







本人的第一次发文,还在努力学习中,可能有不正确的地方,请各位大神轻喷。

数据集介绍:
乳腺癌是全世界妇女中最常见的死亡原因之一。早期检测有助于减少早期死亡的数量。该数据回顾了使用超声扫描的乳腺癌医疗图像。乳房超声数据集被分为三类:正常、良性和恶性图像。乳房超声图像与机器学习相结合,可以在乳腺癌的分类、检测和分割方面产生巨大效果。
本数据集收集的数据包括年龄在25至75岁之间的妇女的乳房超声图像。这个数据是在2018年收集的。患者的数量是600名女性患者。该数据集由780张图像组成,平均图像大小为500*500像素。这些图像是PNG格式的。肿瘤图像(mask)与原始图像(image)一起呈现。这些图像被分为三类,即正常normal(无肿瘤)、良性benign和恶性malignant。
如果你使用这个数据集,请引用:
Al-Dhabyani W, Gomaa M, Khaled H, Fahmy A. Dataset of breast ultrasound images. Data in Brief. 2020 Feb;28:104863. DOI: 10.1016/j.dib.2019.104863.
数据集来源:kaggle
对于机器学习来说,我们需要把不同类型图像给分开以更有利于划分训练集和测试机,本例中需要将image和mask划分并分别把这两种类型图像放置到两个文件夹中以便一一对应。
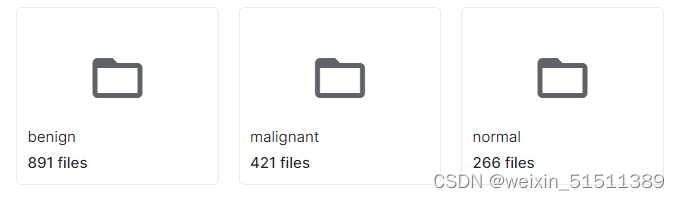
数据集初始状态
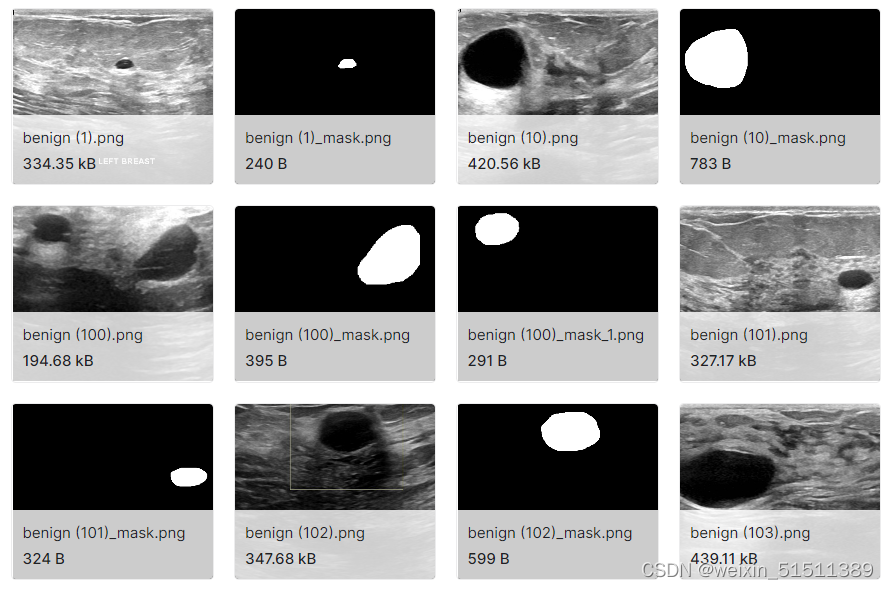
image和mask混合在一起
此部分需要先将正常,良性和恶性所对应的图片细分到六个文件夹里即正常image/正常mask,良性image/良性mask,恶性image/恶性mask。
本人的做法是先将每个文件夹中以mask.png结尾的文件筛选出来并移动到指定目录:
src = r"./images"#原混合图片文件夹路径
dst = r"./masks"#创建放对应mask图片文件夹路径
def moveimages(src,dst): #定义移动函数
new_path=dst
for derName, subfolders, filenames in os.walk(src):
print(derName)
print(subfolders)
print(filenames)
for i in range(len(filenames)):
if filenames[i].endswith('_mask.png'):
file_path=derName+'/'+filenames[i]
newpath=new_path+'/'+filenames[i]
shutil.copy(file_path,newpath)
os.remove(file_path)
elif filenames[i].endswith('_mask_1.png'or'_mask_3.png'or'_mask_2.png'):
file_path=derName+'/'+filenames[i]
os.remove(file_path)
#处理良性样本
moveimages(src+'\\benign',dst+'\\benign')
#处理恶性样本
moveimages(src+'\\malignant',dst+'\\malignant')
#处理正常样本
moveimages(src+'\\normal',dst+'\\normal')
#删除图片文件多余字符,仅保留数字+后缀,如(01).png
#Windows系统下使用powertoys对文件进行批量更名数据初步处理完成,将分好的原图像image和掩码mask分别汇总起来并且要做到一一对应,这样才能让模型学习image和mask的关系。例如良性01号图要和良性01号mask图对应。
from glob import glob
bNames = glob(r'../input/donewelldataset/images/benign/*')
mNames = glob(r'../input/donewelldataset/images/malignant/*')
nNames = glob(r'../i 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2433
2433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









