







倘若您正在寻觅一份关于RAG的非技术性介绍,涵盖了初学者常见问题的解答,并期望深入探讨其实际应用场景,那么您来对地方了。在此,我们为您精心准备了关于RAG的详尽细分,旨在帮助您全面了解其内涵与价值。
在本文中,我们详尽地探讨了实现RAG过程中所需关注的多样化技术要点,深入剖析了分块策略、查询增强技术、层次结构运用、多跳推理机制以及知识图概念等多个层面。此外,我们还对RAG基础设施领域内尚未解决的难题和潜在的机遇进行了讨论,并介绍了一系列构建RAG管道的基础设施解决方案,以期为读者提供更为全面的视角。
在构建RAG系统的过程中,您所面临的首要挑战和关键设计选择将聚焦于如何有效准备用于存储和信息提取的文档。这一环节不仅关乎系统的核心功能实现,更直接影响到后续信息处理的准确性和效率,因此将成为本文的核心议题和主要焦点。
在此,我们简要回顾并概述了RAG系统的整体架构,以便读者能够更好地理解本文所讨论的各个技术要点和解决方案在系统中的具体应用和作用。通过这一综述,我们希望为读者提供一个更加清晰、深入的RAG系统构建与实施指南。
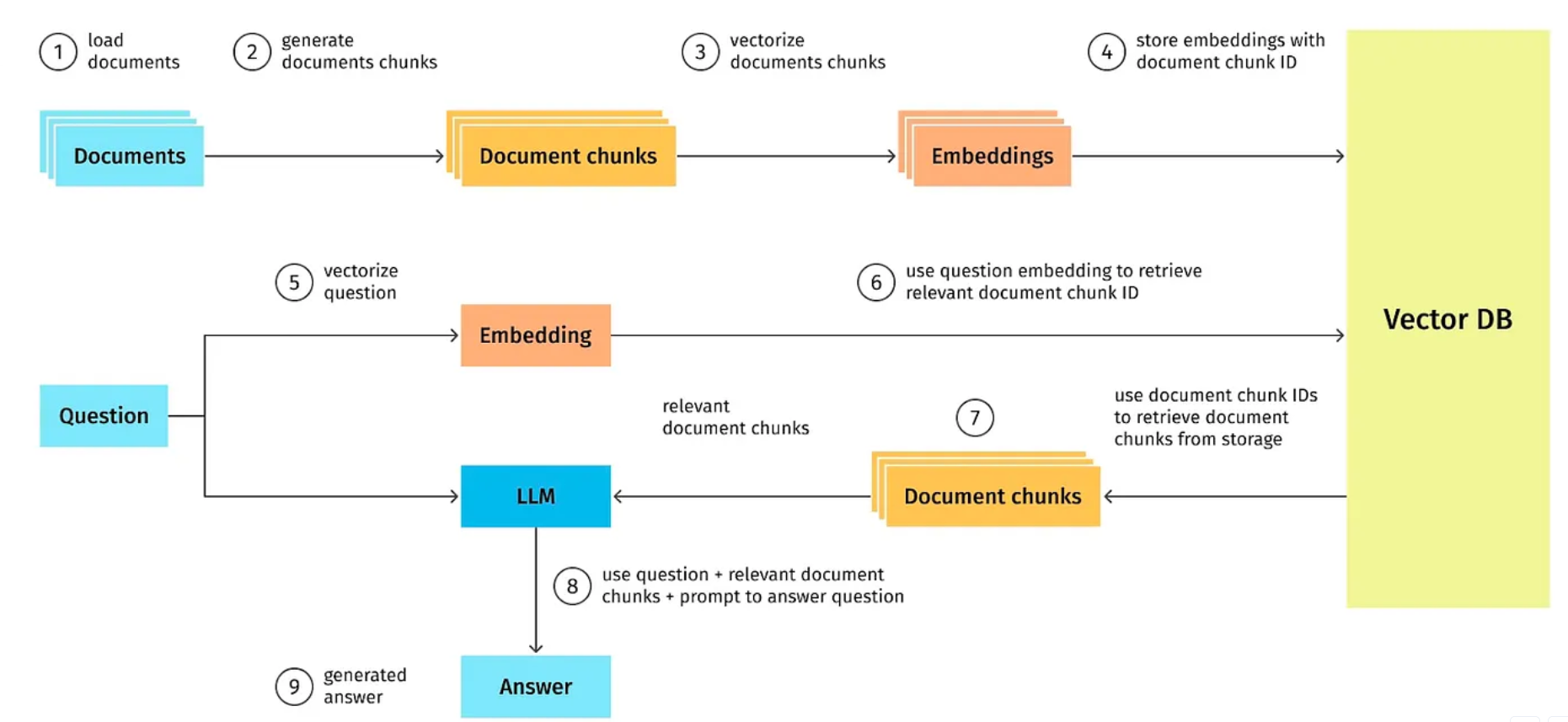
来源:https://blog.griddynamics.com/retrieval-augmented- Generation-llm/
相关性与相似性
在讨论 RAG 中的有效信息检索时,深入理解和把握“相关性”与“相似性”之间的微妙差异显得尤为关键。相似性主要侧重于文本层面的单词匹配程度,它关注的是字面上的接近性;而相关性则侧重于思想层面的连通性,强调信息之间的逻辑联系和深层含义。
尽管我们可以利用向量数据库查询来识别那些在语义上较为接近的内容,但要想精确识别和高效检索真正具有相关性的内容,则往往需要借助更为复杂和精细的工具和技术。
