







 本文围绕Informer模型展开,先指出Transformer和LSTM在长序列时间序列预测中的问题,接着介绍Informer模型的特点与机制原理,分析其性能。还讲解了数据集、项目结构和参数,进行模型训练与结果预测,并说明如何用自己的数据集训练,最后推荐相关时间序列专栏。
本文围绕Informer模型展开,先指出Transformer和LSTM在长序列时间序列预测中的问题,接着介绍Informer模型的特点与机制原理,分析其性能。还讲解了数据集、项目结构和参数,进行模型训练与结果预测,并说明如何用自己的数据集训练,最后推荐相关时间序列专栏。

论文地址-> Informer论文地址PDF点击即可阅读
代码地址-> 论文官方代码地址点击即可跳转下载GIthub链接
个人魔改版本地址-> 魔改版下载地址

一、本文介绍
在之前的文章中我们已经讲过Informer模型了,但是呢官方的预测功能开发的很简陋只能设定固定长度去预测未来固定范围的值,当我们想要发表论文的时候往往这个预测功能是并不能满足的,所以我在官方代码的基础上增添了一个滚动长期预测的功能,这个功能就是指我们可以第一次预测未来24个时间段的值然后我们像模型中填补 24个值再次去预测未来24个时间段的值(填补功能我设置成自动的了无需大家手动填补),这个功能可以说是很实用的,这样我们可以准确的评估固定时间段的值,当我们实际使用时可以设置自动爬取数据从而产生实际效用。本文修改内容完全为本人个人开发,创作不易所以如果能够帮助到大家希望大家给我的文章点点赞,同时可以关注本专栏(免费阅读),本专栏持续复现各种的顶会内容,无论你想发顶会还是其它水平的论文都能够对你有所帮助。
Informer讲解回顾: 时间序列预测模型实战案例(八)(Informer)个人数据集、详细参数、代码实战讲解
连续滚动预测结果评估:

同时我将滚动预测结果生成了csv文件方便大家对比和评估,以下是我生成的csv文件可以说是非常的直观。
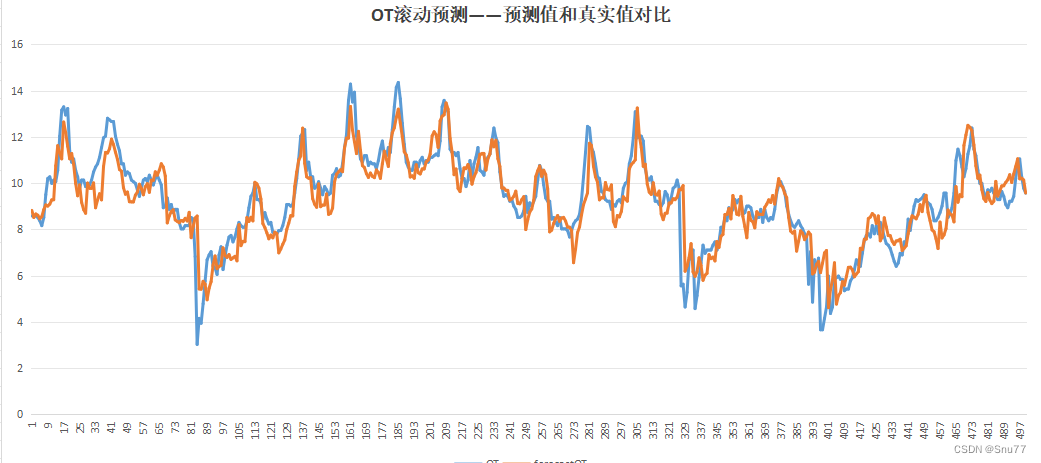
我们可以利用其进行画图从而评估结果->
目录
二、Informer论文笔记
2.1、论文首先提出了Transformer模型的问题
时间序列预测在许多领域都是关键要素,在这些场景中,我们可以利用大量的时间序列历史数据来进行长期预测,即长序列时间序列预测(LSTF)。然而,现有方法大多设计用于短期问题,如预测48点或更少的数据。随着序列长度的增加,模型的预测能力受到挑战。例如,当预测长度超过48点时,LSTM网络的预测效果开始变得不满意,推理速度急剧下降。LSTF的主要挑战是提升预测能力,以满足日益增长的长序列需求,这需要(a)超常的长距离对齐能力和(b)在长序列输入输出上的高效操作。最近,Transformer模型在捕捉长距离依赖性方面表现优于RNN模型。然而,自注意力机制由于其二次方的计算和内存消耗,违反了(b)的要求。一些大型Transformer模型在NLP任务上取得了令人印象深刻的结果,但训练和部署成本高昂。因此,本文试图回答这个问题:我们是否可以改进Transformer模型,使其在计算、内存和架构上更高效,同时保持更高的预测能力?
