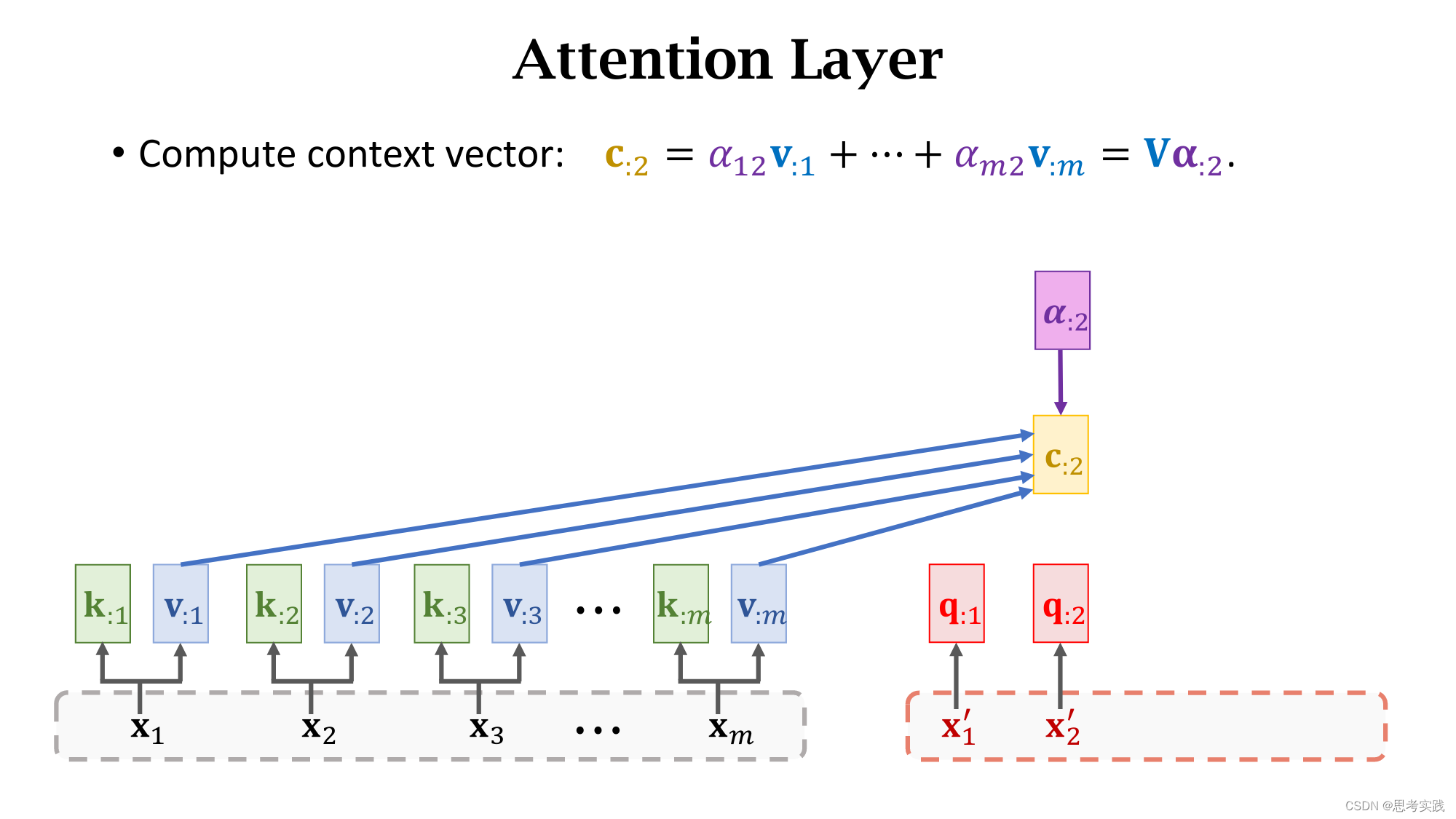
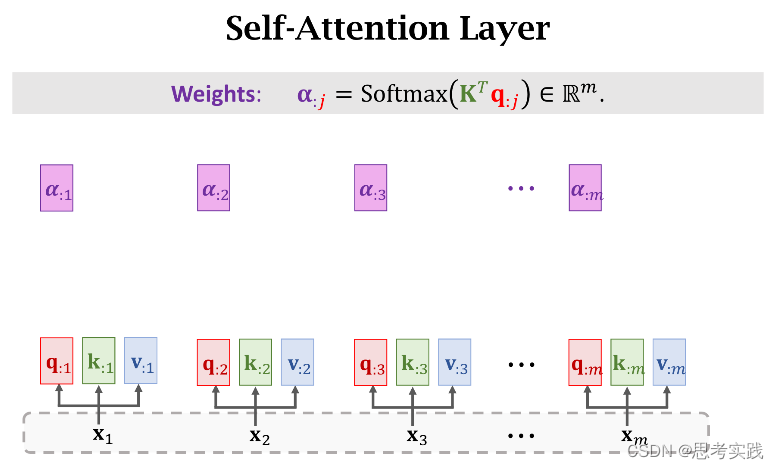
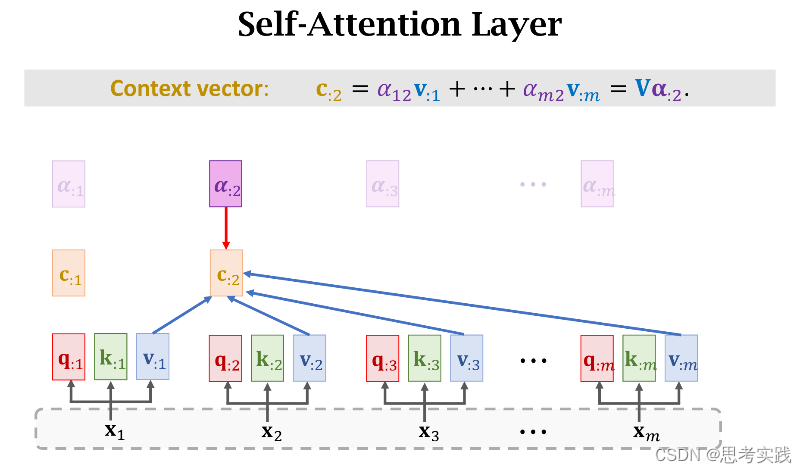
 现在我们有了m个权重值α和m个value向量v,现在用α作权重,把这m个value向量做加权平均,把结果作为新的Context Vector Cj,
现在我们有了m个权重值α和m个value向量v,现在用α作权重,把这m个value向量做加权平均,把结果作为新的Context Vector Cj,![]()
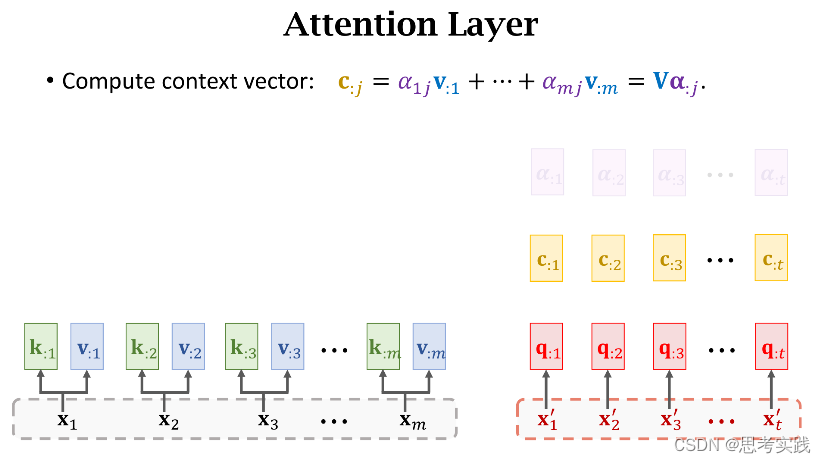
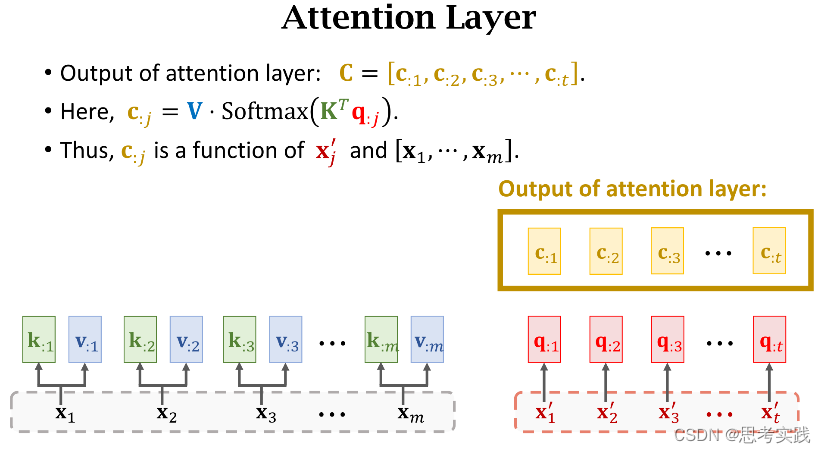
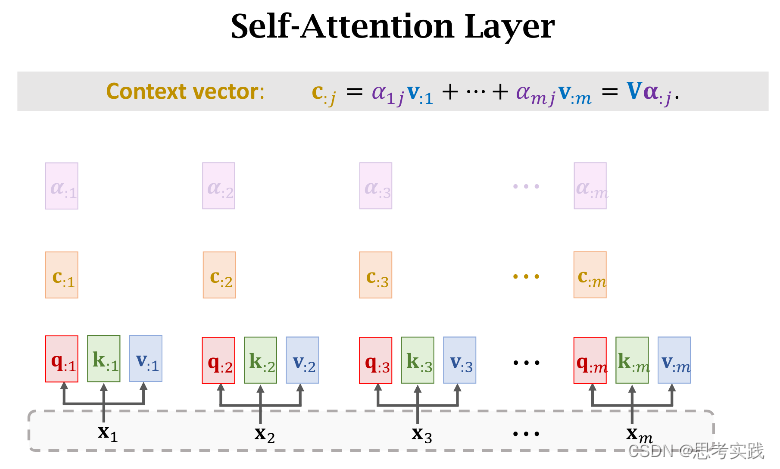
这种计算α权重与Context vector Cj的方法就是Transformer里面用到的