因此,在接下来深入探讨各种 RAG 技术的过程中,我们必须时刻铭记这一重要概念。如果您对此领域尚不熟悉,我强烈建议您查阅 Llamaindex 关于构建生产级RAG应用程序的指南。这份资料不仅为我们提供了宝贵的见解,还为我们探讨各种 RAG 系统开发技术提供了极好的入门指引。
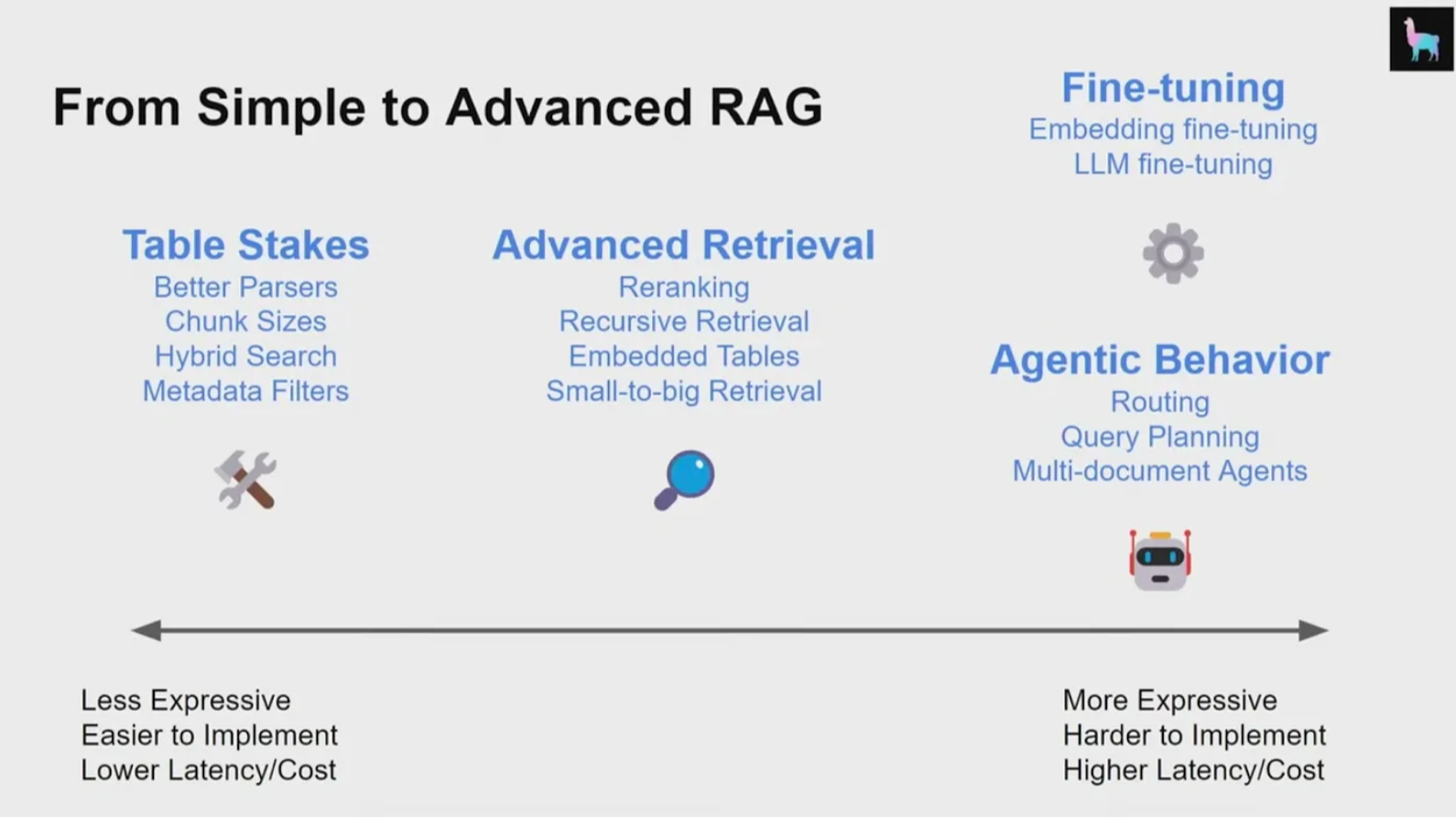
RAG的技术实现
分块策略
在自然语言处理的广阔领域中,“分块”技术扮演着至关重要的角色,它旨在将冗长的文本巧妙地切割成若干小巧、精炼且富含意义的“块”。正是得益于这种精细化的处理方式,RAG系统得以在浩如烟海的大型文档中迅速而精准地锁定那些承载着关键信息的较小文本块,从而为用户呈现出相关的上下文内容。
然而,如何确保我们选中的文本块恰如其分,既能反映原文的核心意义,又不至于过于琐碎或冗余?这就涉及到分块策略的制定与实施了。事实上,分块策略的有效性在很大程度上取决于这些文本块的质量和结构——它们必须既能够凸显文本的主题脉络,又能够保留足够的细节以便后续的分析和解读。
为了确定最佳的块大小,我们需要仔细权衡速度与精度之间的关系。较大的文本块虽然能够涵盖更多的上下文信息,但这也意味着它们会引入更多的噪音,同时处理起来也会消耗更多的时间和计算资源。相反,较小的文本块虽然噪音较少,但可能无法全面覆盖到原文中的关键信息,从而导致信息的遗漏或误解。
为了平衡这两个方面的约束,我们可以采用一种折衷的方法——重叠块策略。通过将相邻的文本块进行部分重叠,我们可以确保查询在跨越多个向量时能够检索到足够的相关数据,从而生成更加准确和全面的上下文响应。这样既可以提高系统的检索效率,又能够保留足够的上下文信息以满足用户的需求。