2.2、LSTM技术的缺陷

上图展示了一个真实数据集上的预测结果,其中LSTM网络从短期(12个点,0.5天)预测电力变压器站的小时温度到长期(480个点,20天)。当预测长度大于48个点时(图1b中的实心星号),整体性能差距显著,均方误差升高,推理速度急剧下降,LSTM模型开始失效。
总结:这里说明了传统的时间序列预测对于长期预测效果不是很好大家如果想看LSTM的预测效果可以看我的往期博客里面有各种类型的LSTM讲解
2.3、Informer模型的提出
Informer是一种用于长序列时间序列预测的Transformer模型,但是它与传统的Transformer模型又有些不同点,与传统的Transformer模型相比,Informer具有以下几个独特的特点:
1. ProbSparse自注意力机制:Informer引入了ProbSparse自注意力机制,该机制在时间复杂度和内存使用方面达到了O(Llog L)的水平,能够有效地捕捉序列之间的长期依赖关系。
2. 自注意力蒸馏:通过减少级联层的输入,自注意力蒸馏技术可以有效处理极长的输入序列,提高了模型处理长序列的能力。
3. 生成式解码器:Informer采用生成式解码器,可以一次性预测整个长时间序列,而不是逐步进行预测。这种方式大大提高了长序列预测的推理速度。
2.4、图解Informer的机制原理

上图为Informer模型概述:左侧:编码器接收大规模的长序列输入(绿色序列)。我们使用提出的ProbSparse自注意力替代传统的自注意力。蓝色梯形表示自注意力蒸馏操作,用于提取主导的注意力,大幅减小网络大小。层堆叠的副本增加了模型的稳健性。右侧:解码器接收长序列输入,将目标元素填充为零,测量特征图的加权注意力组合,并以生成式风格即时预测输出元素(橙色序列)
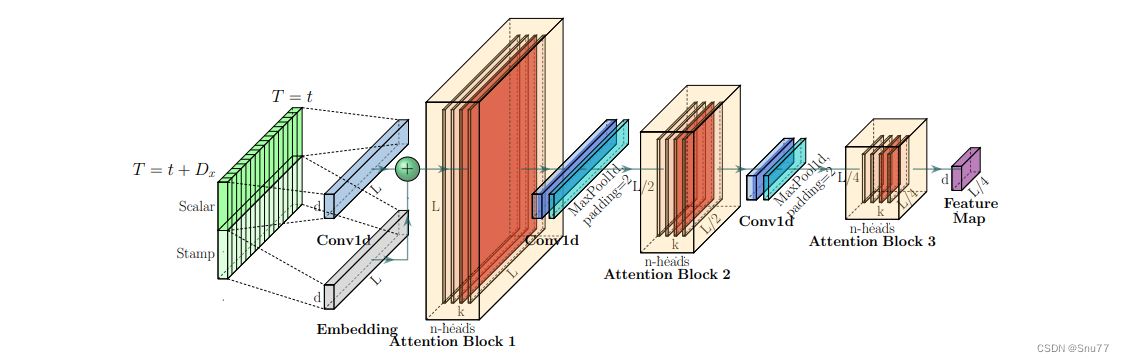
上图是Informer模型编码器结构的视觉表示,下面是对其内容的解释:
编码器堆栈:图像中的水平堆栈代表Informer编码器结构中的一个编码器副本。每个堆栈都是一个独立单元,处理部分或全部输入序列。
主堆栈:图中显示的主堆栈处理整个输入序列。主堆栈之后,第二个堆栈处理输入序列的一半,以此类推,每个后续的堆栈都处理上一个堆栈输入的一半。
点积矩阵:堆栈内的红色层是点积矩阵,它们是自注意力机制的一部分。通过在每一层应用自注意力蒸馏,这些矩阵的大小逐层递减,可能降低了计算复杂度,并集中于序列中最相关的信息。
输出的拼接:通过自注意力机制处理后,所有堆栈的特征图被拼接起来,形成编码器的最终输出。然后,模型的后续部分(如解码器)通常使用这个输出,基于输入序列中学习到的特征和关系生成预测。
这张图片可能用于说明Informer模型如何通过注意力蒸馏和跨多个处理堆栈的输入序列的智能处理,有效地处理长序列并减少计算负载。
2.5、结果分析
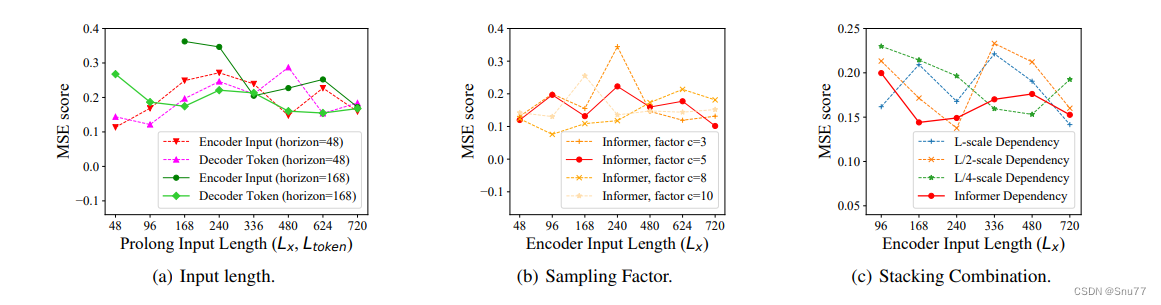
上面图片包含三个图表,分别标记为(a)、(b)和(c),每个图表都展示了Informer模型性能的不同方面与均方误差(MSE)得分之间的关系:
(a) 输入长度:此图表比较了编码器不同输入长度和解码器token长度的MSE得分。它显示了两个预测范围,48和168,指示模型性能随输入序列长度增加的变化。
(b) 采样因子:此图表展示了不同采样因子(c=3、c=5、c=8、c=10)对Informer MSE得分的影响。采样因子在Informer模型的上下文中可能与ProbSparse自注意力机制有关,影响注意力机制如何采样输入序列。
(c) 堆叠组合:这个图表说明了当应用不同的依赖度量尺度(L尺度、L/2尺度、L/4尺度)与Informer自身的依赖方法相比,不同编码器输入长度的MSE得分。这些不同的尺度可能指的是Informer模型处理输入序列的方式,可能表示模型内部的一种层次化处理或注意力机制。
这些图表有助于理解不同参数和配置如何影响Informer模型的性能,特别是在预测准确性方面,以MSE测量。每个图表都提供了洞察如何优化模型以在各种时间序列数据长度上获得更好的准确性。
总结:Informer模型,成功提高了在LSTF问题中的预测能力,验证了类似Transformer的模型在捕捉长序列时间序列输出和输入之间的个体长期依赖关系方面的潜在价值。
- 提出了ProbSparse自注意力机制,以高效地替代传统的自注意力机制,
- 提出了自注意力蒸馏操作,可优化J个堆叠层中主导的注意力得分,并将总空间复杂度大幅降低。
- 提出了生成式风格的解码器,只需要一步前向传播即可获得长序列输出,同时避免在推理阶段累积误差的传播。
三、数据集介绍
我们本文用到的数据集是官方的ETTh1.csv ,该数据集是一个用于时间序列预测的电力负荷数据集,它是 ETTh 数据集系列中的一个。ETTh 数据集系列通常用于测试和评估时间序列预测模型。以下是 ETTh1.csv 数据集的一些内容:
数据内容:该数据集通常包含有关电力系统的多种变量,如电力负荷、价格、天气情况等。这些变量可以用于预测未来的电力需求或价格。
时间范围和分辨率:数据通常按小时或天记录,涵盖了数月或数年的时间跨度。具体的时间范围和分辨率可能会根据数据集的版本而异。
以下是该数据集的部分截图->

四、项目结构和详细参数讲解
4.1、项目结构
项目结构如下图所示,其中main_informer.py文件为程序入口。

4.2、模型参数讲解以及Bug修复