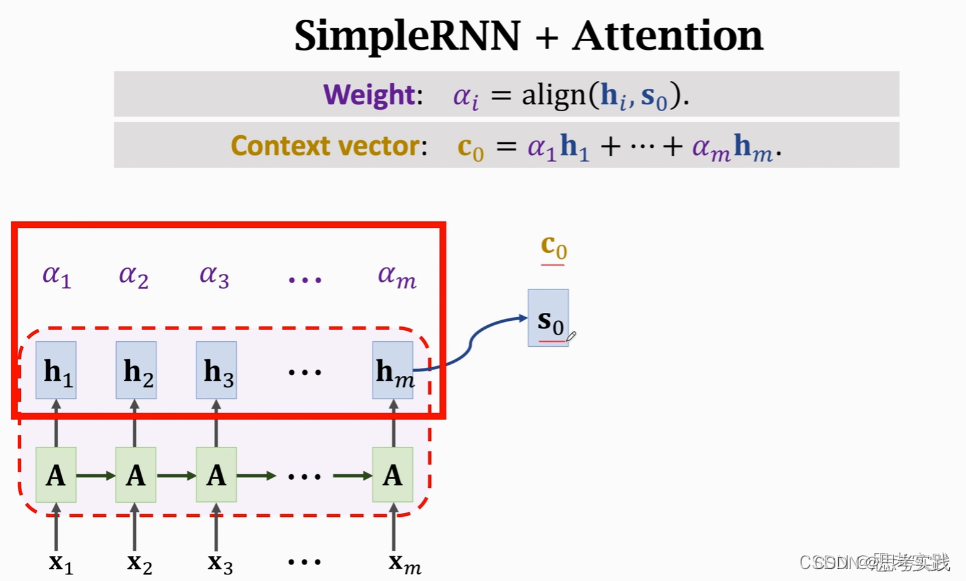
 Attention 原本是用到Rnn上面的,其计算α权重与Context vector Cj的方法,详情链接请跳往这里,如下图所示,没有用到value向量:
Attention 原本是用到Rnn上面的,其计算α权重与Context vector Cj的方法,详情链接请跳往这里,如下图所示,没有用到value向量:
思考一下如何才能剥离Rnn,只保留attention?(Transformer是纯attention)
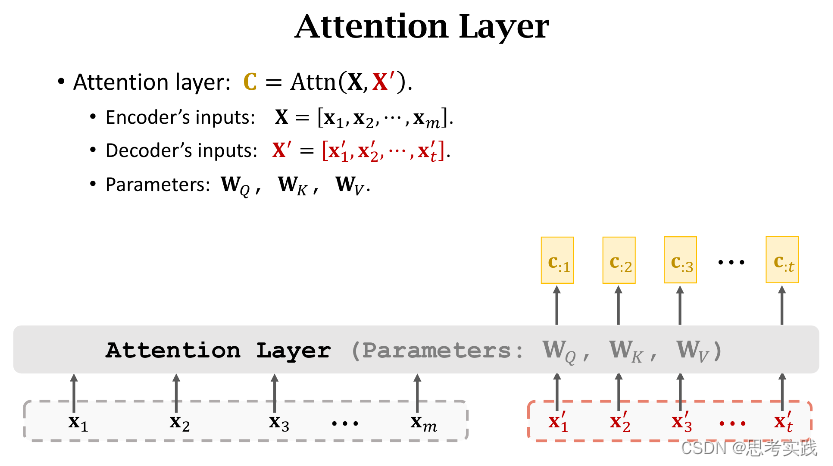
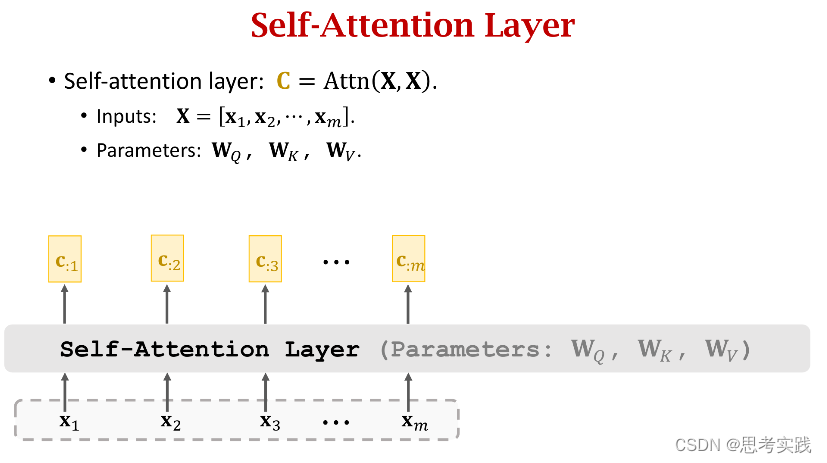
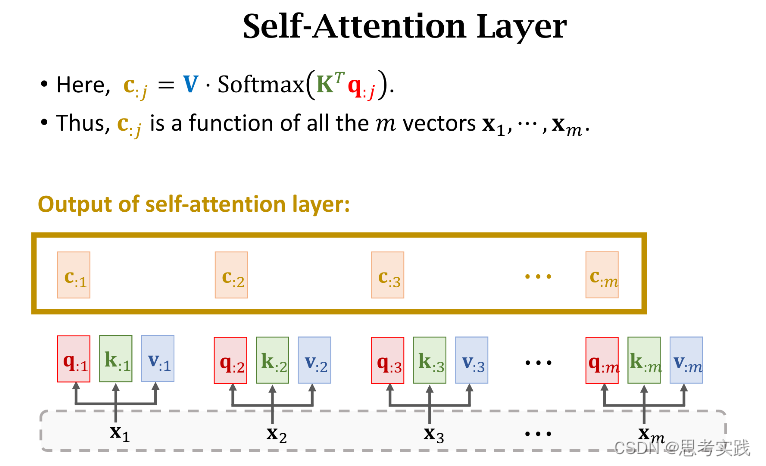
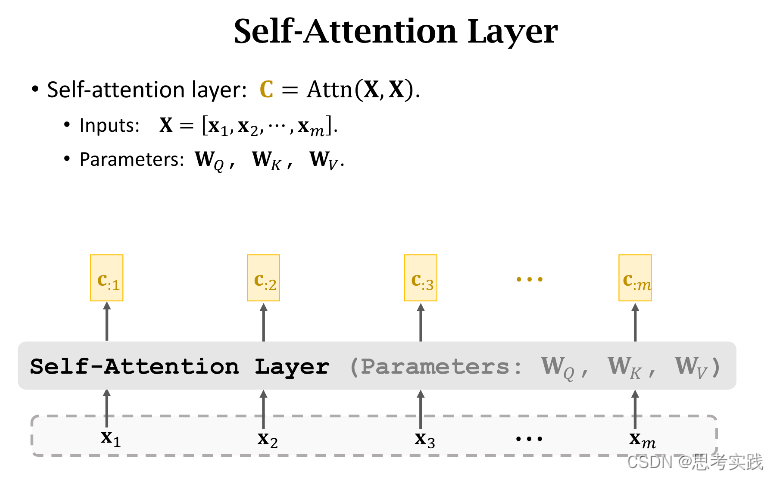