不过,值得注意的是,这种分块策略也存在一定的局限性。它假设用户需要检索的所有信息都能够在单个文档中找到,然而在实际应用中,这种假设并不总是成立。因此,在运用分块策略时,我们需要根据具体的应用场景和需求进行灵活调整和优化,以确保系统能够为用户提供更加准确和高效的服务。
文档层次结构
文档层次结构是组织数据以改进信息检索的有效方法。 您可以将文档层次结构视为 RAG 系统的目录。 它以结构化方式组织块,使 RAG 系统能够有效地检索和处理相关的相关数据。 文档层次结构帮助 LLM 决定哪些块包含要提取的最相关数据,从而在 RAG 的有效性中发挥着至关重要的作用。
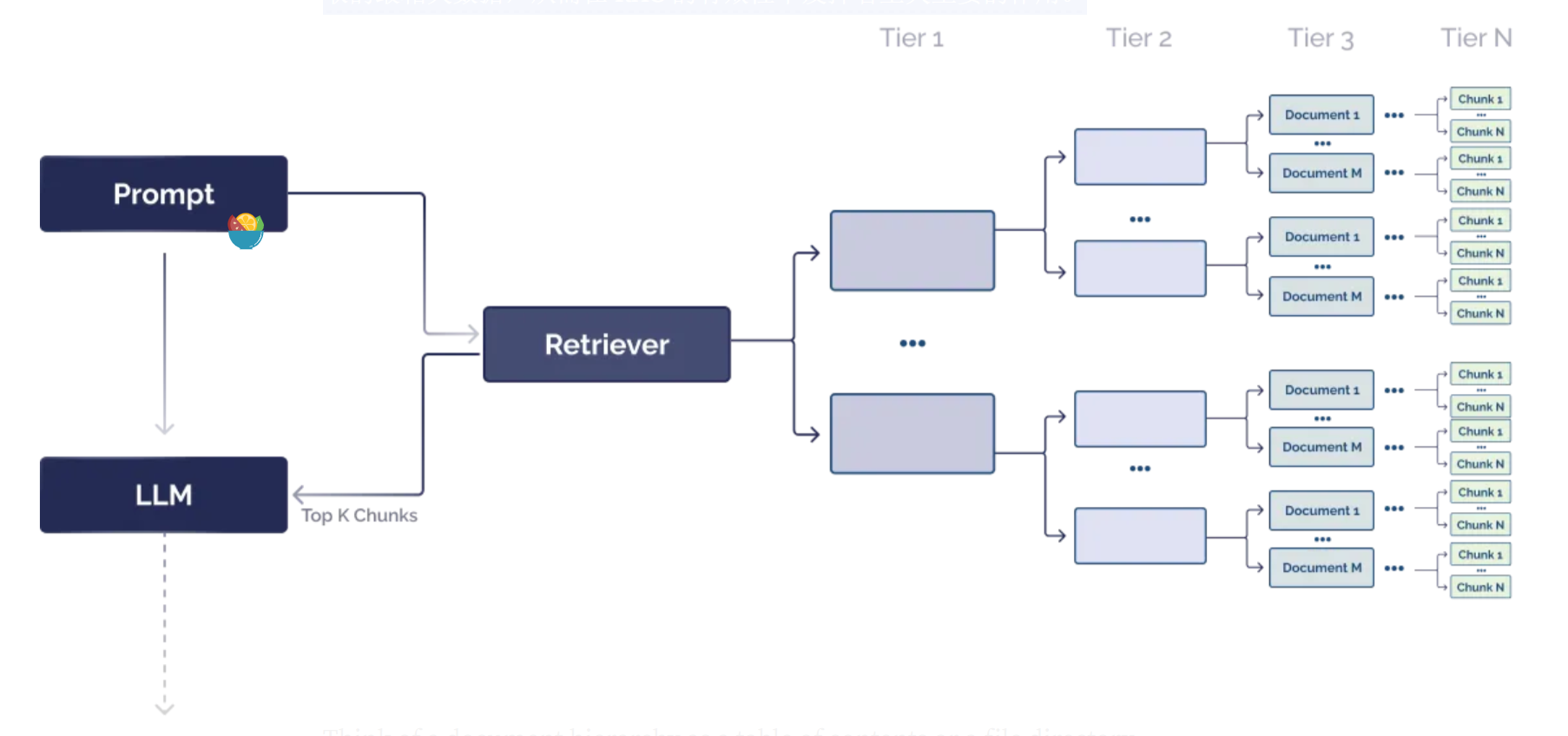
文档层次结构精妙地将各个块与节点紧密关联,并以明晰的父子关系组织起这些节点。每个节点都承载着对内含信息的精炼总结,从而使得RAG系统能够更高效地遍历数据,并精准地识别出需要提取的关键块。
那么,即便LLM能够解析文档中的每个单词,为何文档层次结构依然不可或缺呢?实际上,我们可以将文档层次结构视作一本详尽的目录或文件索引。虽然LLM确实能够从庞大的向量数据库中筛选出相关的文本块,但借助文档层次结构作为预处理环节,我们能够更加精准地定位到最符合需求的文本块,进而大幅提升检索的速度与准确性。
这一策略不仅优化了检索效率,还显著增强了检索的可靠性、速度及可重复性,同时有助于减少因块提取问题导致的误导性信息。值得注意的是,构建文档层次结构往往需要特定领域或问题的专业知识作为支撑,以确保所提炼的摘要与当前任务紧密相关。
以人力资源领域为例,假设某公司拥有多个分布在不同国家的办事处,每个办事处都遵循相似的模板制定各自的人力资源政策。尽管这些政策文件的整体框架相近,但涉及公共假期、医疗保健等具体内容的部分却因国家而异。在这种情况下,即便向量数据库中的“公共假期”段落块在格式上高度相似,但如果没有文档层次结构的辅助,矢量查询很可能返回大量重复且无关紧要的数据,从而导致信息误导。
