









前言
上文我们讲解了什么是高斯过程,接下来我们将会讲解什么是神经过程,实际上就是引入隐变量,将高斯过程网络化。上文分析,高斯过程实际上就是分析输入变量的分布,并依据新的输入在训练样本输入分布中的位置(决定不确定性)来对训练样本的输出分配权重,最后线性组合(决定输出)输出预测值。这个基本逻辑将指导高斯过程的网络化魔改。神经过程由Deep Mind在2018年ICML会议中首次提出,下面我们先对问题进行建模,然后推导,最后给出样例和实现代码。
1. 问题描述
1.1 一般化描述
定义一个随机过程Stochastic process, F F F, 定义 ρ x 1 : n ( y 1 : n ) \rho_{x_{1:n}}(y_{1:n}) ρx1:n(y1:n) 为 ( F ( x 1 ) , F ( x 2 ) , … , F ( x n ) ) (F(x_1),~F(x_2),~\dots,~F(x_n)) (F(x1), F(x2), …, F(xn)) 的边缘分布,那么有: ρ x 1 : n ( y 1 : n ) = ρ x 1 , x 2 , … , x n ( y 1 , y 2 , … , y n ) \rho_{x_{1:n}}(y_{1:n})=\rho_{x_1,~x_2,~\dots,~x_n}(y_1,~y_2,~\dots,~y_n) ρx1:n(y1:n)=ρx1, x2, …, xn(y1, y2, …, yn)
假设随机过程服从分布
f
∼
p
(
f
)
f\sim p(f)
f∼p(f),那么我们有:
ρ
x
1
:
x
(
y
1
:
n
)
=
∫
p
(
f
)
p
(
y
1
:
n
∣
f
,
x
1
:
n
)
d
f
\rho_{x_{1:x}}(y_{1:n})=\int p(f)p(y_{1:n}|f,~x_{1:n})df
ρx1:x(y1:n)=∫p(f)p(y1:n∣f, x1:n)df
假设观测结果
y
y
y带有一定的噪声,即
y
i
=
f
(
x
i
)
+
σ
2
y_i=f(x_i)+\sigma^2
yi=f(xi)+σ2,且样本之间相互独立,则上式可以改写为:
ρ
x
1
:
x
(
y
1
:
n
)
=
∫
p
(
f
)
∏
i
=
1
n
N
(
y
i
∣
f
(
x
i
)
,
σ
2
)
d
f
\rho_{x_{1:x}}(y_{1:n})=\int p(f)\prod_{i=1}^n\mathcal{N}\left(y_i|f(x_i),~\sigma^2\right)df
ρx1:x(y1:n)=∫p(f)i=1∏nN(yi∣f(xi), σ2)df
1.2 分布函数参数化
高斯过程是将随机过程 f f f 的分布假定为一个多元高斯分布,并用均值 μ \mu μ 和方差 Σ \Sigma Σ 参数化表示。神经过程借用了同样的思想,只是现在的分布更加一般化了, f f f 被近似为一个神经网络,且参数为 z z z,网络的目的就是要学习参数 z z z的分布,又是一个网络。 f ( x ) = g ( x , z ) , z ∼ p ( z ) f(x)=g(x,~z),~ z\sim p(z) f(x)=g(x, z), z∼p(z) ρ x 1 : x ( y 1 : n ) = ∫ p ( f ) ∏ i = 1 n N ( y i ∣ g ( x i , z ) , σ 2 ) d f \rho_{x_{1:x}}(y_{1:n})=\int p(f)\prod_{i=1}^n\mathcal{N}\left(y_i|g(x_i, z),~\sigma^2\right)df ρx1:x(y1:n)=∫p(f)i=1∏nN(yi∣g(xi,z), σ2)df这样问题就转化为 p ( z ∣ x 1 : n , y 1 : n ) p(z|x_{1:n},~y_{1:n}) p(z∣x1:n, y1:n)。怎么理解上面的式子?高斯过程是先在一个函数集合 G P \mathcal{GP} GP 中采样出 μ \mu μ, Σ \Sigma Σ,然后再以 x x x为条件,输出 y y y。这里也是同样的过程,先从某一概率分布 p ( z ) p(z) p(z)中采样出 z z z 然后以 x x x 为条件,输出 y y y, 即 g ( x , z ) g(x, z) g(x,z)。下面我们参照https://zhuanlan.zhihu.com/p/42305808的分析逻辑,对NP进行推演。