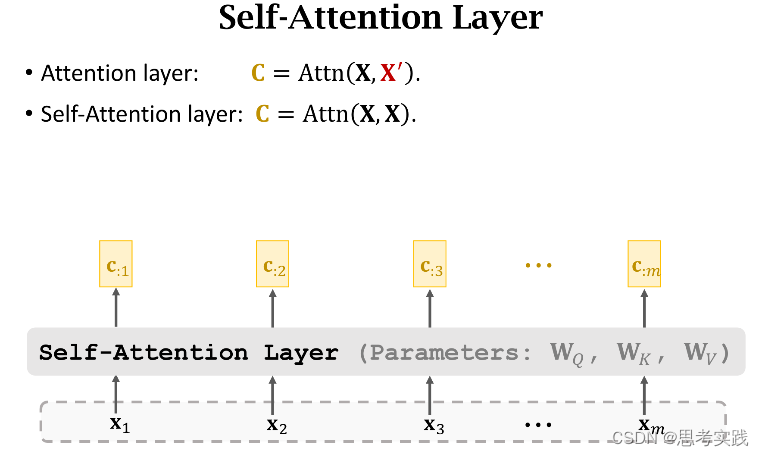
 下面的内容是去掉Rnn只保留Attention,这样可以得到一个attention layer和self-attention layer(这个说法是基于之前讲到的attention与self-attention在rnn里面的运用),因为Transformer是基于纯注意力机制的
下面的内容是去掉Rnn只保留Attention,这样可以得到一个attention layer和self-attention layer(这个说法是基于之前讲到的attention与self-attention在rnn里面的运用),因为Transformer是基于纯注意力机制的
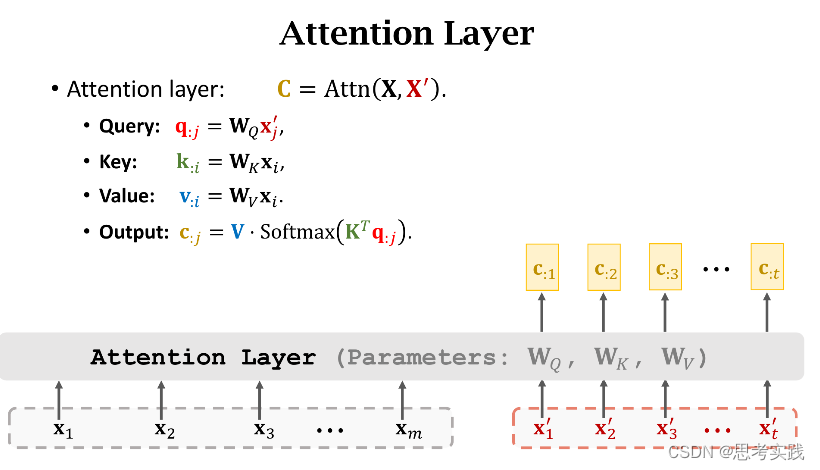
Attention without RNN
 这里的
这里的代表着所有的k向量,再与q:1进行相似计算
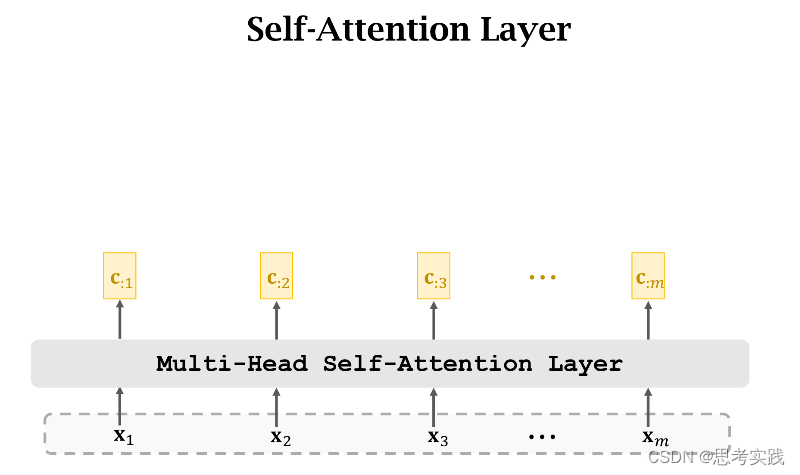