main_informer.py的参数讲解如下->
4.2.1、参数讲解
| 参数名称 | 参数类型 | 参数讲解 | |
|---|---|---|---|
| 0 | model | str | 这是一个用于实验的参数设置,其中包含了三个选项: informer, informerstack, informerlight。根据实验需求,可以选择其中之一来进行实验,默认是使用informer模型。 |
| 1 | data | str | 数据,这个并不是你理解的你的数据集文件,而是你想要用官方定义的方法还是你自己的数据集进行定义数据加载器,如果是自己的数据集就输入custom |
| 2 | root_path | str | 这个才是你文件的路径,不要到具体的文件,到目录级别即可。 |
| 3 | data_path | str | 这个填写你文件的名称。 |
| 4 | is_rolling_predict | bool | 是否进行滚动预测的选项如果设置为False则是普通预测,本文改进 |
| 5 | rolling_data_path | str | 如果你要进行滚动预测则需要一个额外的文件,可以从你的数据集末尾中进行裁取。本文改进 |
| 6 | features | str | 这个是特征有三个选项M,MS,S。分别是多元预测多元,多元预测单元,单元预测单元。 |
| 7 | target | str | 这个是你数据集中你想要预测那一列数据,假设我预测的是油温OT列就输入OT即可。 |
| 8 | freq | str | 时间的间隔,你数据集每一条数据之间的时间间隔。 |
| 9 | checkpoints | str | 训练出来的模型保存路径 |
| 10 | seq_len | int | 用过去的多少条数据来预测未来的数据 |
| 11 | label_len | int | 可以裂解为更高的权重占比的部分要小于seq_len |
| 12 | pred_len | int | 预测未来多少个时间点的数据 |
| 13 | enc_in | int | 你数据有多少列,要减去时间那一列,这里我是输入8列数据但是有一列是时间所以就填写7 |
| 14 | dec_in | int | 同上 |
| 15 | c_out | int | 这里有一些不同如果你的features填写的是M那么和上面就一样,如果填写的MS那么这里要输入1因为你的输出只有一列数据。 |
| 16 | d_model | int | 用于设置模型的维度,默认值为512。可以根据需要调整该参数的数值来改变模型的维度 |
| 17 | n_heads | int | 用于设置模型中的注意力头数。默认值为8,表示模型会使用8个注意力头,我建议和的输入数据的总体保持一致,列如我输入的是8列数据不用刨去时间的那一列就输入8即可。 |
| 18 | e_layers | int | 用于设置编码器的层数 |
| 19 | d_layers | int | 用于设置解码器的层数 |
| 20 | s_layers | str | 用于设置堆叠编码器的层数 |
| 21 | d_ff | int | 模型中全连接网络(FCN)的维度,默认值为2048 |
| 22 | factor | int | ProbSparse自注意力中的因子,默认值为5 |
| 23 | padding | int | 填充类型,默认值为0,这个应该大家都理解,如果不够数据就填写0. |
| 24 | distil | bool | 是否在编码器中使用蒸馏操作。使用--distil参数表示不使用蒸馏操作,默认为True也是我们的论文中比较重要的一个改进。 |
| 25 | dropout | float | 这个应该都理解不说了,丢弃的概率,防止过拟合的。 |
| 26 | attn | str | 编码器中使用的注意力类型,默认为"prob"我们论文的主要改进点,提出的注意力机制。 |
| 27 | embed | str | 时间特征的编码方式,默认为"timeF" |
| 28 | activation | str | 激活函数 |
| 29 | output_attention | bool | 是否在编码器中输出注意力,默认为False |
| 30 | do_predict | bool | 是否进行预测,这里模型中没有给添加算是一个小bug我们需要填写一个default=True在其中。 |
| 31 | mix | bool | 在生成式解码器中是否使用混合注意力,默认为True |
| 32 | cols | str | 从数据文件中选择特定的列作为输入特征,应该用不到 |
| 33 | num_workers | int | 线程windows大家最好设置成0否则会报线程错误,linux系统随便设置。 |
| 34 | itr | int | 实验运行的次数,默认为2,我们这里改成数字1. |
| 35 | train_epochs | int | 训练的次数 |
| 36 | batch_size | int | 一次往模型力输入多少条数据 |
| 37 | patience | int | 早停机制,如果损失多少个epochs没有改变就停止训练。 |
| 38 | learning_rate | float | 学习率。 |
| 39 | des | str | 实验描述,默认为"test" |
