






1、数据集简介
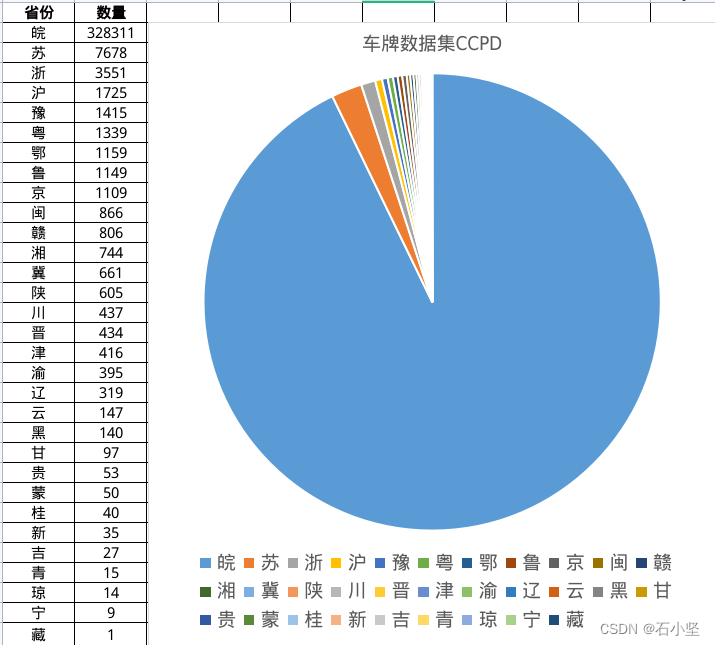
传统车牌检测和识别都是在小规模数据集上进行实验和测试,所获得的算法模型无法胜任环境多变、角度多样的车牌图像检测和识别任务。为此,中科大团队建立了CCPD数据集,这是一个用于车牌识别的大型国内停车场车牌数据集——CCPD(Chinese City Parking Dataset),数据集主要在合肥市的停车场采集得来,采集时间早上7:30到晚上10:00,手工标注车牌位置。拍摄的车牌照片涉及多种复杂环境,包括模糊、倾斜、阴雨天、雪天等等。CCPD数据集一共包含将近30万张图片。
关于车牌号码的含义和蓝绿牌照的区别,可以参考下方链接:
2、数据集规格
CCPD数据集分为蓝牌数据集CCPD2019和新能源车牌数据集CPDD2020,前者采集的车辆、环境比较多,数据庞大,而后者则可以作为补充采集的数据集。

CCPD2019数据集包含将近30万张图片、图片尺寸为720x1160x3,共包含8种类型图片,每种类型、数量及类型说明如下表:
| 类型 | 图片数 | 说明 |
| ccpd_base | 199998 | 正常车牌 |
| ccpd_challenge | 10006 | 比较有挑战的车牌 |
| ccpd_db | 20001 | 光线较暗或较亮车牌 |
| ccpd_fn | 19999 | 距离摄像头较远或较近 |
| ccpd_np | 3036 | 没上牌的新车 |
| ccpd_rotate | 9998 | 水平倾斜20-50度,垂直倾斜-10-10度 |
| ccpd_tilt | 10000 | 水平倾斜15-45度,垂直倾斜-15-45度 |
| ccpd_weather | 9999 | 雨天、雪天或大雾的车牌 |
| 总共283037张车牌图像 |
CCPD的标注数据格式较为特别,是通过解析图片名的方式获取具体信息,也就是说图像名就是标注内容。如图片【025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg】,其文件名的含义如下:
- 025:车牌区域占整个画面的比例;
- 95_113: 车牌水平和垂直角度, 水平95°, 竖直113°
- 154&383_386&473:标注框左上、右下坐标,左上(154, 383), 右下(386, 473)
- 86&473_177&454_154&383_363&402:标注框四个角点坐标,顺序为右下、左下、左上、右上
- 0_0_22_27_27_33_16:车牌号码映射关系如下: 第一个0为省份 对应省份字典provinces中的’皖’,;第二个0是该车所在地的地市一级代码,对应地市一级代码字典alphabets的’A’;后5位为字母和文字, 查看车牌号ads字典,如22为Y,27为3,33为9,16为S,最终车牌号码为皖AY339S
车牌字典如下:
- 省份:[“皖”, “沪”, “津”, “渝”, “冀”, “晋”, “蒙”, “辽”, “吉”, “黑”, “苏”, “浙”, “京”, “闽”, “赣”, “鲁”, “豫”, “鄂”, “湘”, “粤”, “桂”, “琼”, “川”, “贵”, “云”, “藏”, “陕”, “甘”, “青”, “宁”, “新”]
- 地市:[‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘J’, ‘K’, ‘L’, ‘M’, ‘N’, ‘P’, ‘Q’, ‘R’, ‘S’, ‘T’, ‘U’, ‘V’, ‘W’,‘X’, ‘Y’, ‘Z’]
- 车牌号字典:[‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘J’, ‘K’, ‘L’, ‘M’, ‘N’, ‘P’, ‘Q’, ‘R’, ‘S’, ‘T’, ‘U’, ‘V’, ‘W’, ‘X’,‘Y’, ‘Z’, ‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’]
3、数据集工具
由于数据集标注比较独特,为了方便不同需求的朋友进行解析和使用,笔者给出了数据集的解析工具,可以直接通过调用parser_annotations(image_file)函数,即可返回标注信息,并可视化车牌标注的结果。