Self-Attention without RNN



Transformer:From Shallow to Deep


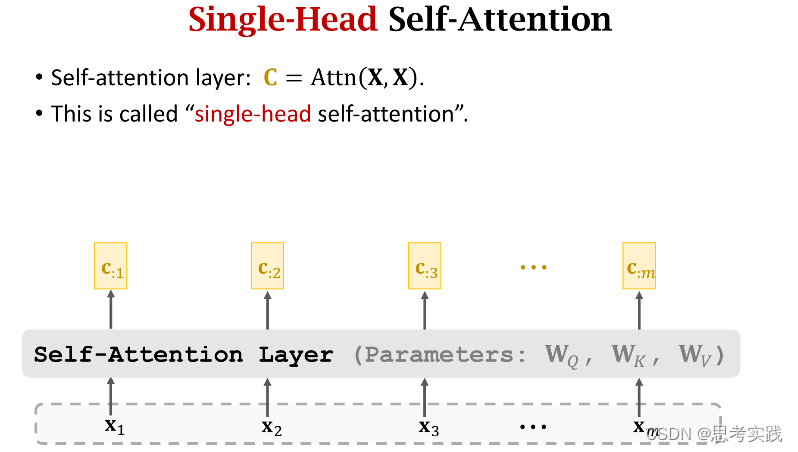
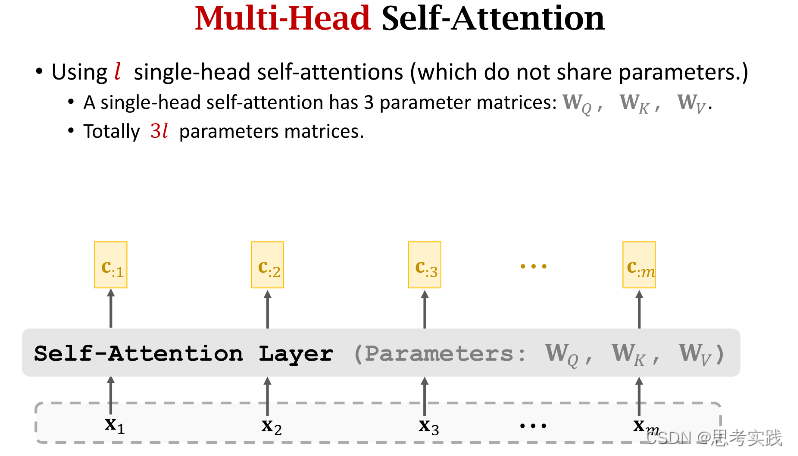
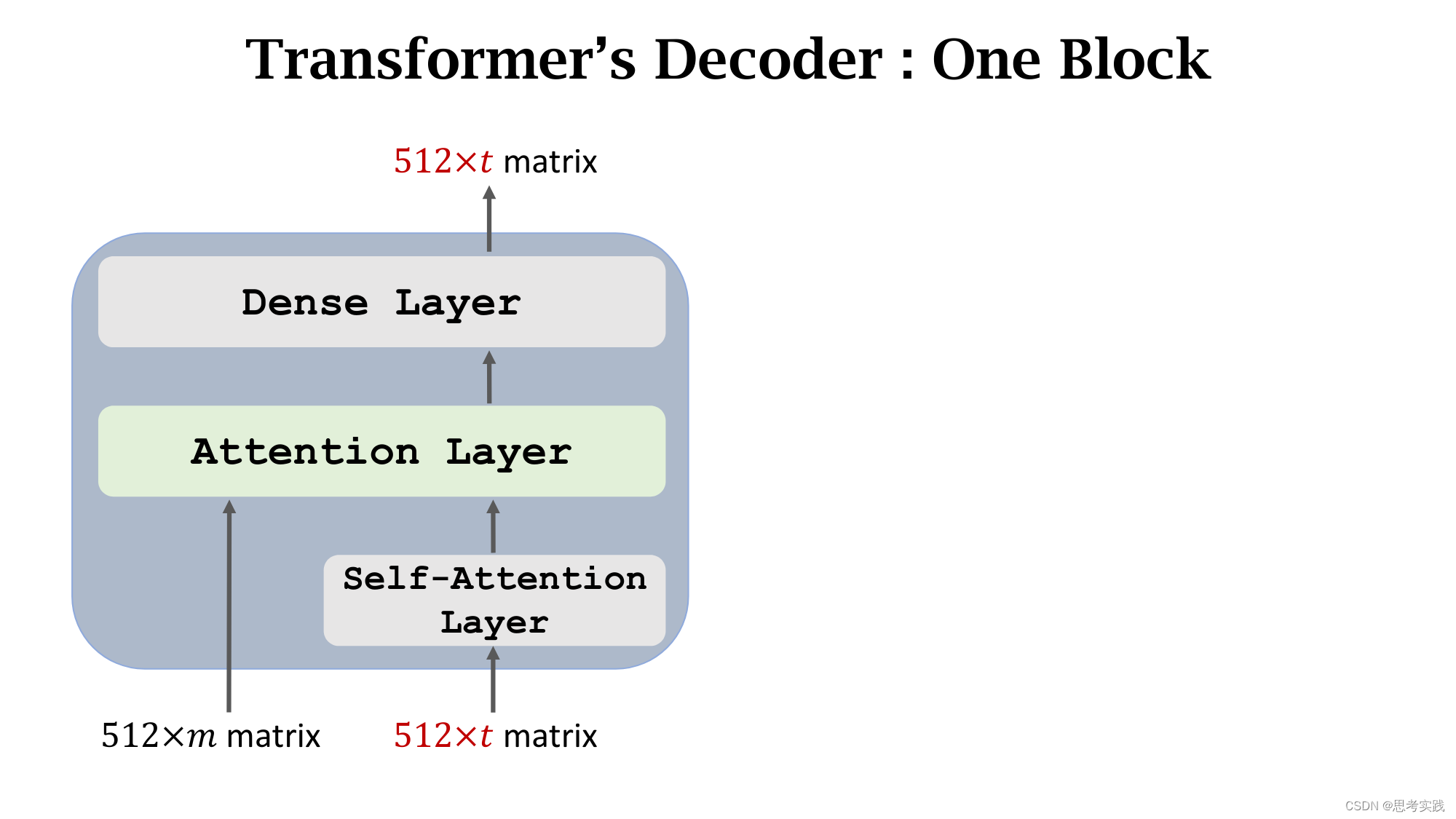
Single-Head Self-Attention
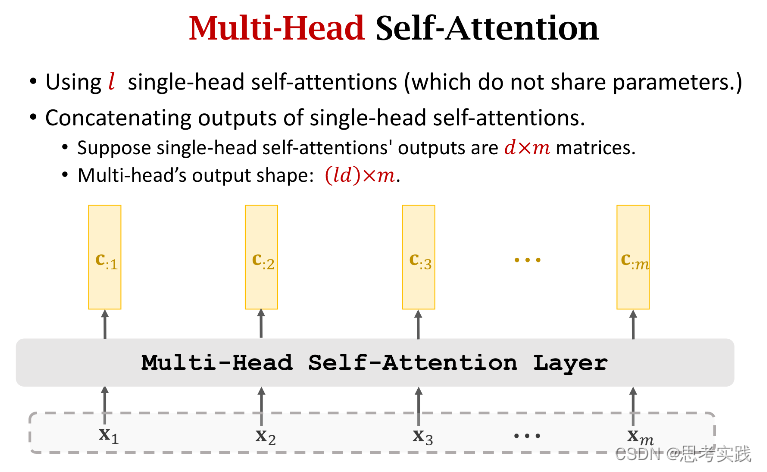
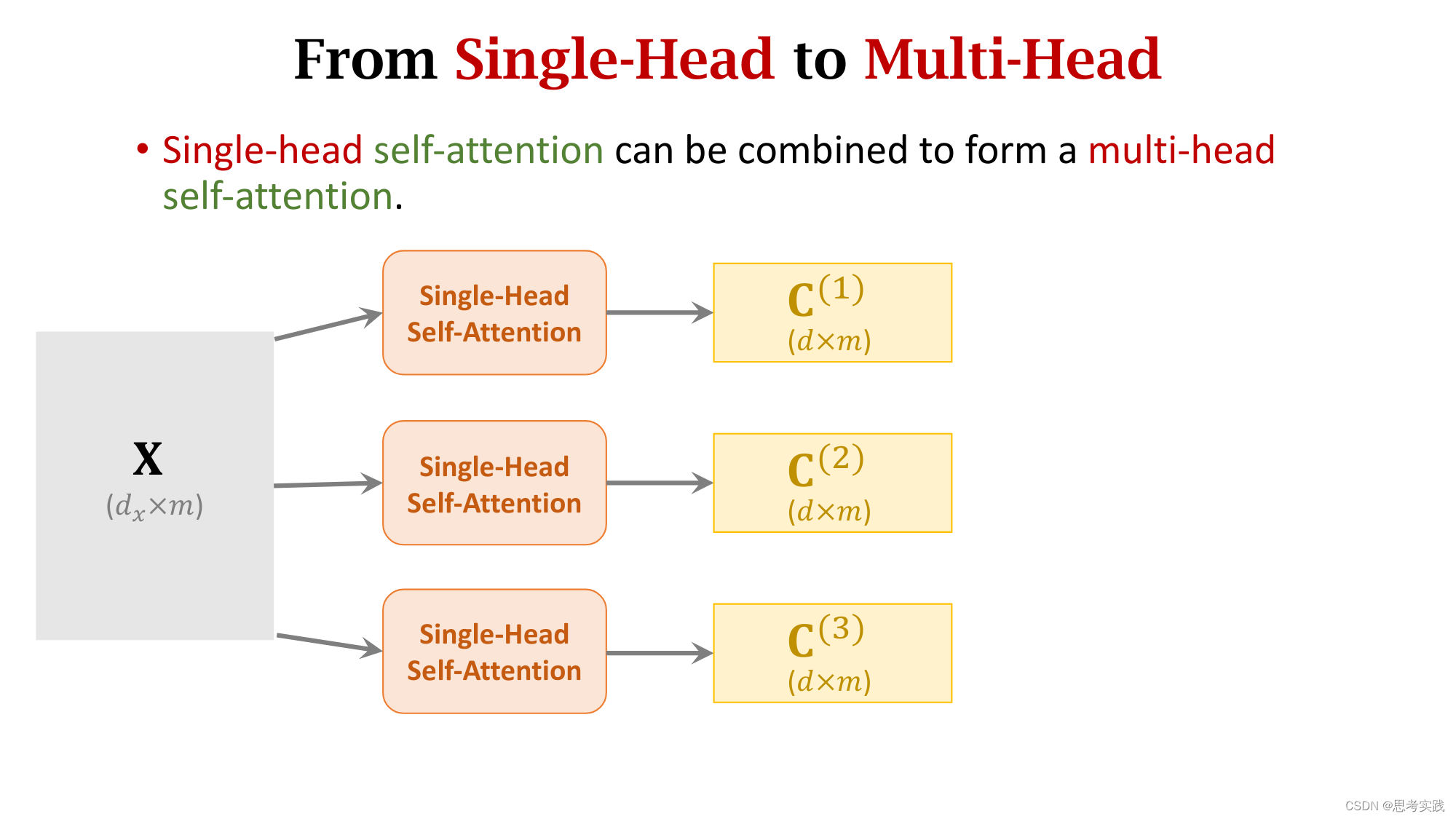
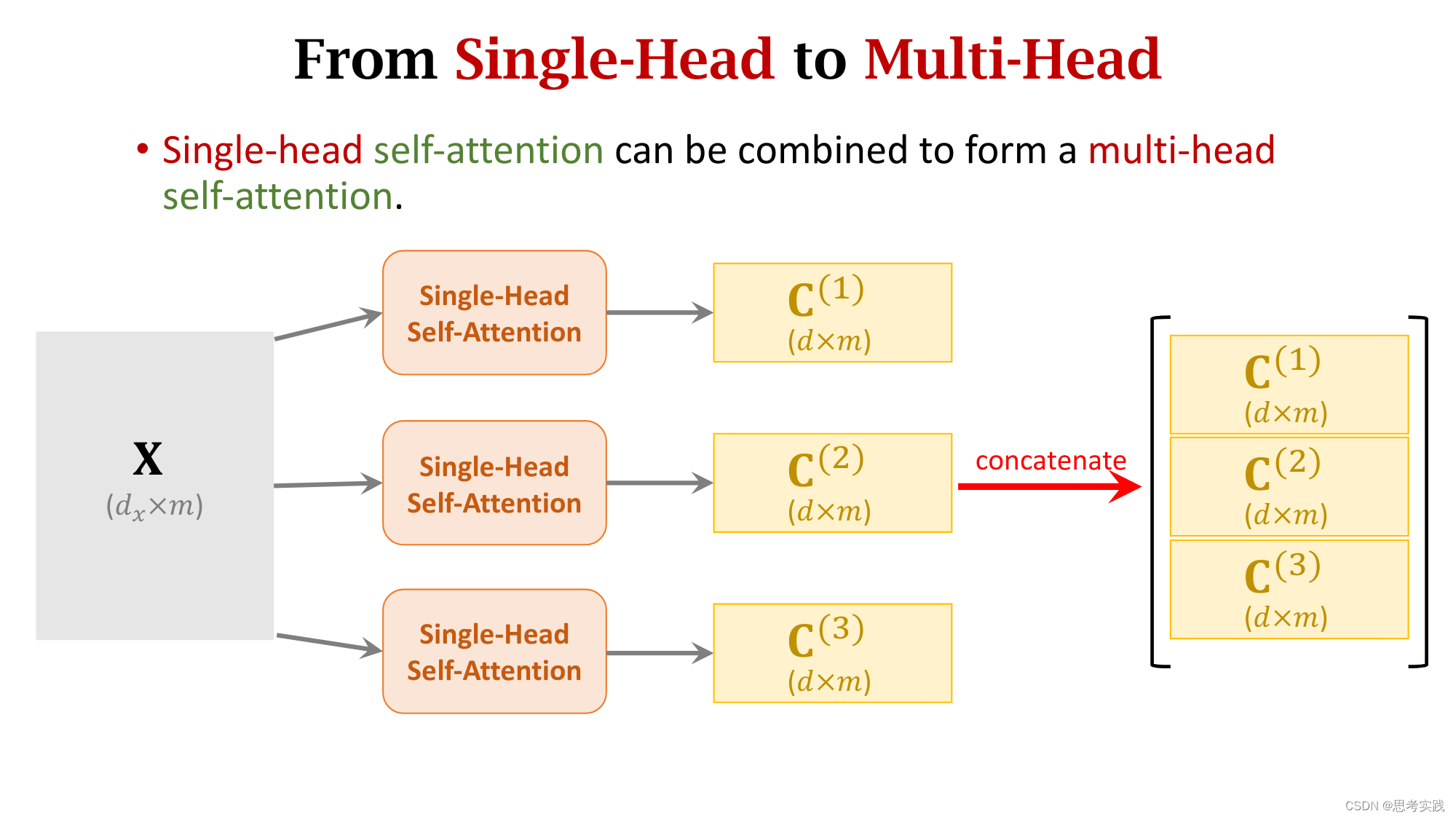
Multi-Head Self-Attention
 Multi-Head Attention