| 40 | loss | str | 损失函数,默认为"mse" |
| 41 | lradj | str | 学习率的调整方式,默认为"type1" |
| 42 | use_amp | bool | 混合精度训练, |
| 43 | inverse | bool | 我们的数据输入之前会被进行归一化处理,这里默认为False,算是一个小bug因为输出的数据模型没有给我们转化成我们的数据,我们要改成True。 |
| 44 | use_gpu | bool | 是否使用GPU训练,根据自身来选择 |
| 45 | gpu | int | GPU的编号 |
| 46 | use_multi_gpu | bool | 是否使用多个GPU训练。 |
| 47 | devices | str | GPU的编号 |
4.2.2、Bug修复
其中定义了许多参数,在其中存在一些bug有如下的->
main_informer.py: error: the following arguments are required: --model, --data
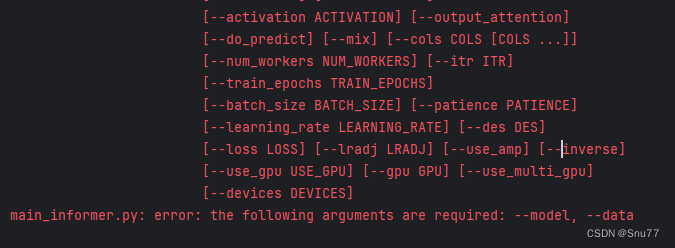
这个bug是因为头两行参数的,中的required=True导致的,我们将其删除掉即可。
parser.add_argument('--model', type=str, required=True, default='informer',help='model of experiment, options: [informer, informerstack, informerlight(TBD)]')
parser.add_argument('--data', type=str, required=True, default='ETTh1', help='data')删除完以后如下->
parser.add_argument('--model', type=str, default='informer',help='model of experiment, options: [informer, informerstack, informerlight(TBD)]')
parser.add_argument('--data', type=str, default='ETTh1', help='data')过程中还有些bug在参数讲解的描述中我都讲述了该如何解决,希望能够帮助到大家。
五、模型训练
到这里参数已经完全讲解完了,bug也解决了我们可以开始进行模型训练了。我修改完训练的main_informer.py内容如下。
import argparse
import torch
from exp.exp_informer import Exp_Informer
parser = argparse.ArgumentParser(description='[Informer] Long Sequences Forecasting')
parser.add_argument('--model', type=str, default='informer',
help='model of experiment, options: [informer, informerstack, informerlight(TBD)]')
parser.add_argument('--data', type=str, default='custom', help='data')
parser.add_argument('--root_path', type=str, default='./', help='root path of the data file')
parser.add_argument('--data_path', type=str, default='ETTh1.csv', help='data file')
parser.add_argument('--is_rolling_predict', type=bool, default=False, help='rolling predict')
parser.add_argument('--rolling_data_path', type=str, default='ETTh1-Test.csv', help='data file')
parser.add_argument('--features', type=str, default='MS', help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')
parser.add_argument('--target', type=str, default='OT', help='target feature in S or MS task')
parser.add_argument('--freq', type=str, default='h',
help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')
parser.add_argument('--checkpoints', type=str, default='./checkpoints/', help='location of model checkpoints')