2.问题求解
2.1 变分推断预备知识
1). 分解边缘分布
为了求后验分布,我们首先想到的是使用变分推断variational inference的方法,而变分法是从边缘分布开始推导的,如下:
p
(
y
)
=
p
(
y
,
z
)
p
(
z
∣
y
)
=
p
(
y
,
z
)
/
q
(
z
)
p
(
z
∣
y
)
/
q
(
z
)
log
p
(
y
)
=
log
p
(
y
,
z
)
q
(
z
)
−
log
p
(
z
∣
y
)
q
(
z
)
log
p
(
y
)
=
∫
q
(
z
)
log
p
(
y
,
z
)
q
(
z
)
d
z
−
∫
q
(
z
)
log
p
(
z
∣
y
)
q
(
z
)
d
z
log
p
(
y
)
=
E
L
B
O
+
K
L
(
q
(
z
)
∥
p
(
z
∣
y
)
)
\begin{aligned} p(y)=&\frac{p(y,z)}{p(z|y)}=\frac{p(y,z)/q(z)}{p(z|y)/q(z)}\\ \log p(y) =& \log\frac{p(y,z)}{q(z)} - \log\frac{p(z|y)}{q(z)}\\ \log p(y) =& \int q(z)\log\frac{p(y,z)}{q(z)}dz - \int q(z)\log\frac{p(z|y)}{q(z)}dz\\ \log p(y) =& ELBO + \mathcal{KL}\left(q(z)\|p(z|y)\right) \end{aligned}
p(y)=logp(y)=logp(y)=logp(y)=p(z∣y)p(y,z)=p(z∣y)/q(z)p(y,z)/q(z)logq(z)p(y,z)−logq(z)p(z∣y)∫q(z)logq(z)p(y,z)dz−∫q(z)logq(z)p(z∣y)dzELBO+KL(q(z)∥p(z∣y)) 在贝叶斯公式中,
p
(
y
)
p(y)
p(y) 为marginal likelihood 也被称作evidence, 因为KL散度表征的是两个概率分布之间的距离,他是没有方向性的,始终大于零,因此具有以下不等式,
e
v
i
d
e
n
c
e
=
E
L
B
O
+
K
L
≥
E
L
B
O
evidence = ELBO + \mathcal{KL} \ge ELBO
evidence=ELBO+KL≥ELBO, evidence lower bound, ELBO 也因此得名,为evidence的下界。变分推断的基本原理就是,当下界ELBO无限逼近evidence分布,KL散度中的两个概率分布将无限靠近,直至为0。此时提议分布proposal distribution,
q
(
z
)
q(z)
q(z) 将无限靠近我们想求解的后验分布
p
(
z
∣
y
)
p(z|y)
p(z∣y),从而解毕。 由于
log
p
(
y
)
\log p(y)
logp(y)是一个确定的数,因此问题最终转换为最大化
E
L
B
O
ELBO
ELBO
2). 求下界ELBO
进一步分析ELBO, 将提议分布
q
(
z
)
q(z)
q(z)改写为引入了先验知识的q(z|y)
E
L
B
O
=
∫
q
(
z
∣
y
)
log
p
(
y
,
z
)
q
(
z
∣
y
)
d
z
=
∫
q
(
z
∣
y
)
log
p
(
y
∣
z
)
p
(
z
)
q
(
z
∣
y
)
d
z
=
E
q
(
z
∣
y
)
[
log
p
(
y
∣
z
)
+
log
p
(
z