而借助文档层次结构,RAG系统便能更有针对性地搜索与特定办事处(如芝加哥办事处)相关的文档,从而更准确地回答关于该办事处公共假期的问题。
由此可见,构建RAG系统的核心工作在于深入理解非结构化数据,并为其添加丰富的上下文信息,使LLM能够进行更加精准和确定性的信息提取。这一过程与指导新入职的实习生如何通过数据集进行推理颇为相似。尽管LLM能够理解文档中的每个单词及其与问题的相关性,但它仍需借助文档层次结构等额外信息来拼凑出完整的上下文答案,确保信息提取的准确性和有效性。
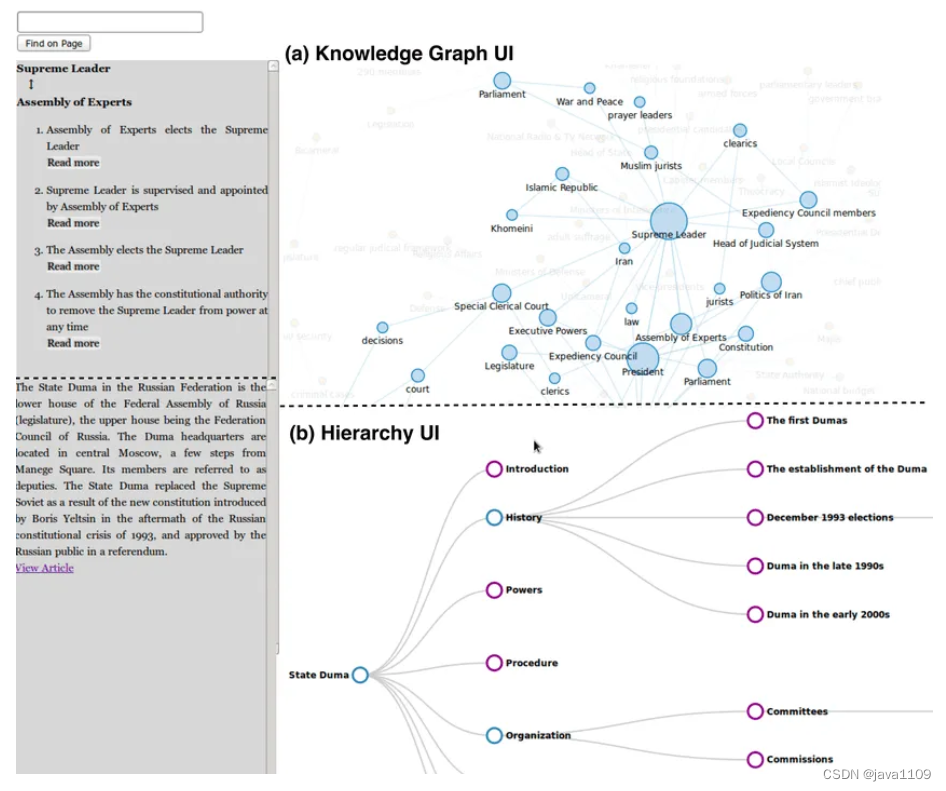
知识图谱
知识图谱作为文档层次结构的一种卓越数据框架,不仅能够有效地强化数据的一致性,更展现了概念和实体间关系的精确映射。相较于向量数据库中仅凭相似性进行的模糊搜索,知识图谱的运用能够确保检索过程和结果的一致性与准确性,从而显著减少信息检索中的误差与幻觉现象。
采用知识图谱来构建和映射文档层次结构的优势在于,它能将复杂的信息检索工作流程清晰地转化为大语言模型能够理解和执行的指令序列。这意味着,当面对某个问题X时,系统能够明确地知道需要从文档A中提取哪些关键信息,并如何将这些信息与文档B中的内容进行比对和分析。
值得一提的是,知识图谱采用自然语言来描述和映射关系,使得即便是非技术背景的用户也能轻松构建、修改和优化规则与关系,从而实现对企业RAG系统的有效控制。举例来说,用户可以设定如下规则:“在回答关于休假政策的问题时,系统应首先查阅指定办公室的人力资源政策文件,并重点查看该文件中的假期部分。”这种自然且直观的方式大大增强了系统的易用性和灵活性,使得知识图谱成为企业信息管理和检索领域的得力助手。
