







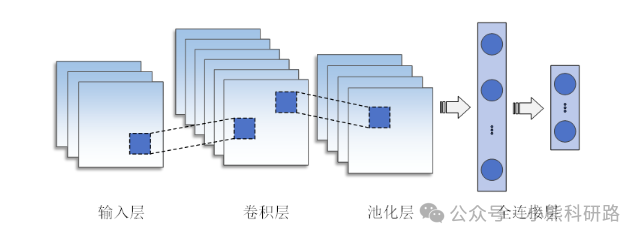
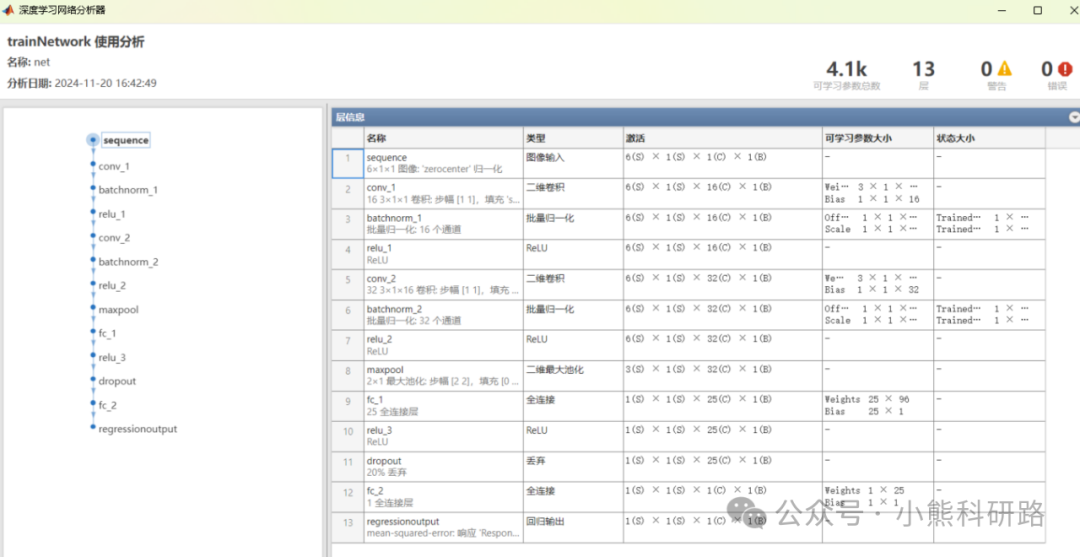
卷积神经网络(Convolutional Neural Networks, CNN)是包含卷积计算且具有深度结构的前馈神经网络,主要由三部分组成:卷积层、池化层和全连接层,其基本型的完整架构展示具体结构如图1所示。
1) 卷积层
在CNN中卷积层位于关键位置,其主要功能是对输入数据进行特征提取。借助卷积运算,卷积层能够有效捕获数据中的重要特征,并加强原始信号中的关键特征,同时有效减少特征的维度。卷积核根据预先设定的参数在特征图上执行扫描运算,从而生成输出特征,其中二维卷积神经网络的卷积过程如图2所示。
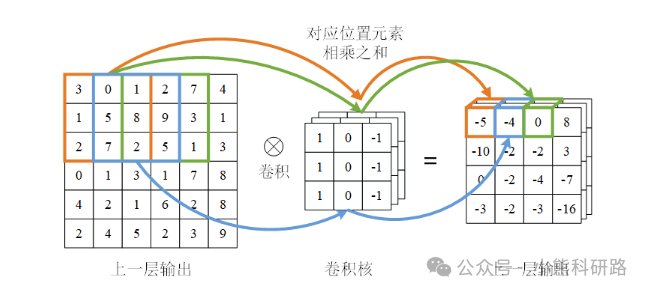
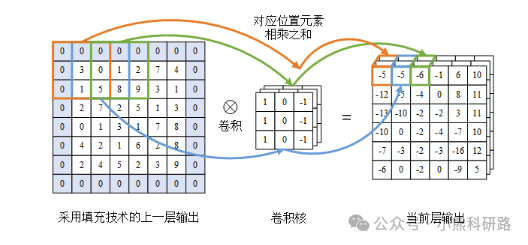
卷积层存在两个主要缺陷:1) 数据边界的限制导致边缘信息丢失,边缘数据仅对少数输出数据有影响,而中间数据影响更多,使得边缘信息难以充分利用; 2) 随着卷积层数增多,输出数据尺寸逐渐缩小,限制了深度卷积神经网络的应用。