)
q
(
z
∣
y
)
]
\begin{equation}\begin{aligned} ELBO=& \int q(z|y)\log\frac{p(y,z)}{q(z|y)}dz\\ =& \int q(z|y)\log\frac{p(y|z)p(z)}{q(z|y)}dz\\ =& \mathbb{E}_{q(z|y)}\left[\log p(y|z) + \log\frac{p(z)}{q(z|y)}\right]\\ \end{aligned}\end{equation}
ELBO===∫q(z∣y)logq(z∣y)p(y,z)dz∫q(z∣y)logq(z∣y)p(y∣z)p(z)dzEq(z∣y)[logp(y∣z)+logq(z∣y)p(z)]
2.2 变分推断应用到当前的场景中
公式(1)中的
y
y
y 变量实际上应该为
y
∣
x
y|x
y∣x,即
x
x
x作为
y
y
y的条件,
x
x
x在整个推导过程中始终处于条件的位置,此外,样本之间相互独立,综上公式(1)的最终结果改写为:
E
L
B
O
=
E
q
(
z
∣
x
1
:
n
,
y
1
:
n
)
[
∑
log
i
=
1
n
p
(
y
i
∣
z
,
x
i
)
+
log
p
(
z
)
q
(
z
∣
x
1
:
n
,
y
1
:
n
)
]
ELBO=\mathbb{E}_{q(z|x_{1:n},~y_{1:n})}\left[\sum\log_{i=1}^n p(y_i|z,~x_i) + \log\frac{p(z)}{q(z|x_{1:n},~y_{1:n})}\right]
ELBO=Eq(z∣x1:n, y1:n)[∑logi=1np(yi∣z, xi)+logq(z∣x1:n, y1:n)p(z)]然而这样处理还不够,对于回归任务,我们的期望是根据一部分已知数据
x
1
:
m
,
y
1
:
m
x_{1:m},~y_{1:m}
x1:m, y1:m,去回归
x
(
m
+
1
)
:
n
x_{(m+1):n}
x(m+1):n 对应的
y
(
m
+
1
)
:
n
y_{(m+1):n}
y(m+1):n,即
p
(
y
(
m
+
1
)
:
n
∣
x
1
:
n
,
y
1
:
m
)
p(y_{(m+1):n}|x_{1:n},~y_{1:m})
p(y(m+1):n∣x1:n, y1:m), 所以最终改写的公式如下:
E
L
B
O
=
E
q
(
z
∣
x
1
:
n
,
y
1
:
n
)
[
∑
log
i
=
m
+
1
n
p
(
y
i
∣
z
,
x
i
)
+
log
p
(
z
∣
x
1
:
m
,
y
1
:
m
)
q
(
z
∣
x
1
:
n
,
y
1
:
n
)
]
\begin{equation} ELBO=\mathbb{E}_{q(z|x_{1:n},~y_{1:n})}\left[\sum\log_{i=m+1}^n p(y_i|z,~x_i) + \log\frac{p(z|x_{1:m},~y_{1:m})}{q(z|x_{1:n},~y_{1:n})}\right] \end{equation}
ELBO=Eq(z∣x1:n, y1:n)[∑logi=m+1np(yi∣z, xi)+logq(z∣x1:n, y1:n)p(z∣x1:m, y1:m)] 这里的
p
(
z
∣
x
1
:
m
,
y
1
:
m
)
p(z|x_{1:m},~y_{1:m})
p(z∣x1:m, y1:m) 也同样是没有办法处理的,因此需要再用一个变分推断,用
q
(
z
∣
x
1
:
m
,
y
1
:
m
)
q(z|x_{1:m},~y_{1:m})
q(z∣x1:m, y1:m)近似他的分布。这里的
x
1
m
,
y
1
:
m
x_{1_m},~y_{1:m}
x1m, y1:m表示上下文信息,contextual information,其输出会与输入的上下文信息发生改变,类似于现在对话系统。我们将
C
\mathcal{C}