# -*-coding: utf-8 -*-
"""
代码需要用到pybaseutils工具,请使用pip安装即可:pip install pybaseutils
"""
import os
import cv2
import numpy as np
from tqdm import tqdm
from pybaseutils import file_utils, image_utils
def get_plate_licenses(plate):
"""
普通蓝牌共有7位字符;新能源车牌有8位字符: https://baike.baidu.com/item/%E8%BD%A6%E7%89%8C/8347320?fr=aladdin
《新能源电动汽车牌照和普通牌照区别介绍》https://www.yoojia.com/ask/4-11906976349117851507.html
新能源汽车车牌可分为三部分:省份简称(1位汉字)十地方行政区代号(1位字母)十序号(6位)
字母“D”代表纯电动汽车;
字母“F”代表非纯电动汽车(包括插电式混合动力和燃料电池汽车等)。
:param plate:
:return:
"""
provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤",
"桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "O"]
alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V',
'W', 'X', 'Y', 'Z', 'O']
ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X',
'Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'O']
result = [provinces[int(plate[0])], alphabets[int(plate[1])]]
result += [ads[int(p)] for p in plate[2:]]
result = "".join(result)
# 新能源车牌的要求,如果不是新能源车牌可以删掉这个if
# if result[2] != 'D' and result[2] != 'F' \
# and result[-1] != 'D' and result[-1] != 'F':
# print(plate)
# print("Error label, Please check!")
print(plate, result)
return result
def parser_annotations(image_file):
"""
:param image_file: 图片路径
:return: 返回标注信息info
"""
filename = os.path.basename(image_file)
try:
annotations = filename.split("-")
rate = annotations[0] # 车牌区域占整个画面的比例;
angle = annotations[1].split("_") # 车牌水平和垂直角度, 水平95°, 竖直113°
box = annotations[2].replace("&", "_").split("_") # 标注框左上、右下坐标,左上(154, 383), 右下(386, 473)
point = annotations[3].replace("&", "_").split("_") # 标注框四个角点坐标,顺序为右下、左下、左上、右上
plate = annotations[4].split("_") # licenses 标注框四个角点坐标,顺序为右下、左下、左上、右上
plate = get_plate_licenses(plate)
box = [int(b) for b in box]
point = [int(b) for b in point]
point = np.asarray(point).reshape(-1, 2)
bboxes = [box]
angles = [angle]
points = [point]
plates = [plate]
labels = ["plate"] * len(bboxes)
except Exception as e:
bboxes = []
points = []
labels = []
plates = []
angles = []
info = {"filename": filename, "bboxes": bboxes, "points": points,
"labels": labels, "plates": plates, "angles": angles}
return info
def save_plate_licenses(image, bboxes, plates, out_dir, name=""):
crops = image_utils.get_bboxes_crop(image, bboxes)
for i in range(len(crops)):
label = plates[i]
# image_id = file_utils.get_time(format="p")
file = os.path.join(out_dir, "{}_{}_{:0=3d}.jpg".format(label, name, i))
file_utils.create_file_path(file)
cv2.imwrite(file, crops[i])
def converter_CCPD2voc(image_dir, vis=True):
"""
将CCPD数据集转换为VOC数据格式(xmin,ymin,xmax,ymax)
:param image_dir: BITVehicle数据集图片(*.jpg)根目录
:param annot_file: BITVehicle数据集标注文件VehicleInfo.mat
:param out_voc: 输出VOC格式数据集目录
:param vis: 是否可视化效果
"""
print("image_dir :{}".format(image_dir))
class_set = []
image_list = file_utils.get_images_list(image_dir)
for i, image_file in enumerate(tqdm(image_list)):
info = parser_annotations(image_file)
labels = info["labels"]
bboxes = info["bboxes"]
points = info["points"]
plates = info["plates"]
angles = info["angles"]
image_name = info["filename"]
print("i={},plates:{},angles(水平,垂直角度):{}".format(os.path.basename(image_file), plates, angles))
if len(labels) == 0:
continue
image_name = os.path.basename(image_name)
img_postfix = image_name.split(".")[-1]
image_id = image_name[:-len(img_postfix) - 1]
class_set = labels + class_set
class_set = list(set(class_set))
if not os.path.exists(image_file):
print("not exist:{}".format(image_file))
continue
image = cv2.imread(image_file)
if vis:
image = image_utils.draw_image_bboxes_text(image, bboxes, plates, color=(255, 0, 0), thickness=3,
fontScale=1.2, drawType="chinese")
# image = image_utils.draw_image_points_lines(image, points=points[0], line_color=(0, 0, 255))
image_utils.cv_show_image("det", image, use_rgb=False, delay=0)
print("class_set:{}".format(class_set))
if __name__ == "__main__":
image_dir = "path/to/dataset/CCPD2020/ccpd_green/train"
converter_CCPD2voc(image_dir, vis=True)4、数据集下载
CCPD2019:官方原始数据,主要是蓝牌数据,约34W;
CCPD2020:官方原始数据,主要是新能源绿牌数据,约1万:
【下载地址】
关于数据集的任何问题,均可以在评论区或后台私信留言,我看到会第一时间回复。
欢迎关注我的个人vx公众号:石小坚,获取更多数据集!
整理不易,求个关注~拜托啦!

















 544
544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