Multi-Head Attention 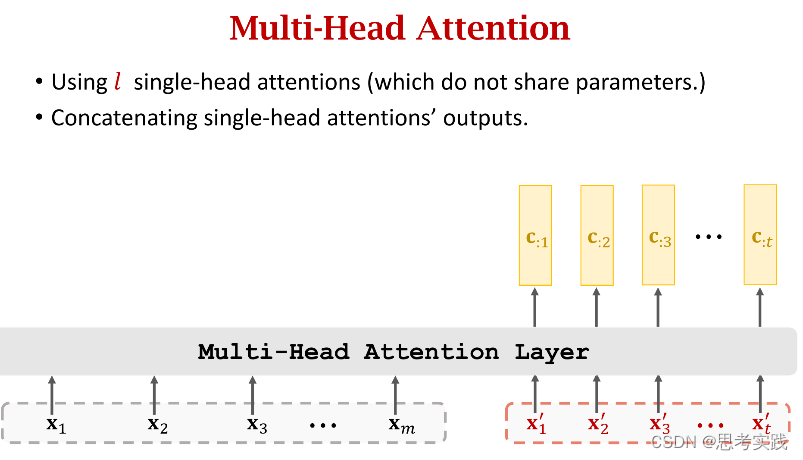
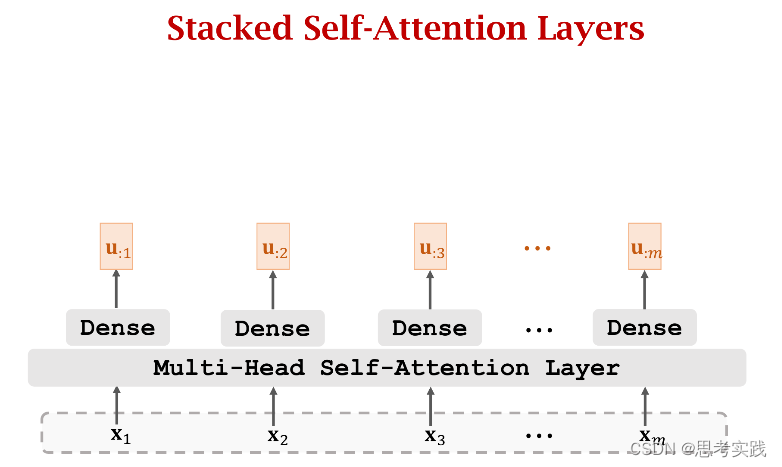
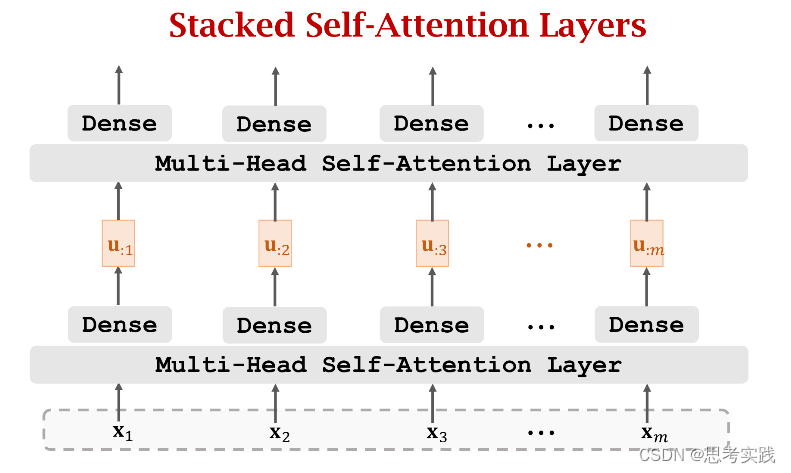
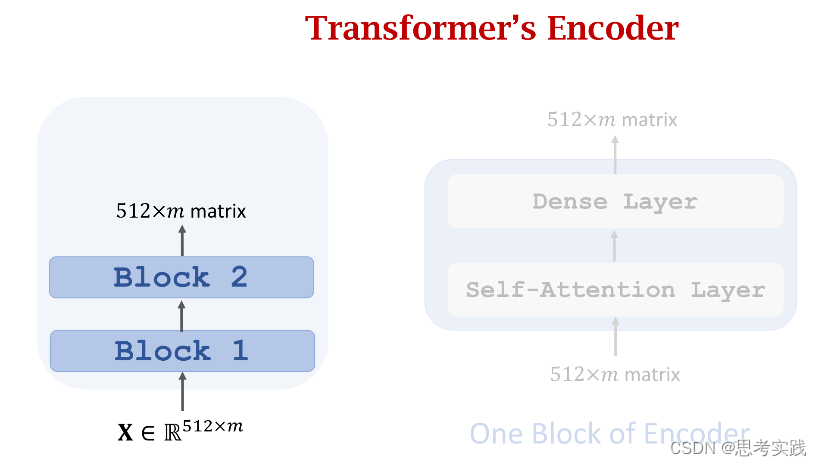
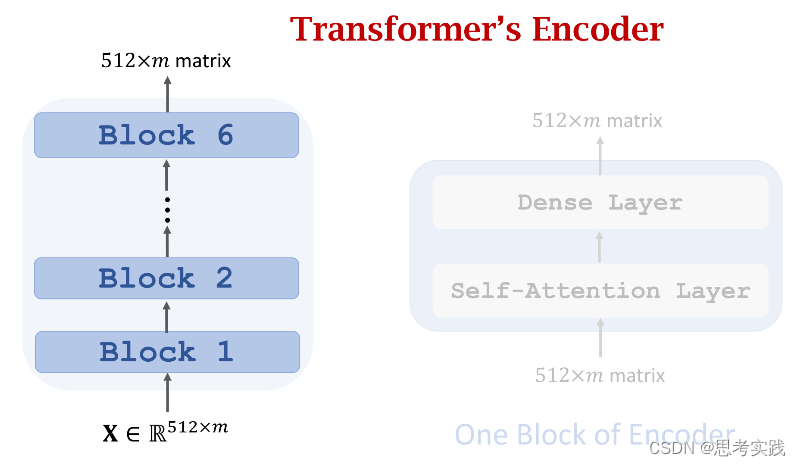
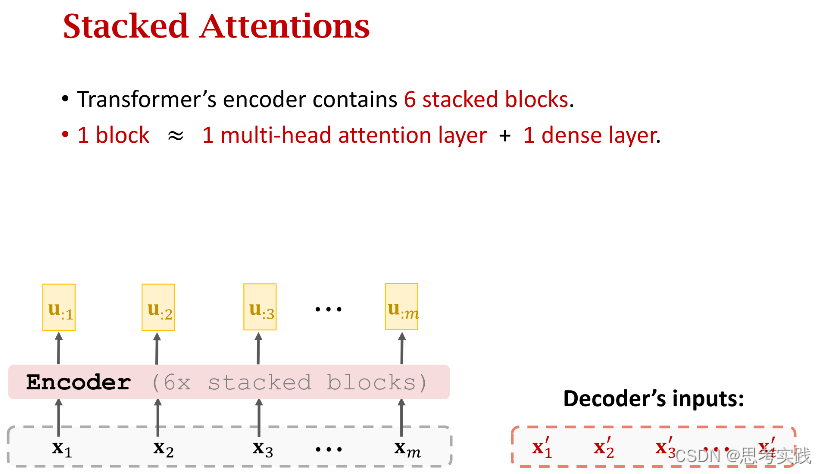
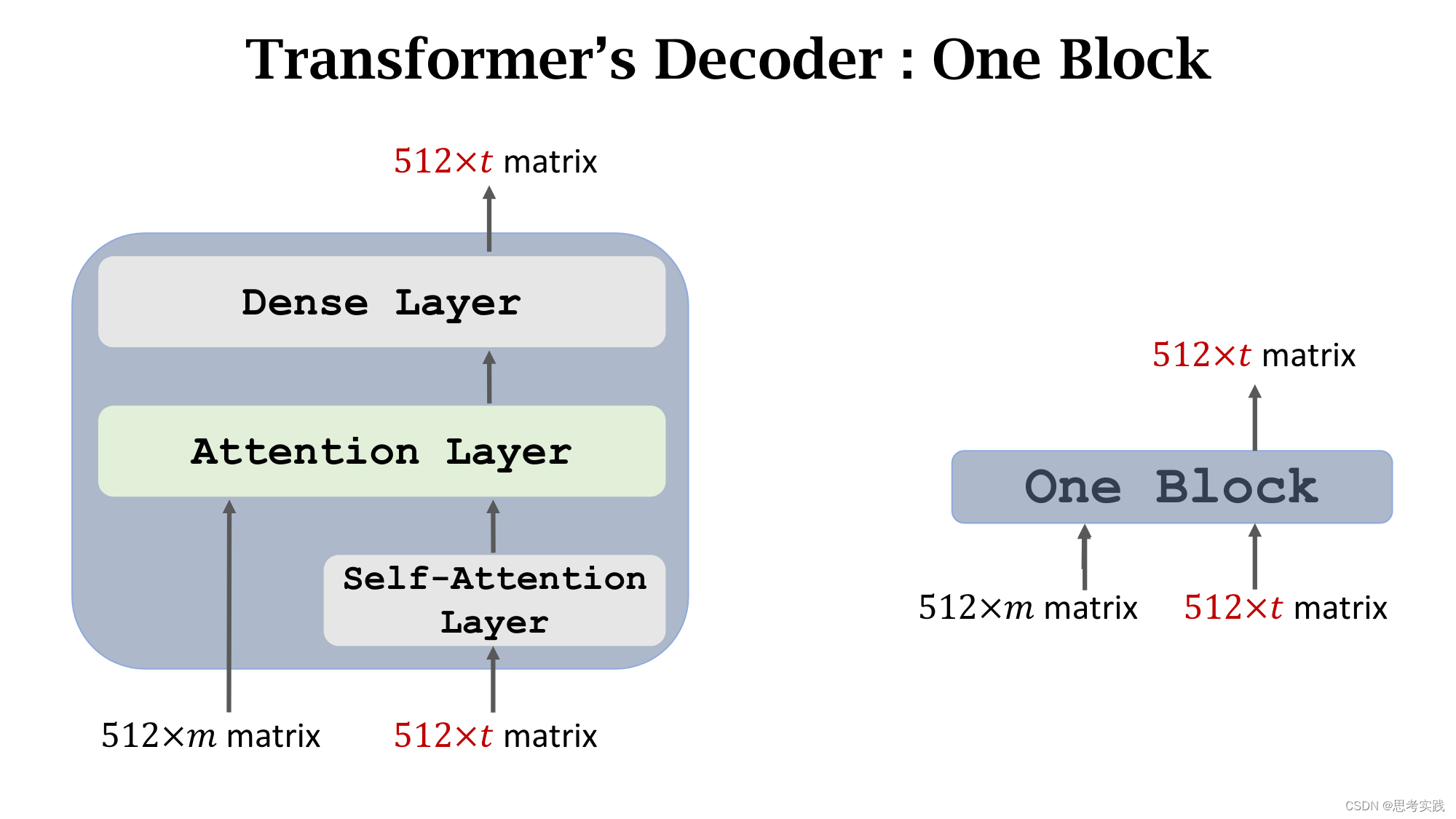
Stacked Self-Attention Layers

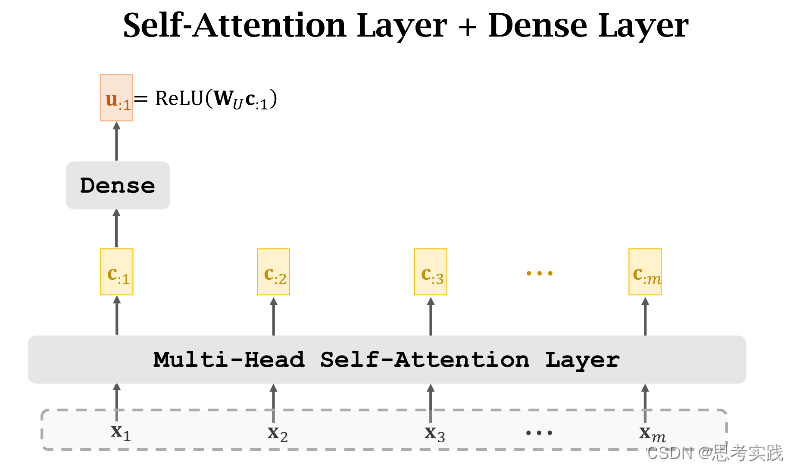
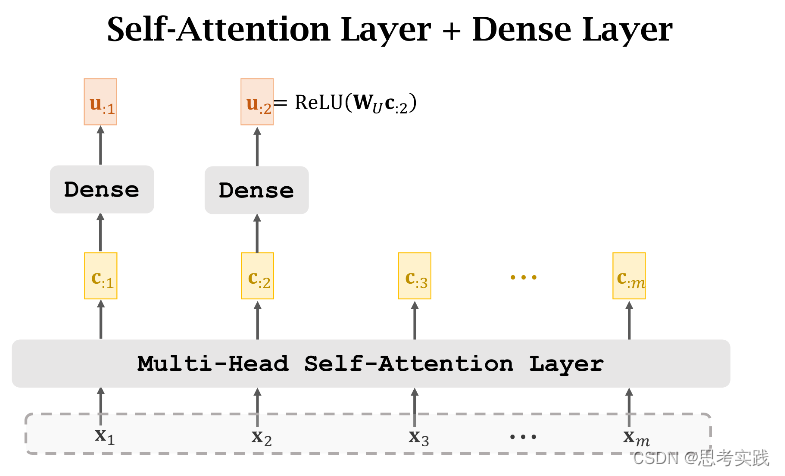
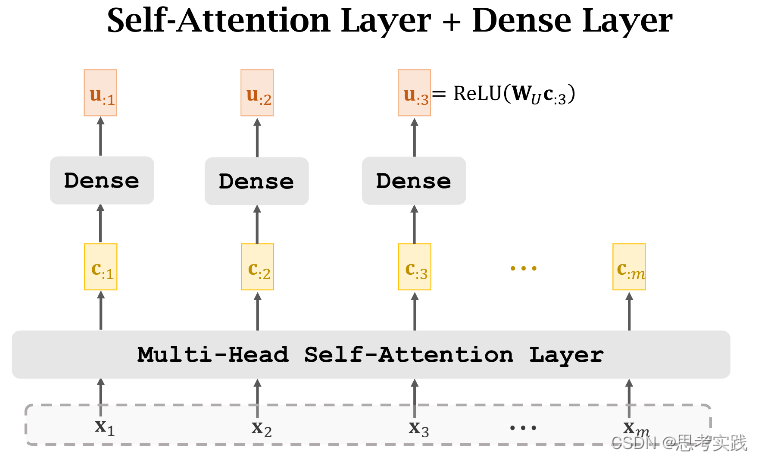