填充技术解决这两个问题,通过在输入数据边界外填充某些特定的值(一般是 0),增大输入数据尺寸,保持输出数据尺寸不缩减,提高边界数据对输出的影响,采用填充技术后卷积运算过程如图3所示。
(2) 池化层
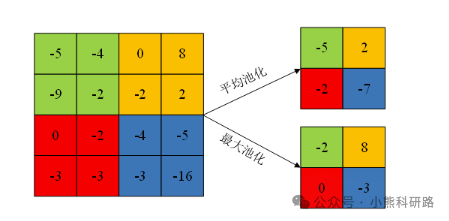
池化层通过对卷积层输出的特征进行进一步筛选,提取更具代表性和重要性的特征信息,实现降维效果,池化层卷积操作如图4所示。
(3) 激活层
激活层引入非线性性,通过对全连接层的输出或卷积层的输出应用激活函数(Activation Function),使网络能够学习更复杂的模式,激活函数之前已讲解过,在此不再赘述。
(4) 全连接层
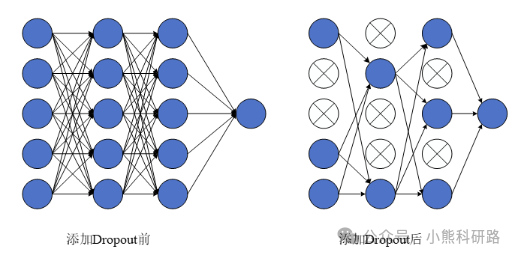
全连接层位于卷积神经网络(CNN)的末端,用于整合CNN提取的特征,并进行回归分析。全连接层包含参数较多,能有效提升数据拟合精度。根据任务类型,在全连接层中添加相应的函数,并引入Dropout。Dropout在模型训练期间,通过随机地忽略一部分神经元,来增强模型的非线性能力和鲁棒性,同时提升计算能力和速度。Dropout结构如图5所示。
CNN回归预测步骤:
(1)数据准备:
收集和整理需要用于回归预测的输入数据和目标值(即标签)。
对数据进行预处理,例如归一化或标准化,以确保数据在同一范围内,便于网络训练。
(2)模型构建:
构建卷积神经网络模型,通常包括输入层、若干个卷积层、池化层、全连接层以及输出层。
卷积层用于提取数据中的特征,池化层用于减少特征图的尺寸,从而降低计算复杂度和防止过拟合。
(3)模型训练:
将预处理后的数据输入到构建好的CNN模型中。
通过定义的损失函数(如均方误差)来评估模型预测值与实际值之间的差异。
使用优化算法(如梯度下降)调整模型参数,使损失函数的值逐步减小,从而提高模型的预测精度。
(4)模型评估:
使用验证数据集对训练好的模型进行评估,以检测其预测性能和泛化能力。
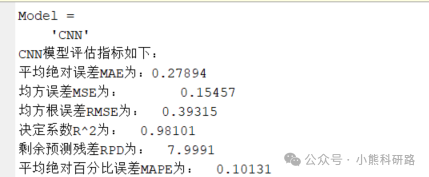
通过一些评价指标(如均方误差、平均绝对误差)来量化模型的预测效果。
(5)模型优化:
根据评估结果,对模型进行调整和优化,可能需要调整网络结构、优化算法或超参数。
反复进行训练和评估,直到模型性能达到预期标准。
(6)模型预测:
使用训练好的CNN模型对新数据进行回归预测,输出预测值。
根据需求,对预测结果进行后处理或应用。
