







 该专栏为热销专栏榜 第2名
该专栏为热销专栏榜 第2名 本文详细介绍了如何利用CVPR2024的DynamicConv论文中的GhostModule改进YOLOv8的C2f部分。通过动态卷积,文章展示了在不大幅增加FLOPs的情况下提升模型参数量的方法,增强了网络的适应性和参数效率。作者还手把手指导读者如何在代码中添加GhostModule,并提供了yaml文件和训练过程记录。
本文详细介绍了如何利用CVPR2024的DynamicConv论文中的GhostModule改进YOLOv8的C2f部分。通过动态卷积,文章展示了在不大幅增加FLOPs的情况下提升模型参数量的方法,增强了网络的适应性和参数效率。作者还手把手指导读者如何在代码中添加GhostModule,并提供了yaml文件和训练过程记录。
一、本文介绍
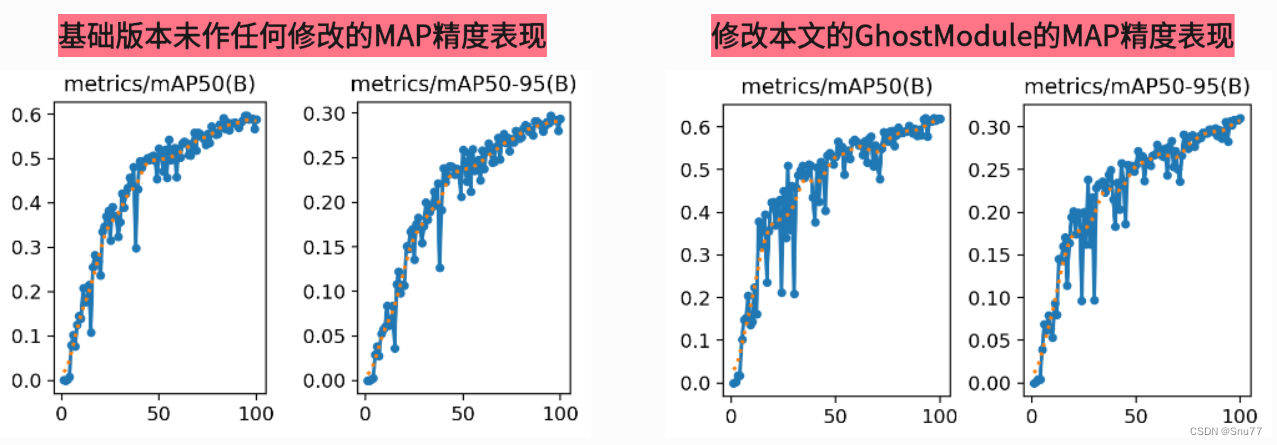
本文给大家带来的改进机制是CVPR2024的最新改进机制DynamicConv其是CVPR2024的最新改进机制,这个论文中介绍了一个名为ParameterNet的新型设计原则,它旨在在大规模视觉预训练模型中增加参数数量,同时尽量不增加浮点运算(FLOPs),所以本文的DynamicConv被提出来了,使得网络在保持低FLOPs的同时增加参数量,在其提出的时候它也提出了一个新的模块hostModule,我勇其魔改C2f从而达到创新的目的,在V8n上其参数量仅有220W计算量为5.8GFLOPs,从而允许这些网络从大规模视觉预训练中获益。
欢迎大家订阅我的专栏一起学习YOLO!
目录

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 347
347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