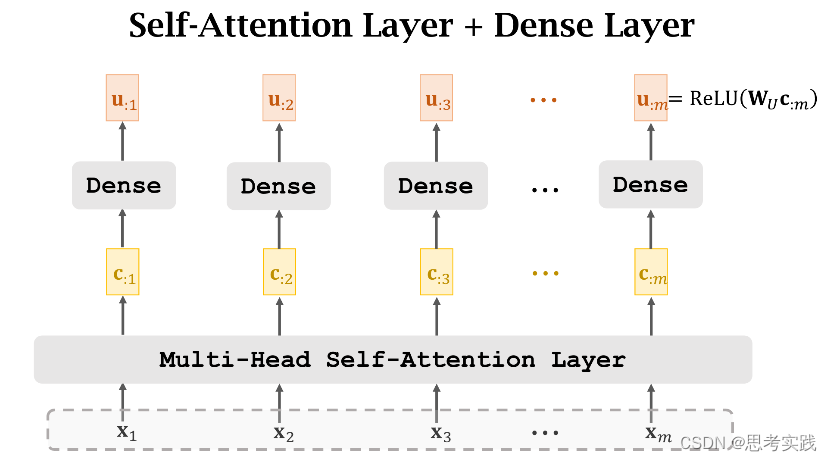
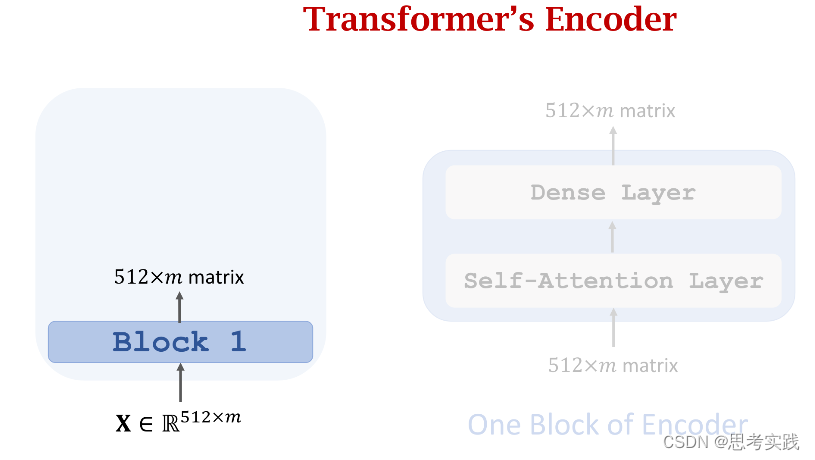
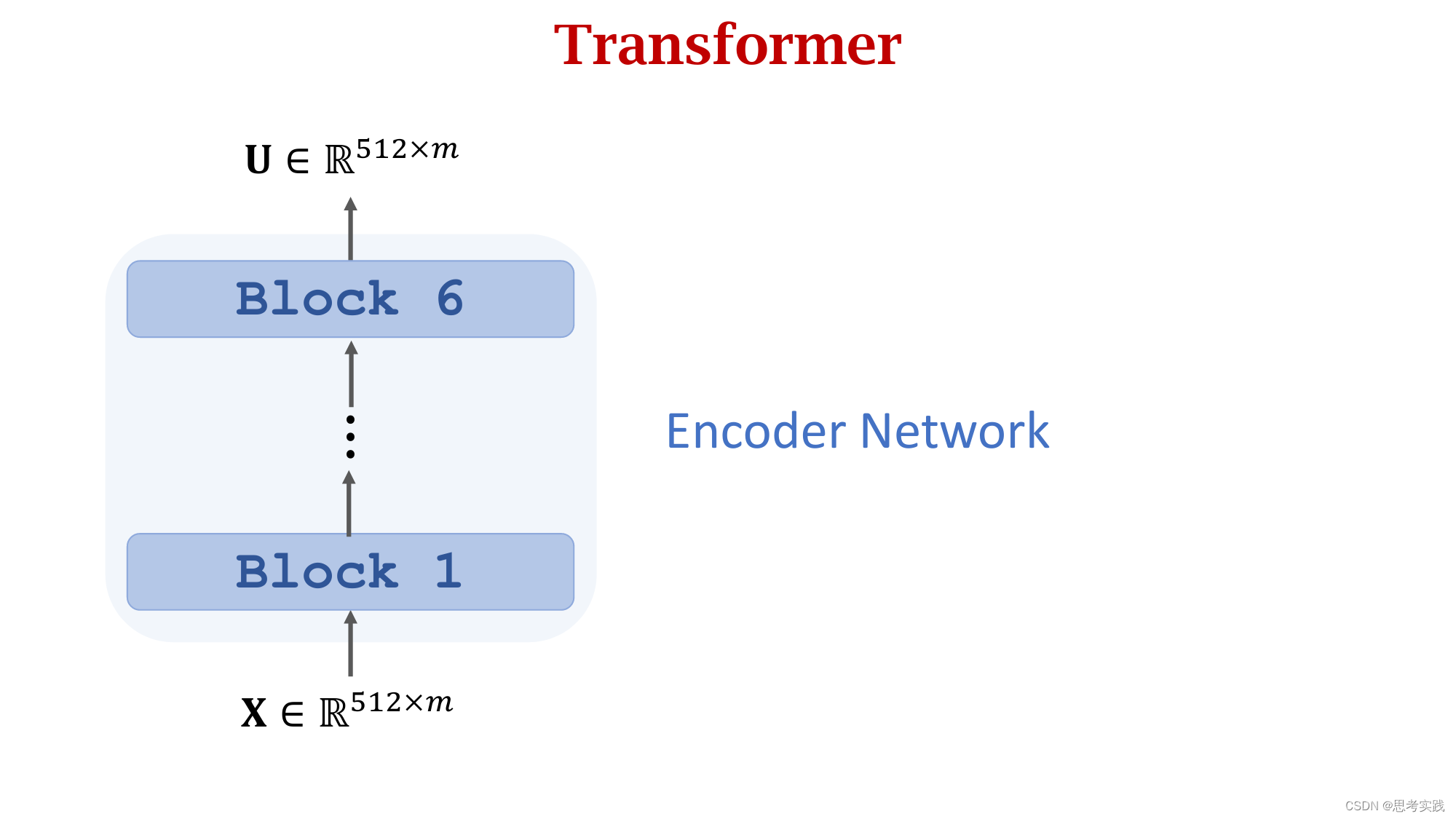
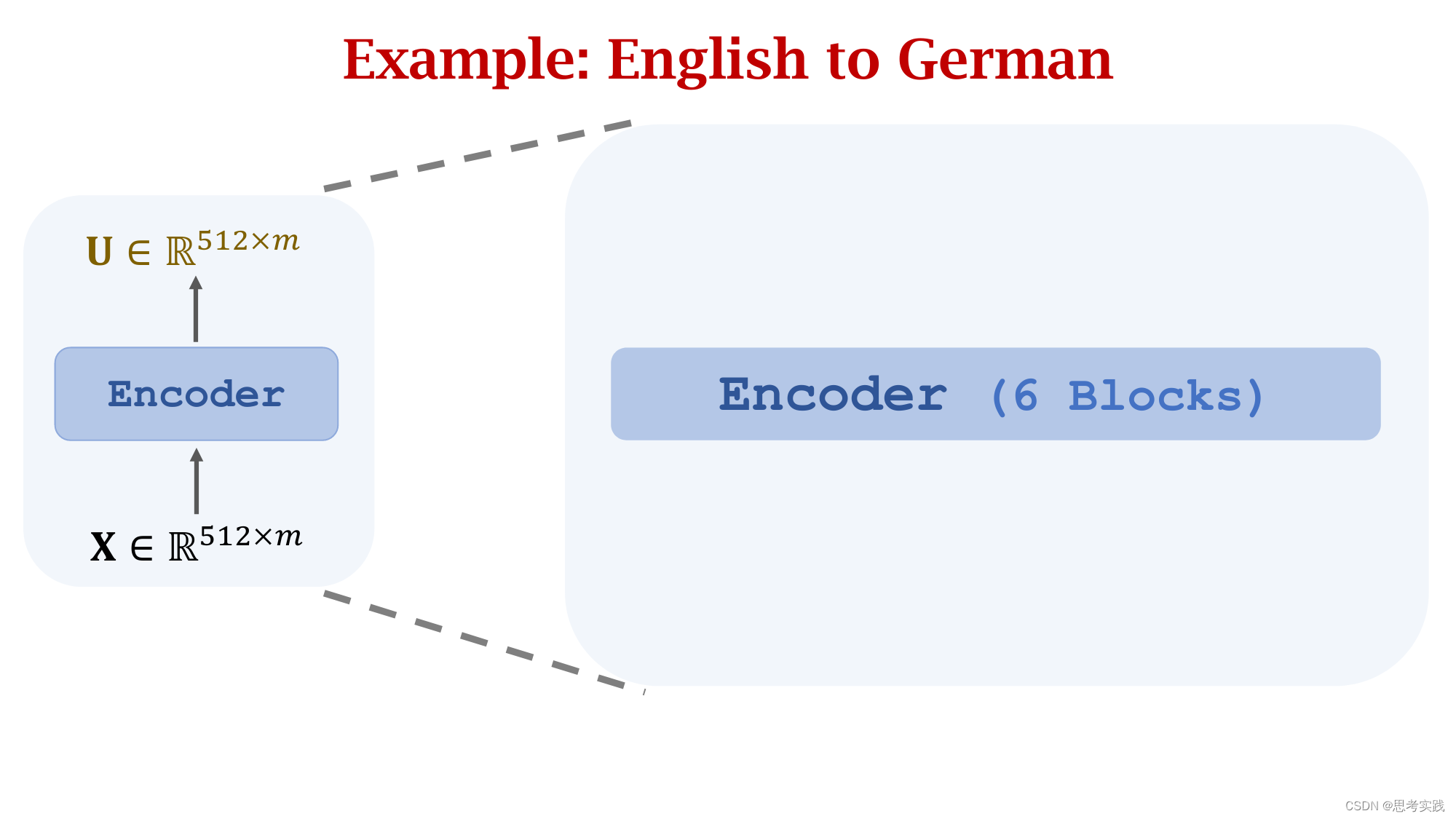
Transformer's Encoder 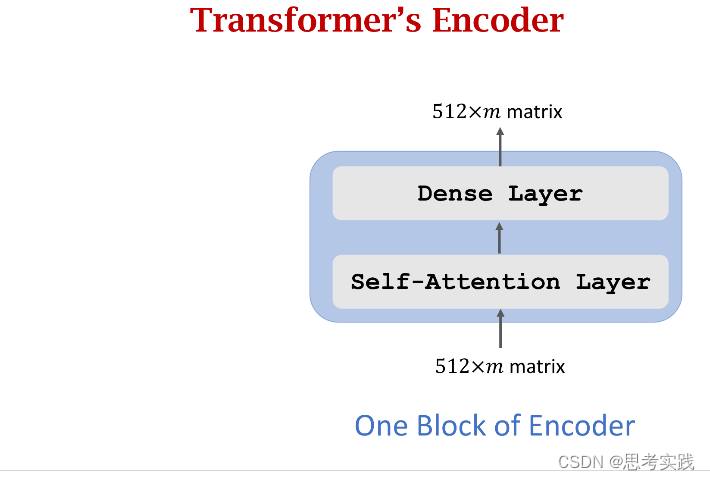
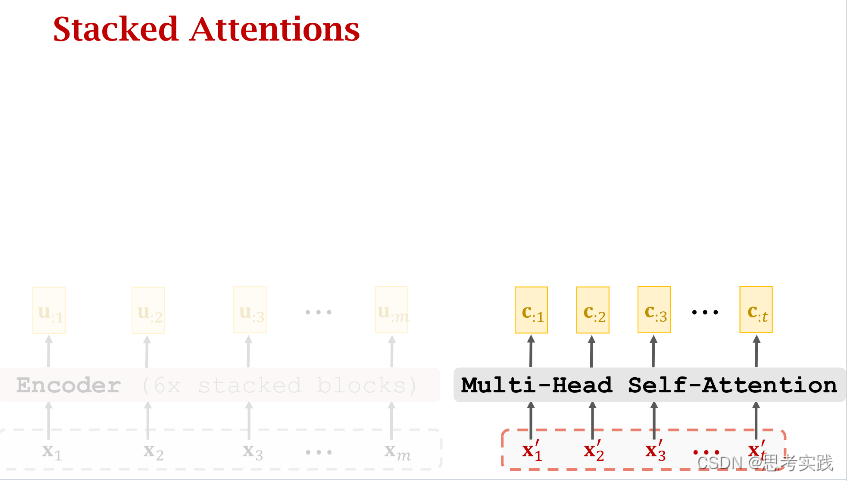
Stacked Attention Layers


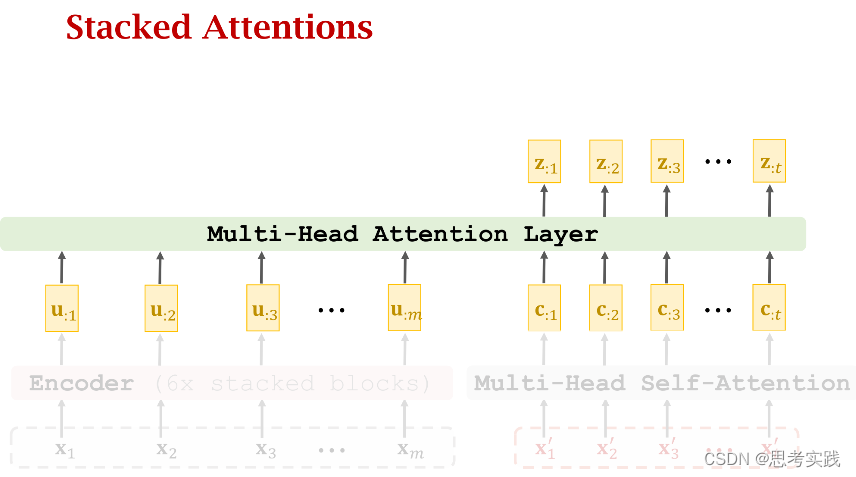
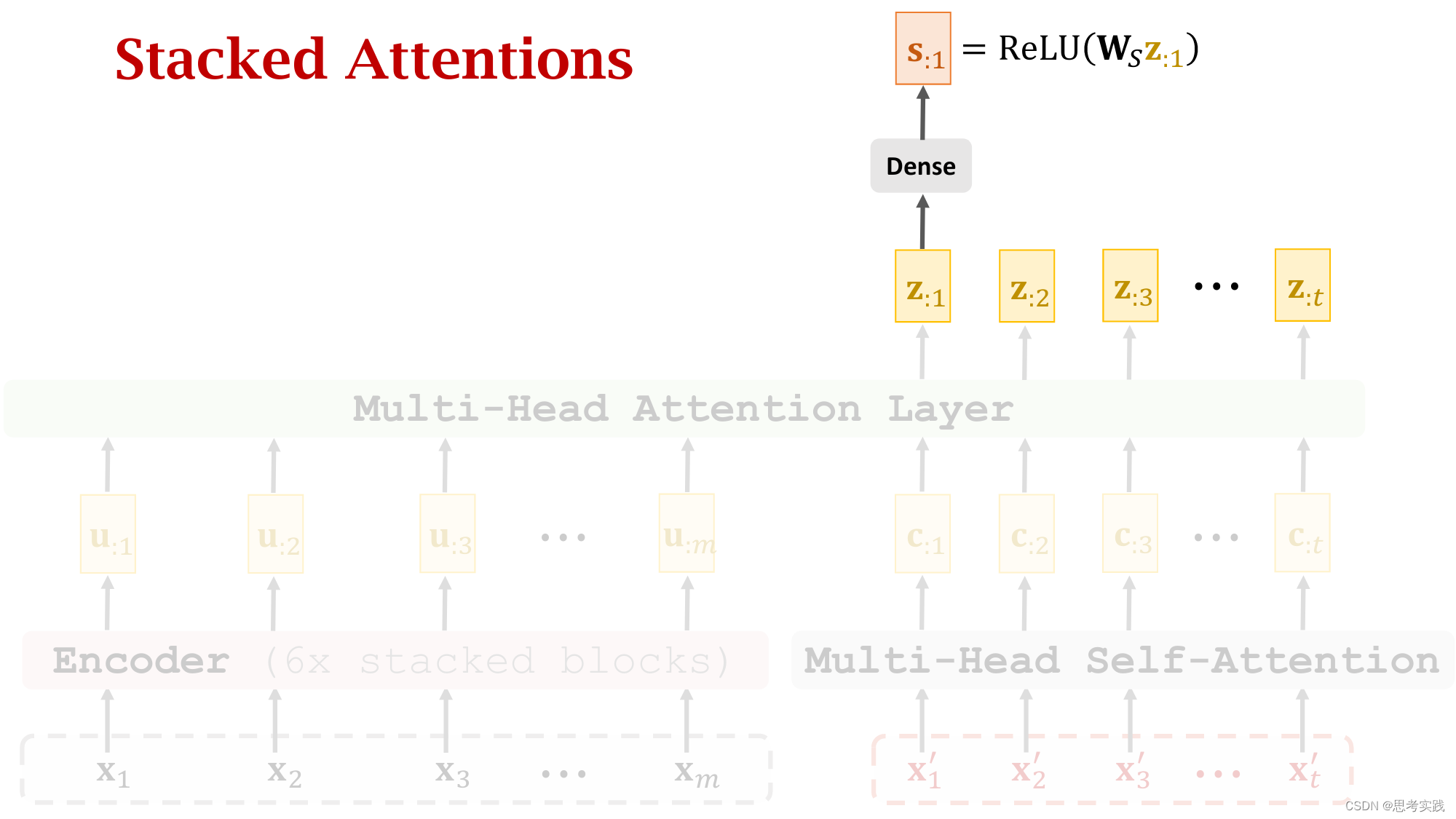
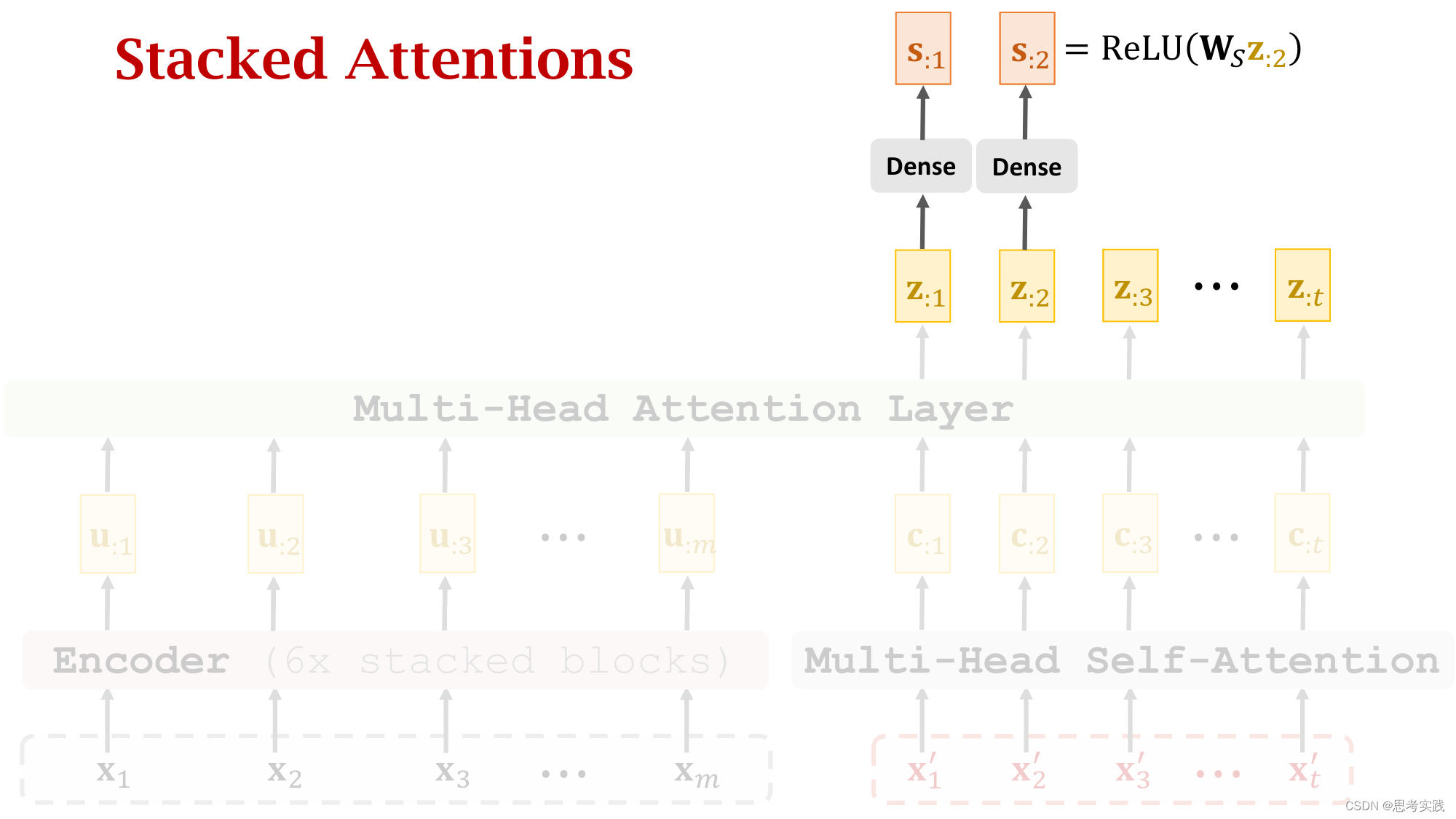