C 定义为context 数据,
C
=
{
1
:
m
}
\mathcal{C}=\{1:m\}
C={1:m},
T
=
{
1
:
n
}
\mathcal{T}=\{1:n\}
T={1:n},在代码实现的时候,公式(2)将会改写为:
E
L
B
O
=
E
q
(
z
∣
x
T
,
y
T
)
[
∑
log
i
=
m
+
1
n
p
(
y
i
∣
z
,
x
i
)
]
−
E
q
(
z
∣
x
T
,
y
T
)
[
log
q
(
z
∣
x
T
,
y
T
)
p
(
z
∣
x
C
,
y
C
)
]
=
M
e
a
n
z
∼
q
(
z
∣
x
T
,
y
T
)
(
∑
log
i
=
m
+
1
n
p
(
y
i
∣
z
,
x
i
)
−
K
L
(
q
(
z
∣
x
T
,
y
T
)
,
p
(
z
∣
x
C
,
y
C
)
)
)
\begin{equation} \begin{aligned} ELBO=&\mathbb{E}_{q(z|x_{\mathcal{T}},~y_{\mathcal{T}})}\left[\sum\log_{i=m+1}^n p(y_i|z,~x_i)\right] - \mathbb{E}_{q(z|x_{\mathcal{T}},~y_{\mathcal{T}})}\left[\log\frac{q(z|x_{\mathcal{T}},~y_{\mathcal{T}})}{p(z|x_{\mathcal{C}},~y_{\mathcal{C}})}\right]\\ =&{Mean}_{z\sim q(z|x_{\mathcal{T}},~y_{\mathcal{T}})}\bigg(\sum\log_{i=m+1}^n p(y_i|z,~x_i) - \mathcal{KL}\left(q(z|x_{\mathcal{T}},~y_{\mathcal{T}}),~p(z|x_{\mathcal{C}},~y_{\mathcal{C}})\right)\bigg)\\ \end{aligned} \end{equation}
ELBO==Eq(z∣xT, yT)[∑logi=m+1np(yi∣z, xi)]−Eq(z∣xT, yT)[logp(z∣xC, yC)q(z∣xT, yT)]Meanz∼q(z∣xT, yT)(∑logi=m+1np(yi∣z, xi)−KL(q(z∣xT, yT), p(z∣xC, yC))) 假设网络参数为
θ
\theta
θ, 那么优化方程为:
θ
∗
=
arg
θ
min
(
−
E
L
B
O
θ
)
\theta^* = \arg_{\theta}\min(-ELBO_{\theta})
θ∗=argθmin(−ELBOθ)
3. 神经过程模型 the neural process model
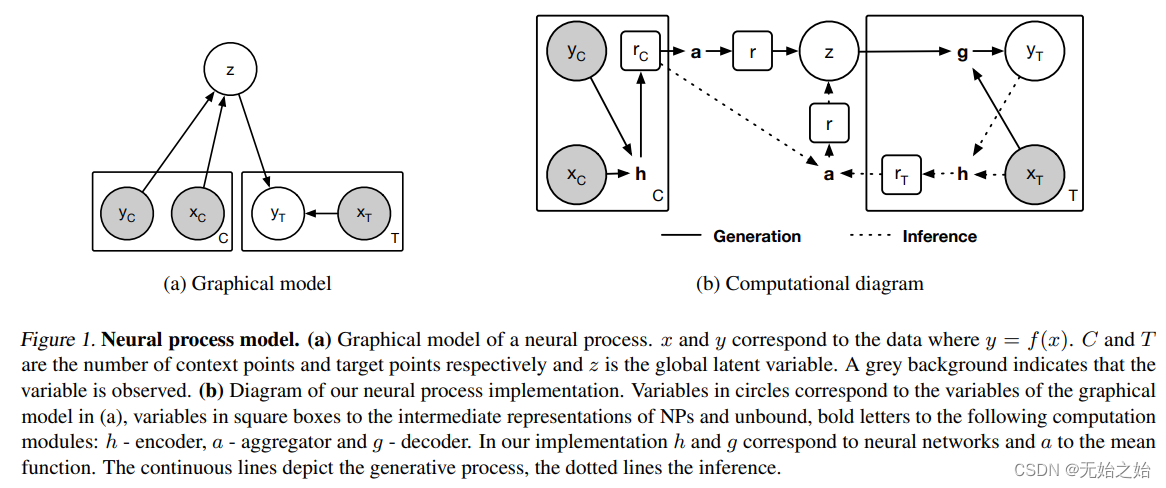
3.1 Reparameterization
1). Motivation
实现这个模型需要使用到 重参数(reparameterization) 的采样的技巧,这篇知乎文章解释得比较清楚。该技巧是一个针对具有期望结构的网络求梯度时的处理技巧。下面我们按照这篇文章https://spaces.ac.cn/archives/6705的逻辑进行讲解:
假设目标形式为:
L
θ
=
E
z
∼
p
θ
(
z
)
[
f
(
z
)
]
\mathcal{L}_\theta=\mathbb{E}_{z\sim p_\theta(z)}\left[f(z)\right]
Lθ=Ez∼pθ(z)[f(z)]进一步展开,连续形式为
L
θ
=
∫
p
θ
(
z
)
f
(
z
)
d
z
\mathcal{L}_\theta=\int p_\theta(z)f(z)dz
Lθ=∫pθ(z)f(z)dz, 离散形式下
L
θ
=
∑
p
θ
(
z
)
f
(
z
)
\mathcal{L}_\theta=\sum p_\theta(z)f(z)