parser.add_argument('--seq_len', type=int, default=126, help='input sequence length of Informer encoder')
parser.add_argument('--label_len', type=int, default=64, help='start token length of Informer decoder')
parser.add_argument('--pred_len', type=int, default=4, help='prediction sequence length')
# parser.add_argument('--sum_pred_len', type=int, default=42, help='sum_pred_len // pred_len = 0')
# Informer decoder input: concat[start token series(label_len), zero padding series(pred_len)]
parser.add_argument('--enc_in', type=int, default=7, help='encoder input size')
parser.add_argument('--dec_in', type=int, default=7, help='decoder input size')
parser.add_argument('--c_out', type=int, default=1, help='output size')
parser.add_argument('--d_model', type=int, default=512, help='dimension of model')
parser.add_argument('--n_heads', type=int, default=8, help='num of heads')
parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers')
parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers')
parser.add_argument('--s_layers', type=str, default='3,2,1', help='num of stack encoder layers')
parser.add_argument('--d_ff', type=int, default=2048, help='dimension of fcn')
parser.add_argument('--factor', type=int, default=5, help='probsparse attn factor')
parser.add_argument('--padding', type=int, default=0, help='padding type')
parser.add_argument('--distil', action='store_false',
help='whether to use distilling in encoder, using this argument means not using distilling',
default=True)
parser.add_argument('--dropout', type=float, default=0.05, help='dropout')
parser.add_argument('--attn', type=str, default='prob', help='attention used in encoder, optio---ns:[prob, full]')
parser.add_argument('--embed', type=str, default='timeF',
help='time features encoding, options:[timeF, fixed, learned]')
parser.add_argument('--activation', type=str, default='gelu', help='activation')
parser.add_argument('--output_attention', action='store_true', help='whether to output attention in ecoder')
parser.add_argument('--do_predict', action='store_true', default=True, help='whether to predict unseen future data')
parser.add_argument('--mix', action='store_false', help='use mix attention in generative decoder', default=True)
parser.add_argument('--cols', type=str, nargs='+', help='certain cols from the data files as the input features')
parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')
parser.add_argument('--itr', type=int, default=1, help='experiments times')
parser.add_argument('--train_epochs', type=int, default=20, help='train epochs')
parser.add_argument('--batch_size', type=int, default=32, help='batch size of train input data')
parser.add_argument('--patience', type=int, default=5, help='early stopping patience')
parser.add_argument('--learning_rate', type=float, default=0.0001, help='optimizer learning rate')
parser.add_argument('--des', type=str, default='test', help='exp description')
parser.add_argument('--loss', type=str, default='mse', help='loss function')
parser.add_argument('--lradj', type=str, default='type1', help='adjust learning rate')
parser.add_argument('--use_amp', action='store_true', help='use automatic mixed precision training', default=False)
parser.add_argument('--inverse', action='store_true', help='inverse output data', default=False)
parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')
parser.add_argument('--gpu', type=int, default=0, help='gpu')
parser.add_argument('--use_multi_gpu', action='store_true', help='use multiple gpus', default=False)
parser.add_argument('--devices', type=str, default='0,1,2,3', help='device ids of multile gpus')
args = parser.parse_args()
args.use_gpu = True if torch.cuda.is_available() and args.use_gpu else False
if args.use_gpu and args.use_multi_gpu:
args.devices = args.devices.replace(' ', '')
device_ids = args.devices.split(',')
args.device_ids = [int(id_) for id_ in device_ids]
args.gpu = args.device_ids[0]
data_parser = {
'ETTh1': {'data': 'sum.csv', 'T': 'sl', 'B': [7, 7, 7], 'S': [350, 168, 4], 'MS': [7, 7, 1]},
'ETTh2': {'data': 'ETTh2.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'ETTm1': {'data': 'sum.csv', 'T': 'sl', 'B': [7, 7, 7], 'S': [126, 42, 4], 'MS': [7, 7, 1]},
'ETTm2': {'data': 'ETTm2.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'WTH': {'data': 'WTH.csv', 'T': 'WetBulbCelsius', 'M': [12, 12, 12], 'S': [1, 1, 1], 'MS': [12, 12, 1]},
'ECL': {'data': 'ECL.csv', 'T': 'MT_320', 'M': [321, 321, 321], 'S': [1, 1, 1], 'MS': [321, 321, 1]},
'Solar': {'data': 'solar_AL.csv', 'T': 'POWER_136', 'M': [137, 137, 137], 'S': [1, 1, 1], 'MS': [137, 137, 1]},
'custom': {'data': '{}'.format(args.data_path), 'T': 'OT', 'M': [7, 7, 7], 'MS': [7, 7, 1], 'S': [1, 1, 1]},
