







1.解释Lifted ,Structured
structured:结构化
可以参考structured learning : to prediction structured ojects ,rather than scalar discrete or real values.For example,the problem of translating a natural language sentence into a syntactic representation such as a parse tree can be seen as a structured prediction problem in which the structured output domain is the set of all possible parse trees.
feature embedding:特征映射
Lifting problem : 参考 Homotopy lifting property
wiki:https://en.wikipedia.org/wiki/Homotopy_lifting_property
2.what is metric learning
度量学习,也就是为了学习一个度量函数,也是一个相似性函数,使得相似的物体的语义距离近,不相似的物体的语义距离远.
当前主流的Metric learning 方法当属triplet loss,常见的还有Contrastive loss,但是这两种方法都没有很充分的利用每个training batch 的信息。引用原文的一句话:
taking full advantage of the training batches in the neural network training by lifting the vector of pairwise distance within the batch to the matrix of pairwise distances
3.what is the problem
the existing approaches cannot take full adwantage of the training batches used during the mini-batch stochastic gradient descent traning of the networks 。即,由于采用的是deep learning 的方法,我们采用的SGD随机梯度方法训练网络,每次计算都是一个batch,triplet 和contrastive 这这两种方法都没有充分利用整个batch size,triplet 是一个三元组(achor,negative,postive),contrastive是一个二元组(xi,xj)(xi,xj可以是来自同一个类,或者来自不同类),如果是triplet 和 contrastive ,每个batch size 都是由这些二元组或者三元组组成,如下图
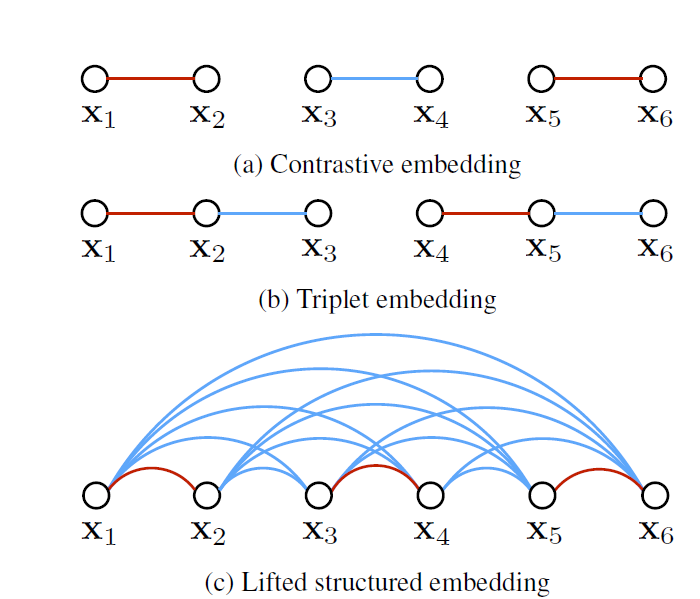
计算loss 和更新权重时,只依赖(x1,x2),(x3,x4),(x5,x6),而跟(x1,x3),(x4,x6)等等没有关系,triplet也有这种问题。
为了充分利用一个batch 里样本,来更新权重和计算loss,作者就提出了 Lifted Structured embedding
4 . what is Lifted Structured embedding
如果想学习最完美的metric learning 函数,那么理论上的loss 函数:
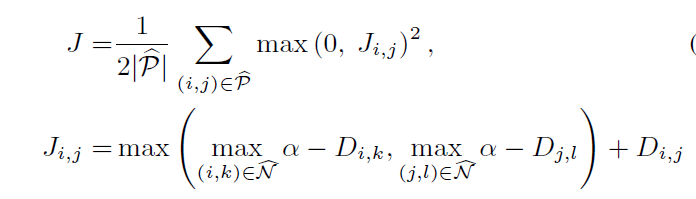
P是train set里的正样本对集,N是train set里所有可能的负样本对集,但是如果想用deep learning来实现的话,那么可以看到,负样本对太多了。
所以这样就导致了两个问题:
(1)loss 是一个非光滑函数
(2)计算或者估计次梯度需要频繁的求最小的pairs,而且是再整个样本集。
那么怎么解决这个问题呢:
(1)将loss 换成一个光滑的上界函数来代替;
(2)将样本集分成无数小的batch,每个batch 采用上述方法计算loss
因此从之前的O(m)pairs变成了O(m^2) 个pairs
5 .定义距离函数
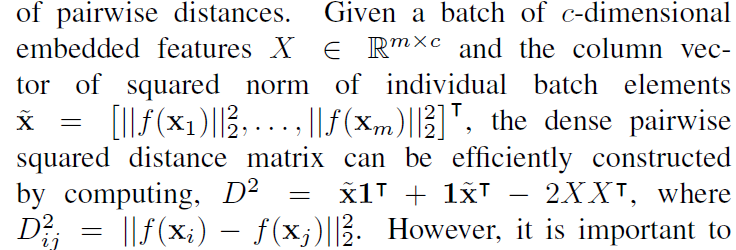
f(x)是cnn 学习到的特征,将每张图片映射到这个256维的向量,然后用这256维向量来计算距离。
6.光滑的上界函数是
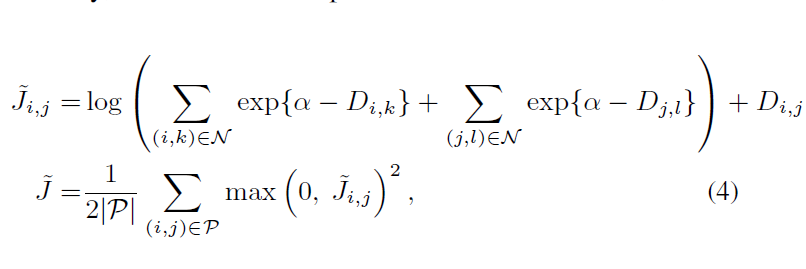
转化为光滑的上界函数也是因为:嵌套的max loss函数会导致network 收敛到一个坏的局部最优点。
然后就是对着loss函数求导了:
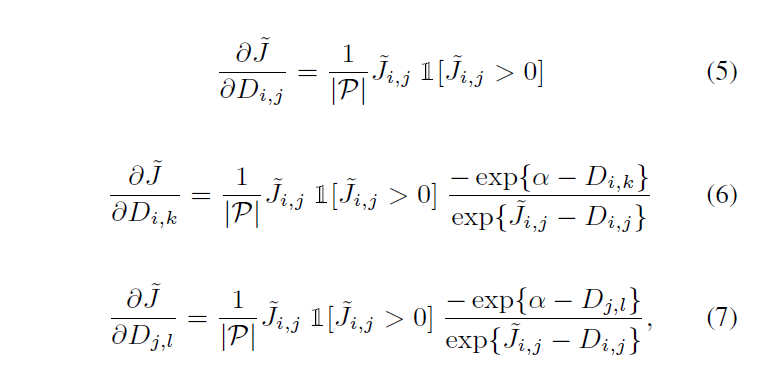

lifted structured feature embedding 大大增加了训练的样本数目pairs num;















 2735
2735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









