









最近研究数据挖掘的相关知识,总是搞混一些算法之间的关联,俗话说好记性不如烂笔头,还是记下了以备不时之需。
首先明确一点KNN与Kmeans的算法的区别:
1.KNN算法是分类算法,分类算法肯定是需要有学习语料,然后通过学习语料的学习之后的模板来匹配我们的测试语料集,将测试语料集合进行按照预先学习的语料模板来分类
2Kmeans算法是聚类算法,聚类算法与分类算法最大的区别是聚类算法没有学习语料集合。
K-means算法是聚类分析中使用最广泛的算法之一。它把n个对象根据他们的属性分为k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。其聚类过程可以用下图表示:
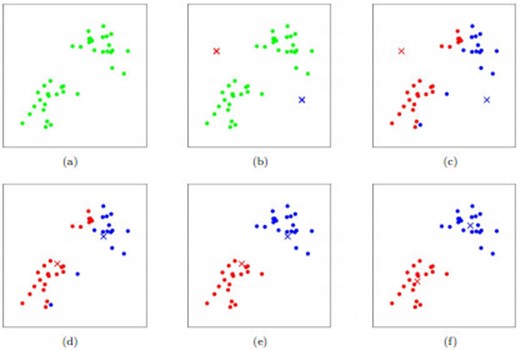
如图所示,数据样本用圆点表示,每个簇的中心点用叉叉表示。(a)刚开始时是原始数据,杂乱无章,没有label,看起来都一样,都是绿色的。(b)假设 数据集可以分为两类,令K=2,随机在坐标上选两个点,作为两个类的中心点。(c-f)演示了聚类的两种迭代。先划分,把每个数据样本划分到最近的中心点 那一簇;划分完后,更新每个簇的中心,即把该簇的所有数据点的坐标加起来去平均值。这样不断进行”划分—更新—划分—更新”,直到每个簇的中心不在移动为 止。
该算法过程比较简单,但有些东西我们还是需要关注一下,此处,我想说一下"求点中心的算法"
一般来说,求点群中心点的算法你可以很简的使用各个点的X/Y坐标的平均值。也可以用另三个求中心点的的公式:
1)Minkowski Distance 公式 —— λ 可以随意取值,可以是负数,也可以是正数,或是无穷大。

2)Euclidean Distance 公式 —— 也就是第一个公式 λ=2 的情况

3)CityBlock Distance 公式 —— 也就是第一个公式 λ=1 的情况
![]()
这三个公式的求中心点有一些不一样的地方,我们看下图(对于第一个 λ 在 0-1之间)。



(1)Minkowski Distance (2)Euclidean Distance (3)CityBlock Distance
上面这几个图的大意是他们是怎么个逼近中心的,第一个图以星形的方式,第二个图以同心圆的方式,第三个图以菱形的方式。
Kmeans算法的缺陷
- 聚类中心的个数K 需要事先给定,但在实际中这个 K 值的选定是非常难以估计的,很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适
- Kmeans需要人为地确定初始聚类中心,不同的初始聚类中心可能导致完全不同的聚类结果。(可以使用Kmeans++算法来解决)

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