Lθ=∑pθ(z)f(z)。这样的目标经常出现在VAE, GAN, 以及强化学习中。为了最小化
L
θ
\mathcal{L}_\theta
Lθ,我们需要从分布
p
θ
(
z
)
p_\theta(z)
pθ(z)中采样出
z
z
z,但是
p
θ
(
z
)
p_\theta(z)
pθ(z)中具有
θ
\theta
θ的信息,也就是我们需要优化的参数信息。直接采样的话会直接失去
θ
\theta
θ的梯度,从而无法更新参数
θ
\theta
θ。因此,reparameterization 提出的方法是,先把对
z
z
z做个变换,把原来对
z
z
z采样转换为对新的
ε
\varepsilon
ε变量采样,从而
θ
\theta
θ可以显示地出现在采样过程中,完成梯度的传递。步骤为:
Step 1: 从无参数分布
q
(
ε
)
q(\varepsilon)
q(ε)中采样一个
ε
\varepsilon
ε,
Step 2: 通过变换得到
z
=
g
θ
(
ε
)
z=g_\theta(\varepsilon)
z=gθ(ε)得到
z
z
z。
PS: 重参数要求
f
f
f可导
重参数是梯度估计(gradient estimator) 的一个分支, 在梯度估计分支的基本框架如下:
∂
∂
θ
∫
p
θ
(
z
)
f
(
z
)
d
z
=
∫
p
θ
(
z
)
f
(
z
)
p
θ
(
z
)
∂
∂
θ
p
θ
(
z
)
d
z
=
E
z
∼
p
θ
(
z
)
[
f
(
z
)
∂
∂
θ
log
p
θ
(
z
)
]
\frac{\partial}{\partial\theta}\int p_\theta(z)f(z)dz=\int p_\theta(z)\frac{f(z)}{p_\theta(z)}\frac{\partial}{\partial\theta}p_{\theta}(z)dz=\mathbb{E}_{z\sim p_\theta(z)}\left[f(z)\frac{\partial}{\partial\theta}\log p_\theta(z)\right]
∂θ∂∫pθ(z)f(z)dz=∫pθ(z)pθ(z)f(z)∂θ∂pθ(z)dz=Ez∼pθ(z)[f(z)∂θ∂logpθ(z)]这种方法看着很美好,目前效果一般,估计的方差比较大。由于reinforcement learning中的reward function一般都不可导,因此在求解带期望的目标函数时,会研究梯度估计的问题,在搜索相关研究的时候可以同时输入gradient estimator, reinforcement 关键字。
2). 举个栗子
在变分自编码器中用到的采样分布为 p θ ( z ) = N ( z ; μ θ , σ θ 2 ) p_\theta(z)=\mathcal{N}(z; \mu_\theta, \sigma_\theta^2) pθ(z)=N(z;μθ,σθ2),如何转换使得网络能够更新 θ \theta θ, 让网络能够学习?
通过重参数后的采样过程如下:
E
z
∼
N
(
z
;
μ
θ
,
σ
θ
2
)
[
f
(
z
)
]
=
E
ε
∼
N
(
ε
;
0
,
1
)
[
f
(
ε
×
σ
θ
+
μ
θ
)
]
\mathbb{E}_{z\sim\mathcal{N}(z;~\mu_\theta,~\sigma_\theta^2)}[f(z)]=\mathbb{E}_{\varepsilon\sim\mathcal{N}(\varepsilon;~0,~1)}[f(\varepsilon\times\sigma_\theta+\mu_\theta)]
Ez∼N(z; μθ, σθ2)[f(z)]=Eε∼N(ε; 0, 1)[f(ε×σθ+μθ)]
离散目标函数的重参数目前暂时没有涉及到,先按下不表。















 1862
1862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