查询增强
查询增强有效解决了措辞不当的问题,这在我们此次探讨的RAG中是一个屡见不鲜的挑战。我们的目标在于,针对那些缺乏具体细节的问题,提供精准且恰当的上下文信息,以最大程度地提升查询的相关性。
措辞错误的问题,往往源于语言的复杂多变。比如,同一个词汇在不同的语境下可能指代截然不同的两个概念。正如Agustinus(CarSales.AU的人工智能主管)所言,这一问题在很大程度上与特定领域密切相关。以“炸鸡”为例,它与“鸡汤”还是“炒饭”更为接近?答案实则取决于具体的上下文。若着眼于食材成分,那么“炸鸡”与“鸡汤”更为相似;但从烹饪方式的角度考虑,它则更接近于“炒饭”。这种差异正是领域特性所带来的。
那么,当需要将大型语言模型与公司或特定领域的术语相结合时,又该如何操作呢?以公司首字母缩略词为例,如ARP代表会计调节流程。再举一个来自我们客户的实际案例,这是一家旅行社。在旅游业的语境下,客户需要准确区分“靠近海滩”和“海滨”这两个短语。对于大多数大型语言模型而言,这样的术语区分颇具挑战。然而,在旅行领域的实际应用中,海滨房屋与靠近海滩的房屋却有着截然不同的含义。为此,我们采取了预处理查询的方式,通过添加公司特定的上下文信息,将“靠近海滩”的属性映射到特定的属性部分,同时将“海滨”属性映射到另一个属性,从而确保查询结果更加符合客户的实际需求。
查询计划
查询规划代表生成正确上下文所需的子问题的过程,并生成答案,这些答案组合后可以完全回答原始问题。 添加相关上下文的过程原则上类似于查询增强。
让我们以一个问题为例:“哪个城市的人口最多?”。 为了回答这个问题,RAG 系统必须先生成以下子问题的答案,如下图所示,然后再按人口对城市进行排名:
“多伦多有多少人口?”
