







 本文详细介绍了变分自编码器(VAE)的算法实现、直观解释和数学原理。通过具体的网络结构和训练过程,阐述了VAE在数据生成、高维数据可视化、缺失数据填补和半监督学习中的应用。此外,还探讨了VAE与自编码器的联系,以及流形学习的概念。文章最后提到了VAE在半监督学习中的潜力与其他无监督方法的比较。
本文详细介绍了变分自编码器(VAE)的算法实现、直观解释和数学原理。通过具体的网络结构和训练过程,阐述了VAE在数据生成、高维数据可视化、缺失数据填补和半监督学习中的应用。此外,还探讨了VAE与自编码器的联系,以及流形学习的概念。文章最后提到了VAE在半监督学习中的潜力与其他无监督方法的比较。
近年,随着有监督学习的低枝果实被采摘的所剩无几,无监督学习成为了研究热点。VAE(Variational Auto-Encoder,变分自编码器)[1,2] 和 GAN(Generative Adversarial Networks) 等模型,受到越来越多的关注。
笔者最近也在学习 VAE 的知识(从深度学习角度)。首先,作为工程师,我想要正确的实现 VAE 算法,以及了解 VAE 能够帮助我们解决什么实际问题;作为人工智能从业者,我同时希望在一定程度上了解背后的原理。
作为学习笔记,本文按照由简到繁的顺序,首先介绍 VAE 的具体算法实现;然后,再从直观上解释 VAE 的原理;最后,对 VAE 的数学原理进行回顾。我们会在适当的地方,对变分、自编码、无监督、生成模型等概念进行介绍。
我们会看到,同许多机器算法一样,VAE 背后的数学比较复杂,然而,工程实现上却非常简单。
这篇 Conditional Variational Autoencoders 也是 by intuition 地介绍 VAE,几张图也非常用助于理解。
1. 算法实现
这里介绍 VAE 的一个比较简单的实现,尽量与文章[1] Section 3 的实验设置保持一致。完整代码可以参见 repo。
1.1 输入:
数据集 X⊂Rn 。
做为例子,可以设想 X 为 MNIST 数据集。因此,我们有六万张 0~9 的手写体 的灰度图(训练集), 大小为
28×28 。进一步,将每个像素归一化到 [0,1] ,则 X⊂[0,1]784 。

