







 本文深入探讨了机器学习中的性能度量,包括查准率、查全率、F1度量、混淆矩阵、ROC与AUC的概念,并分析了代价敏感错误率与代价曲线的重要性。通过实例解释了不同场景下如何权衡这些指标,特别强调了F1度量在不同应用场景中的意义,以及代价曲线在决策中的作用。
本文深入探讨了机器学习中的性能度量,包括查准率、查全率、F1度量、混淆矩阵、ROC与AUC的概念,并分析了代价敏感错误率与代价曲线的重要性。通过实例解释了不同场景下如何权衡这些指标,特别强调了F1度量在不同应用场景中的意义,以及代价曲线在决策中的作用。
废话不说,本文分为两个部分:
- 第一部分,我对周志华教授《机器学习》这本书中性能度量知识点中疑难点的学习感悟
- 第二部分,我感觉该书2.3节 性能度量 中最后部分的代价曲线表述有误,苦于没找到联系教授的正确方式,故希望与广大网友一起探讨
查准率、查全率与F1
在异常检测的机器学习模型中,如图1所示,1表示检测为正常(positive),0表示检测为异常(negative)。那么,查准率(precision)是预测为正例的样本中预测正确的概率;查全率(recall,亦称召回率)是正例样本被预测正确的概率。顾名思义,对于检测正常(检测1)的查准率越大,检测为正常的样本越可信;查全率越大,检测出来的正常样本越多。对于检测异常(检测0)也是一个道理。以信息检索为例,根据检索结果中感兴趣词条和不感兴趣词条可以计算precision,根据检索结果中感兴趣词条和所有感兴趣词条数目(包括未检索出来的) 可以计算recall。
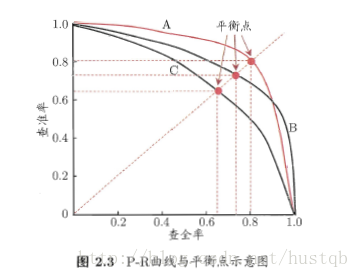
理论上,precision与recall**相互矛盾**,如图2所示。图2是一个 P-R曲线与平衡点示意图 ,可以看出无法兼顾准确率和查全率。此时有几种不同的选值方法:
1. 选取凸点,即梯度为-1的点。
2. 选取如图所示的平衡点。
3. F1度量。
4. 比较P-R曲线的包络,如下图C被B完全包围,则模型B的性能优于模型C。

F1度量
F1是基于precision与recall的调和平均(harmonic mean):
1F1=12⋅(1P+1R) 1 F 1 = 1 2 ⋅ ( 1 P + 1 R )
F1度量平衡了precision和negative,但是为什么不用算术平均而是用调和平均呢??
原因是调和平均会在P和R相差较大时偏向较小的值,是最后的结果偏差,比较符合人的主观感受。
在一些应用中,对查准率和查重率的重视程度不同。例如在商品推荐系统中,为了尽可能少打扰用户,更希望推荐内容确是用户感兴趣的,此时查准率更重要;而在逃犯信息检索系统中,更希望尽可能少漏掉逃犯,此时查全率更重要。F1度量的一般形式—— Fβ F β ,能让我们表到处对查准率/查全率的不同偏好,它定义为:
Fβ F β 是加权调和平均:
1Fβ=1β2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1009
1009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