}
if args.data in data_parser.keys():
data_info = data_parser[args.data]
args.data_path = data_info['data']
args.target = data_info['T']
args.enc_in, args.dec_in, args.c_out = data_info[args.features]
args.s_layers = [int(s_l) for s_l in args.s_layers.replace(' ', '').split(',')]
args.detail_freq = args.freq
args.freq = args.freq[-1:]
print('Args in experiment:')
print(args)
Exp = Exp_Informer
for ii in range(args.itr):
# setting record of experiments
setting = 'group_id{}_{}_{}_ft{}_sl{}_ll{}_pl{}_dm{}_nh{}_el{}_dl{}_df{}_at{}_fc{}_eb{}_dt{}_mx{}_{}_{}'.format(
args.data_path, args.model, args.data, args.features,
args.seq_len, args.label_len, args.pred_len,
args.d_model, args.n_heads, args.e_layers, args.d_layers, args.d_ff, args.attn, args.factor,
args.embed, args.distil, args.mix, args.des, ii)
exp = Exp(args) # set experiments
print('>>>>>>>start training : {}>>>>>>>>>>>>>>>>>>>>>>>>>>'.format(setting))
exp.train(setting)
print('>>>>>>>testing : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.test(setting)
if args.do_predict:
print('>>>>>>>predicting : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.predict(args, setting, True)
torch.cuda.empty_cache()
我们运行该文件,控制台就会开始输出进行训练。
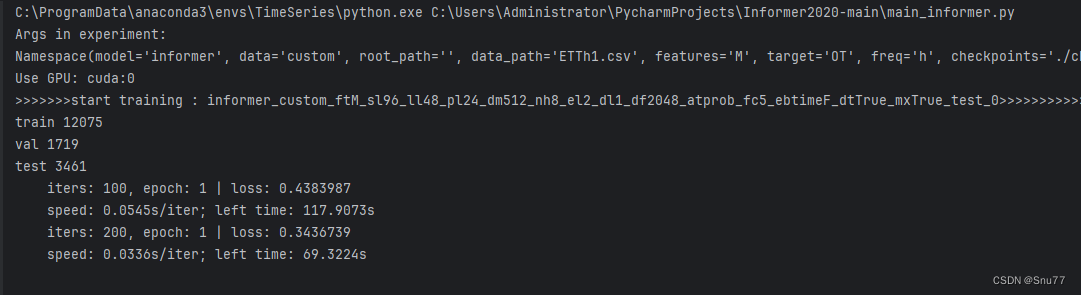
训练出来的模型会保存在该目录下->其中的pth文件就是保存下来的模型。
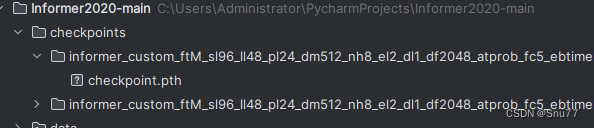
六、结果预测
训练完成之后,我们就可以开始预测了,我这里进行了修改,将所有的结果都变成了CSV文件这样方便大家观测结果会保存在下面的文件当中。
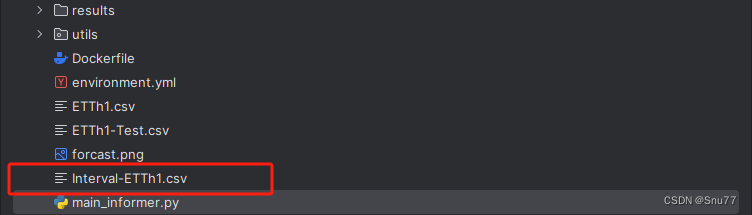
我们可以打开该文件部分截图如下->
我们可以利用其进行画图从而评估结果->

七、如何训练你自己的数据集
上面介绍了用我的数据集训练模型,那么大家在利用模型的时候如何训练自己的数据集呢这里给家介绍一下需要修改的几处地方。
parser.add_argument('--data', type=str, default='custom', help='data')
parser.add_argument('--root_path', type=str, default='./', help='root path of the data file')
parser.add_argument('--data_path', type=str, default='ETTh1.csv', help='data file')
parser.add_argument('--is_rolling_predict', type=bool, default=False, help='rolling predict')
parser.add_argument('--rolling_data_path', type=str, default='ETTh1.csv', help='data file')
parser.add_argument('--features', type=str, default='MS', help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')
parser.add_argument('--target', type=str, default='OT', help='target feature in S or MS task')
parser.add_argument('--freq', type=str, default='h',