“芝加哥有多少人口?”
“休斯顿有多少人口?”
“波士顿有多少人口?”
“亚特兰大有多少人口?”
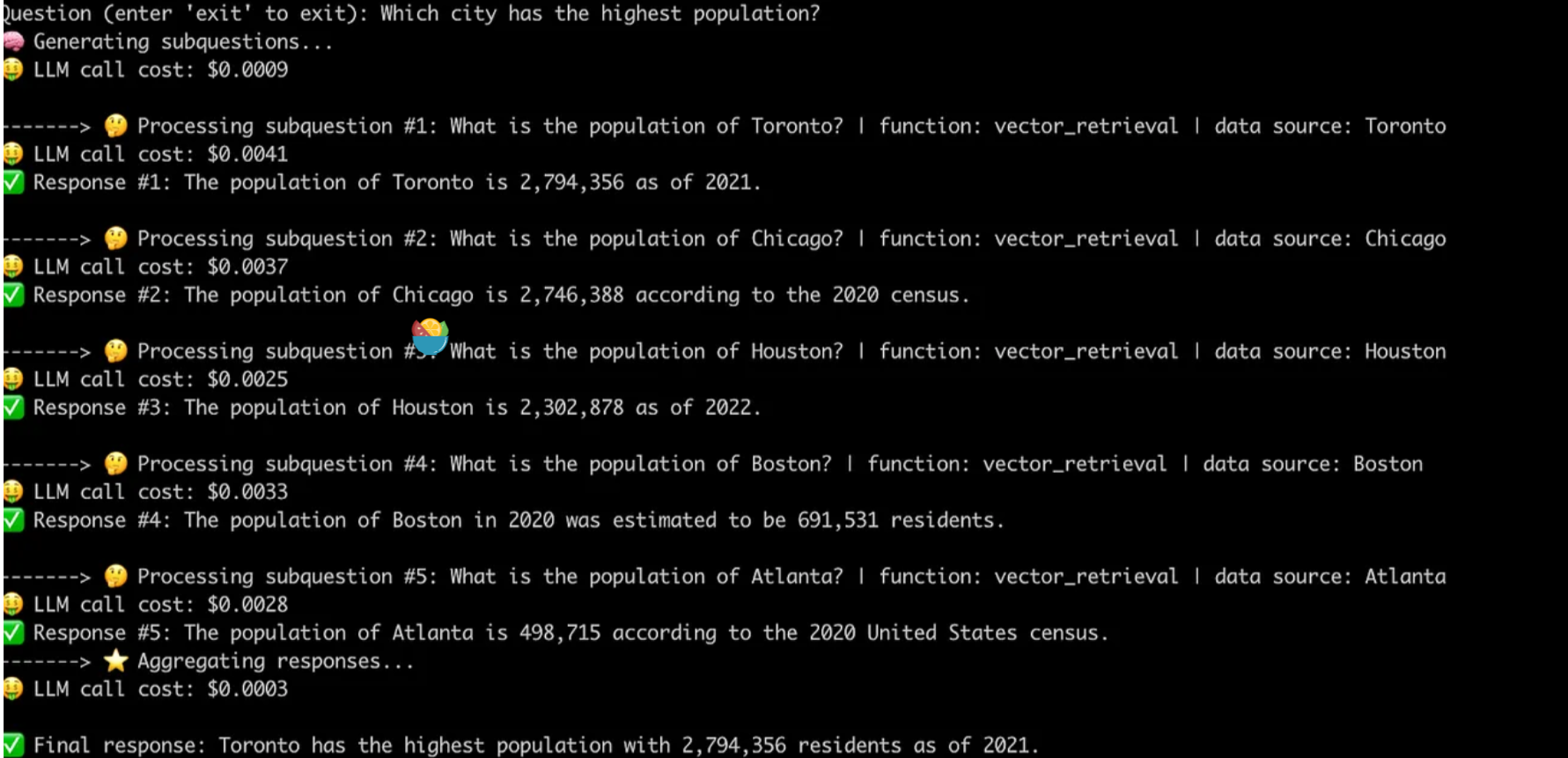
LlamaIndex 采用这一策略,精确识别并确定需要解答的相关子问题,从而全面回应顶级问题。不仅如此,LlamaIndex 还广泛运用了其他多样化的方法,这些方法在很大程度上都是基于上述核心概念的灵活衍生与创新,旨在提升问题解答的精准度和深度。
以下是 LlamaIndex 的查询规划代理用来识别子问题的代码片段。
‘dependencies’: {‘title’: ‘Dependencies’,
‘description’: ‘List of sub-questions that need to be answered in order to answer the question given by `query_str`.Should be blank if there are no sub-questions to be specified, in which case `tool_name` is specified.’,众所周知,LLM 在缺乏协助的情况下,进行逻辑推理往往显得颇为吃力。因此,在生成子问题的过程中,确保准确性无疑成为了主要挑战。
“”为了验证此行为,我们使用 LlamaIndex 子问题查询引擎实现了该示例。与我们的观察一致,该系统经常产生错误的子问题,并且对子问题使用错误的检索功能”—— Pramod Chunduri 关于建设先进的 RAG 管道(23年10月30日 )
明确确切地说,这并非对LlamaIndex本身的体现,而是凸显了单纯依赖LLM(大型语言模型)进行推理的局限与挑战。为了更有效地回答问题,我们或许需要引入外部推理结构和规则,借助这些结构和规则,通过生成或存储的子问题来强制实施某些原则和个人化的方法。特别是当我们考虑到不同行业、公司乃至个人的偏好可能与LLM 的偏好存在显著差异时,这一挑战便显得尤为突出。因此,我们需要更加灵活地结合多种资源和手段,以应对这种多元化的推理需求。