图1. MNIST demo (图片来源)
1.2 输出:
一个输入为 m 维,输出为
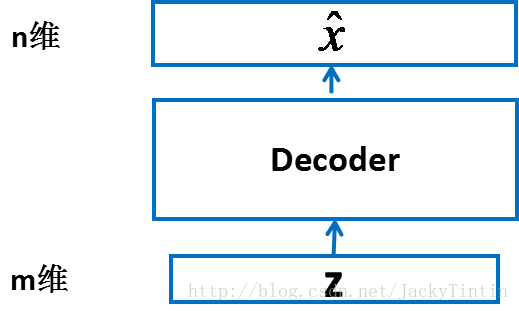
图 2. decoder
- 在输入输出维度满足要求的前提下,decoder 以为任何结构——MLP、CNN,RNN 或其他。
- 由于我们已经将输入数据规一化到 [0, 1] 区间,因此,我们令 decoder 的输出也在这个范围内。这可以通过在 decoder 的最后一层加上 sigmoid 激活实现 :
f(x)=11+e−x- 作为例子,我们取 m = 100,decoder 的为最普遍的全连接网络(MLP)。基于 Keras Functional API 的定义如下:
n, m = 784, 2
hidden_dim = 256
batch_size = 100
## Encoder
z = Input(batch_shape=(batch_size, m))
h_decoded = Dense(hidden_dim, activation='tanh')(z)
x_hat = Dense(n, activation='sigmoid')(h_decoded)1.3 训练
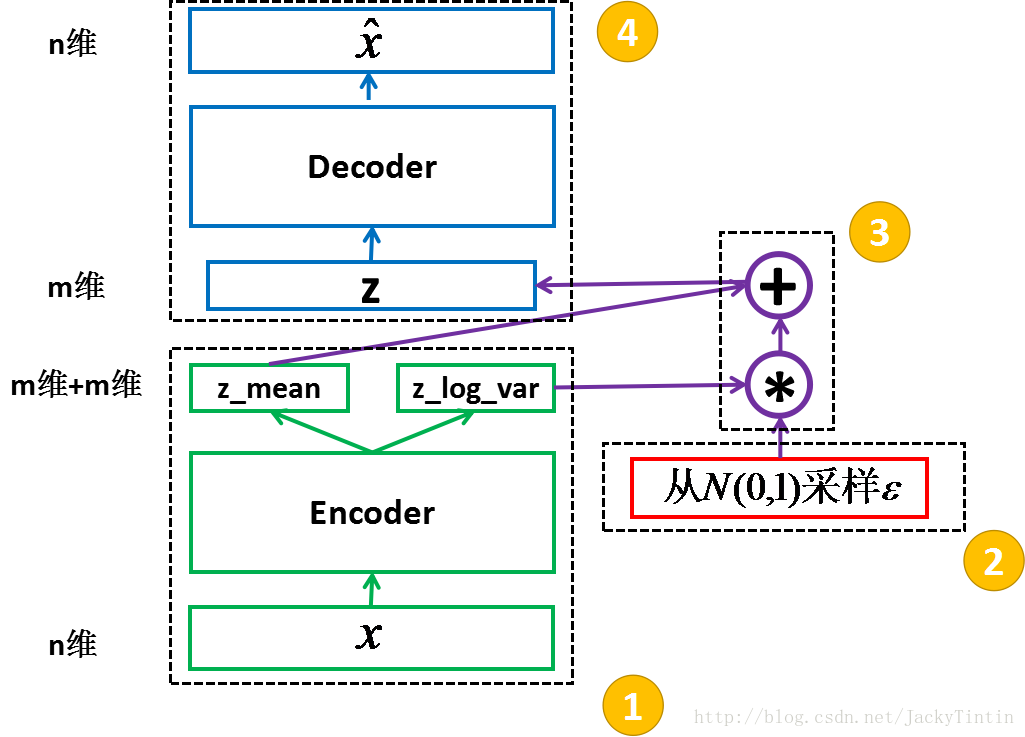
图 3. VAE 结构框架
1.3.1 encoder
为了训练 decoder,我们需要一个辅助的 encoder 网络(又称 recognition model)(如图3)。encoder 的输入为 n 维,输出为
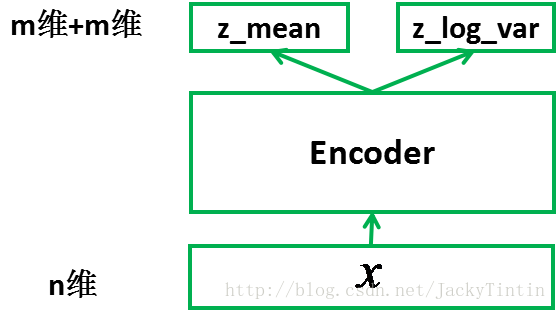
图 4. encoder
1.3.2 采样(sampling)
我们将 encoder 的输出( 2×m 个数)视作分别为 m 个高斯分布的均值(z_mean)和方差的对数(z_log_var)。
接着上面的例子,encoder 的定义如下:
## Encoder
x = Input(batch_shape=(batch_size, n))
h_encoded = Dense(hidden_dim, activation='tanh')(x)
z_mean = Dense(m)(h_encoded) # 均值
z_log_var = Dense(m)(h_encoded) # 方差对数然后,根据 encoder 输出的均值与方差,生成服从相应高斯分布的随机数:
epsilon = K.random_normal(shape=(batch_size, m),
mean=0.,std=epsilon_std) # 标准高斯分布
z = z_mean + exp(z_log_var / 2) * epsilon
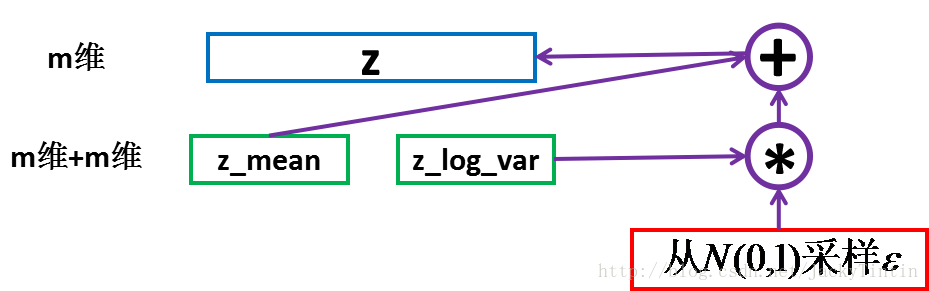
图5. 采样
这里运用了 reparemerization 的技巧。由于 z∼N(μ,σ) ,我们应该从 N(μ,σ) 采样,但这个采样操作对 μ 和 σ 是不可导的,导致常规的通过误差反传的梯度下降法(GD)不能使用。通过 reparemerization,我们首先从 N(0,1) 上采样 ϵ ,然后, z=σ⋅ϵ+μ 。这样, z∼N(μ,σ) ,而且,从 encoder 输出到 z ,只涉及线性操作,(
ϵ 对神经网络而言只是常数),因此,可以正常使用 GD 进行优化。方法正确性证明见[1] 2.3小节和[2] 第3节 (stochastic backpropagation)。

图6. Reparameterization (图片来源)
preparameterization 的代价是隐变量必须连续变量[7]。
1.3.3 优化目标
encoder 和 decoder 组合在一起,我们能够对每个 x∈X ,输出一个相同维度的 x^ 。我们目标是,令 x^ 与 x 自身尽量的接近。即
注:严格而言,按照模型的假设,我们要优化的并不是 x 与
x^ 之间的距离,而是要最大化 x 的似然。不同的损失函数,对应着不是p(x|z) 的不同概率分布假设。此处为了直观,姑且这么解释,详细讨论见下文([1] 附录C)。
由于 x∈[0,1] ,因此,我们用交叉熵(cross entropy)度量 x 与
xent 越小, x 与
我们也可以用均方误差来度量:
mse 越小,两者越接近。
训练过程中,输出即是输入,这便是 VAE 中 AE(autoencoder,自编码)的含义。
另外,我们需要对 encoder 的输出 z_mean( μ )及 z_log_var( logσ2 )加以约束。这里使用的是 KL 散度(具体公式推导见下文):
这里的KL, 其实是 KL 散度的负值,见下文。
总的优化目标(最小化)为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