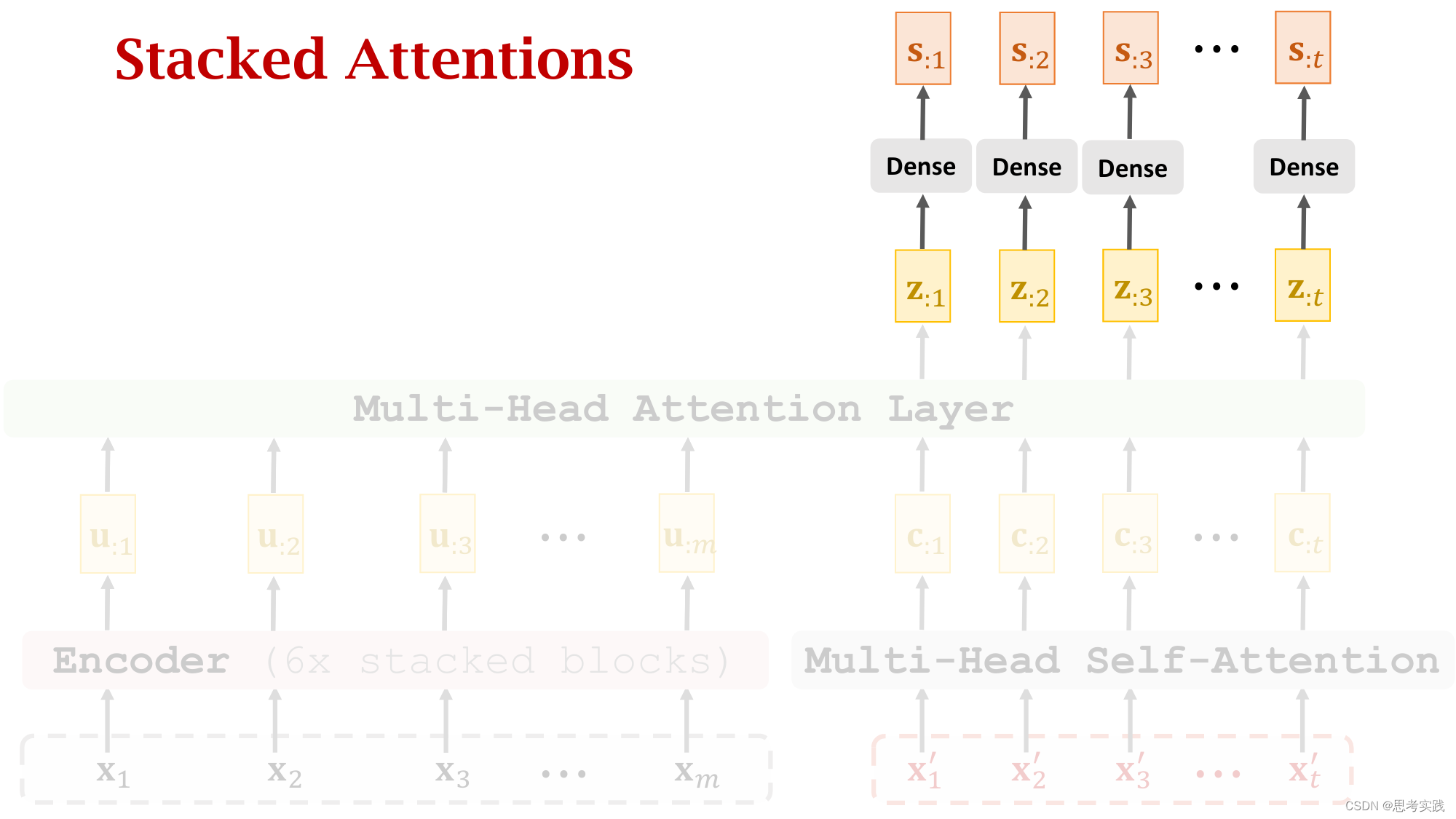

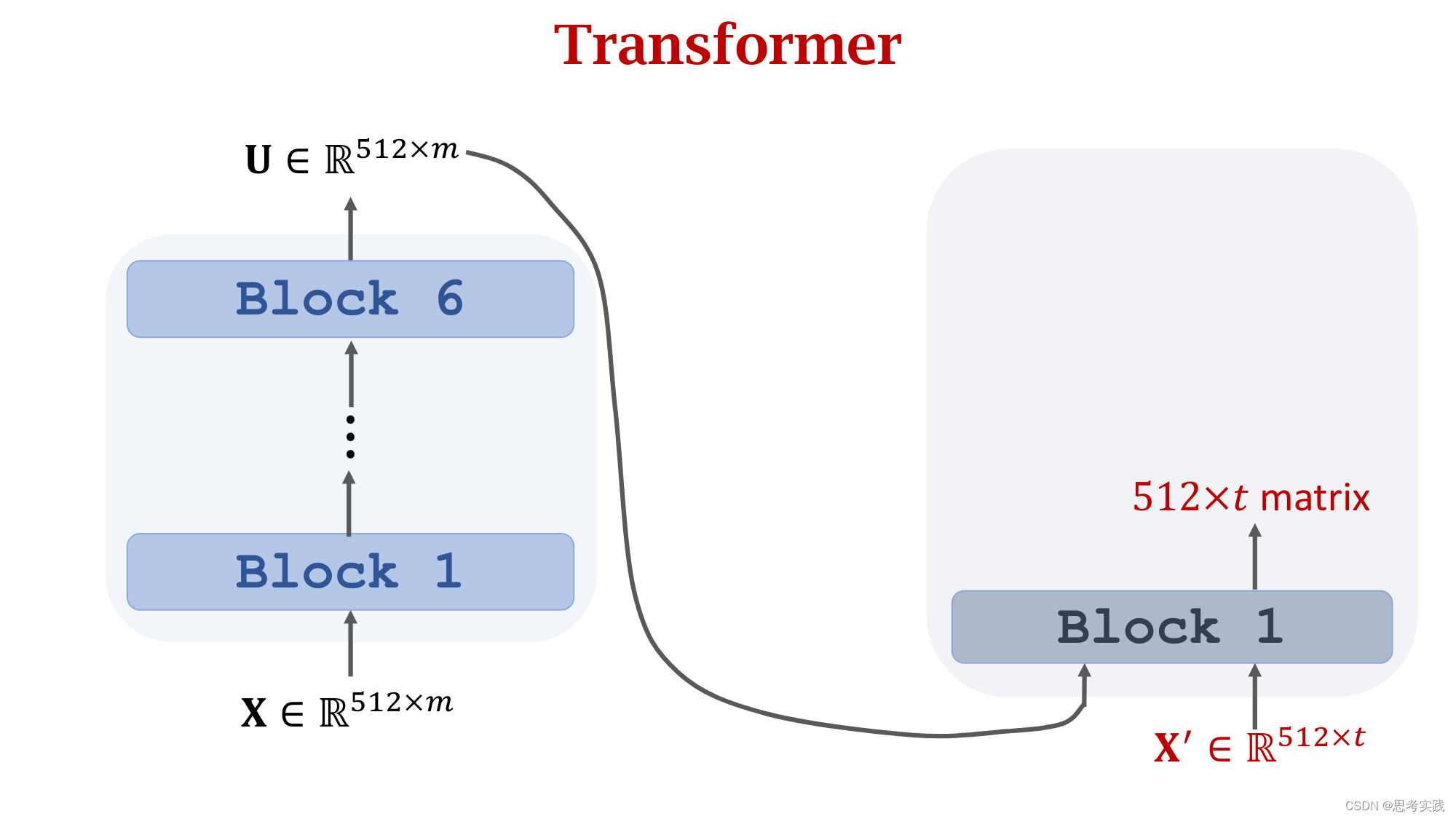
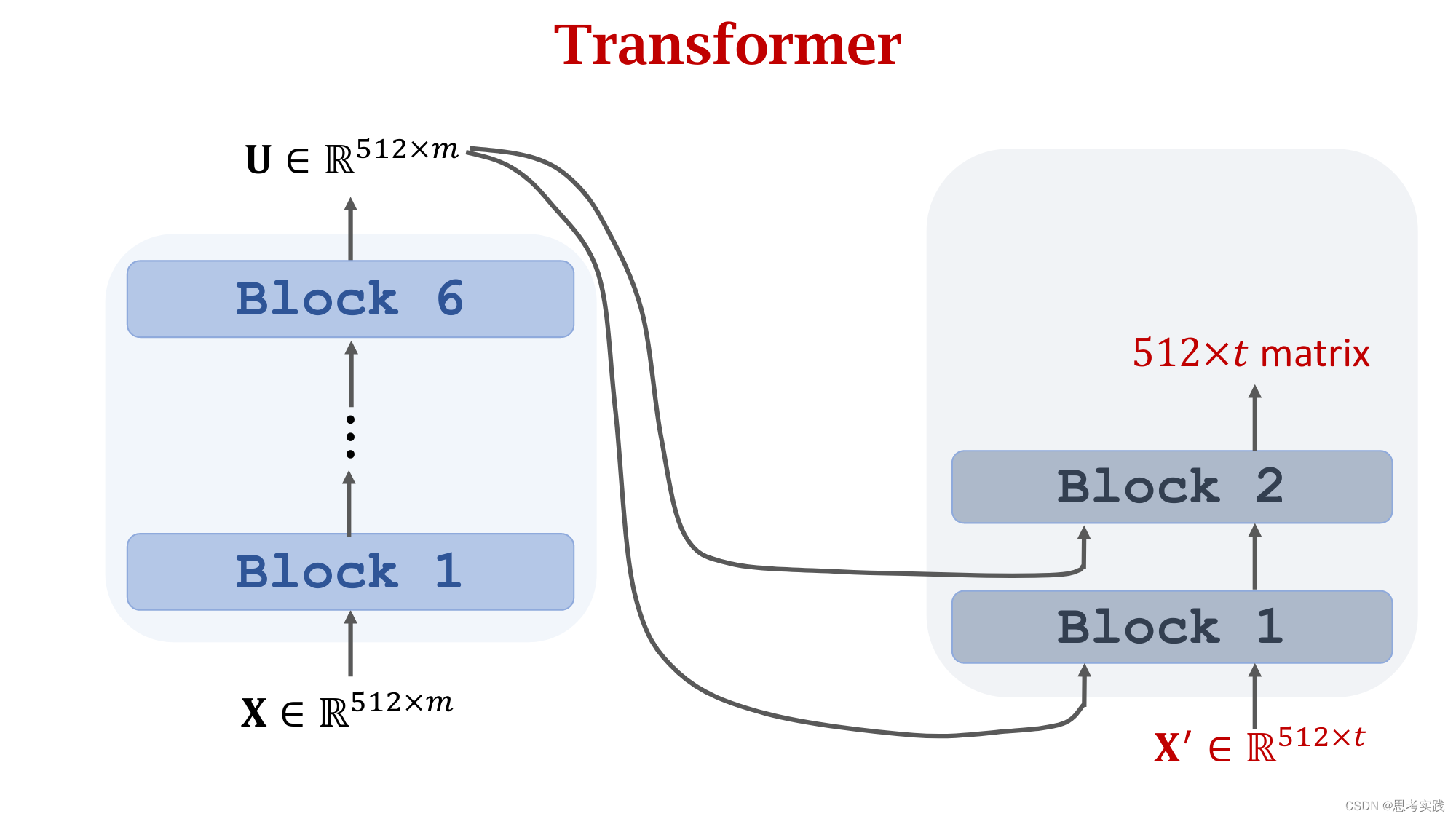
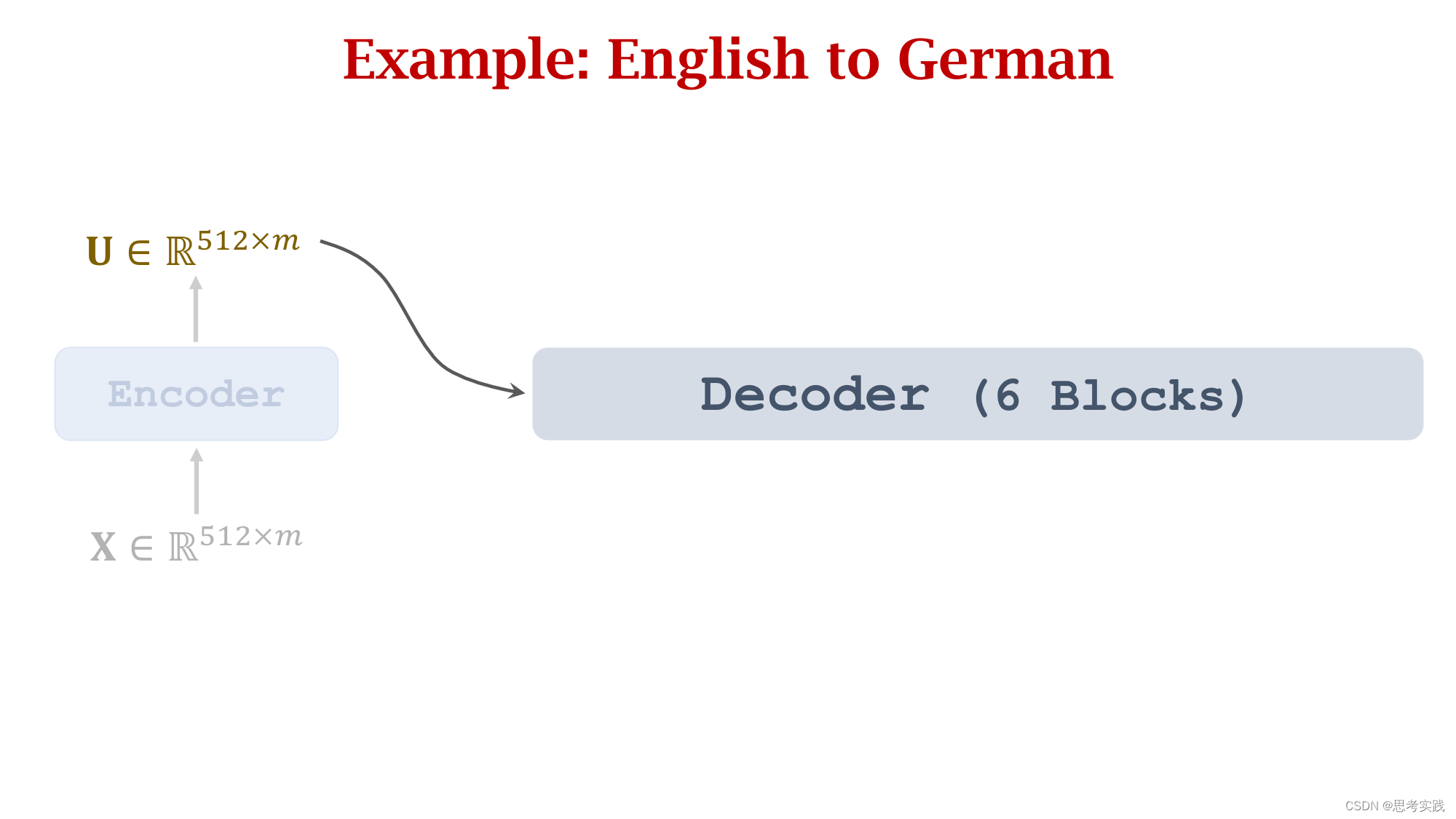
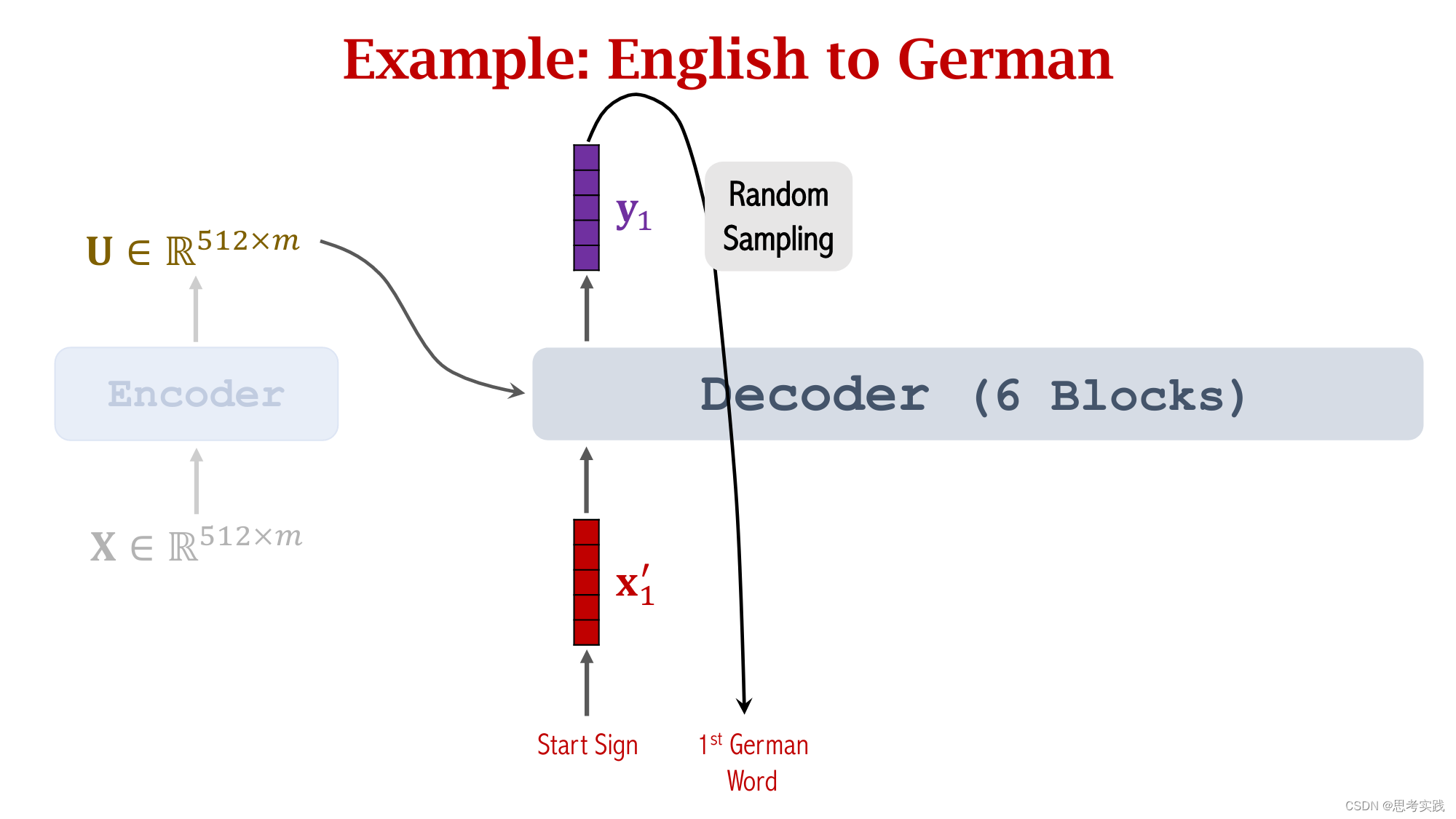
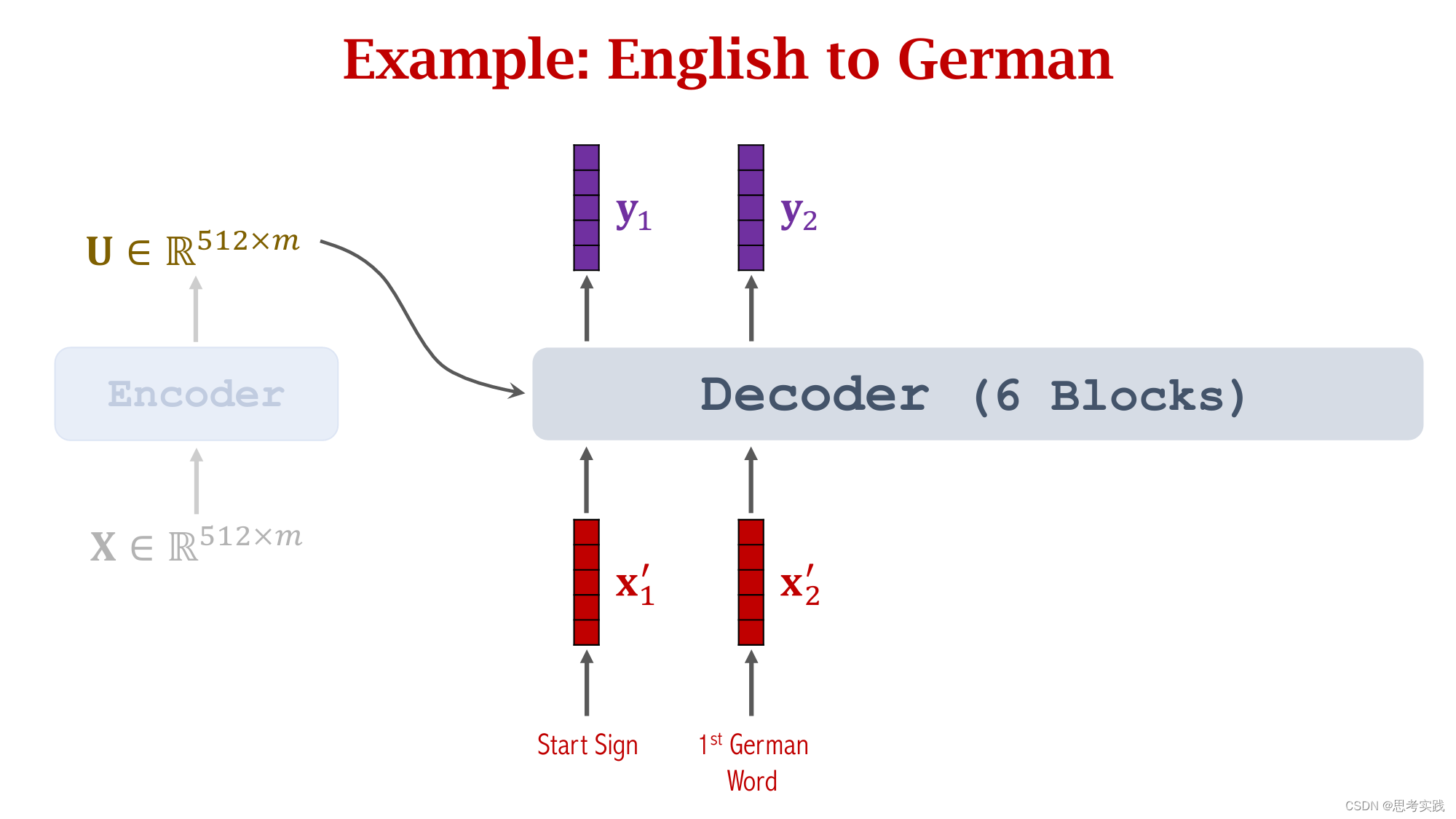
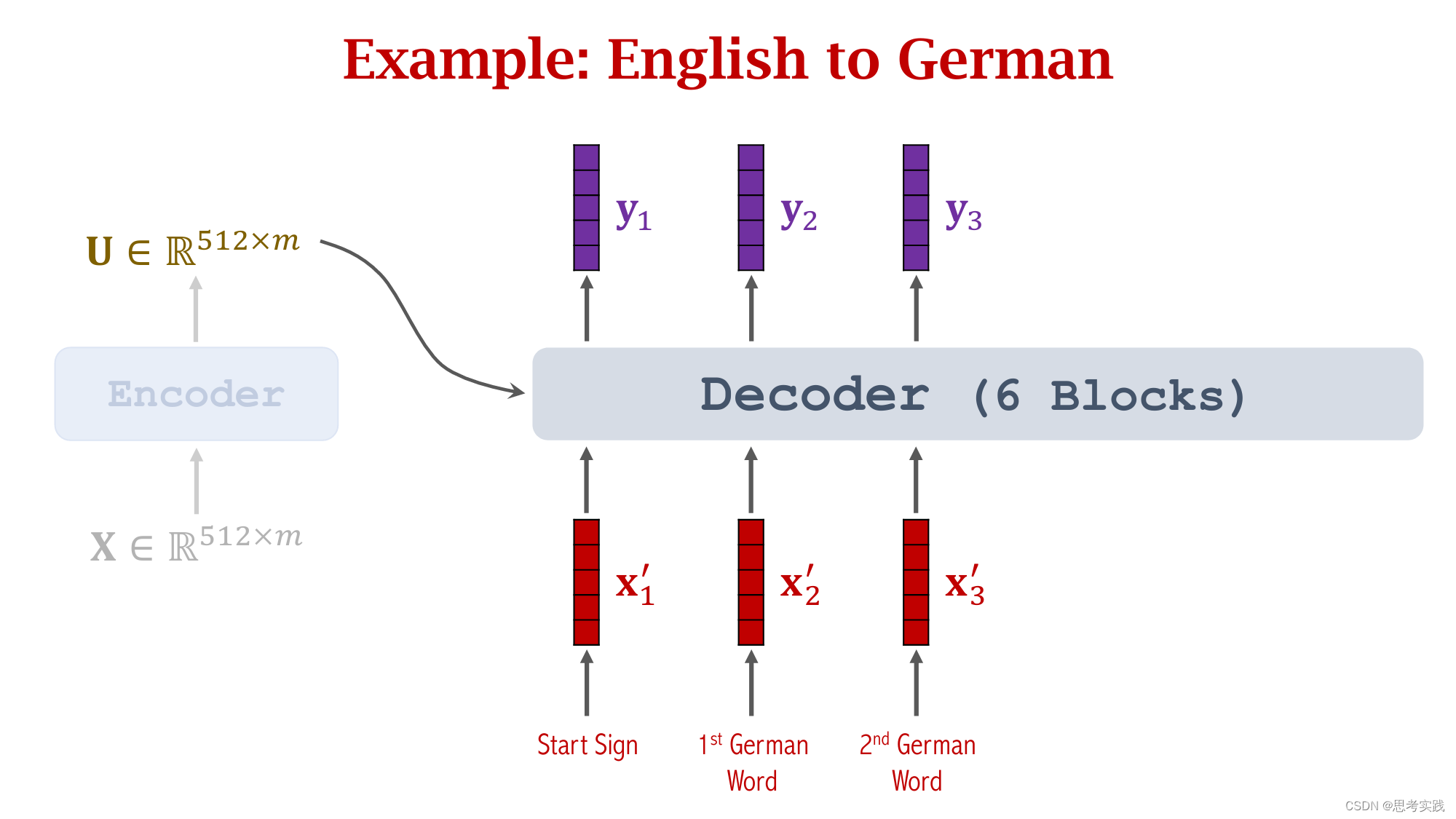
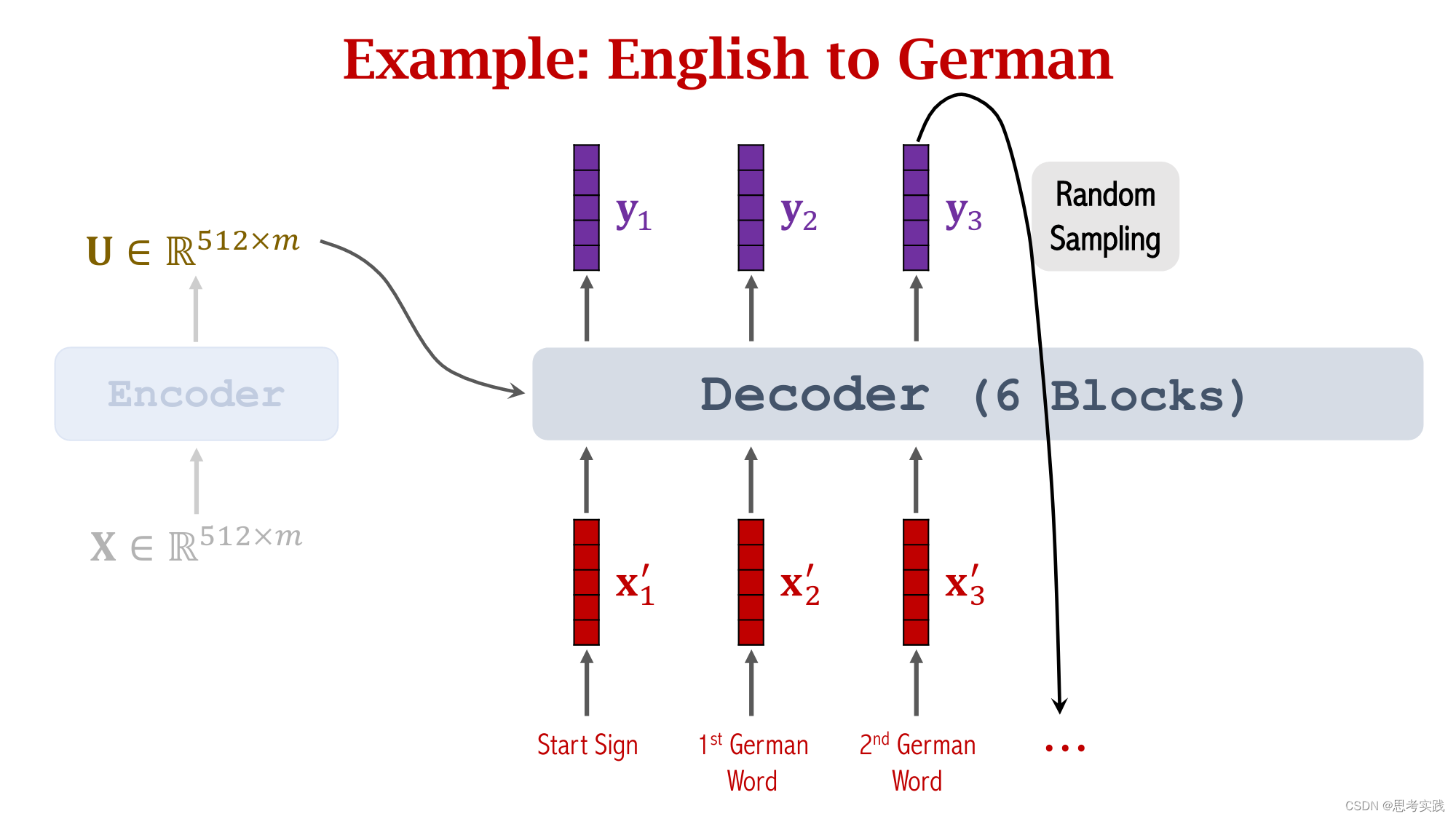
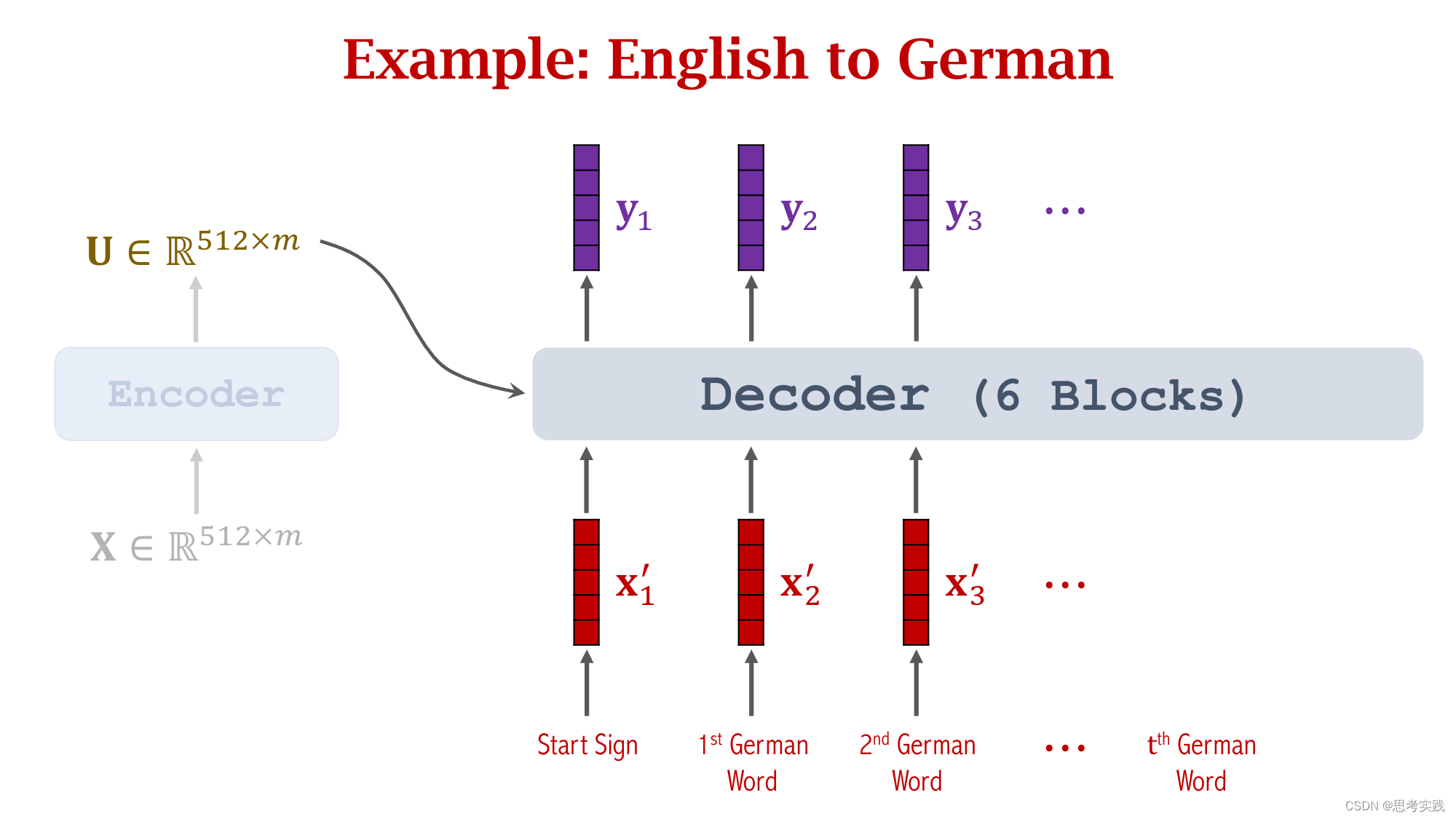
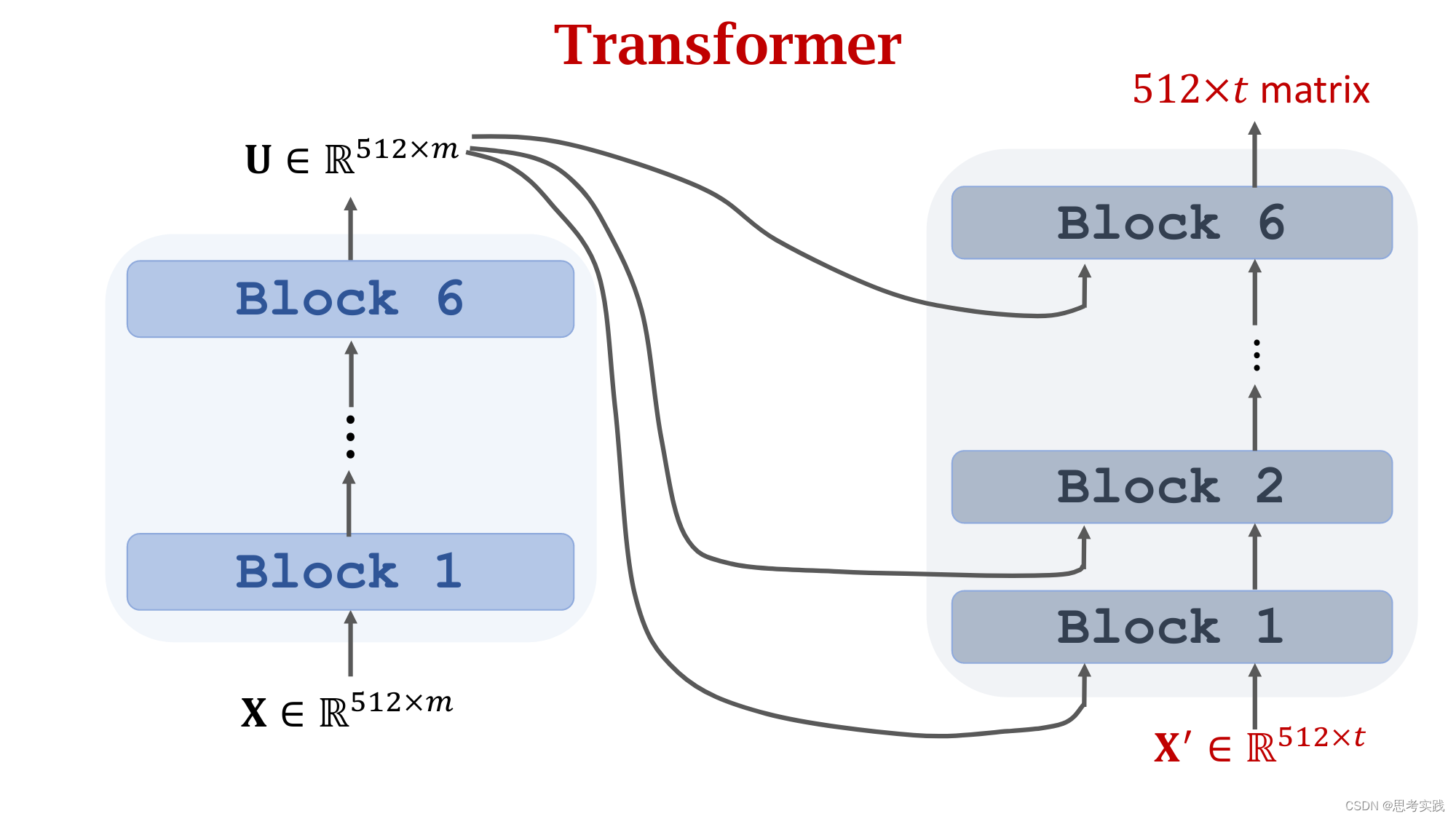 Comparison with RNN Seq2Seq Model
Comparison with RNN Seq2Seq Model









`
参考资料
Transformer模型(1/2): 剥离RNN,保留Attention_哔哩哔哩_bilibili
https://github.com/wangshusen/DeepLearning //Slide are brief and clear,highly recommended
,you can see how attention-machanism get started until transformer use it.

https://github.com/wangshusen/DeepLearning/blob/master/Slides/10_Transformer_1.pdf















 4555
4555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