让我们考虑一下上述城市人口问题的外部推理规则。该规则以自然语言编写,然后由 LLM 代理在回答问题时阅读:
- 在考虑人口最多的城市时,询问他们想要查看哪个大陆,然后检索该大陆的所有城市以比较人口。
对这种方法的批评是,它代表了对推理过程的手动干预,并且人们不可能想象每个潜在问题的每个子问题。这是真实的。考虑到 LLM 的现状,人们应该只在LLM 失败时寻求用外部推理规则进行干预,而不是寻求重新创建每一个可能的子问题。
将所有内容组合成一个能够进行多跳推理和查询修改的 RAG 系统
在上一篇文章中,我们讨论了复杂 RAG 中多跳检索的作用,以及工作流程中可能出现复杂 RAG 的各种场景。以下是构建多跳检索时出现的问题。
- 数据集成和质量:互连数据源的高质量、相关性和最新性至关重要。不良或有偏见的数据可能导致不准确的多步骤结论。
- 上下文理解和链接:系统不仅必须理解每个查询和子查询,而且还必须了解它们如何连接以形成一个连贯的整体。这涉及先进的自然语言理解,以辨别不同信息之间的微妙联系。
- 用户意图识别:识别用户的潜在意图及其随每一跳的演变是关键。系统应根据查询的演变性质调整其检索策略。这与查询增强有很大重叠。
让我们用医学领域的一个例子来解构。在这篇文章中,Wisecube 提出了以下问题:“阿尔茨海默病治疗的最新进展是什么?”利用上述策略的 RAG 系统将采用以下步骤:
查询计划:
- “目前阿尔茨海默病的治疗方法和副作用是什么?”
- “这些治疗方法的最新研究是什么?”
查询增强:
- “这些治疗方法的最新研究是什么?”通过访问知识图谱,该代理可以一致地检索有关阿尔茨海默病治疗的结构化数据,例如“胆碱酯酶抑制剂”和“美金刚”。
- 然后,RAG 系统会将问题细化为“胆碱酯酶抑制剂和美金刚在阿尔茨海默病治疗中的最新研究是什么?”
