








What is a one-sided limits?
Introduction
One-sided Limits and Two-sided Limits
People are familiar with two sided limits, shown below.
But here, we are going to introduce one-sided limits and shown the correlative between them.
The expression of one-sided limits are shown below.
The different is the superscript of a, which means the direction of approaching. E.g., the formula (2) means that
f(x)
is close to
L
, as the provided
And the same as formula (3), which means that
Graph
See the graph down there.
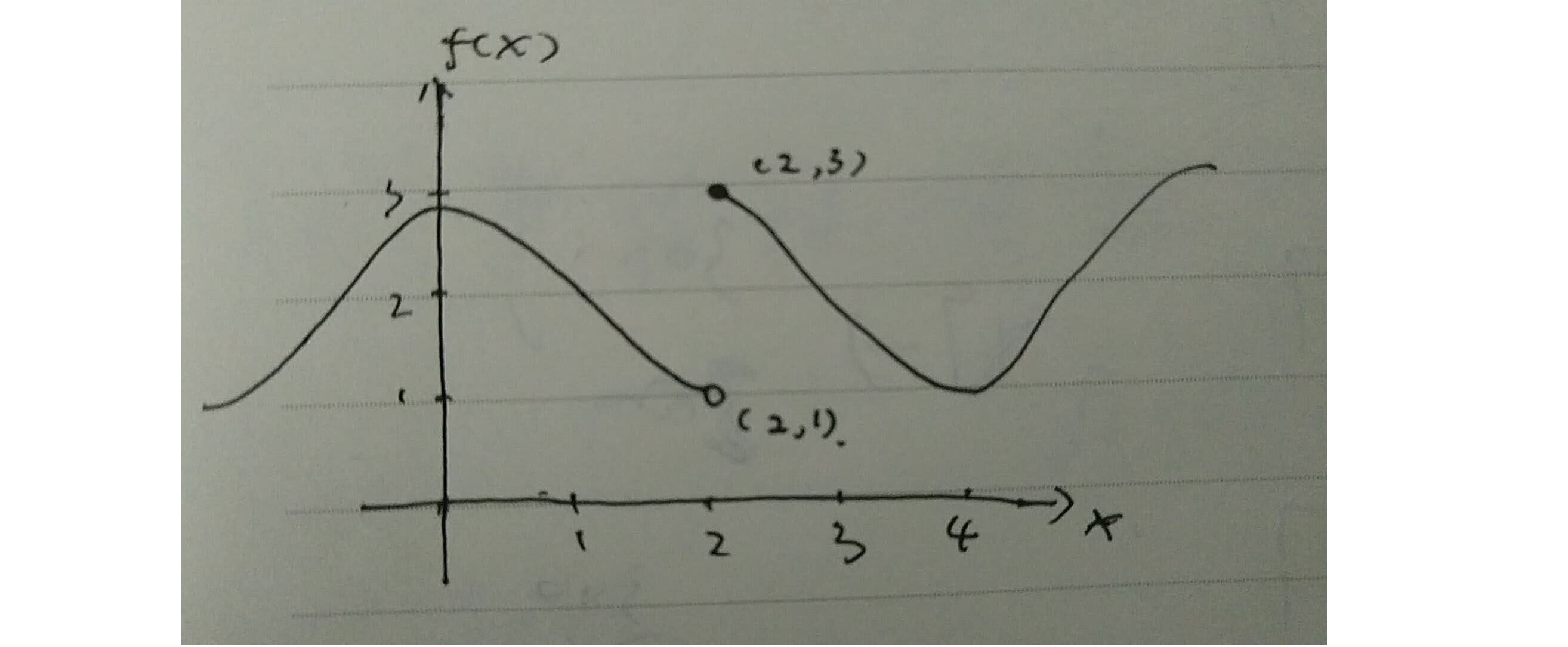
Compare graph with formula (2) and (3). You can say that
Correlation between One-sided Limits and Two-sided Limits
When one-sided limits from both sides are equal to the same value, we could simply use two-sided limits to express. Whereas, the one-sided limits is not exactly the same, we have use one-sided limits.
E.g.,
Summary
- One-sided limits is not equal to two-sided limits.
- If both sides of one-sided limits have the same value, we could make it two-sided limits.
Reference
[1] Introduction of Calculus in Coursera by Jim Fowler















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