help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')首先需要修改的就是上面这几处,
- 其中data必须填写custom,
- root_path填写文件夹即可,
- data_path填写具体的文件在你文件夹下面,
- is_rolling_predict就是滚动预测的开关设置为True则进行滚动预测否则就是普通预测
- rolling_data_path如果你要进行滚动预测则需要一个额外的文件,可以从你的数据集末尾中进行裁取。
- features前面有讲解,具体是看你自己的数据集,我这里MS就是7列结果综合分析输出想要的那一列结果的预测值,
- target就是你数据集中你想要知道那列的预测值的列名,
- freq就是你两条数据之间的时间间隔。
parser.add_argument('--seq_len', type=int, default=96, help='input sequence length of Informer encoder')
parser.add_argument('--label_len', type=int, default=48, help='start token length of Informer decoder')
parser.add_argument('--pred_len', type=int, default=24, help='prediction sequence length')然后这三个就是影响精度的地方,seq_len和label_len需要根据数据的特性来设置,要进行专业的数据分析,我会在下一周出教程希望到时候能够帮助到大家。
parser.add_argument('--enc_in', type=int, default=7, help='encoder input size')
parser.add_argument('--dec_in', type=int, default=7, help='decoder input size')
parser.add_argument('--c_out', type=int, default=7, help='output size')这三个参数要修改和你的数据集对应和前面features的设定来配合设置,具体可以看我前面的参数讲解部分,参数需要修改的就这些,然后是代码部分如下。
data_parser = {
'ETTh1': {'data': 'ETTh1.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'ETTh2': {'data': 'ETTh2.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'ETTm1': {'data': 'ETTm1.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'ETTm2': {'data': 'ETTm2.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'WTH': {'data': 'WTH.csv', 'T': 'WetBulbCelsius', 'M': [12, 12, 12], 'S': [1, 1, 1], 'MS': [12, 12, 1]},
'ECL': {'data': 'ECL.csv', 'T': 'MT_320', 'M': [321, 321, 321], 'S': [1, 1, 1], 'MS': [321, 321, 1]},
'Solar': {'data': 'solar_AL.csv', 'T': 'POWER_136', 'M': [137, 137, 137], 'S': [1, 1, 1], 'MS': [137, 137, 1]},
'custom': {'data': 'ETTh1.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
}
main_informer.py文件有如上的结构,这是我修改之后的,你可以按照我的修改,其中custom就是对应你前面设置参数data的名字,然后data后面替换成你的数据集,必须是csv格式的文件这里,然后是T大家不用管,OT修改成你自己数据集中预测的哪一列列名,就是前面设置的target值,然后是M,S,MS分别对应你数据中的列的给个数即可,我这里输入是8列扣去时间一列在M中就全部填写7即可,S的话我的数据集用不到,MS就是7列输出一列。
最后呢大家如果需要我的数据集和修改完成之后的实战代码可以在评论区留言。
八、全文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的时间序列专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的模型进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
如果大家有不懂的也可以评论区留言一些报错什么的大家可以讨论讨论看到我也会给大家解答如何解决!最后希望大家工作顺利学业有成!




















 3595
3595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