文档层次结构和LLM 向量数据库检索:
- 使用文档层次结构,确定哪些文档和块与“胆碱酯酶抑制剂”和“美金刚”最相关,并返回相关答案。
- 您还可以让 LLM 将这些块包含到潜在知识的知识图谱中,以便他们可以随着时间的推移逐渐添加更多上下文数据。然后,LLM 可以再次重复向量数据库检索过程,使用增强的潜在知识库(现在由知识图谱构建)和新增强的查询,从向量数据库中检索更多相关信息,以获得满意的答案。
- Greywing (YCW21) 的首席技术官Hrishi 阐述了使用 LLM“走到相关文档块”的类似原理的示例。
增强响应:
- 作为后处理步骤,您还可以选择使用医疗保健行业特定的知识图谱来增强后处理输出。例如,您可以包含特定于美金刚治疗的默认健康警告或与两种治疗或副作用相关的任何其他信息。
与向量数据库相比,使用知识图谱进行查询增强的优点是,知识图谱可以对关系已知的某些关键主题和概念强制执行一致的检索。在增强响应步骤中,RAG 系统可以自动包括每当答案包括特定药物或疾病或概念时必须包括的某些警告或相关概念。
RAG 中未解决的问题代表着未来的机遇
短期内,RAG 有很多提高成本效率和准确性的机会。这为开发更复杂、更精确、资源效率更高的数据检索流程开辟了途径。
从长远来看,有一个重要的机会来设计以可扩展的方式构建和存储语义推理的方法。这涉及探索知识表示的新领域,例如复杂数据关系的高级编码技术和创新的存储解决方案。这些发展将使 RAG 系统能够有效管理和利用日益复杂的数据。
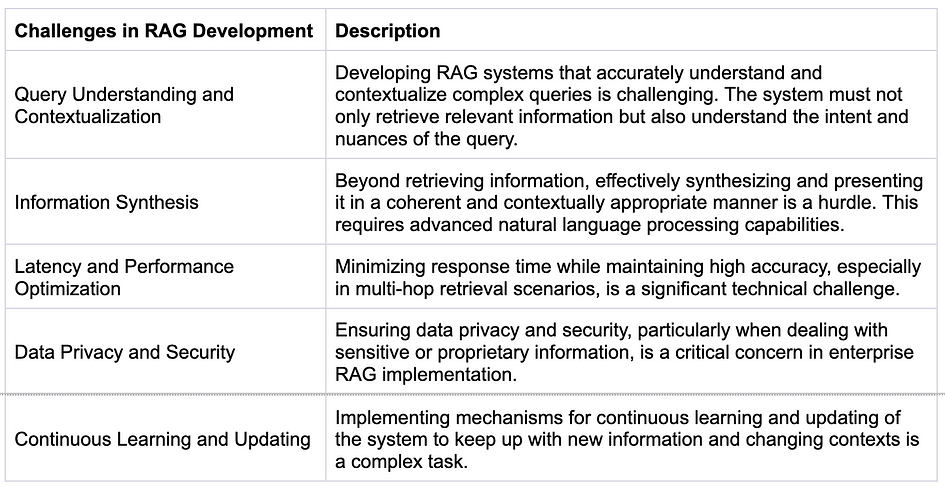
RAG 开发的挑战
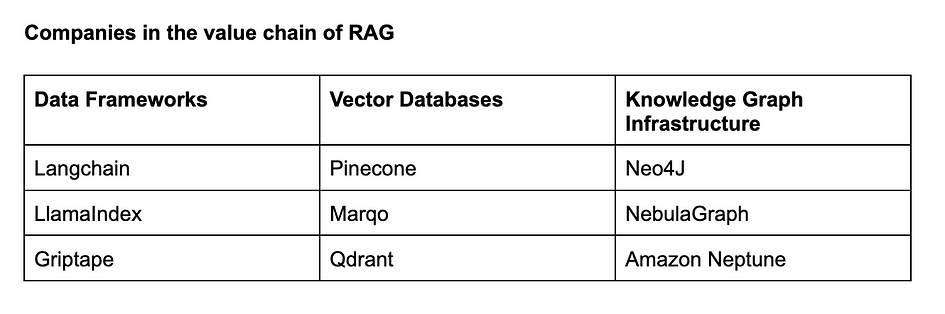

















 4196
4196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