运行效果及数据集样式展示:
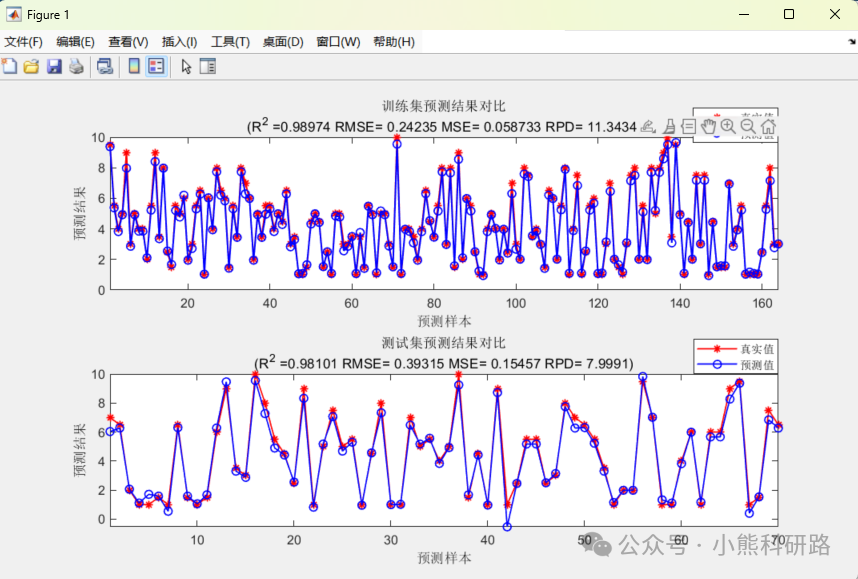
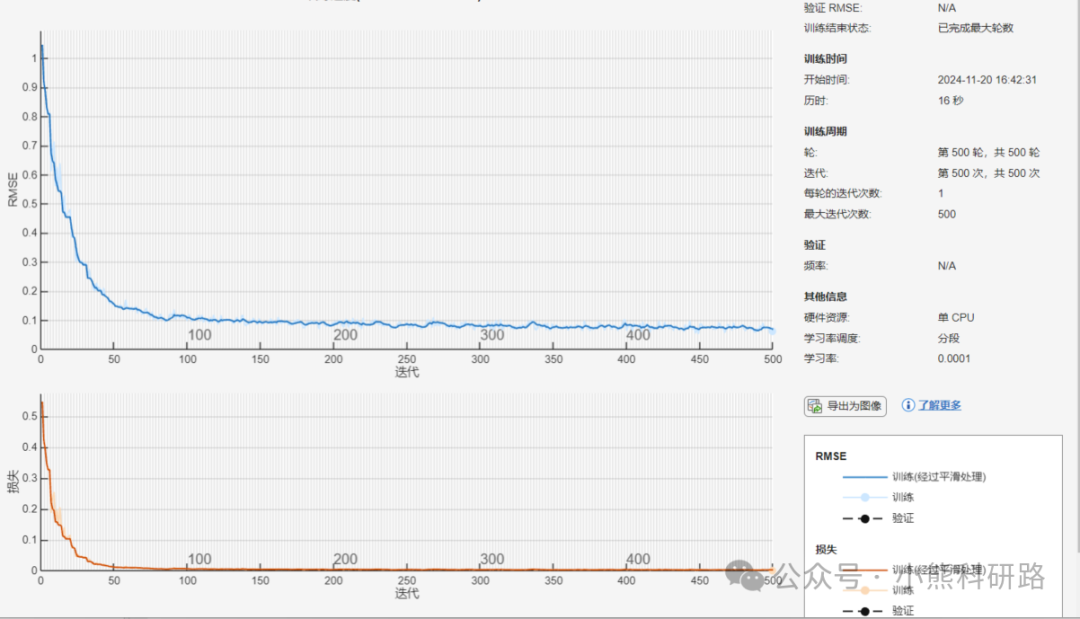
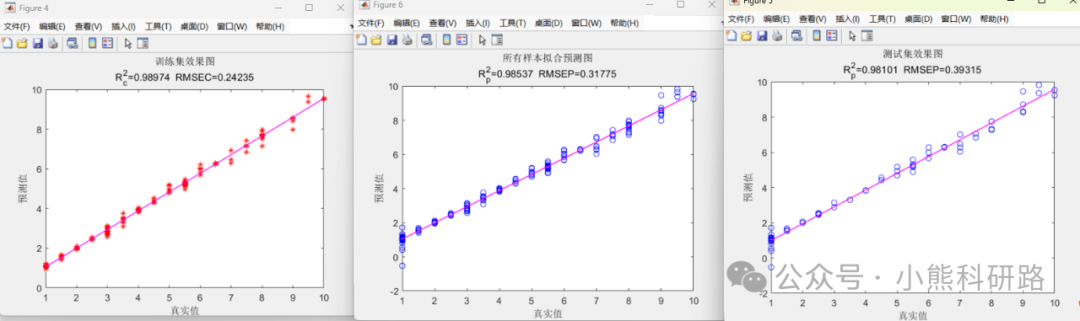
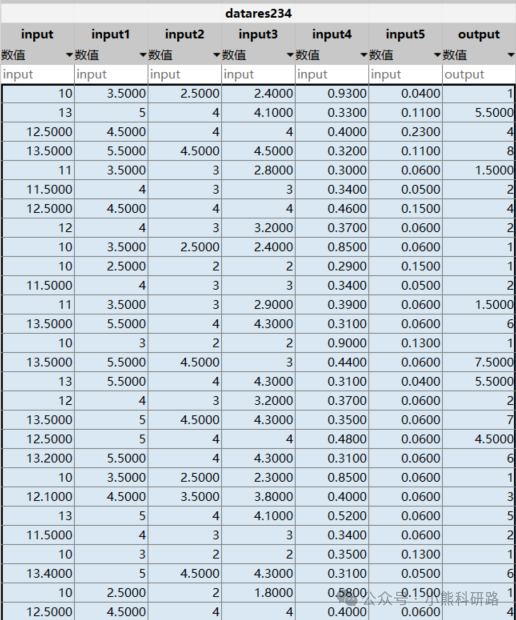
本文采用Matlab编写了深度学习之卷积神经网络CNN回归预测模型代码,代码注释详细,编写逻辑清晰易懂,可一键运行,数据集采用excel数据形式,方便替换数据集。适合新手学习和SCI建模使用。
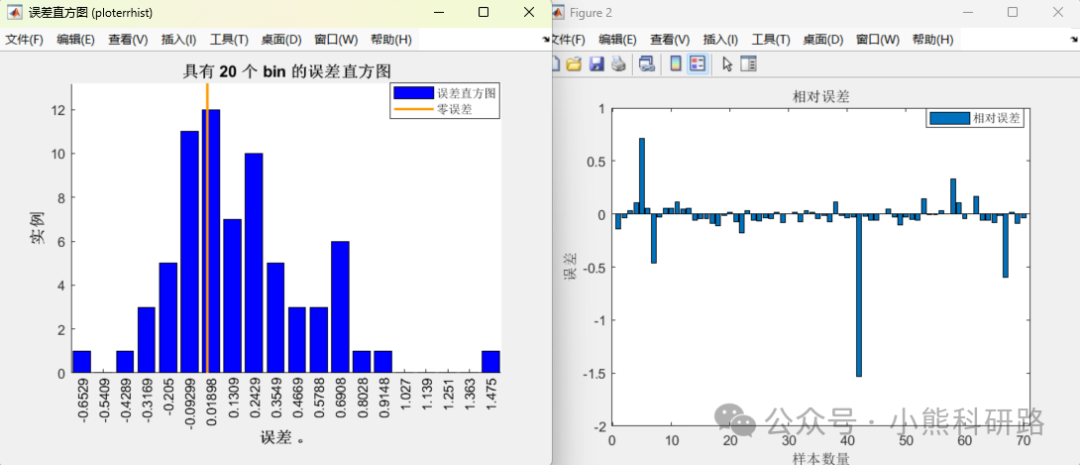
评价指标全面包括 MAE,MAPE,MSE,RMSE,R2,error,errorPercent,RPD等性能指标,出图包括训练集和预测集预测对比图果,拟合效果图,误差直方图、相对误差图等进行可视化分析,使用起来简单方便,直接替换成自己的数据即可生成美观图形用于写作。

















 849
849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









